





继上一篇“空间节省50%,时序性能提升5倍,三一重工从Hadoop+Spark到MatrixDB架构变迁实现One for ALL”(点击标题阅读原文)发布后,这次我们再从 Apache NiFi + MatrixDB 着手,用20行代码轻松实现数据实时入库!
作者信息:李净芝 - 工程车辆事业部研究院大数据工程师
前言

什么是 Apache NiFi ?
什么是 MatrixGate ?
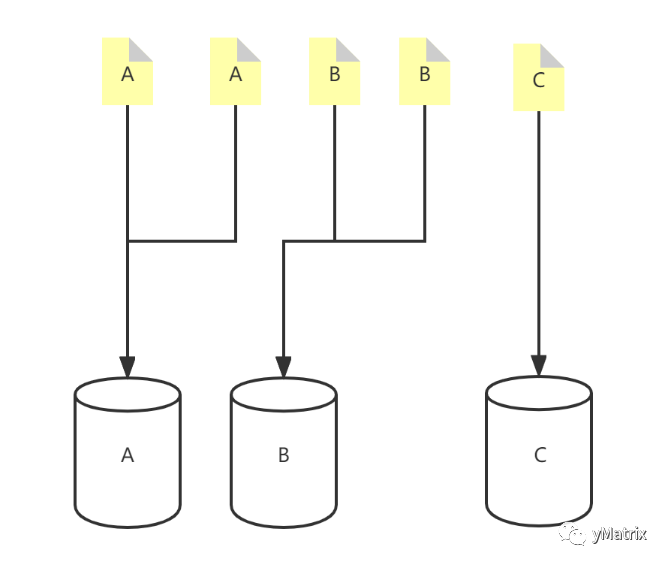
MatrixGate 简称 mxgate,是 MatrixDB 自带的高性能流式数据加载服务器,使用 mxgate 进行数据加载性能要远远高于原生 INSERT 语句,MatrixGate 加载数据的逻辑如下图所示:
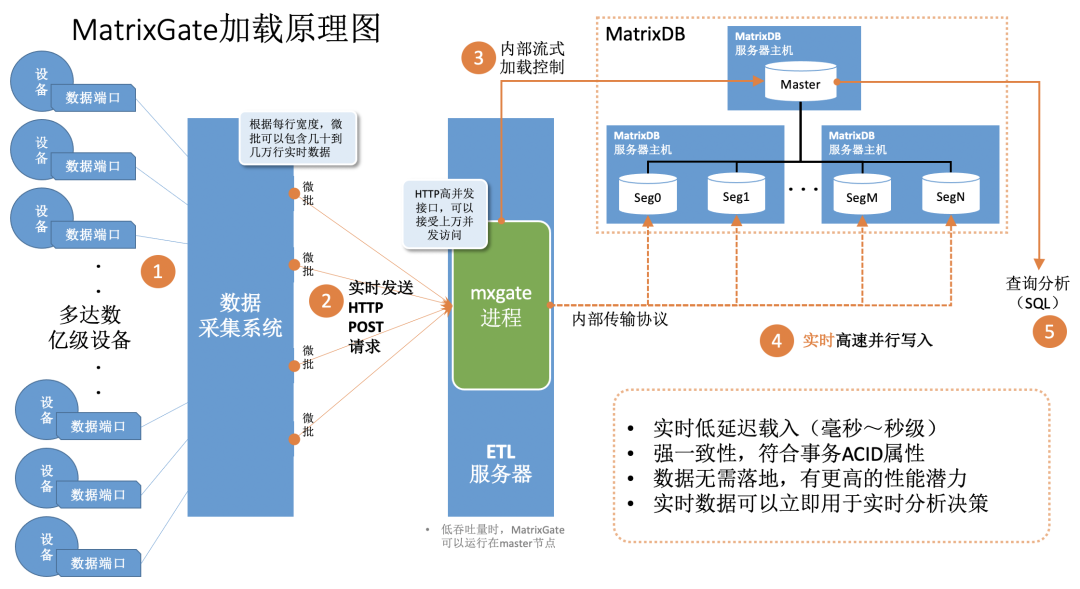
数据采集系统采集设备数据或者接收由设备发送来的数据 采集系统以并发微批的模式向 MatrixGate 的服务进程 mxgate 持续发送数据 mxgate 进程和 MatrixDB 的 master 进程高效通信,沟通事务和控制信息 数据直接发送到 segment 节点,并行高速写入,不存在 master 单点瓶颈。
三一重工泵诵云平台将二者相结合,实现数据实时入库,且解决标准化的问题。在分享案例之前,先了解一下 NiFi 中一个重要的概念:
· FlowFile 是 NiFi 的核心概念,是对原始数据记录的抽象,是面向 FBP (Flow-Based Programming) 设计的。
案例

根据上面的思路,使用 NiFi 搭建数据流的过程如下:
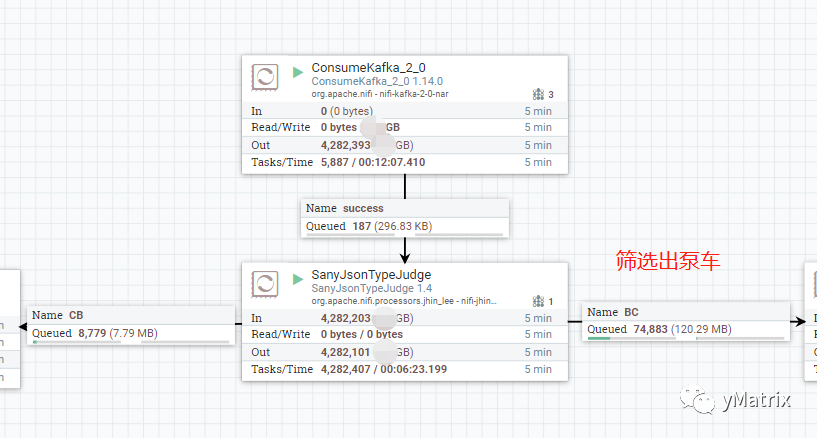
02.
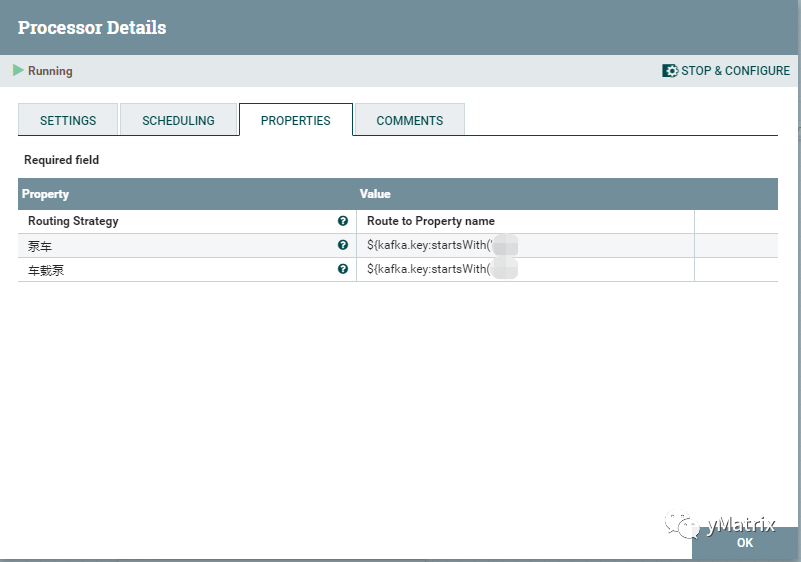
上图中的 Sany/JsonTypeJudge 为自定义组件,功能为根据 kafka.key 分发车载泵和泵车的数据,也可以用 NiFi 自带的 RouteOnAttribute 组件。
官方组件实现的分发规则更加的灵活,但是效率要低许多。样例如下:

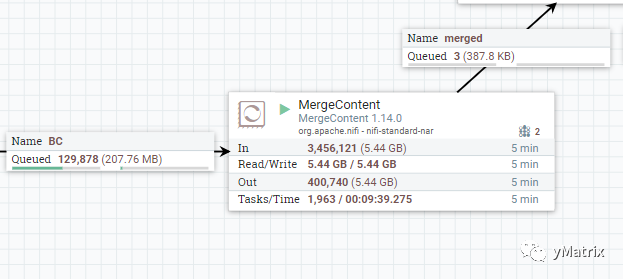

每个 FlowFile 都有属性,桶策略首先需要指定合并属性,在上图中,合并属性设置为 kafka.key,也就是设备号。
kafka.key 为A的 FlowFile 将进入A桶,kafka.key 为B的 FlowFile 将进入B桶,以此类推,每个 FlowFile 根据自身的属性进入对应的桶。
桶策略还有其他配置,比如桶中的最小/最大文件数、桶中文件的最小/最大 Size、桶的持续时间等等,一旦达到门限值,桶里面的 FlowFiles 会打包合并成一个 FlowFile 输出到下一组件。
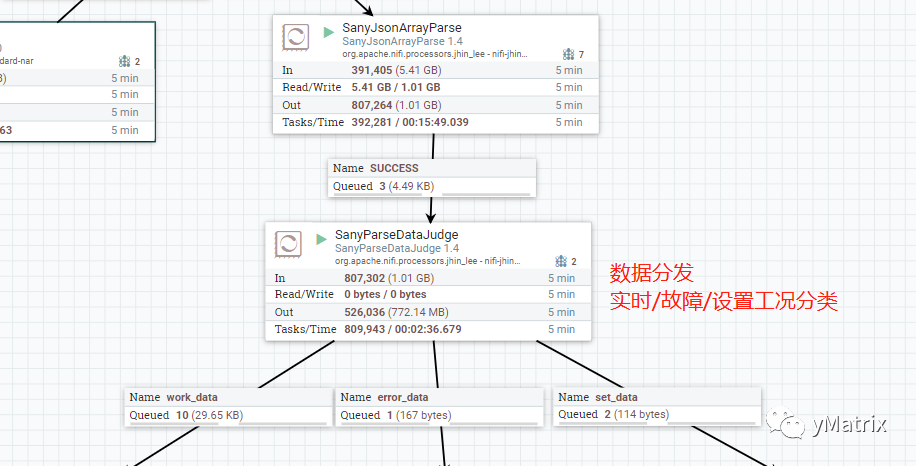
04.
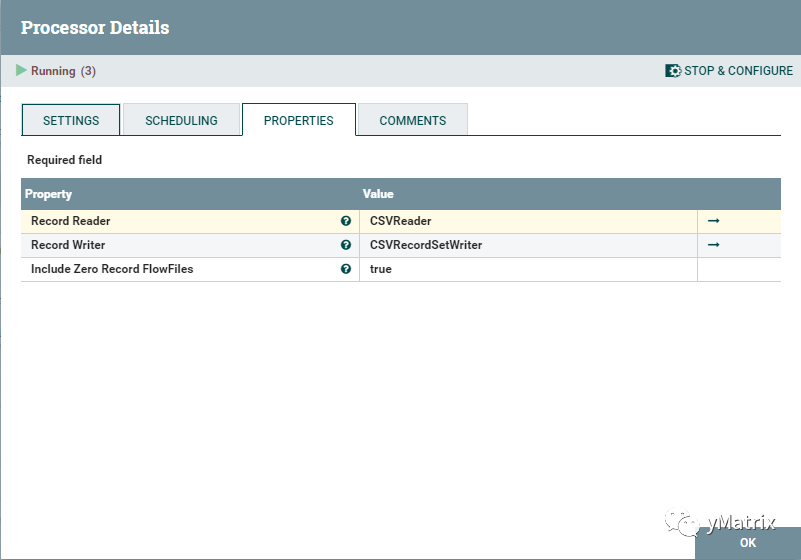
将合并后的 jsonArray 进行解析,在这里用到的组件为自定义组件,因为原始的 json,key 不固定,而 NiFi 自带的 jsonReader 组件只能用单一的 schema 去读。
05.
对分发的实时工况进行标准化。设备上传的数据是由控制协议定义的,随着控制协议以及设备的更新,新老设备对于同一个物理量会存在不同的字段映射,比如转速这个物理量,在1车型中是字段A,在2车型中是字段B,我们希望根据车型的不同,填充A or B 到转速这个物理量。
以下是实现标准化涉及的组件:
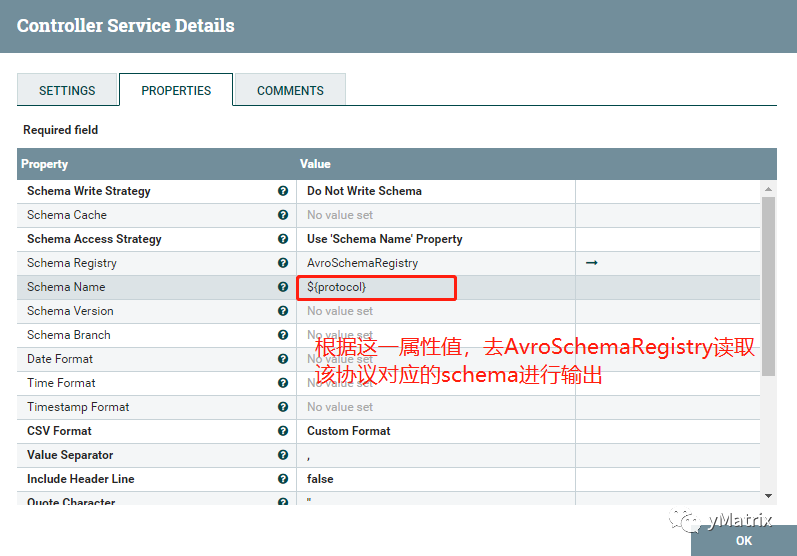
NiFi 自带的 LookupAttribute 组件,根据前文提到的 kafka.key 这一属性,为每条记录添加 protocol 属性,为后续每条记录输出A还是输出B提供依据。
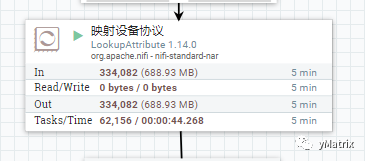


为每个 FlowFile 添加上 protocol 这个属性后,在使用 NiFi 自带的 ConvertRecord 组件根据 protocol 的值动态地输出A or B,以此达到标准化的效果。
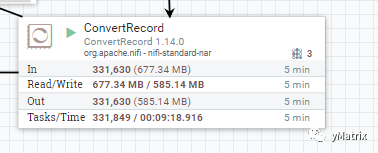

小结
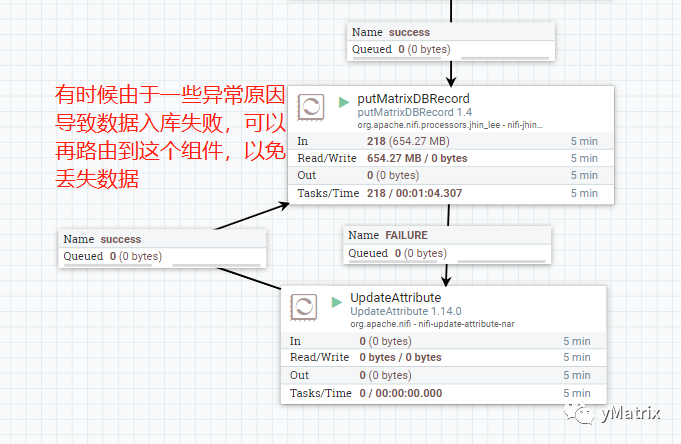
在本案例中,需要注意的是,NiFi 为了防止数据丢失会将接入的数据内容作为内容声明保存在本地,可以通过更改 NiFi 配置再重启来改变内容声明留存时间。





 分享、点赞、在看,一起为 yMatirx 充电!
分享、点赞、在看,一起为 yMatirx 充电!
