







IN子查询优化
物化表转连接
「derived_merge=on(视图/派生表合并,需要配合好Auto_key)」复制
SELECT * FROM t1 WHERE key1 IN (SELECT common_field FROM t2 WHERE key3 = 'a');复制
SELECT t1.* FROM t1 INNER JOIN materialized_table ON key1 = m_val;复制
使用t1表作为驱动表的话,总查询成本由下边几个部分组成:
使用materialized_table表作为驱动表的话,总查询成本由下边几个部分组成:
视图/派生表合并(Derived merge)
Derived作为FROM后面子查询生成的派生表/衍生表,生成在内存或者临时表空间。
含有派生表的查询,MySQL提供了两种执行策略:派生表物化——将派生表的结果集写到一个内部的临时表中,然后就把这个物化表当作普通表一样参与查询。当然,在对派生表进行物化时,MySQL使用了一种称为延迟物化的策略,也就是在查询中真正使用到派生表时才回去尝试物化派生表,而不是还没开始执行查询呢就把派生表物化掉;派生表和外层的表合并,也就是将查询重写为没有派生表的形式。通过将外层查询和派生表合并的方式成功的消除了派生表,也就意味着我们没必要再付出创建和访问临时表的成本了。
如果Derived表作为驱动表,需减少数据量为目的。
执行计划中出现<derived>当作被驱动表的时候,可能会产生auto_key(是在内存中的索引)【对tmp_table_size、max_heap_table_size依赖较大】,生命周期就是这个SQL的执行时间,并且创建临时索引也需要消耗时间、资源。产生auto_key索引也是要以减少数据量为目的。
derived_merge=on,可以把简单的Subquuery转换成Join。on时,被驱动表的连接条件需要有索引,off时,被驱动表的结果集要小。
1、使用limit语法可以阻止视图合并;(即阻止物化生成Derived表)
2、视图合并慢是因为视图合并因为被驱动表中没有索引。
3、为什么不先JOIN,然后再把最终结果及排序?答:就是处理结果集的面积大小问题。(结果集的行数量和列数量的乘积)
4、视图合并是5.7的新特性,建议使用,使用的前提是被驱动表的关联字段必须有索引(视图合并慢是因为视图合并因为被驱动表中没有索引),5.6是没有视图合并的,会先生成一个derived表,并创建derived表的auto_key,其实视图合并的优势在于不用生成一个derived表的过程,被驱动表关联列上加上索引就相当于5.6中的auto_key(只适用于小结果集,如果结果集所在的中间结果集大,会产生磁盘IO)效果了。
5、Derived表不能合并(Derived表不能转换为Join)的情况:
union/union all
group by
distinct
聚合函数,MIN()、MAX()、SUM()、COUNT()...(我的理解此条为需要对结果集二次计算的情况)
limit
having
@分配给用户变量
SELECT List中的子查询
仅引用文字值
将子查询转换为semi-join
半连接(semi-join)
「semijoin=on(半连接)loosescan=on(半连接—松散扫描)firstmatch=on(半连接—首次匹配)duplicateweedout=on(半连接—重复值消除)」复制
虽然将子查询进行物化之后再执行查询都会有建立临时表的成本,但是不管怎么说,我们见识到了将子查询转换为连接的强大作用,MySQL继续优化:能不能不进行物化操作直接把子查询转换为连接呢?(就是再次缩减物化生成临时表的成本)
SELECT * FROM t1 WHERE key1 IN (SELECT common_field FROM t2 WHERE key3 = 'a');复制
这个查询可以理解成:对于t1表中的某条记录,如果我们能在t2表(准确的说是执行完WHERE t2.key3 = 'a'之后的结果集)中找到一条或多条记录,这些记录的common_field的值等于t1表记录的key1列的值,那么该条t1表的记录就会被加入到最终的结果集。这个过程其实和把t1和t2两个表连接起来的效果很像:
SELECT t1.* FROM t1 INNER JOIN t2 ON t1.key1 = t2.common_field WHERE t2.key3 = 'a';复制
我们不能保证对于t1表的某条记录来说,在t2表(准确的说是执行完WHERE t2.key3 = 'a'之后的结果集)中有多少条记录满足t1.key1 = t2.common_field这个条件,不过我们可以分三种情况讨论:
1、对于t1表的某条记录来说,t2表中没有任何记录满足t1.key1 = t2.common_field这个条件,那么该记录自然也不会加入到最后的结果集。
2、对于t1表的某条记录来说,t2表中有且只有1条记录满足t1.key1 = t2.common_field这个条件,那么该记录会被加入最终的结果集。
3、对于t1表的某条记录来说,t2表中至少有2条记录满足t1.key1 = t2.common_field这个条件,那么该记录会被多次加入最终的结果集。
对于t1表的某条记录来说,由于我们只关心t2表中是否存在记录满足t1.key1 = t2.common_field这个条件,而不关心具体有多少条记录与之匹配,又因为有情况三的存在,我们上边所说的IN子查询和两表连接之间并不完全等价。但是将子查询转换为连接又真的可以充分发挥优化器的作用,MySQL提出了一个新概念——半连接(英文名:semi-join)。
SELECT t1.* FROM t1 SEMI JOIN t2 ON t1.key1 = t2.common_field WHERE key3 = 'a';复制
半连接(semi-join)的实现
01
Table pullout (子查询中的表上拉)
SELECT * FROM t1 WHERE key2 IN (SELECT key2 FROM t2 WHERE key3 = 'a');复制
由于key2列是t2表的唯一二级索引列,所以我们可以直接把t2表上拉到外层查询的FROM子句中,并且把子查询中的搜索条件合并到外层查询的搜索条件中,上拉之后的查询就是这样的。
SELECT t1.* FROM t1 INNER JOIN t2 ON t1.key2 = t2.key2 WHERE t2.key3 = 'a';复制
02
DuplicateWeedout execution strategy(重复值消除)
对于这个查询:
SELECT * FROM t1 WHERE key1 IN (SELECT common_field FROM t2 WHERE key3 = 'a');复制
CREATE TABLE tmp ( id PRIMARY KEY);复制
这样在执行连接查询的过程中,每当某条t1表中的记录要加入结果集时,就首先把这条记录的id值加入到这个临时表里,如果添加成功,说明之前这条t1表中的记录并没有加入最终的结果集,现在把该记录添加到最终的结果集;如果添加失败,说明之前这条t1表中的记录已经加入过最终的结果集,这里直接把它丢弃就好了,这种使用临时表消除semi-join结果集中的重复值的方式称之为DuplicateWeedout。
03
LooseScan execution strategy(松散扫描)
这个查询:
SELECT * FROM t1 WHERE key3 IN (SELECT key1 FROM t2 WHERE key1 > 'a' AND key1 < 'b');复制
04
Semi-join Materialization execution strategy
05
FirstMatch execution strategy(首次匹配)
FirstMatch是一种最原始的半连接执行方式,跟我们常规认知中的相关子查询的执行方式是一样的,先取一条外层查询的中的记录,然后到子查询的表中寻找符合匹配条件的记录,如果能找到一条,则将该外层查询的记录放入最终的结果集并且停止查找更多匹配的记录,如果找不到则把该外层查询的记录丢弃掉;然后再开始取下一条外层查询中的记录,重复上边这个过程。
对于某些使用IN语句的相关子查询。
SELECT * FROM t1 WHERE key1 IN (SELECT common_field FROM t2 WHERE t1.key3 = t2.key3);复制
可以很方便的转为半连接,转换后的语句类似这样:
SELECT t1.* FROM t1 SEMI JOIN t2 ON t1.key1 = t2.common_field AND t1.key3 = t2.key3;复制
半连接(semi-join)的使用场景
SELECT ... FROM outer_tables WHERE expr IN (SELECT ... FROM inner_tables ...) AND ...SELECT ... FROM outer_tables WHERE (oe1, oe2, ...) IN (SELECT ie1, ie2, ... FROM inner_tables ...) AND ...复制
不适用半连接(semi-join)的情况
以下情况不能将子查询转换为semi-join:
1、外层查询的WHERE条件中有其他搜索条件与IN子查询组成的布尔表达式使用OR连接起来。
SELECT * FROM t1 WHERE key1 IN (SELECT common_field FROM t2 WHERE key3 = 'a') OR key2 > 100;复制
2、使用NOT IN而不是IN的情况。
SELECT * FROM t1 WHERE key1 NOT IN (SELECT common_field FROM t2 WHERE key3 = 'a');复制
3、在SELECT子句中的IN子查询的情况。
SELECT key1 IN (SELECT common_field FROM t2 WHERE key3 = 'a') FROM t1 ;复制
4、子查询中包含GROUP BY、HAVING或者聚集函数的情况。
SELECT * FROM t1 WHERE key2 IN (SELECT COUNT(*) FROM t2 GROUP BY key1);复制
5、子查询中包含UNION的情况。
SELECT * FROM t1 WHERE key1 IN ( SELECT common_field FROM t2 WHERE key3 = 'a' UNION SELECT common_field FROM t2 WHERE key3 = 'b');复制
不能转为semi-join查询的子查询MySQL还是做了一些优化工作:
对于不相关子查询来说,可以尝试把它们物化之后再参与查询。先将子查询物化,然后再判断字段值是否在物化表的结果集中可以加快查询执行的速度。
不管子查询是相关的还是不相关的,都可以把IN子查询尝试转为EXISTS子查询。
outer_expr IN (SELECT inner_expr FROM ... WHERE subquery_where)/* 可以转换为 */EXISTS (SELECT inner_expr FROM ... WHERE subquery_where AND outer_expr=inner_expr)复制
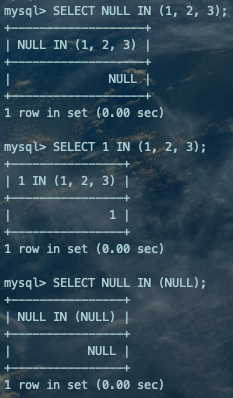
当然这个过程中有一些特殊情况,比如在outer_expr或者inner_expr值为NULL的情况下就比较特殊。有NULL值作为操作数的表达式结果往往是NULL。
SELECT NULL IN (1, 2, 3);SELECT 1 IN (1, 2, 3);SELECT NULL IN (NULL);复制
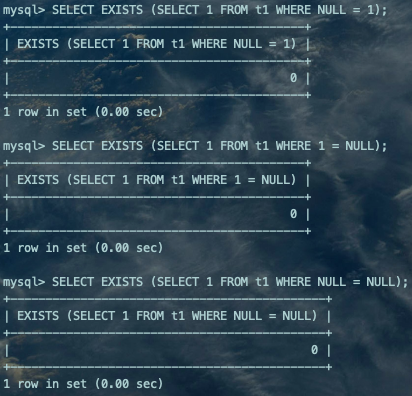
SELECT EXISTS (SELECT 1 FROM t1 WHERE NULL = 1);SELECT EXISTS (SELECT 1 FROM t1 WHERE 1 = NULL);SELECT EXISTS (SELECT 1 FROM t1 WHERE NULL = NULL);复制
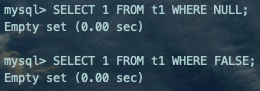
大部分使用IN子查询的场景是把它放在WHERE或者ON子句中,而WHERE或者ON子句是不区分NULL和FALSE的。
SELECT 1 FROM t1 WHERE NULL;SELECT 1 FROM t1 WHERE FALSE;复制
SELECT * FROM t1 WHERE key1 IN (SELECT key3 FROM t2 where t1.common_field = t2.common_field) OR key2 > 1000;/* 转换为 */SELECT * FROM t1 WHERE EXISTS (SELECT 1 FROM t2 where t1.common_field = t2.common_field AND t2.key3 = t1.key1) OR key2 > 1000;复制
※ 果IN子查询不满足转换为semi-join的条件,又不能转换为物化表或者转换为物化表的成本太大,那么它就会被转换为EXISTS查询。
※ 如果果IN子查询符合转换为semi-join的条件,查询优化器会优先把该子查询转换为semi-join,然后从下边5种执行半连接的策略中选择成本最低的那种执行策略来执行子查询:Table pullout、DuplicateWeedout、LooseScan、Materialization、FirstMatch。
※ 如果IN子查询不符合转换为semi-join的条件,那么查询优化器会从下边两种策略中找出一种成本更低的方式执行子查询:先将子查询物化之后再执行查询、执行IN to EXISTS转换。
ANY/ALL子查询优化
如果ANY/ALL子查询是不相关子查询的话,它们在很多场合都能转换成我们熟悉的方式去执行。
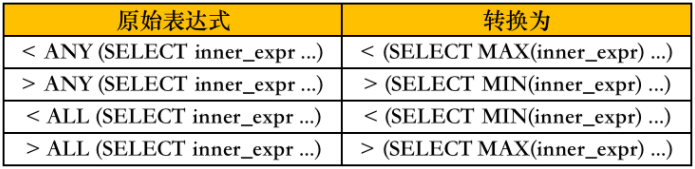
[NOT] EXISTS子查询的执行
如果[NOT] EXISTS子查询是不相关子查询,可以先执行子查询,得出该[NOT] EXISTS子查询的结果是TRUE还是FALSE,并重写原先的查询语句。
SELECT * FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE key1 = 'a') OR key2 > 100;复制
SELECT * FROM t1 WHERE TRUE OR key2 > 100;/* 进一步简化后 */SELECT * FROM t1 WHERE TRUE;复制
对于相关的[NOT] EXISTS子查询来说,比如这个查询:
SELECT * FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t1.common_field = t2.common_field);复制
这个查询只能按照我们常规认知中的那种执行相关子查询的方式来执行。不过如果[NOT] EXISTS子查询中如果可以使用索引的话,那查询速度也会加快不少,比如:
SELECT * FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t1.common_field = t2.key1);复制
这个EXISTS子查询中可以使用idx_key1来加快查询速度。
今天的内容很重要,篇幅较长,就不做小结了,因为我感觉通篇几乎都是知识点,虽然是偏理论的原理性文章,但是背后的本质和处理逻辑还是需要我们掌握的。刚开始学习的时候,我也懵懵懂懂,但是有一句话:书读百遍,其义自见。我觉得这句话对我非常有用,一个难以理解的知识点,看一遍不会,那就看第二遍,两遍不会,再看第三遍,以此类推,直到理解看会,总会有彻悟的一天。
纵观整个MySQL的优化特性,优化的本质一直都是减少扫描行数、减少随机IO、随机IO优化成顺序IO、能够使用到索引、将常规认知中的子查询执行方式转换成连接查询...等等。MySQL的开发人员对业务使用场景较多的子查询有较大篇幅的优化算法设计,不愧为仅次于Oracle数据库的优秀数据库软件,汇聚了很多开发人员的心血,作为使用者的我们,更应该知其然,知其所以然,才不会飘飘然。
站在巨人的肩膀上,每天进步一点点,大道至简,贵在坚持!~
参考资料
小孩子4919《MySQL是怎样运行的:从根上理解MySQL》

end
