





作者:陈裘凯( 求索)
前言
Cloud Native
https://github.com/kubedl-io/kubedl
网站:
https://kubedl.io/model/intro/
Overlay 不是银弹
Cloud Native
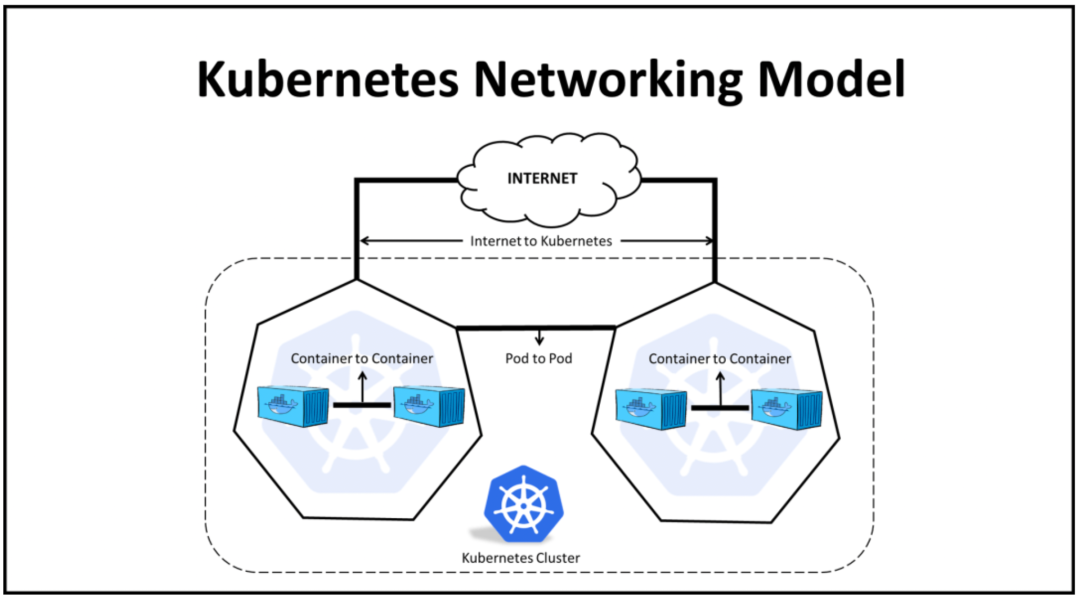
Pod 的无感迁移:Overlay 网络是基于物理网络构建的虚拟二层网络,Pod IP 并不与任何节点绑定,当节点宕机或发生其他硬件异常时,对应的服务 Pod 可以通过相同的 IP 在其他节点上重新启动,只要底层的物理网络连通不中断就不影响服务的可用性。在大规模的分布式机器学习训练中。KubeDL 也是基于“Pod 可能漂移,但 Service 是固定的”这一前提实现的计算节点故障转移(FailOver);
网络节点的规模:经典的 NAT 地址解析通常通过 ARP 广播协议来自动学习邻接节点 IP 与 MAC 地址的映射,但当节点规模庞大时,一次广播很容易造成 ARP 风暴并引起网络拥塞,而基于隧道穿越的 Overlay 网络只需知道少数的 VTEP 节点的 MAC 地址即能实现数据包的转发,极大的降低了网络的压力;
租户网络隔离:Kubernetes 强大的网络插件扩展性配合 VxLAN 的协议设计,很容易实现虚拟网络的再划分从而实现租户之间的网络隔离;
使能 Host 高性能网络
Cloud Native
apiVersion: training.kubedl.io/v1alpha1kind: "TFJob"metadata:name: "mnist"namespace: kubedlspec:cleanPodPolicy: NonetfReplicaSpecs:PS:replicas: 2restartPolicy: Nevertemplate:spec:containers:- name: tensorflowimage: kubedl/tf-mnist-with-summaries:1.0command:- "python"- "/var/tf_mnist/mnist_with_summaries.py"- "--log_dir=/train/logs"- "--learning_rate=0.01"- "--batch_size=150"volumeMounts:- mountPath: "/train"name: "training"resources:limits:cpu: 2048mmemory: 2Girequests:cpu: 1024mmemory: 1Givolumes:- name: "training"hostPath:path: /tmp/datatype: DirectoryOrCreateWorker:replicas: 3restartPolicy: ExitCodetemplate:spec:containers:- name: tensorflowimage: kubedl/tf-mnist-with-summaries:1.0command:- "python"- "/var/tf_mnist/mnist_with_summaries.py"- "--log_dir=/train/logs"- "--learning_rate=0.01"- "--batch_size=150"volumeMounts:- mountPath: "/train"name: "training"resources:limits:cpu: 2048mmemory: 2Girequests:cpu: 1024mmemory: 1Givolumes:- name: "training"hostPath:path: /tmp/datatype: DirectoryOrCreate
标准容器网络的好处显而易见,简单直观的网络设置,FailOver 友好的网络容错,都使得这一方案能够满足大多数场景下的需求。但对高性能网络有诉求的场景下又该如何运转呢?KubeDL 给出了主机网络的解决方案。
沿用以上的例子,启用主机网络的方式很简单,只要给 TFJob 追加一个 annotation 即可,其余的作业配置都无需特殊改造,如下所示:
apiVersion: training.kubedl.io/v1alpha1kind: "TFJob"metadata:name: "mnist"namespace: kubedlannotations:kubedl.io/network-mode: hostspec:cleanPodPolicy: NonetfReplicaSpecs:PS:...Worker:...
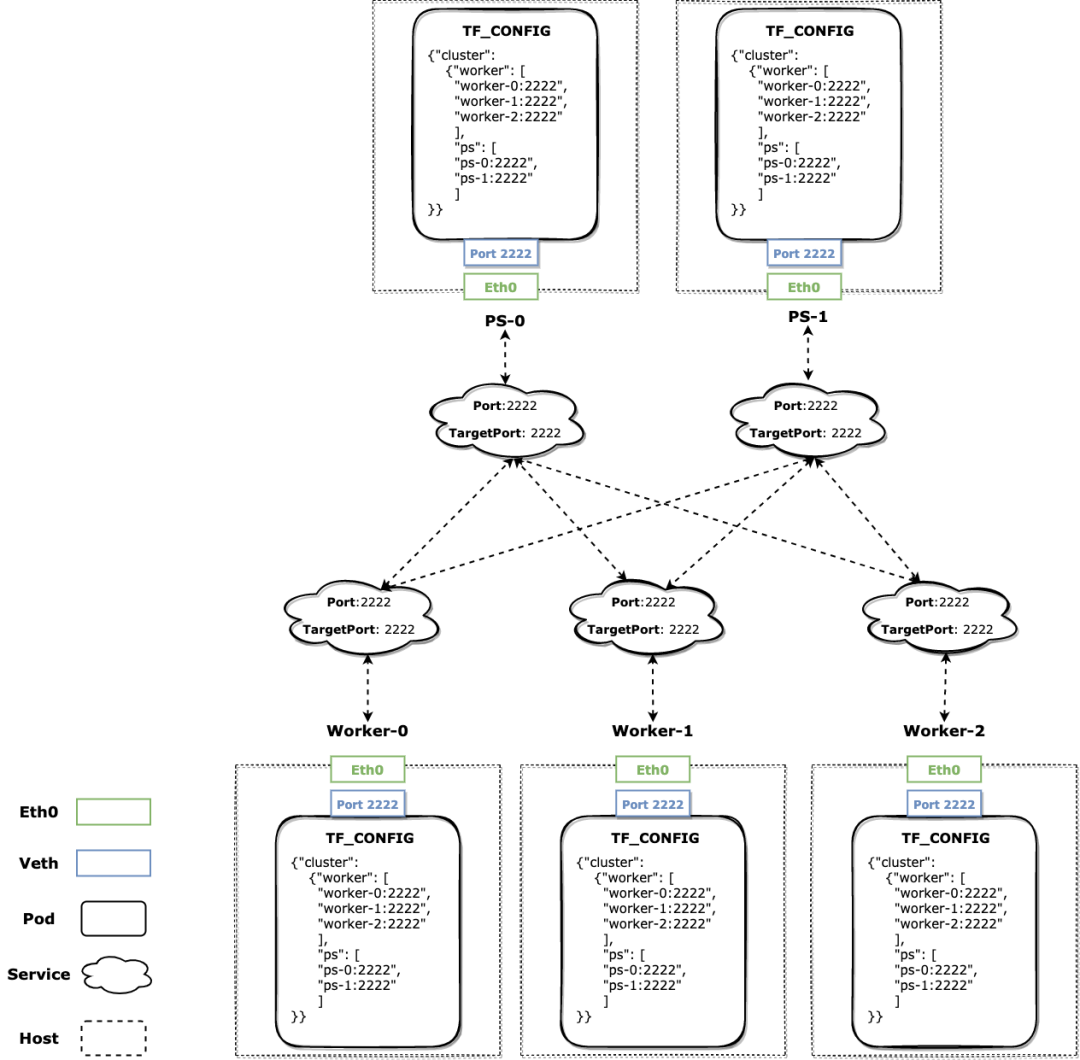
创建 Pod 时不再使用固定端口,而是在一定端口范围内随机出一个主机端口,并设置对应暴露的容器端口号,通过上下文的方式传递到后续的控制流中;
对 Pod 启用 HostNetwork 并设置 DNS 解析策略为 Host 优先;
不再创建 Headless Service,取而代之的是一个正常的流量转发 Service,暴露端口为原先的恒定值,目标端口为 Pod 的真实值;
生成的 TF Cluster Spec 中,自身对应的 Role+Index 可见 Local 地址端口为真实的主机端口,其他 Role 实例的地址端口都是恒定的,无论对方的 Pod 如何漂移都能通过 Service 正确转发;
当发生 FailOver 时,KubeDL 会为重建后的 Pod 重新选择端口,新启动的 Pod 会通过 TF_CONFIG 得到新的 Local 地址端口,同时 KubeDL 保证对应 Service 的目标端口得到正确更新,其他与之相连的 Role 也能在 Service 目标端口更新后继续通信;
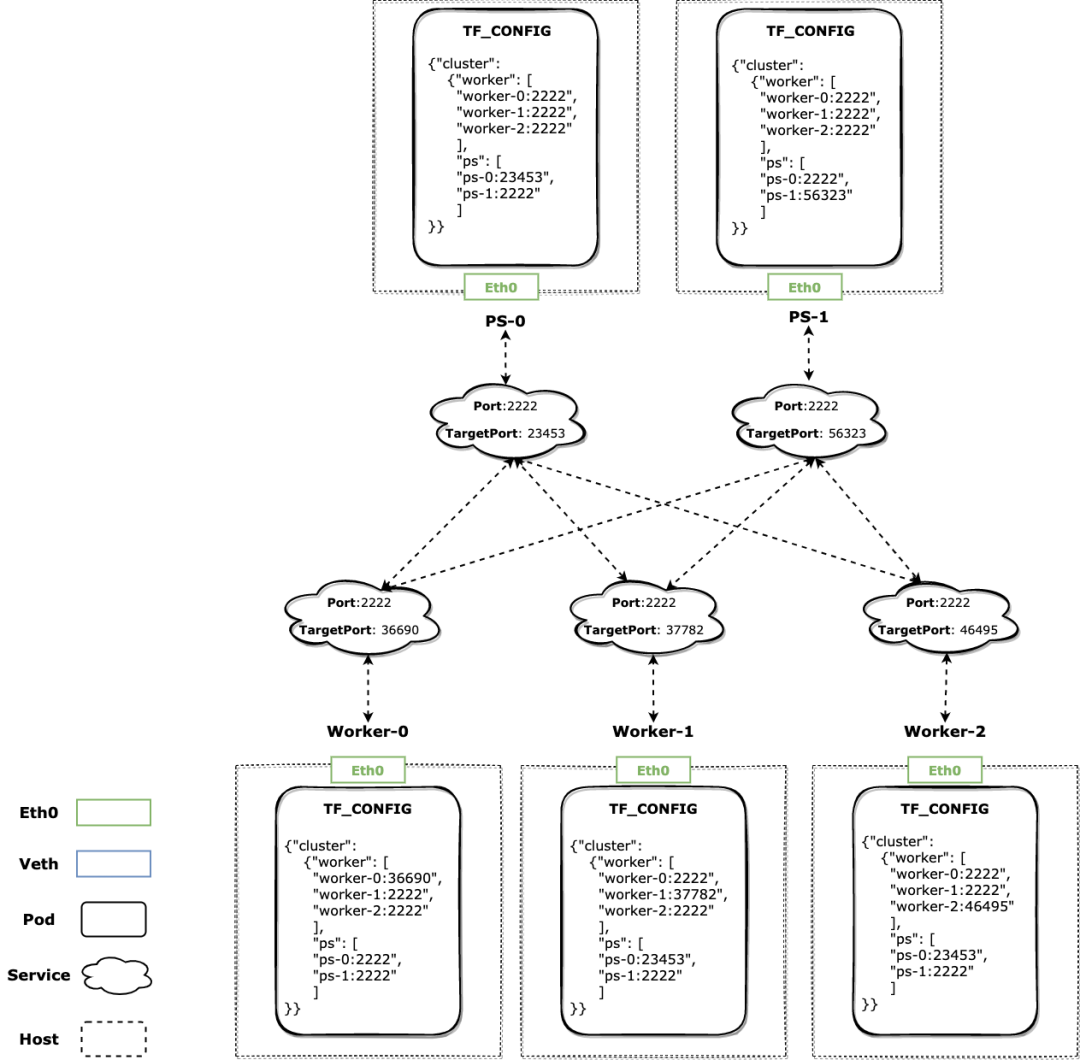
我们以 Tensorflow 作为主机网络的例子,因为它的 Cluster Spec 复杂性更具代表性,但 KubeDL 的内置工作负载(如 PyTorch,XGBoost 等)我们也都针对其框架的行为实现了对应主机网络模式的网络拓扑设置。
总结
Cloud Native
文章转载自阿里巴巴云原生,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
