




Mysql HeatWave是一种分布式、可伸缩、无共享、内存中的列式查询处理引擎,可以在不改造应用的情况下快速提高应用查询性能,许多用户都希望从MySQL HeatWave 中受益,迈出的第一步是进行数据迁移, 本文将介绍Amazon Redshift的数据如何迁移到Oracle Mysql Database Service(简称MDS)上来。
1. Redshift的数据导出为CSV文件,使用Redshit的UNLOAD功能
2. 导入CSV文件到MDS,使用MySQL Shell工具
本文我们使用Redshift的官方演示数据:Tickit
Redshift UNLOAD是官方推荐的导出方案,该方案需要使用S3,下面是一些准备工作
1. 首先需要创建一个S3 buckct : mys3
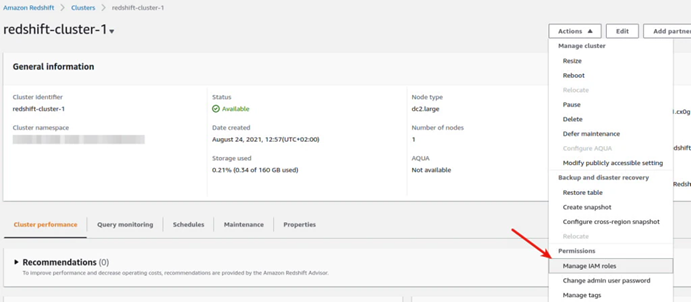
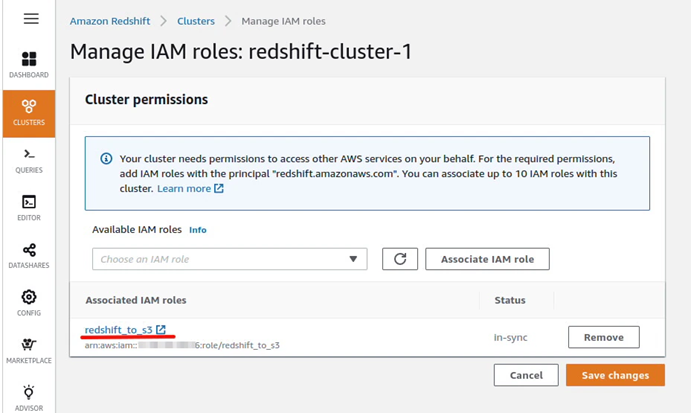
2. 创建一个IAM 角色:redshift_to_s3 ,配置具有mys3的读写权限
3. 绑定角色redshift_to_s3到Redshift Cluster上
现在就可以使用查询编辑器UNLOAD所有的数据了
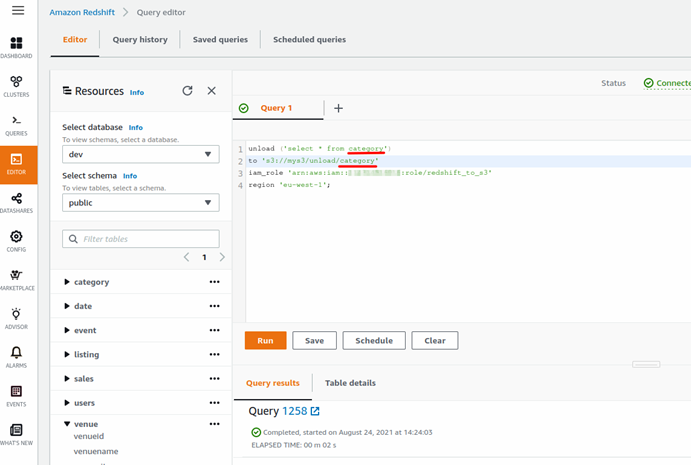
重复该操作把全部的表导出到S3上。
Redshift是PostgreSQL的变种,在导入数据到MDS之前需要创建对应的表结构,所以需要生成建表语句,如下实例中
Redshift中的建表语句为:
create tablecategory(catid smallint not nulldistkey sortkey, catgroupvarchar(10), catname varchar(10), catdesc varchar(50));
修改MDS中建表语句为:
create tablecategory(catid smallint not null auto_increment primary key, catgroup varchar(10), catname varchar(10), catdesc varchar(50));
为了便于读取S3的数据,我们使用s3fs-fuse把S3作为一个文件系统挂载到Linux服务器上
$ sudo yuminstall -y s3fs-fuse
首先需要从AWS上获取Access Key ID和Secret Access Key然后添加到 .passwd-s3fs文件中,两个值使用冒号分割

然后对该文件进行授权
chmod 600~/.passwd-s3fs
在S3中需要为该Bucket创建一个访问端点
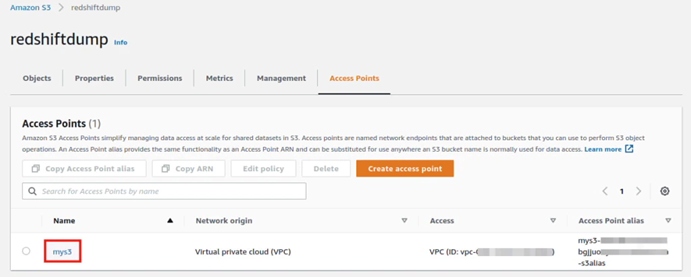
现在就可以把Bucket挂载到Linux上了

数据导入我们推荐使用 MySQL Shell的importTable工具,因为针对大数据集,importTable可以多线程并行导入
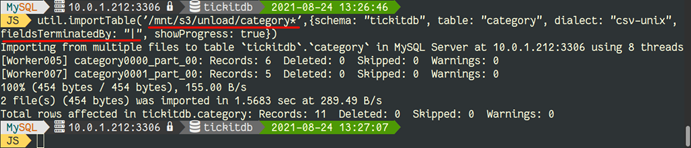
注意使用UNLOAD导出的数据字段分隔符是“|”,所以需要在importTable中进行配置。
使用MySQL Shell可以很容易的把Redshift的数据迁移到MDS,便于我们快速体验到MDS,享受HeatWave的强大功能。

作者简介
高胜杰,甲骨文云平台数据集成高级咨询顾问,专注于甲骨文数据集成相关产品及解决方案。具有7+年的大数据、数据处理经验,熟悉甲骨文相关集成产品,方案和项目实施经验。您可以通过joy.gao@oracle.com与他联系。
