




A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set.
布隆过滤器是一种高效利用空间的概率数据结构,1970年由 Burton Howard Bloom 提出的。可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率(False positive)和删除困难。
适用场景
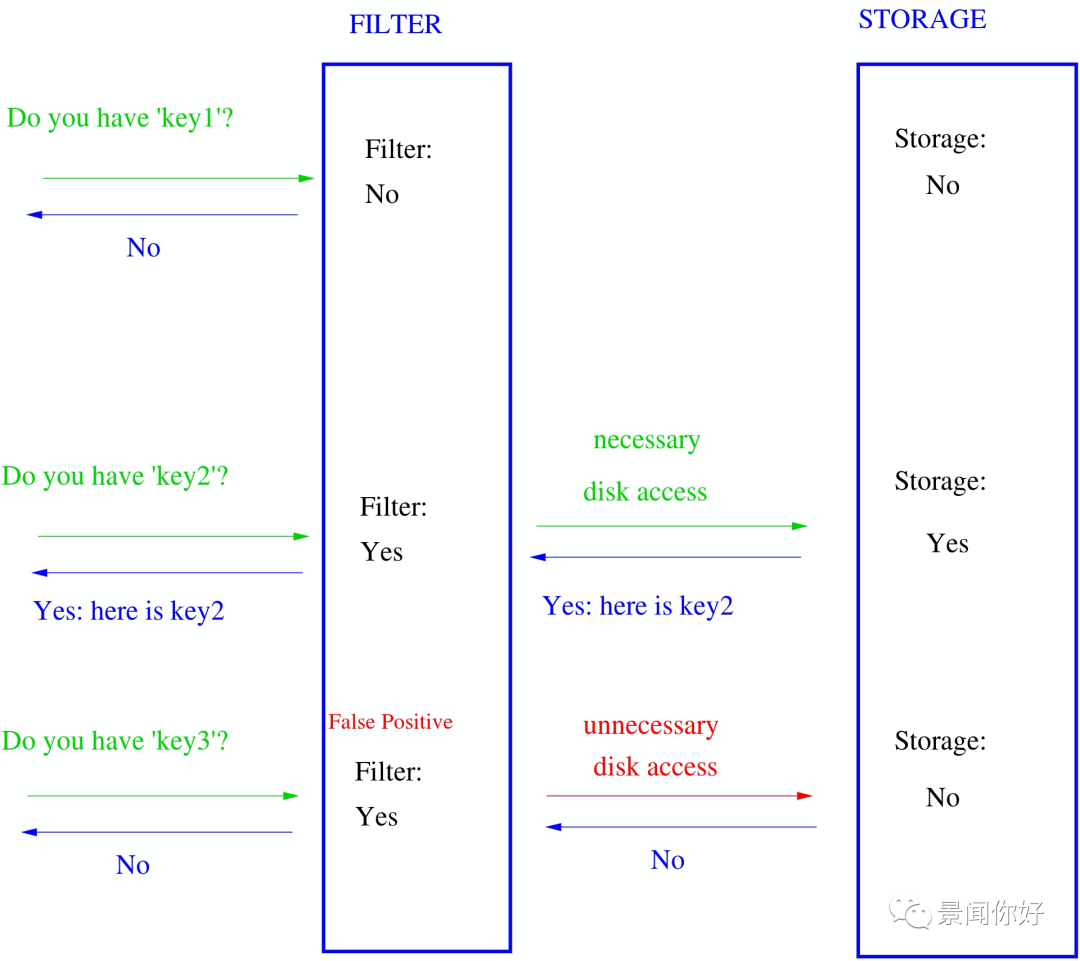
主要判断一个元素是否存在于一个集合中,Bloom filter used to speed up answers in a key-value storage system. Values are stored on a disk which has slow access times. Bloom filter decisions are much faster.
基本概念
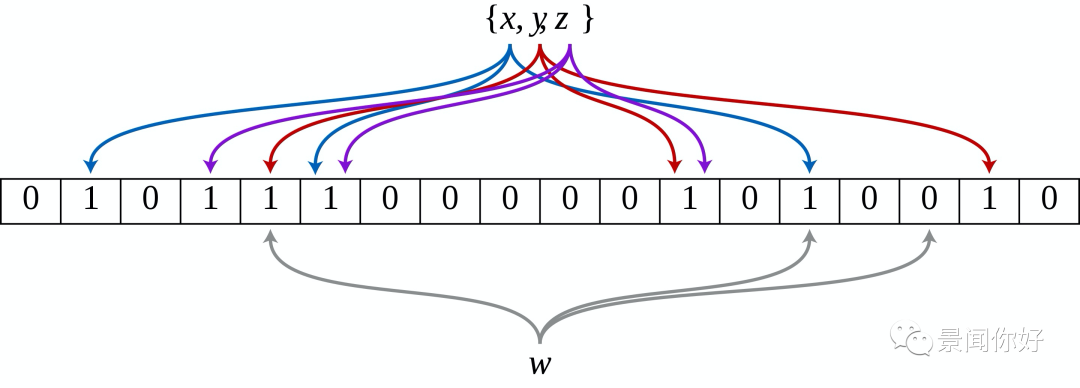
An empty Bloom filter 是由一个bitArray(长度m)和一个hash函数集(个数k)组成,bitArray初始化为0,m远大于k. 每一个hash函数都将元素映射为0~m-1之间的一个整数。举个例子
An example of a Bloom filter, representing the set {x, y, z} . The colored arrows show the positions in the bit array that each set element is mapped to. The element w is not in the set {x, y, z} , because it hashes to one bit-array position containing 0. For this figure, m = 18 and k = 3.
基本操作
增加元数:对于待添加元素x,依次通过 k hash functions计算k个hash值,并将hash值对应bitArray中的bit置1.
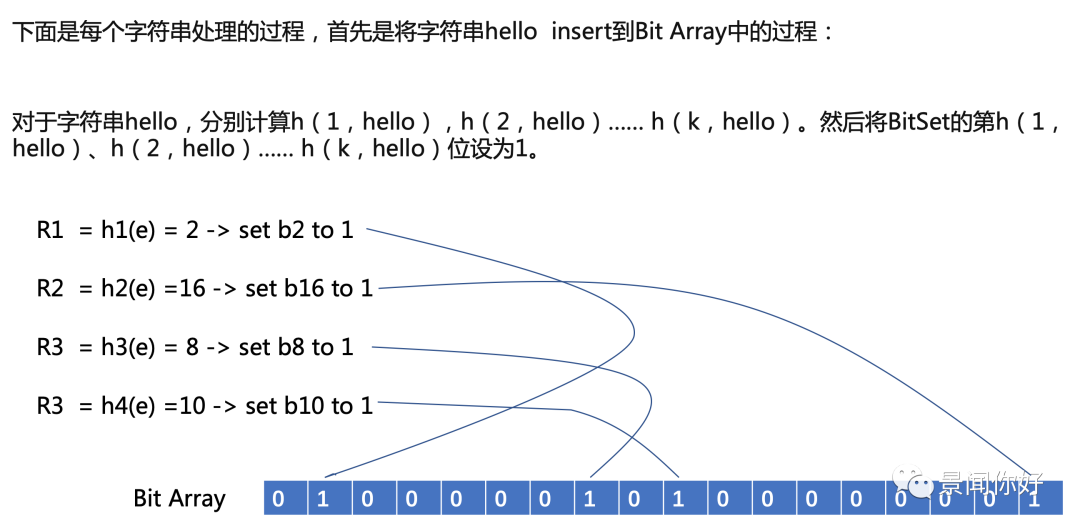
查询元数:对于待添加元素y,依次通过 k hash functions计算k个hash值,并查询bitArray中对应的bit是否全为1,只要有任意一个bit为0,则元素y必然不在集合中;如果全为1,则认为y在集合中。实际上是不能100%的肯定该字符串被Bloom Filter记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)
误判:不在集合中的元素可能被误判为在集合中,因为对于一次查询的k个bit,可能由不同的添加操作而置1. 但反过来,在集合中的元素一定不会被误判。
布隆过滤器不支持删除操作,因为某个bit为1可能与多个添加操作有关,一旦复位为0则会影响多个元素的判断。若非要支持删除,思路之一是增加一个布隆过滤器,记录删除的元素。
由以上可知,布隆过滤器的初衷是,保证快速查询的同时极大的节省存储空间,并以很小的误判率作为代价。并且布隆过滤器并不存储元素本身,对于一些保密要求严格的场景尤其友好。
由以上可知,布隆过滤器的初衷是,保证快速查询的同时极大的节省存储空间,并以很小的误判率作为代价。并且布隆过滤器并不存储元素本身,对于一些保密要求严格的场景尤其友好。
空间和时间复杂度优势
尽管存在假阳性的风险,但是相比其他的数据结构平衡二叉树,tries树,hash table,数组,linked list等还是有空间上的优势。在初始化之后,Bloom Filter不会动态增长,运行过程中维护的始终只是m位的bitArray,空间复杂度是O(m),元素在插入和查询的时候,主要操作是计算K个hash function,因此时间复杂度是O(k).
误判概率推导
错误率一般主要有两种,P(Positive)和N(Negative) 表示模型的判断结果,T(True)和F(False) 表示模型的判断结果是否正确。FP即是FP = false positive,FN = false negative。FP可以理解为模型的判断结果为正例(P),但实际上这个判断结果是错误的(F),连起来就是假正例。
对应Bloom Filter的情况下,FP就是「集合里没有某元素,查找结果是有该元素」,FN就是「集合里有某元素,查找结果是没有该元素」。FN显然总是0,FP会随着Bloom Filter中插入元素的数量而增加——极限情况就是所有bit都为1,这时任何元素都会被认为在集合里。
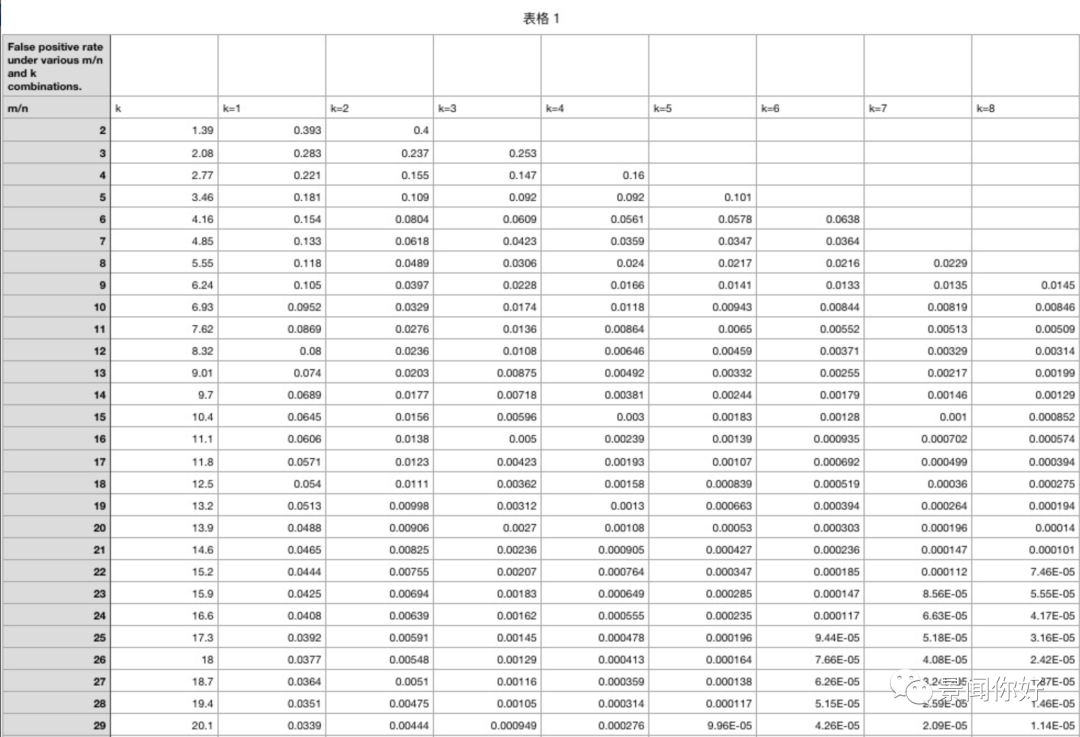
从上面给出的这个表格中,m:BitArray的位数,n:插入字符串个数,k :hash函数个数,从中可以看到 m/n越大准确率越高,误判率越低,k越大准确率越高,误判率越低。但实际上根据公式推导还不完全是这样的情况。
向Bloom Filter插入一个元素时,其一个Hash Function会将BitArray中的某Bit置为1,故对于任一Bit而言,
其被置为1的概率
那么其依然是0的概率
因此当插入一个元素时,K个Hash Function都未将该Bit置为1的概率为
,则向Bloom Filter 插入全部n个元素后,该Bit依然为0的概率即为
反之,该Bit为1的概率则为
由前文可知,判定一个元素存在于Bloom Filter,要求k个Hash Function的哈希值对应的Bit的值均为1。据此, 我们可以计算出其误判率 P(true)=
]
根据极限定理计算 。
可知:
从上述公式可以看出来,当BitArray数组的大小m增大 或 欲插入Bloom Filter中的元素数目n 减小时,均可以使得误判率P(true)下降。
Hash Function 数据K
上面已经提到过Hash Function数目k的增加可以减小误判率P(true)。但是随着Hash Function数目k的继续增加,反而会使误判率P(true)上升,即误判率是一个关于Hash Function数目k的凸函数。所以当k在极值点时,此时误判率即为最小值。
令 ,令 ,那么
要求极值,先对公式两边取对数,然后取导数,可得
f(k)' = lna
当f(k)' = 0 存在极值点,即可求得
0 = lna
所以 ^ =
k = 0.7
因此,是可以通过m和n来确定最优的Hash Function数目k的值。
代码实现
开源的Guava框架中,布隆过滤器的实现主要涉及到2个类,BloomFilter和BloomFilterStrategies,首先来看一下BloomFilter:
public final class BloomFilter<T> implements Predicate<T>, Serializable {
/** The bit set of the BloomFilter (not necessarily power of 2!) */
private final LockFreeBitArray bits;
/** Number of hashes per element */
private final int numHashFunctions;
/** The funnel to translate Ts to bytes */
private final Funnel<? super T> funnel;
/** The strategy we employ to map an element T to {@code numHashFunctions} bit indexes. */
private final Strategy strategy;
/** Creates a BloomFilter. */
private BloomFilter(
LockFreeBitArray bits, int numHashFunctions, Funnel<? super T> funnel, Strategy strategy) {
checkArgument(numHashFunctions > 0, "numHashFunctions (%s) must be > 0", numHashFunctions);
checkArgument(
numHashFunctions <= 255, "numHashFunctions (%s) must be <= 255", numHashFunctions);
this.bits = checkNotNull(bits);
this.numHashFunctions = numHashFunctions;
this.funnel = checkNotNull(funnel);
this.strategy = checkNotNull(strategy);
}
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
checkNotNull(funnel);
checkArgument(
expectedInsertions >= 0, "Expected insertions (%s) must be >= 0", expectedInsertions);
checkArgument(fpp > 0.0, "False positive probability (%s) must be > 0.0", fpp);
checkArgument(fpp < 1.0, "False positive probability (%s) must be < 1.0", fpp);
checkNotNull(strategy);
if (expectedInsertions == 0) {
expectedInsertions = 1;
}
/*
* TODO(user): Put a warning in the javadoc about tiny fpp values, since the resulting size
* is proportional to -log(p), but there is not much of a point after all, e.g.
* optimalM(1000, 0.0000000000000001) = 76680 which is less than 10kb. Who cares!
*/
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter<T>(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);
}
}
这里定义了私有的构造函数,是无法通过直接构造对象的方式进行创建BloomFilter,却可以通过内部的create的方式来创建。
接受的参数是funnel(输入的数据),expectedInsertions(预计插入的元素总数),strategy(实现Strategy的实例)。
strategy是重要的四个final成员变量之一:
Strategy是定义在BloomFilter类内部的接口,代码如下,有3个方法,put(插入元素),mightContain(判定元素是否存在)和ordinal方法(可以理解为枚举类中那个默认方法)
interface Strategy extends java.io.Serializable {
<T> boolean put(T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits);
/**
* Queries {@code numHashFunctions} bits of the given bit array, by hashing a user element;
* returns {@code true} if and only if all selected bits are set.
*/
<T> boolean mightContain(
T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits);
/**
* Identifier used to encode this strategy, when marshalled as part of a BloomFilter. Only
* values in the [-128, 127] range are valid for the compact serial form. Non-negative values
* are reserved for enums defined in BloomFilterStrategies; negative values are reserved for any
* custom, stateful strategy we may define (e.g. any kind of strategy that would depend on user
* input).
*/
int ordinal();
LockFreeBitArray是定义在BloomFilterStrategies中的内部类,封装了布隆过滤器底层bit数组的操作
numHashFunctions是哈希函数的个数,即k的值;
Funnel,这是Guava中定义的一个接口,它和PrimitiveSink配套使用,主要是把任意类型的数据转化成Java基本数据类型(primitive value,如char,byte,int……),默认用java.nio.ByteBuffer实现,最终均转化为byte数组;
参考文献
吴军. 数学之美[M]. 人民邮电出版社, 2012.
Bloom filter https://en.wikipedia.org/wiki/Bloom_filter
https://zhuanlan.zhihu.com/p/140545941
https://segmentfault.com/a/1190000012620152
https://github.com/google/guava/src/com/google/common/hash/BloomFilter.java
