





作者 | JiekeXu
来源 | JiekeXu之路(ID: JiekeXu_IT)
转载请联系授权 | (微信ID:xxq1426321293)
大家好,我是 JiekuXu,很高兴又和大家见面了,今天分享下 Oracle 统计信息和执行计划。本文首发于微信公众号【JiekeXu之路】,欢迎点击上方蓝字关注我吧!
前 言
前几天,微信上收到《Oracle DBA工作笔记》、《MySQL DBA工作笔记》作者,DBAplus社群联合发起人杨建荣老师的邀请,说在他的 QQ 群里分享一下技术类、职场类、感悟类的文章,我顿时感到诚惶诚恐,荣幸之至,分享也是一个学习的过程呀,便欣然答应了杨老师的邀请。想着最近也在学习优化相关的东西,那就一边学习一边总结分享,文中如有其它不到之处,还请多多指教。
一、统计信息
统计信息主要是描述数据库中表,索引的大小,规模,数据分布状况等的一类信息。例如,表的行数,块数,平均每行的大小,索引的 leaf blocks,索引字段的行数,不同值的大小等,都属于统计信息。从 Oracle11G 开始,数据库统计信息的自动收集被整合到自动维护任务中,基本上都是默认自动执行的,也满足大多数情形下的运行需求,不过也可以手动收集,下面可以一起说一说。
使用 gather_stats_job 自动收集是在创建数据库时自动创建的,并由调度程序进行管理。他会收集数据库中优化程序统计信息缺失或已过时的所有对象的统计信息。
使用 dbms_stats 程序包手动收集收集的是系统统计信息。
查看自动收集统计信息任务状态
SYS@PROD1> select client_name,status from Dba_Autotask_Client where client_name='auto optimizer stats collection';CLIENT_NAME STATUS------------------------------------------------------------------------auto optimizer stats collection ENABLED
oracle 11g 中统计信息自动收集任务的名称是 auto optimizer stats collection。11g中自动任务默认的执行时间窗口(oracle时间窗口介绍)为:
周一到周五是晚上 10 点开始到 2 点结束
周末是早上六点,持续 20 个小时。
这期间一般服务器压力比较小。服务器的资源可以留下来收集统计信息了,收集统计信息也是比较耗资源的。可以通过如下语句查看:
SYS@PROD1> set line 234SYS@PROD1> set pagesize 120SYS@PROD1> col WINDOW_NEXT_TIME fora34SYS@PROD1> select WINDOW_NAME,WINDOW_NEXT_TIME , WINDOW_ACTIVE,OPTIMIZER_STATS from DBA_AUTOTASK_WINDOW_CLIENTS order by WINDOW_NEXT_TIME ;WINDOW_NAME WINDOW_NEXT_TIME WINDO OPTIMIZE---------------------------------------------------------------- ----- --------WEDNESDAY_WINDOW 01-APR-20 10.00.00.000000 PMPRC FALSE ENABLEDTHURSDAY_WINDOW 02-APR-20 10.00.00.000000 PMPRC FALSE ENABLEDFRIDAY_WINDOW 03-APR-20 10.00.00.000000 PMPRC FALSE ENABLEDSATURDAY_WINDOW 04-APR-20 06.00.00.000000 AMPRC FALSE ENABLEDSUNDAY_WINDOW 05-APR-20 06.00.00.000000 AMPRC FALSE ENABLEDMONDAY_WINDOW 06-APR-20 10.00.00.000000 PMPRC FALSE ENABLEDTUESDAY_WINDOW 07-APR-20 10.00.00.000000 PMPRC FALSE ENABLED7 rows selected.
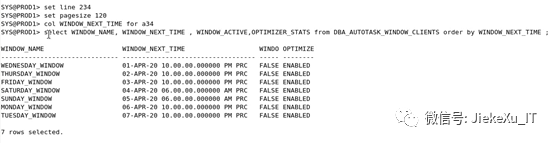
如上,每天都有统计信息的任务在执行,但如果夜间数据库服务器压力比较重,负载高,这个任务就不一定会执行了。则需要调整这个任务及时间了。可以禁用也可以修改,但一般都不会禁用。则需要修改时间窗口到特定的时间
--如下示例,将周五时间窗口时间到晚间23点30分BEGINDBMS_SCHEDULER.DISABLE (name =>'"SYS"."FRIDAY_WINDOW"', force => TRUE);END;BEGINDBMS_SCHEDULER.SET_ATTRIBUTE (name =>'"SYS"."FRIDAY_WINDOW"',attribute => 'REPEAT_INTERVAL',VALUE =>'FREQ=WEEKLY;BYDAY=FRI;BYHOUR=23;BYMINUTE=30;BYSECOND=0');END;BEGINDBMS_SCHEDULER.ENABLE (name =>'"SYS"."FRIDAY_WINDOW"');END;--验证修改SELECT w.window_name,w.repeat_interval,w.duration,w.enabledFROM dba_autotask_window_clientsc, dba_scheduler_windows wWHERE c.window_name =w.window_name AND c.optimizer_stats = 'ENABLED' AND c.window_name ='FRIDAY_WINDOW';WINDOW_NAME REPEAT_INTERVAL DURATION ENABL--------------- ------------------------------------------------------------------------ --------FRIDAY_WINDOW FREQ=WEEKLY;BYDAY=FRI;BYHOUR=23;BYMINUTE=30;BYSECOND=0 +000 04:00:0 TRUE
--停止和开启单个任务(即停止某一日任务)
BEGINDBMS_SCHEDULER.DISABLE(name=>'"SYS"."FRIDAY_WINDOW"',force=>TRUE);END;BEGINDBMS_SCHEDULER.ENABLE(name=>'"SYS"."FRIDAY_WINDOW"');END;
相关视图:
dba_autotask_taskdba_autotask_clientdba_autotask_client_jobdba_autotask_window_clientsdba_autotask_client_historydba_scheduler_jobsdba_scheduler_job_classesdba_scheduler_window_groupsdba_scheduler_windowsdba_scheduler_wingroup_members
自动收集就说到这里了,更多相信请查官方文档或 Doc ID 1300313.1
How to Create an Own Maintenance Window for Autotask Jobs in 11g (Doc ID1300313.1)。下面说一下 dbms_stats 包相关的。
dbms_stats
DBMS_STATS包,主要提供了搜集(gather),删除(delete),导出(export),导入(import),修改(set)统计信息的方法。说起 dbms_stats 那就有必要说说analyze 命令。
dbms_stats 与 analyze 的区别:dbms_stats 是 Oracle9i 及后续版本中用于收集统计信息的包,虽然 analyze 命令也一直可以使用,但是现在已经不推荐使用 analyze 命令来收集统计信息,而是使用 dbms_stats。两者之间有很大的不同,dbms_stats 能正确收集分区表的统计信息,也就是说能够收集 global statistic,而 analyze 只能收集最低层次对象的统计信息,然后推导和汇总出高一级对象的统计信息,如果分区表只会收集分区统计信息,然后再汇总出所有分区的统计信息,得到表一级的统计信息。Analyze 基本上已经废弃不使用了,七八年前使用的还比较多,Oracle 和专家们都在推荐使用dbms_stats 包。
dbms_stats包可以收集数据库、数据字典、索引、表 等的统计信息。

dbms_stats.gather_table_ststs 参数
1、 cascade:
true:表示统计表时连同索引一起收集统计
2、 no_invalidate:
true:收集统计信息后,原有执行计划不失效。
false:收集统计信息后,原有执行计划失效。
默认 DBMS_STATS.AUTO_INVALIDATE,Oracle 自行决定何时使执行计划失效。
3、 method_opt:
FOR ALL [INDEXED | HIDDEN] COLUMNS[size_clause]
FOR COLUMNS [size clause] column[size_clause] [,column [size_clause]...]
字段数据分布不均衡时,建立柱状图(直方图):
柱状图统计信息:索引字段列值建立统计信息
多列统计信息:复合索引列建立统计信息
表达式统计信息:对函数索引键建立统计信息
柱状图统计信息:execdbms_stats.gather_table_stats('SCOTT','TEST',cascade=>true,method_opt=>'forcolumns empno size auto')多列统计信息:EXECDBMS_STATS.GATHER_TABLE_STATS('SH','CUSTOMERS',METHOD_OPT =>'FOR ALL COLUMNSSIZE SKEWONLY FOR COLUMNS (CUST_STATE_PROVINCE,COUNTRY_ID) SIZE SKEWONLY');execdbms_stats.gather_table_stats('sh','customers', method_opt =>'for allcolumns size skewonly for columns (lower(cust_state_province)) size skewonly');
注意:以上两行大小写区别,使用 exec 执行时需要写在一行。匿名块则可以写入多行。另外 Size 大小取值为 1-254,不过在 12c 以后取值则变为 1-2048 。
统计信息查看:
col TABLE_NAME for a10col COLUMN_NAME for a10select TABLE_NAME,COLUMN_NAME,NUM_DISTINCT,DENSITY,NUM_BUCKETS,LAST_ANALYZED,HISTOGRAM from user_tab_col_statisticswhere table_name='TEST';
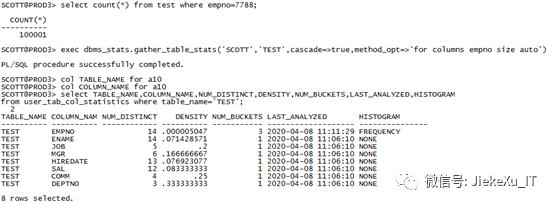
注意:普通用户查 user_tab_col_statistics ,DBA 用户可以查 dba_tab_col_statistics。当然也可以使用 dba_tab_statistics 查看最近一次统计信息收集时间。
Select table_name,num_rows,last_analyzed,stale_stats from dba_tab_statistics where table_name=’TEST’;
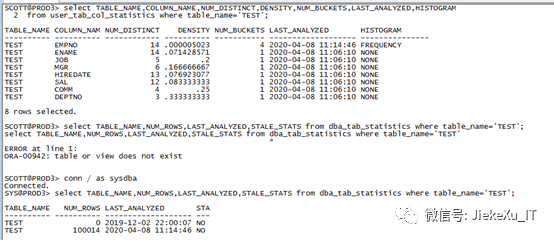
好了统计信息就说到这里了,下面来进入到今天的主题:执行计划。
二、执行计划
执行计划:一条 SQL 语句在数据库中的访问路径或者执行过程的描述。Oracle 通过优化器 Optimizer(这里的优化器是指基于代价的优化器[Cost Based Optimizer,CBO])找到一个最优的执行计划去执行。那么我们首先了解下一条 SQL 是怎么执行的:一般都会经历解析(Parse)、执行(Execute)、获取(Fetch)三个阶段,由 Oracle 不同的组件来完成,详细信息还要从 Oracle 体系结构说起,这里就不展开说了。
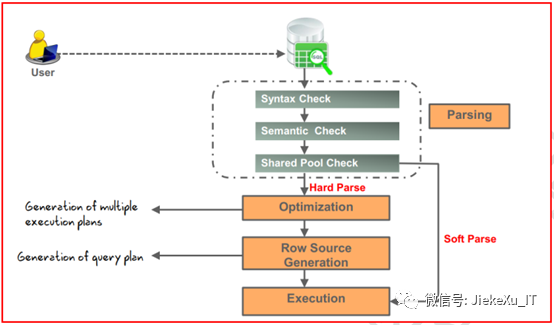
rowsource行源:在查询中,由上一操作返回的符合条件的数据集,它可能是整个表,也可能是部分,当然也可以对2个表进行连接操作(join)最后得到的数据集。关于硬解析、软解析可查看前面一篇文章。
三、查看执行计划
一条 SQL 在数据库中执行出来返回结果,中间经历了什么,都访问了哪些路径,这就需要去查看执行计划了,优化器自以为是的会选择一个认为最为合理的,最为高效的执行方法执行 SQL 返回结果集给客户端,那么就一起看一下查看执行计划都有哪些常用的方法,包括但不限于以下七大方法。
查看执行计划的七大方法
PLSQL 工具
Explain plan for
Set autotrace on
Statistics_level=all
Dbms_xplan.display_cursor
10046 trace
Awrsqrpt.sql
1、PLSQL
PL/SQLDeveloper,Navicat, Toad等客户端工具: 很简单将 SQL 语句写出来,便可以使用 F5 查看执行计划了,不过需要注意缩进格式而且这个执行计划并不是真实计划,并没有实际执行此 SQL。这个工具更适合开发朋友们使用,这个就不用多说了。
2、Explain plan for
Explainplan for:这个命令后面直接跟 SQL语句,然后运行家目录下的 utlxplp.sql 这个脚本便可以查看执行计划。那么这个脚本是啥内容,如下也就是一行内容,这样便可以直接使用如下语句了。顺便说一句,前面客户端工具也是调用这个脚本产生执行计划,那么,这个方法查看的执行计划当然也不是真实的了。
select * from table(dbms_xplan.display());
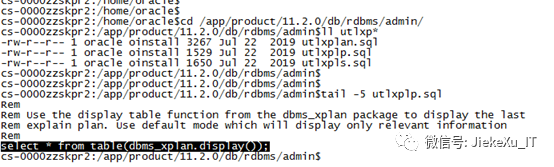
这里的 utlxpls.sql 和 utlxplp.sql是串行执行计划和并行执行计划的脚本, utlxplan.sql 这个脚本只是创建了一个 PLAN_TABLE 的表用于存储执行计划。
explain plan for select * from test whereename='SCOTT';@?/rdbms/admin/utlxplp.sqlSelect count(*) from test;select * from table(dbms_xplan.display());
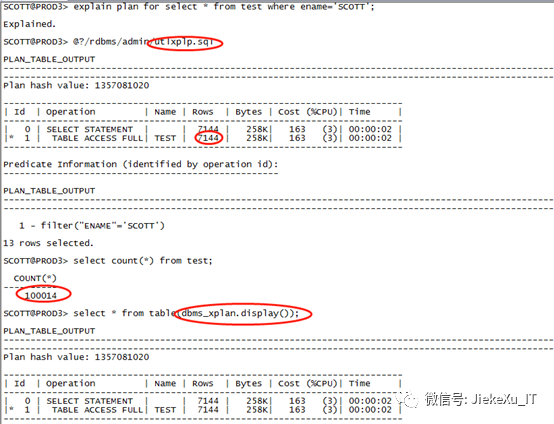
注意:这里并不是真实执行计划,预估到 7144 行,而实际上有 10W 行之多。
3、Set autotrace on
Setautotrace on:这个呢算是比较常用的,也有好几个格式的组合,有的组合不一定是真的执行了 SQL,需要区别对待。各种组合和简单解释如下表格所示:
序号 | 命令 | 解释 |
1 | SET AUTOTRACE OFF | 此为默认值,即关闭Autotrace |
2 | SET AUTOTRACE ON EXPLAIN | 只显示执行计划 |
3 | SET AUTOTRACE ON STATISTICS | 只显示执行的统计信息 |
4 | SET AUTOTRACE ON | 显示执行计划和统计信息两项内容 |
5 | SET AUTOTRACE TRACEONLY | 与ON相似但不显示语句的执行结果 |
6 | SET AUTOTRACE TRACEONLY EXPLAN | 类似于 explain for. |
7 | SET AUTOTRACE TRACEONLY STATISTICS | 和 set autot traceonly 一样 |
注意:当使用 AUTOTRACE 时,Oracle 实际上启动了两个会话连接,一个会话用于执行查询,另一个会话用户记录执行计划和输出最终结果,这两个会话是由同一个进程派生出来的(一个进程对应多个会话)。另外 AUTOTRACE 还可以简写成 AUTOT。
这里值得说明的是当普通用户使用此命令查看执行计划时则会报错,原因是系统缺少角色 PLUSTRACE.需要执行脚本 plustrce.sql 脚本,执行完脚本后将此角色授予给普通用户则可以查看。
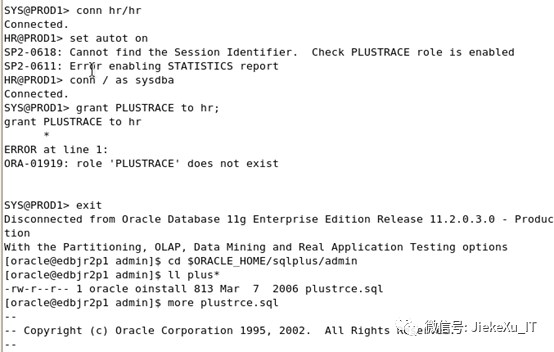
查看脚本内容如下:
set echo ondrop role plustrace;create role plustrace;grant select on v_$sesstat to plustrace;grant select on v_$statname to plustrace;grant select on v_$mystat to plustrace;grant plustrace to dba with admin option;set echo off
注意:with admin option 的意思是级联,即可将授予的权限再次授予下级其他用户。

注意:AUTOTRACE 所列出的执行计划也不一定是真实的,他实际上是通过查询PLAN_TABLE 统计出来的执行计划。
4、Statistics_level=all
Statistics_level=all:Oracl e数据库提供了初始化参数 STATISTICS_LEVEL,该参数控制数据库中的所有主要统计信息收集或建议。此参数设置数据库的统计信息收集级别。
根据的设置 STATISTICS_LEVEL,收集某些报告或统计信息,如下所示:
· BASIC
:未收集任何建议或统计信息。监视和许多自动功能已禁用。Oracle不建议使用此设置,因为它会禁用重要的 Oracle 数据库功能。
· TYPICAL
:这是默认值,可确保收集所有主要统计信息,同时提供最佳的整体数据库性能。对于大多数环境,此设置应足够。
· ALL
:TYPICAL
包括所有通过典型设置收集的警告或统计信息,以及定时操作系统统计信息和行源执行统计信息。
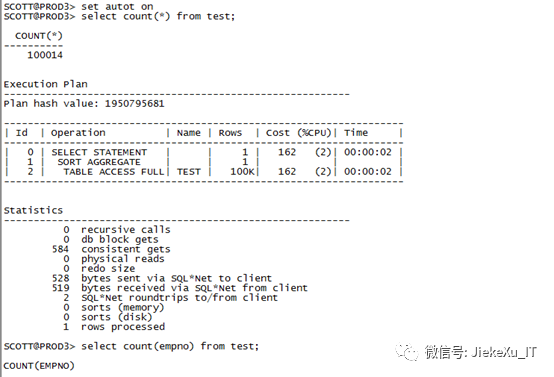
Alter session set Statistics_level=all;Select count(empno) from scott.test;select * from table(dbms_xplan.display_cursor(null,null,’allstatslast’));

注意:这里的 A-Rows 和 E-Rows 代表的是真实行数和评估行数,A-Time 为真实的执行时间,Buffers 则是真实的逻辑读的数值,那么这就意味着这种方法查到的执行计划是真实的。
5、dbms_xplan.display_cursor
dbms_xplan.display_cursor:这个是从共享池获取 SQL_ID ,能够得到 sql_id 则说明此 SQL 已经在数据库里运行过了,故执行计划也是真实存在的。下边还有一个等价的语句从 AWR 性能视图来获取的。
Select * fromtable(dbms_xplan.display_cursor(‘&SQL_ID’));Select * fromtable(dbms_xplan.display_awr(‘&SQL_ID’));
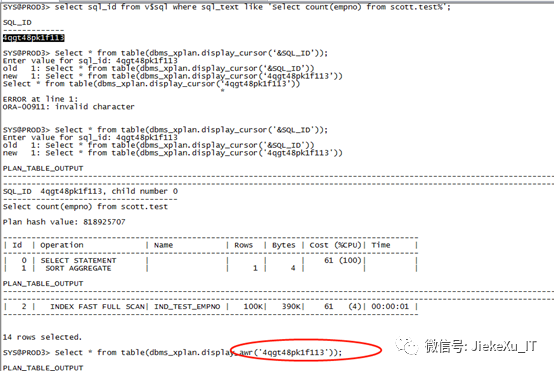
这个比较简单,没有物理读、逻辑读、递归调用等信息。仔细看这种方法和前面一种类似,主要区别在括号里的参数。
6、10046 trace
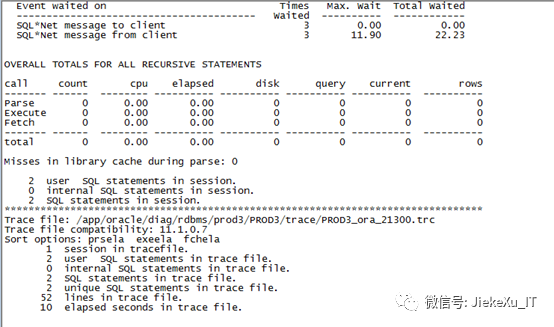
10046 trace:10046事件是 Oracle 提供的内部跟踪事件,是对 SQL_TRACE 的增强,通过 10046 可以知道 Oracle 内核执行 SQL_TRACE 类的跟踪操作。当然 SQL 语句的执行也可以用此跟踪,下面就一起来看看吧。
Alter session set events ‘10046 trace namecontext forever,level 12’;Select count(empno) from scott.test;Alter session set events ‘10046 trace namecontext off’;Select value from v$diag_info where name=’Default Trace File’;Tkprof XXXX/21300.trc test.text sys=nosort=prsela,exeela,fchela
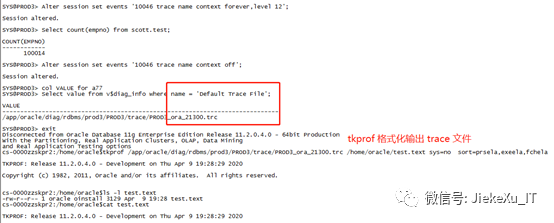
查看格式化后的文件内容,也可以有一些有趣的内容,快去试试吧。
7、Awrsqrpt.sql
Awrsqrpt.sql:这个看着就像 AWR 报告相关的东西吧,还真是的,获取方法类似于 AWR,不过还需要一个 sql_id 就可以了,如果有多个执行计划,用这个就很方便了。
Select sql_id from v$sql where sql_text like ‘select count(*)%’;select max(snap_id) from dba_hist_snapshot;Exec dbms_workload_repository.create_snapshot(); --手动生成快照@?/rdbms/admin/awrsqrpt.sql
--示范例SYS@PROD3> set time on20:23:23 SYS@PROD3> select count(*) from scott.test;COUNT(*)----------10001420:23:35 SYS@PROD3> select count(*) from scott.test;COUNT(*)----------10001420:23:36 SYS@PROD3> select sql_id from v$sql where sql_text like 'select count(*) from scott.test%';SQL_ID-------------88y10jh9cu55420:23:47 SYS@PROD3> exec dbms_workload_repository.create_snapshot();PL/SQL procedure successfully completed.20:24:31 SYS@PROD3> @?/rdbms/admin/awrsqrpt.sqlCurrent Instance~~~~~~~~~~~~~~~~DB Id DB Name Inst Num Instance----------- ------------ -------- ------------1636729019 PROD3 1 PROD3Specify the Report Type~~~~~~~~~~~~~~~~~~~~~~~Would you like an HTML report, or a plain text report?Enter 'html' for an HTML report, or 'text' for plain textDefaults to 'html'Enter value for report_type:Type Specified: htmlInstances in this Workload Repository schema~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~DB Id Inst Num DB Name Instance Host------------ -------- ------------ ------------ ------------* 1636729019 1 PROD3 PROD3 cs-0000zzskpr2Using 1636729019 for database IdUsing 1 for instance numberSpecify the number of days of snapshots to choose from~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~Entering the number of days (n) will result in the most recent(n) days of snapshots being listed. Pressing <return> withoutspecifying a number lists all completed snapshots.Enter value for num_days: 1Listing the last day's Completed SnapshotsSnapInstance DB Name Snap Id Snap Started Level------------ ------------ --------- ------------------ -----PROD3 PROD3 3783 09 Apr 2020 00:01 13784 09 Apr 2020 02:00 13785 09 Apr 2020 03:00 13786 09 Apr 2020 04:01 13787 09 Apr 2020 05:00 13788 09 Apr 2020 06:00 13789 09 Apr 2020 07:00 13790 09 Apr 2020 08:00 13791 09 Apr 2020 09:00 13792 09 Apr 2020 10:00 13793 09 Apr 2020 11:00 13794 09 Apr 2020 12:00 13795 09 Apr 2020 13:00 13796 09 Apr 2020 14:00 13797 09 Apr 2020 15:00 13798 09 Apr 2020 16:00 13799 09 Apr 2020 17:00 13800 09 Apr 2020 18:00 13801 09 Apr 2020 19:00 13802 09 Apr 2020 20:00 13803 09 Apr 2020 20:17 13804 09 Apr 2020 20:24 1Specify the Begin and End Snapshot Ids~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~Enter value for begin_snap: 3803Begin Snapshot Id specified: 3803Enter value for end_snap: 3804End Snapshot Id specified: 3804Specify the SQL Id~~~~~~~~~~~~~~~~~~Enter value for sql_id: 88y10jh9cu554SQL ID specified: 88y10jh9cu554Specify the Report Name~~~~~~~~~~~~~~~~~~~~~~~The default report file name is awrsqlrpt_1_3803_3804.html. To use this name,press <return> to continue, otherwise enter an alternative.Enter value for report_name: awrsqlrpt_1_3803_3804.html……………………<br ><a class="awr" href="#top">Back to Top</a><p ></body></html>Report written to awrsqlrpt_1_3803_3804.html
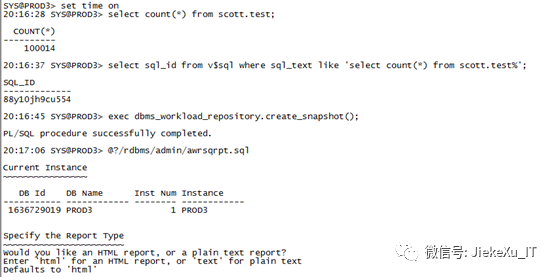
最后生成的报告就是这样的,如下图所示,也很详细。就是有点麻烦,需要查 sql_id 还要生成报告,比较繁琐,使用的人也很少,但有多个执行计划时推荐使用此方法便可以查看全部执行计划了。
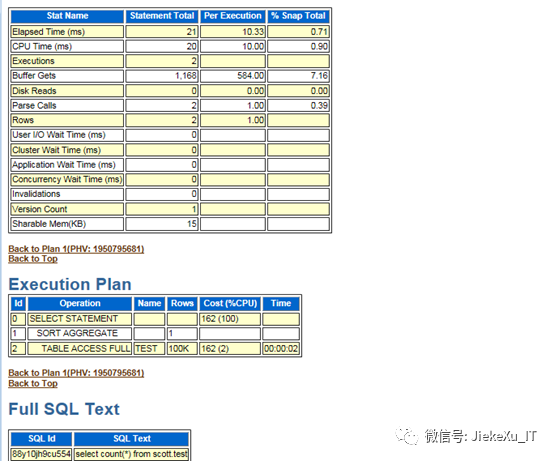
四、读懂执行计划
当我们查看一个执行计划时,能够理解执行计划的顺序就显得非常的重要了,但遗憾的是 Oracle 并没有提供一个很好的方法来查看执行顺序,这就需要我们根据一定的经验以及规则去判断了。
执行计划是由很多步骤组成的,而这些步骤之间是有一定的顺序的,可通过查看执行计划 ID 列则为步骤编号,步骤也存在父子关系,父子关系是通过缩进来体现的,子节点会较父节点向右缩进,父节点就是子节点上面离他最近的左移节点。根据这个规则总结得出一个八字箴言 先子后父,先上后下 根据这个便可以了解大多数执行计划的执行步骤。
执行计划中字段解释:
ID: 一个序号,但不是执行的先后顺序。执行的先后根据缩进来判断。Operation:当前操作的内容。Name:当前所有的对象名称。Rows:当前操作的 Cardinality,Oracle估计当前操作的返回结果集。Bytes:是所处理的所有记录的字节数,是扩展出来的一个预估值,一致获取的开销,以微秒为单位,多少取决于许多因素。Cost(CPU):Oracle 计算出来的一个数值(代价),用于说明SQL执行的代价。Time:Oracle 估计当前操作的时间。Access: 表示这个谓词条件的值将会影响数据的访问路径(表还是索引)。Filter:表示谓词条件的值不会影响数据的访问路径,只起过滤的作用。Dynamic:动态采样,说明 SQL 没有收集到统计信息则会出现动态采样。
这里简单列出一个说明执行计划的执行顺序:
SELECT ename,job,sal,dnameFROM emp,deptWHERE dept.deptno = emp.deptno and notexists (SELECT * FROM salgradeWHERE emp.sal between losal and hisal);
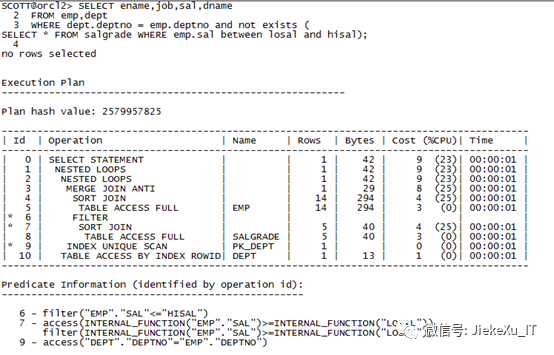
那么我们一起来看一看这个执行步骤是什么:
执行顺序:5-4-8-7-6-3-9-2-10-1-0
按照从左至右,从上至下的方法,了解执行计划的执行步骤
执行计划按照层次逐步缩进,从左至右看,缩进最多的那一步,最先执行,如果缩进量相同,则按照从上而下的方法判断执行顺序,可粗略认为上面的步骤优先执行。每一个执行步骤都有对应的 COST,可从单步 COST的高低,以及单步的估计结果集(对应ROWS/基数),来分析表的访问方式,连接顺序以及连接方式是否合理。
最后,来一起了解下表的访问方式和连接方式有哪些?
表的访问方式主要有全表扫(TABLE ACCESS FULL)和索引扫描(INDEX SCAN),当进行索引扫描(index scan 和 index lookup) 时有五种数据类型的索引:
唯一索引(index uniquescan)
索引范围扫描(indexrange scan)
索引全扫描(index fullscan)
索引快速扫描(index fastfull scan) 5.索引跳跃扫描(skipscan)
表的连接方式主要有四种表连接方式:
嵌套循环(NESTED LOOPS)
哈希连接(HASH JOIN)
排序-合并连接(SORT MERGE JOIN)
笛卡尔积(Cartesian Product)
执行计划、访问方式、连接模式就简单介绍到这里,Hint 提示,表连接,用不上索引,固定最优执行计划,索引的三大特性等等等等,太深入的东西还需要继续学习,毕竟 SQL 优化不是一天两天就可以完成的事儿,脚踏实地,一步一个脚印慢慢走下去。
参考链接
网络链接:
https://juejin.im/entry/59f04c2f5188252c23121278
https://www.cnblogs.com/xqzt/p/4467867.html
https://www.cnblogs.com/xwdreamer/p/3897580.html
11g 官方文档
https://docs.oracle.com/cd/E11882_01/server.112/e41573/toc.htm
Oracle® DatabasePerformance Tuning Guide 11g Release 2 (11.2)
梁敬彬 梁敬弘 著《收获不止SQL优化》
韩峰 著 《SQL优化最佳实践》
好了,到这里就告一段落了,写作不易,此文如果对你有帮助,请支持点“在看”与转发,你的支持便是我最大的动力,让我们一起努力做更好的自己!

Oracle 11GR2 RAC 最新补丁 190416 安装指导
你该知道的 Oracle 认证那些事儿(送 OCP 题库)
三万字打造 91 道 MySQL 面试题【建议收藏】
Oracle 软件包及补丁包免费下载及简单说明
Oracle 12C 最新补丁下载与安装操作指北
Oracle 12CR2 安装配置与基础学习
Windows 环境下安装 Oracle 19C




点亮在看,你最好看!
