




一个问题引出另一个问题
因某些原因客户把数据库手动重启了,起来以后使用节点1的VIP连接数据库失败,报错 ORA-12514:TNS:监听程序当前无法识别连接描述符中请求的服务,使用所有节点的物理IP连接数据库报错 ORA-12541: TNS:无监听程序。
- 想看下集群资源的状态(crsctl status res -t),竟然报出以下错误信息(所有节点):

- crsctl status res -t -init 再查询一下(所有节点现象相同):
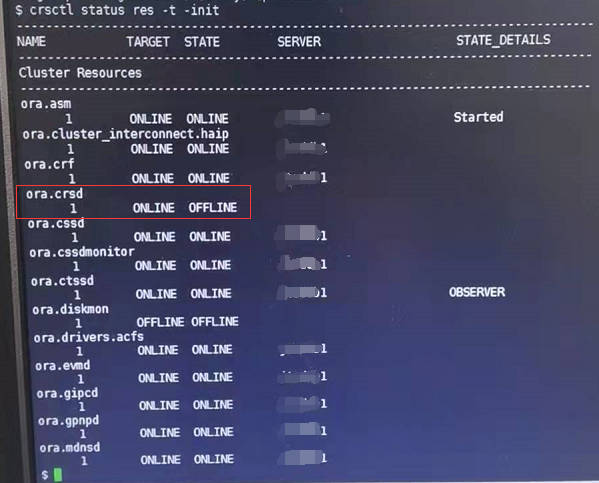
可以发现 ora.crsd 资源处于 OFFLINE 状态,不正常,以前遇到过一次因为本地空间爆满导致 ora.crsd 资源异常,df命令检查下本地磁盘空间,使用率均未超过60%。 - 尝试手动启动一下 ora.crsd 资源(所有节点现象相同)
su - grid
crsctl start resource "ora.crsd" -init
复制
显示资源启动成功,但是(crsctl status res -t)还是不能正常显示,(crsctl status res -t -init)还是显示 ora.crsd 资源处于 OFFLINE 状态。
- 由于客户环境不能远程,这个问题先放一下吧,先处理客户反应的问题(使用节点1的VIP连接数据库失败),因为 ora.crsd 资源启动失败不会影响数据库的运行和对外提供服务,抓紧解决掉客户关心的问题才是重点。
处理使用节点1的VIP连接数据库失败的问题
这个问题比较好分析,查看监听状态,检查数据库状态,检查local_listener参数大致就能找到原因。
- 检查监听状态
# 查看当前环境启动了哪些监听
ps -ef |grep tns
# 当前只有一个默认的监听,查看监听状态
lsnrctl status
复制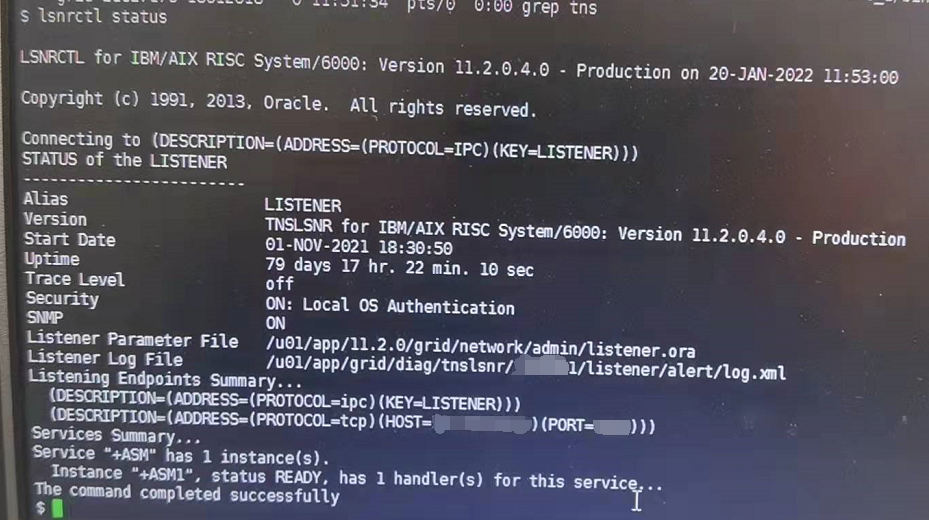
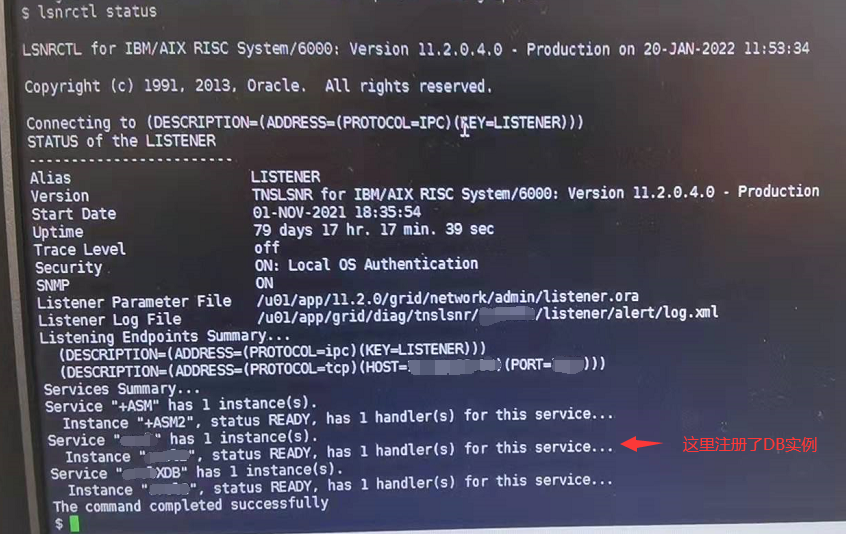
节点1的监听没有实例注册,并且此监听只注册了VIP,节点2的监听注册了实例,但是也只注册了VIP,从这里就能体现出上面提出的故障问题:使用节点1的VIP连接数据库失败,报错 ORA-12514:TNS:监听程序当前无法识别连接描述符中请求的服务,使用所有节点的物理IP连接数据库报错 ORA-12541: TNS:无监听程序。
- 检查实例状态和参数
--两个节点数据库实例均为 READ WRITE 状态
select open_mode from v$database;
--检查local_listener参数
show parameter listener
复制节点1

节点2

节点1 local_listener 参数为空,所以实例没有注册到监听上,重启数据库为啥一个实例配置了参数值,一个实例没有配置参数值呢?
-- 检查一下pfile是否用的同一个
show parameter pfile
-- 经检查pfile也是用的同一个
复制- 那就手动修改一下节点1的 local_listener 参数,解决客户提出的问题。
alter system set local_listener = '(address = (protocol = tcp)(host = 1.1.1.1)(port = 1111))' sid='xx1';
复制配置参数后,节点1的实例注册到监听上了,业务连接VIP可以正常连接数据库了。
那么另一个问题,监听为什么没有注册物理IP,使用所有节点的物理IP连接数据库报错 ORA-12541: TNS:无监听程序,怀疑跟 ora.crsd 资源异常有关系,跟客户要了集群的alter日志和crsd的日志继续分析。
继续分析 ora.crsd 资源异常问题
- 分析集群的alter日志
节点1 /u01/app/11.2.0/grid/log/node1/alternode1.log
2021-11-01 18:30:34.323:
[evmd(9109594)]CRS-1401:EVMD started on node node1.
2021-11-01 18:30:36.650:
# 这里 CRSD 是正常启动成功的
[crsd(10092766)]CRS-1201:CRSD started on node node1.
2021-11-01 18:30:45.538:
[crsd(10092766)]CRS-2772:Server 'node1' has been assigned to pool 'Generic'.
2021-11-01 18:30:45.572:
[crsd(10092766)]CRS-2772:Server 'node1' has been assigned to pool 'ora.orcl'.
... ...
2021-11-17 01:05:44.483:
[gpnpd(7733360)]CRS-2340:Errors occurred while processing received gpnp message.
2021-11-20 05:36:11.591:
[gpnpd(7733360)]CRS-2340:Errors occurred while processing received gpnp message.
2021-11-22 05:53:06.120:
[gpnpd(7733360)]CRS-2340:Errors occurred while processing received gpnp message.
2021-11-27 20:51:29.212:
[gpnpd(7733360)]CRS-2340:Errors occurred while processing received gpnp message.
2021-12-03 15:17:52.373:
[gpnpd(7733360)]CRS-2340:Errors occurred while processing received gpnp message.
2021-12-04 03:28:23.664:
[gpnpd(7733360)]CRS-2340:Errors occurred while processing received gpnp message.
2021-12-05 22:14:47.650:
[gpnpd(7733360)]CRS-2340:Errors occurred while processing received gpnp message.
2021-12-11 19:47:36.341:
[gpnpd(7733360)]CRS-2340:Errors occurred while processing received gpnp message.
2021-12-11 22:11:16.501:
[gpnpd(7733360)]CRS-2340:Errors occurred while processing received gpnp message.
# 这里可以发现 ora.OCR_VOTE.dg 出现了问题
2021-12-15 03:01:19.840:
[crsd(10092766)]CRS-2765:Resource 'ora.OCR_VOTE.dg' has failed on server 'node1'.
2021-12-15 03:01:20.139:
[crsd(10092766)]CRS-2878:Failed to restart resource 'ora.OCR_VOTE.dg'
2021-12-15 03:01:20.148:
[crsd(10092766)]CRS-2769:Unable to failover resource 'ora.OCR_VOTE.dg'.
2021-12-15 06:46:50.947:
[crsd(10092766)]CRS-1006:The OCR location +OCR_VOTE is inaccessible. Details in /u01/app/11.2.0/grid/log/node1/crsd/crsd.log.
2021-12-15 06:46:50.949:
[crsd(10092766)]CRS-1006:The OCR location +OCR_VOTE is inaccessible. Details in /u01/app/11.2.0/grid/log/node1/crsd/crsd.log.
# 导致资源 ora.crsd 也出现了问题
2021-12-15 06:47:03.092:
[ohasd(3735758)]CRS-2765:Resource 'ora.crsd' has failed on server 'node1'.
2021-12-15 06:47:03.115:
[/u01/app/11.2.0/grid/bin/orarootagent.bin(13041806)]CRS-5822:Agent '/u01/app/11.2.0/grid/bin/orarootagent_root' disconnected from server. Details at (:CRSAGF00117:) {0:3:34766} in /u01/app/11.2.0/grid/log/node1/agent/crsd/orarootagent_root/orarootagent_root.log.
2021-12-15 06:47:03.127:
[/u01/app/11.2.0/grid/bin/scriptagent.bin(12320904)]CRS-5822:Agent '/u01/app/11.2.0/grid/bin/scriptagent_grid' disconnected from server. Details at (:CRSAGF00117:) {0:9:4} in /u01/app/11.2.0/grid/log/node1/agent/crsd/scriptagent_grid/scriptagent_grid.log.
2021-12-15 06:47:03.135:
[/u01/app/11.2.0/grid/bin/oraagent.bin(10879164)]CRS-5822:Agent '/u01/app/11.2.0/grid/bin/oraagent_oracle' disconnected from server. Details at (:CRSAGF00117:) {0:11:4567} in /u01/app/11.2.0/grid/log/node1/agent/crsd/oraagent_oracle/oraagent_oracle.log.
2021-12-15 06:47:03.135:
[/u01/app/11.2.0/grid/bin/oraagent.bin(12648584)]CRS-5822:Agent '/u01/app/11.2.0/grid/bin/oraagent_grid' disconnected from server. Details at (:CRSAGF00117:) {0:1:9} in /u01/app/11.2.0/grid/log/node1/agent/crsd/oraagent_grid/oraagent_grid.log.
2021-12-15 06:47:04.669:
[crsd(51052572)]CRS-1013:The OCR location in an ASM disk group is inaccessible. Details in /u01/app/11.2.0/grid/log/node1/crsd/crsd.log.
2021-12-15 06:47:04.723:
[crsd(51052572)]CRS-0804:Cluster Ready Service aborted due to Oracle Cluster Registry error [PROC-26: Error while accessing the physical storage
]. Details at (:CRSD00111:) in /u01/app/11.2.0/grid/log/node1/crsd/crsd.log.
2021-12-15 06:47:05.212:
[ohasd(3735758)]CRS-2765:Resource 'ora.crsd' has failed on server 'node1'.
2021-12-15 06:47:06.713:
[crsd(1245502)]CRS-1013:The OCR location in an ASM disk group is inaccessible. Details in /u01/app/11.2.0/grid/log/node1/crsd/crsd.log.
复制节点2 /u01/app/11.2.0/grid/log/node2/alternode2.log
2021-11-01 18:35:39.122:
[evmd(10027094)]CRS-1401:EVMD started on node node2.
# 这里 CRSD 是正常启动成功的
2021-11-01 18:35:41.530:
[crsd(12124276)]CRS-1201:CRSD started on node node2.
... ...
# 导致资源 ora.crsd 也出现了问题,和节点1几乎相同的时间点
2021-12-15 06:47:04.357:
[ohasd(5570634)]CRS-2765:Resource 'ora.crsd' has failed on server 'node2'.
2021-12-15 06:47:04.372:
[/u01/app/11.2.0/grid/bin/orarootagent.bin(12583042)]CRS-5822:Agent '/u01/app/11.2.0/grid/bin/orarootagent_root' disconnected from server. Details at (:CRSAGF00117:) {0:3:6702} in /u01/app/11.2.0/grid/log/node2/agent/crsd/orarootagent_root/orarootagent_root.log.
2021-12-15 06:47:04.374:
[/u01/app/11.2.0/grid/bin/oraagent.bin(13041828)]CRS-5822:Agent '/u01/app/11.2.0/grid/bin/oraagent_oracle' disconnected from server. Details at (:CRSAGF00117:) {0:7:1457} in /u01/app/11.2.0/grid/log/node2/agent/crsd/oraagent_oracle/oraagent_oracle.log.
2021-12-15 06:47:04.374:
[/u01/app/11.2.0/grid/bin/oraagent.bin(12320902)]CRS-5822:Agent '/u01/app/11.2.0/grid/bin/oraagent_grid' disconnected from server. Details at (:CRSAGF00117:) {0:1:7} in /u01/app/11.2.0/grid/log/node2/agent/crsd/oraagent_grid/oraagent_grid.log.
2021-12-15 06:47:05.953:
[crsd(17432590)]CRS-1013:The OCR location in an ASM disk group is inaccessible. Details in /u01/app/11.2.0/grid/log/node2/crsd/crsd.log.
2021-12-15 06:47:06.041:
[crsd(17432590)]CRS-0804:Cluster Ready Service aborted due to Oracle Cluster Registry error [PROC-26: Error while accessing the physical storage
]. Details at (:CRSD00111:) in /u01/app/11.2.0/grid/log/node2/crsd/crsd.log.
2021-12-15 06:47:06.465:
[ohasd(5570634)]CRS-2765:Resource 'ora.crsd' has failed on server 'node2'.
2021-12-15 06:47:07.964:
[crsd(12189816)]CRS-1013:The OCR location in an ASM disk group is inaccessible. Details in /u01/app/11.2.0/grid/log/node2/crsd/crsd.log.
2021-12-15 06:47:08.011:
[crsd(12189816)]CRS-0804:Cluster Ready Service aborted due to Oracle Cluster Registry error [PROC-26: Error while accessing the physical storage
]. Details at (:CRSD00111:) in /u01/app/11.2.0/grid/log/node2/crsd/crsd.log.
2021-12-15 06:47:08.522:
[ohasd(5570634)]CRS-2765:Resource 'ora.crsd' has failed on server 'node2'.
复制所以可以看出来 ora.OCR_VOTE.dg 资源出现了问题导致ora.crsd资源也出现了问题。
- 分析 crsd.log 日志
/u01/app/11.2.0/grid/log/node1/crsd/crsd.log
2021-12-15 03:00:20.226: [UiServer][12339] CS(112f8ce10)set Properties ( grid,1131b53f0)
2021-12-15 03:00:20.237: [UiServer][12082]{1:34635:15443} Sending message to PE. ctx= 110f51cd0, Client PID: 12648584
2021-12-15 03:00:20.238: [ CRSPE][11825]{1:34635:15443} Processing PE command id=81015. Description: [Stat Resource : 1132bcb10]
2021-12-15 03:00:20.238: [ CRSPE][11825]{1:34635:15443} Expression Filter : ((NAME == ora.scan1.vip) AND (LAST_SERVER == node1))
2021-12-15 03:00:20.245: [UiServer][12082]{1:34635:15443} Done for ctx=110f51cd0
2021-12-15 03:01:19.806: [ AGFW][10540]{0:1:4} Agfw Proxy Server received the message: RESOURCE_STATUS[Proxy] ID 20481:994989
2021-12-15 03:01:19.806: [ AGFW][10540]{0:1:4} Verifying msg rid = ora.OCR_VOTE.dg node1 1
# 这里发现 ora.OCR_VOTE.dg 开始 OFFLINE
2021-12-15 03:01:19.806: [ AGFW][10540]{0:1:4} Received state change for ora.OCR_VOTE.dg node1 1 [old state = ONLINE, new state = OFFLINE]
2021-12-15 03:01:19.810: [ AGFW][10540]{0:1:4} Agfw Proxy Server sending message to PE, Contents = [MIDTo:2|OpID:3|FromA:{Invalid|Node:0|Process:0|Type:0}|ToA:{Invalid|Node:-1|Process:-1|Type:-1}|MIDFrom:0|Type:4|Pri2|Id:1679694:Ver:2]
2021-12-15 03:01:19.810: [ AGFW][10540]{0:1:4} Agfw Proxy Server replying to the message: RESOURCE_STATUS[Proxy] ID 20481:994989
2021-12-15 03:01:19.814: [ CRSPE][11825]{0:1:4} State change received from node1 for ora.OCR_VOTE.dg node1 1
2021-12-15 03:01:19.825: [ CRSPE][11825]{0:1:4} Processing PE command id=81016. Description: [Resource State Change (ora.OCR_VOTE.dg node1 1) : 110f4fbb0]
2021-12-15 03:01:19.839: [ CRSPE][11825]{0:1:4} RI [ora.OCR_VOTE.dg node1 1] new external state [OFFLINE] old value: [ONLINE] on node1 label = []
2021-12-15 03:01:19.840: [ CRSD][11825]{0:1:4} {0:1:4} Resource Resource Instance ID[ora.OCR_VOTE.dg node1 1]. Values:
STATE=OFFLINE
TARGET=ONLINE
LAST_SERVER=node1
CURRENT_RCOUNT=0
LAST_RESTART=0
FAILURE_COUNT=0
FAILURE_HISTORY=
STATE_DETAILS=
INCARNATION=1
STATE_CHANGE_VERS=0
LAST_FAULT=0
LAST_STATE_CHANGE=1639508479
INTERNAL_STATE=0
DEGREE_ID=1
ID=ora.OCR_VOTE.dg node1 1
Lock Info:
Write Locks:none
ReadLocks:|STATE INITED||INITIAL CHECK DONE| has failed!
2021-12-15 03:01:19.841: [ CRSRPT][12082]{0:1:4} Published to EVM CRS_RESOURCE_STATE_CHANGE for ora.OCR_VOTE.dg
2021-12-15 03:01:19.846: [ CRSPE][11825]{0:1:4} Processing unplanned state change for [ora.OCR_VOTE.dg node1 1]
2021-12-15 03:01:19.862: [ CRSPE][11825]{0:1:4} Scheduled local recovery for [ora.OCR_VOTE.dg node1 1]
2021-12-15 03:01:19.872: [ CRSPE][11825]{0:1:4} Op 112f8ce10 has 5 WOs
2021-12-15 03:01:19.883: [ CRSPE][11825]{0:1:4} RI [ora.OCR_VOTE.dg node1 1] new internal state: [STARTING] old value: [STABLE]
2021-12-15 03:01:19.883: [ CRSPE][11825]{0:1:4} Sending message to agfw: id = 1679696
2021-12-15 03:01:19.883: [ AGFW][10540]{0:1:4} Agfw Proxy Server received the message: RESOURCE_START[ora.OCR_VOTE.dg node1 1] ID 4098:1679696
2021-12-15 03:01:19.883: [ CRSPE][11825]{0:1:4} CRS-2672: Attempting to start 'ora.OCR_VOTE.dg' on 'node1'
2021-12-15 03:01:19.884: [ AGFW][10540]{0:1:4} Agfw Proxy Server forwarding the message: RESOURCE_START[ora.OCR_VOTE.dg node1 1] ID 4098:1679696 to the agent /u01/app/11.2.0/grid/bin/oraagent_grid
2021-12-15 03:01:20.049: [ AGFW][10540]{0:1:4} Received the reply to the message: RESOURCE_START[ora.OCR_VOTE.dg node1 1] ID 4098:1679697 from the agent /u01/app/11.2.0/grid/bin/oraagent_grid
2021-12-15 03:01:20.050: [ AGFW][10540]{0:1:4} Agfw Proxy Server sending the reply to PE for message:RESOURCE_START[ora.OCR_VOTE.dg node1 1] ID 4098:1679696
2021-12-15 03:01:20.050: [ CRSPE][11825]{0:1:4} Received reply to action [Start] message ID: 1679696
2021-12-15 03:01:20.120: [ AGFW][10540]{0:1:4} Received the reply to the message: RESOURCE_START[ora.OCR_VOTE.dg node1 1] ID 4098:1679697 from the agent /u01/app/11.2.0/grid/bin/oraagent_grid
2021-12-15 03:01:20.120: [ AGFW][10540]{0:1:4} Agfw Proxy Server sending the last reply to PE for message:RESOURCE_START[ora.OCR_VOTE.dg node1 1] ID 4098:1679696
2021-12-15 03:01:20.120: [ CRSPE][11825]{0:1:4} Received reply to action [Start] message ID: 1679696
2021-12-15 03:01:20.120: [ CRSPE][11825]{0:1:4} RI [ora.OCR_VOTE.dg node1 1] new internal state: [STABLE] old value: [STARTING]
# 资源 ora.OCR_VOTE.dg 启动失败
2021-12-15 03:01:20.120: [ CRSPE][11825]{0:1:4} CRS-2674: Start of 'ora.OCR_VOTE.dg' on 'node1' failed
2021-12-15 03:01:20.121: [ CRSPE][11825]{0:1:4} Sequencer for [ora.OCR_VOTE.dg node1 1] has completed with error: CRS-0215: Could not start resource 'ora.OCR_VOTE.dg'.
2021-12-15 03:01:20.121: [ CRSPE][11825]{0:1:4} Starting resource state restoration for: START of [ora.OCR_VOTE.dg node1 1] on [node1] : local=1, unplanned=0112f8ce10
2021-12-15 03:01:20.139: [ CRSD][11825]{0:1:4} {0:1:4} Created alert : (:CRSPE00190:) : Resource restart failed!
2021-12-15 03:01:20.147: [ CRSPE][11825]{0:1:4} RIs of this resource are not relocatable:ora.OCR_VOTE.dg: failover impossible
2021-12-15 03:01:20.148: [ CRSD][11825]{0:1:4} {0:1:4} Created alert : (:CRSPE00191:) : Failover cannot be completed for [ora.OCR_VOTE.dg node1 1]. Stopping it and the resource tree
2021-12-15 03:01:20.164: [ CRSPE][11825]{0:1:4} Op 1132bcb10 has 5 WOs
2021-12-15 03:01:20.171: [ CRSPE][11825]{0:1:4} PE Command [ Resource State Change (ora.OCR_VOTE.dg node1 1) : 110f4fbb0 ] has completed
2021-12-15 03:01:20.171: [ AGFW][10540]{0:1:4} Agfw Proxy Server received the message: CMD_COMPLETED[Proxy] ID 20482:1679700
2021-12-15 03:01:20.171: [ AGFW][10540]{0:1:4} Agfw Proxy Server replying to the message: CMD_COMPLETED[Proxy] ID 20482:1679700
2021-12-15 03:01:20.171: [ AGFW][10540]{0:1:4} Agfw received reply from PE for resource state change for ora.OCR_VOTE.dg node1 1
... ...
2021-12-15 03:01:20.121: [ CRSPE][11825]{0:1:4} Starting resource state restoration for: START of [ora.OCR_VOTE.dg node1 1] on [node1] : local=1, unplanned=0112f8ce10
2021-12-15 03:01:20.139: [ CRSD][11825]{0:1:4} {0:1:4} Created alert : (:CRSPE00190:) : Resource restart failed!
2021-12-15 03:01:20.147: [ CRSPE][11825]{0:1:4} RIs of this resource are not relocatable:ora.OCR_VOTE.dg: failover impossible
2021-12-15 03:01:20.148: [ CRSD][11825]{0:1:4} {0:1:4} Created alert : (:CRSPE00191:) : Failover cannot be completed for [ora.OCR_VOTE.dg node1 1]. Stopping it and the resource tree
2021-12-15 03:01:20.164: [ CRSPE][11825]{0:1:4} Op 1132bcb10 has 5 WOs
2021-12-15 03:01:20.171: [ CRSPE][11825]{0:1:4} PE Command [ Resource State Change (ora.OCR_VOTE.dg node1 1) : 110f4fbb0 ] has completed
2021-12-15 03:01:20.171: [ AGFW][10540]{0:1:4} Agfw Proxy Server received the message: CMD_COMPLETED[Proxy] ID 20482:1679700
2021-12-15 03:01:20.171: [ AGFW][10540]{0:1:4} Agfw Proxy Server replying to the message: CMD_COMPLETED[Proxy] ID 20482:1679700
2021-12-15 03:01:20.171: [ AGFW][10540]{0:1:4} Agfw received reply from PE for resource state change for ora.OCR_VOTE.dg node1 1
2021-12-15 03:01:20.232: [UiServer][12339] CS(1132bb190)set Properties ( grid,1132bbcd0)
2021-12-15 03:01:20.243: [UiServer][12082]{1:34635:15444} Sending message to PE. ctx= 110f4fe30, Client PID: 12648584
2021-12-15 03:01:20.243: [ CRSPE][11825]{1:34635:15444} Processing PE command id=81017. Description: [Stat Resource : 1132bc0b0]
2021-12-15 03:01:20.244: [ CRSPE][11825]{1:34635:15444} Expression Filter : ((NAME == ora.scan1.vip) AND (LAST_SERVER == node1))
2021-12-15 03:01:20.251: [UiServer][12082]{1:34635:15444} Done for ctx=110f4fe30
2021-12-15 03:01:26.010: [UiServer][12339] CS(11346e410)set Properties ( root,11346d410)
2021-12-15 03:01:26.021: [UiServer][12082]{1:34635:15445} Sending message to PE. ctx= 110f50090, Client PID: 9699388
2021-12-15 03:01:26.022: [ CRSPE][11825]{1:34635:15445} Processing PE command id=81018. Description: [Stat Resource : 114168570]
2021-12-15 03:01:26.023: [UiServer][12082]{1:34635:15445} Done for ctx=110f50090
2021-12-15 03:01:47.396: [ CRSPE][11825]{2:26524:113} Cmd : 112f89450 : flags: EVENT_TAG | FORCE_TAG | QUEUE_TAG
2021-12-15 03:01:47.401: [ CRSPE][11825]{2:26524:113} Processing PE command id=169. Description: [Stop Resource : 112f89450]
2021-12-15 03:01:47.419: [ CRSPE][11825]{2:26524:113} Expression Filter : (((NAME == ora.OCR_VOTE.dg) AND (LAST_SERVER == node2)) AND (STATE != OFFLINE))
2021-12-15 03:01:47.420: [ CRSPE][11825]{2:26524:113} Expression Filter : (((NAME == ora.OCR_VOTE.dg) AND (LAST_SERVER == node2)) AND (STATE != OFFLINE))
2021-12-15 03:01:47.427: [ CRSPE][11825]{2:26524:113} Attribute overrides for the command: USR_ORA_OPI = true;
2021-12-15 03:01:47.431: [ CRSPE][11825]{2:26524:113} Filtering duplicate ops: server [] state [OFFLINE]
2021-12-15 03:01:47.432: [ CRSPE][11825]{2:26524:113} Op 1131aae10 has 5 WOs
2021-12-15 03:01:47.433: [ CRSPE][11825]{2:26524:113} RI [ora.OCR_VOTE.dg node2 1] new target state: [OFFLINE] old value: [ONLINE]
2021-12-15 03:01:47.436: [ CRSOCR][11054]{2:26524:113} Multi Write Batch processing...
2021-12-15 03:01:47.437: [ CRSPE][11825]{2:26524:113} RI [ora.OCR_VOTE.dg node2 1] new internal state: [STOPPING] old value: [STABLE]
2021-12-15 03:01:47.437: [ CRSPE][11825]{2:26524:113} Sending message to agfw: id = 1679716
# 自动把节点2的资源 ora.OCR_VOTE.dg 给停了
2021-12-15 03:01:47.437: [ CRSPE][11825]{2:26524:113} CRS-2673: Attempting to stop 'ora.OCR_VOTE.dg' on 'node2'
... ...
2021-12-15 03:01:47.447: [ CRSPE][11825]{2:26524:113} Received reply to action [Stop] message ID: 1679716
2021-12-15 03:01:47.486: [ CRSOCR][11054]{2:26524:113} Multi Write Batch done.
2021-12-15 03:01:47.519: [ CRSPE][11825]{2:26524:113} Received reply to action [Stop] message ID: 1679716
2021-12-15 03:01:47.519: [ CRSPE][11825]{2:26524:113} RI [ora.OCR_VOTE.dg node2 1] new internal state: [STABLE] old value: [STOPPING]
2021-12-15 03:01:47.519: [ CRSPE][11825]{2:26524:113} RI [ora.OCR_VOTE.dg node2 1] new external state [OFFLINE] old value: [ONLINE] label = []
# 节点2的资源 ora.OCR_VOTE.dg 停止成功
2021-12-15 03:01:47.520: [ CRSPE][11825]{2:26524:113} CRS-2677: Stop of 'ora.OCR_VOTE.dg' on 'node2' succeeded
复制- 分析ASM alert日志
节点1 /u01/app/grid/diag/asm/+asm/+ASM1/trace/alert_+ASM1.log
Wed Dec 15 03:01:04 2021
WARNING: Waited 15 secs for write IO to PST disk 0 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 1 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 2 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 0 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 1 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 2 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 0 in group 4.
WARNING: Waited 15 secs for write IO to PST disk 0 in group 4.
# ASM磁盘组 PST 心跳超时(默认15s),将磁盘组offline
# 参考MOS文章:ASM diskgroup dismount with "Waited 15 secs for write IO to PST" (Doc ID 1581684.1)
Wed Dec 15 03:01:04 2021
NOTE: process _b000_+asm1 (15728952) initiating offline of disk 0.3843512884 (OCR_VOTE_0000) with mask 0x7e in group 3
NOTE: process _b000_+asm1 (15728952) initiating offline of disk 1.3843512885 (OCR_VOTE_0001) with mask 0x7e in group 3
NOTE: process _b000_+asm1 (15728952) initiating offline of disk 2.3843512886 (OCR_VOTE_0002) with mask 0x7e in group 3
NOTE: checking PST: grp = 3
GMON checking disk modes for group 3 at 17 for pid 27, osid 15728952
ERROR: no read quorum in group: required 2, found 0 disks
NOTE: checking PST for grp 3 done.
NOTE: initiating PST update: grp = 3, dsk = 0/0xe5175a34, mask = 0x6a, op = clear
NOTE: initiating PST update: grp = 3, dsk = 1/0xe5175a35, mask = 0x6a, op = clear
NOTE: initiating PST update: grp = 3, dsk = 2/0xe5175a36, mask = 0x6a, op = clear
GMON updating disk modes for group 3 at 18 for pid 27, osid 15728952
ERROR: no read quorum in group: required 2, found 0 disks
Wed Dec 15 03:01:04 2021
NOTE: cache dismounting (not clean) group 3/0xC137A90B (OCR_VOTE)
NOTE: messaging CKPT to quiesce pins Unix process pid: 17564158, image: oracle@node1 (B001)
Wed Dec 15 03:01:04 2021
NOTE: halting all I/Os to diskgroup 3 (OCR_VOTE)
Wed Dec 15 03:01:04 2021
NOTE: LGWR doing non-clean dismount of group 3 (OCR_VOTE)
NOTE: LGWR sync ABA=96.297 last written ABA 96.297
# Offline failed
WARNING: Offline for disk OCR_VOTE_0000 in mode 0x7f failed.
WARNING: Offline for disk OCR_VOTE_0001 in mode 0x7f failed.
WARNING: Offline for disk OCR_VOTE_0002 in mode 0x7f failed.
Wed Dec 15 03:01:05 2021
kjbdomdet send to inst 2
detach from dom 3, sending detach message to inst 2
Wed Dec 15 03:01:05 2021
List of instances:
1 2
Dirty detach reconfiguration started (new ddet inc 1, cluster inc 4)
Wed Dec 15 03:01:05 2021
NOTE: No asm libraries found in the system
Global Resource Directory partially frozen for dirty detach
* dirty detach - domain 3 invalid = TRUE
0 GCS resources traversed, 0 cancelled
Dirty Detach Reconfiguration complete
Wed Dec 15 03:01:05 2021
ERROR: ORA-15130 in COD recovery for diskgroup 3/0xc137a90b (OCR_VOTE)
ERROR: ORA-15130 thrown in RBAL for group number 3
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_rbal_11927660.trc:
ORA-15130: diskgroup "OCR_VOTE" is being dismounted
Wed Dec 15 03:01:05 2021
WARNING: dirty detached from domain 3
NOTE: cache dismounted group 3/0xC137A90B (OCR_VOTE)
NOTE: cache deleting context for group OCR_VOTE 3/0xc137a90b
# 强制 dismount OCR_VOTE
SQL> alter diskgroup OCR_VOTE dismount force /* ASM SERVER:3241650443 */
GMON dismounting group 3 at 19 for pid 29, osid 17564158
NOTE: Disk OCR_VOTE_0000 in mode 0x7f marked for de-assignment
NOTE: Disk OCR_VOTE_0001 in mode 0x7f marked for de-assignment
NOTE: Disk OCR_VOTE_0002 in mode 0x7f marked for de-assignment
NOTE:Waiting for all pending writes to complete before de-registering: grpnum 3
WARNING: Waited 15 secs for write IO to PST disk 0 in group 1.
WARNING: Waited 15 secs for write IO to PST disk 0 in group 1.
Wed Dec 15 03:01:19 2021
SQL> ALTER DISKGROUP OCR_VOTE MOUNT /* asm agent *//* {0:1:4} */
WARNING: Disk Group OCR_VOTE containing spfile for this instance is not mounted
WARNING: Disk Group OCR_VOTE containing configured OCR is not mounted
WARNING: Disk Group OCR_VOTE containing voting files is not mounted
ORA-15032: not all alterations performed
ORA-15017: diskgroup "OCR_VOTE" cannot be mounted
ORA-15013: diskgroup "OCR_VOTE" is already mounted
ERROR: ALTER DISKGROUP OCR_VOTE MOUNT /* asm agent *//* {0:1:4} */
Wed Dec 15 03:01:21 2021
Received dirty detach msg from inst 2 for dom 3
Wed Dec 15 03:01:21 2021
List of instances:
1 2
Dirty detach reconfiguration started (new ddet inc 2, cluster inc 4)
Global Resource Directory partially frozen for dirty detach
* dirty detach - domain 3 invalid = TRUE
0 GCS resources traversed, 0 cancelled
freeing rdom 3
Dirty Detach Reconfiguration complete
Wed Dec 15 03:01:35 2021
NOTE:Waiting for all pending writes to complete before de-registering: grpnum 3
Wed Dec 15 03:01:47 2021
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15079: ASM file is closed
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15079: ASM file is closed
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15079: ASM file is closed
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15079: ASM file is closed
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15079: ASM file is closed
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15079: ASM file is closed
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15079: ASM file is closed
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15079: ASM file is closed
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15079: ASM file is closed
Wed Dec 15 03:01:47 2021
ASM Health Checker found 1 new failures
# 磁盘组 OCR_VOTE dismounted
Wed Dec 15 03:02:05 2021
SUCCESS: diskgroup OCR_VOTE was dismounted
SUCCESS: alter diskgroup OCR_VOTE dismount force /* ASM SERVER:3241650443 */
SUCCESS: ASM-initiated MANDATORY DISMOUNT of group OCR_VOTE
# 资源 ora.OCR_VOTE.dg is offline
Wed Dec 15 03:02:05 2021
NOTE: diskgroup resource ora.OCR_VOTE.dg is offline
Wed Dec 15 06:46:50 2021
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15078: ASM diskgroup was forcibly dismounted
WARNING: requested mirror side 1 of virtual extent 6 logical extent 0 offset 720896 is not allocated; I/O request failed
WARNING: requested mirror side 2 of virtual extent 6 logical extent 1 offset 720896 is not allocated; I/O request failed
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_ora_12386428.trc:
ORA-15078: ASM diskgroup was forcibly dismounted
ORA-15078: ASM diskgroup was forcibly dismounted
Wed Dec 15 06:46:50 2021
SQL> alter diskgroup OCR_VOTE check /* proxy */
ORA-15032: not all alterations performed
ORA-15001: diskgroup "OCR_VOTE" does not exist or is not mounted
ERROR: alter diskgroup OCR_VOTE check /* proxy */
Wed Dec 15 06:47:03 2021
NOTE: client exited [10092766]
Wed Dec 15 06:47:04 2021
NOTE: [crsd.bin@node1 (TNS V1-V3) 51052572] opening OCR file
Wed Dec 15 06:47:06 2021
NOTE: [crsd.bin@node1 (TNS V1-V3) 1245502] opening OCR file
复制- 检查操作系统日志
AIX 检查操作系统日志的命令是 errpt,经检查没有日志输出。 - OCR_VOTE磁盘组异常,就要检查下表决盘和OCR
crsctl query css votedisk ocrcheck复制
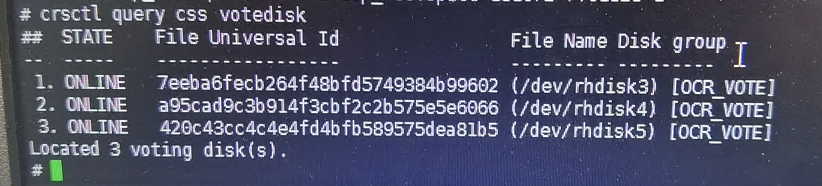

- 检查磁盘状态
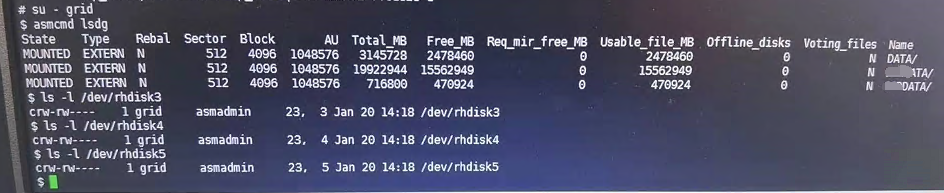
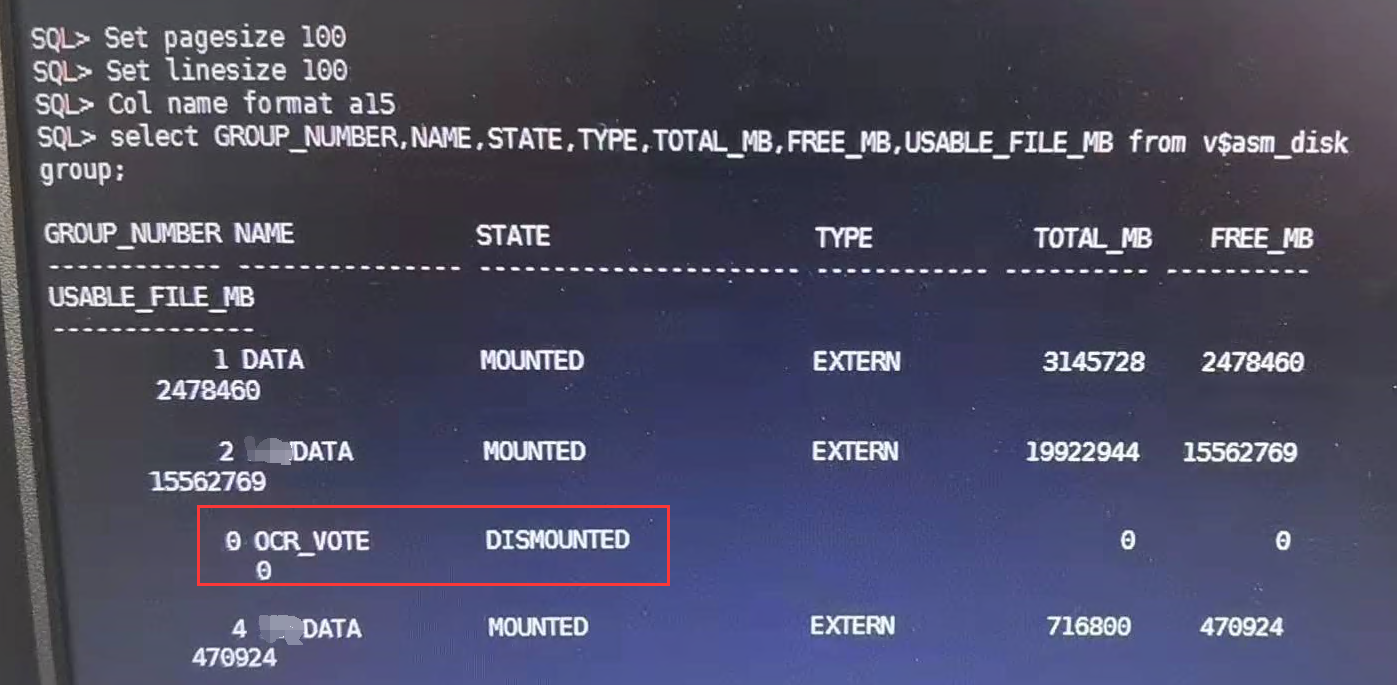
所有节点的磁盘属组和权限都正常,asmcmd中不显示 OCR_VOTE 磁盘组。 - 通过视图查看磁盘组处于 DISMOUNTED 状态
临时解决问题,启动 ora.crsd 资源
- mount 磁盘组 OCR_VOTE (所有节点)
su - grid
sqlplus / as sysasm
alter diskgroup ocr_vote mount;
复制- 启动 ora.crsd 资源
su - grid
crsctl start resource "ora.crsd" -init
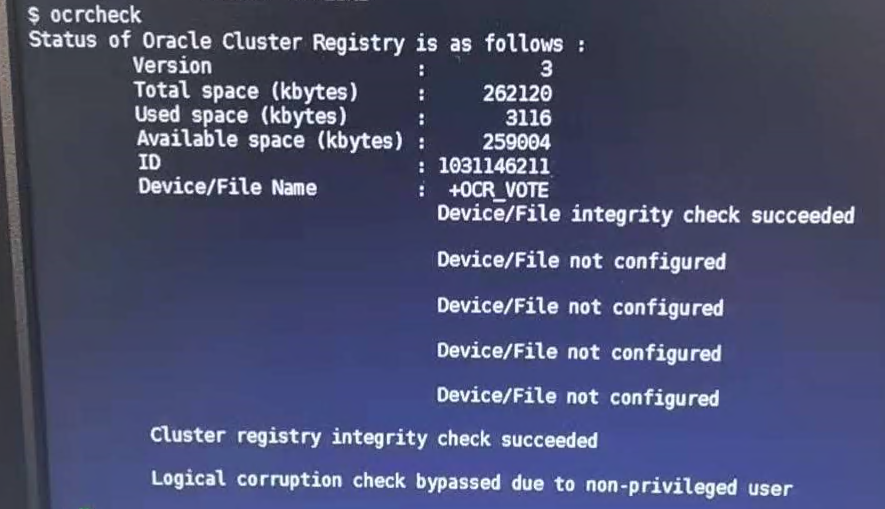
复制- 检查
ocrcheck 显示正常
crscrl status res -t 显示正常
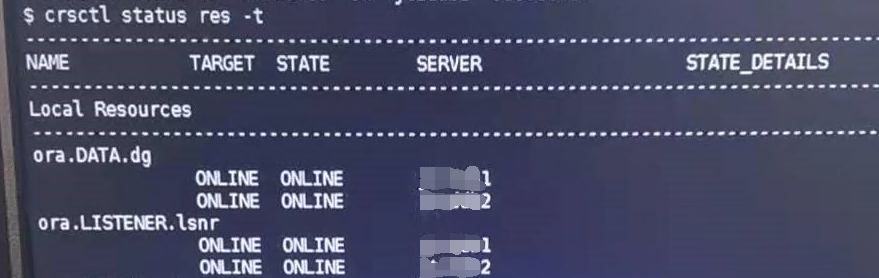
监听也显示正常,并且注册了物理IP地址,解决了 物理IP连接数据库报错 ORA-12541: TNS:无监听程序
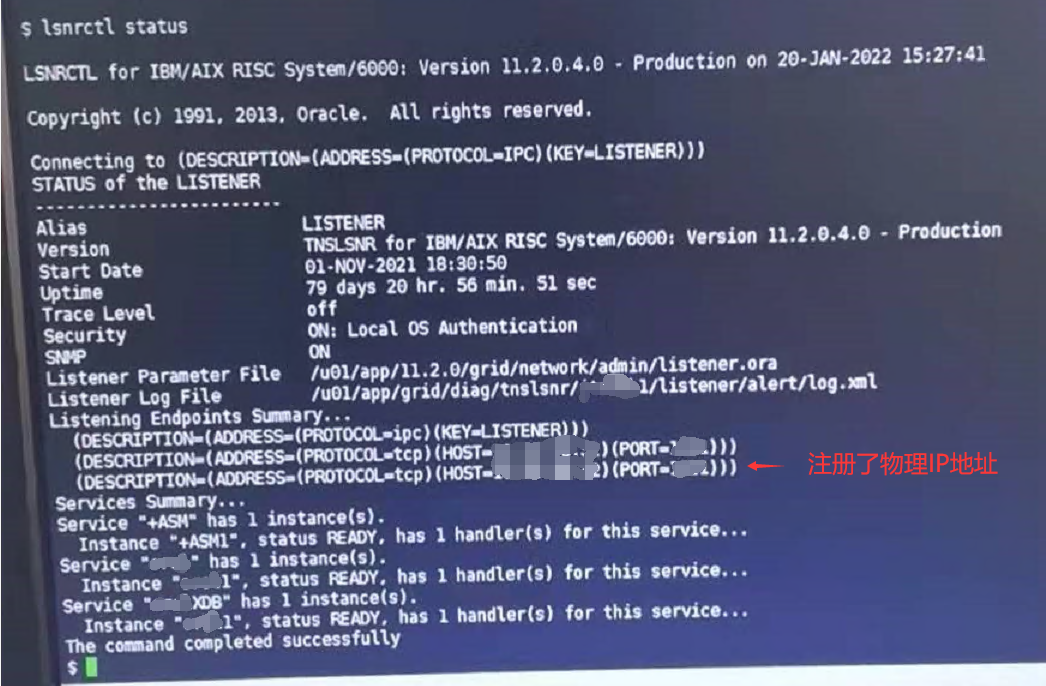
客户测试,一切正常。
根据 MOS 分析磁盘组 OCR_VOTE DISMOUNTED 问题
- ASM alert日志:
Wed Dec 15 03:01:04 2021
WARNING: Waited 15 secs for write IO to PST disk 0 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 1 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 2 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 0 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 1 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 2 in group 3.
WARNING: Waited 15 secs for write IO to PST disk 0 in group 4.
WARNING: Waited 15 secs for write IO to PST disk 0 in group 4.
Wed Dec 15 03:01:04 2021
NOTE: process _b000_+asm1 (15728952) initiating offline of disk 0.3843512884 (OCR_VOTE_0000) with mask 0x7e in group 3
NOTE: process _b000_+asm1 (15728952) initiating offline of disk 1.3843512885 (OCR_VOTE_0001) with mask 0x7e in group 3
NOTE: process _b000_+asm1 (15728952) initiating offline of disk 2.3843512886 (OCR_VOTE_0002) with mask 0x7e in group 3
NOTE: checking PST: grp = 3
GMON checking disk modes for group 3 at 17 for pid 27, osid 15728952
ERROR: no read quorum in group: required 2, found 0 disks
NOTE: checking PST for grp 3 done.
NOTE: initiating PST update: grp = 3, dsk = 0/0xe5175a34, mask = 0x6a, op = clear
NOTE: initiating PST update: grp = 3, dsk = 1/0xe5175a35, mask = 0x6a, op = clear
NOTE: initiating PST update: grp = 3, dsk = 2/0xe5175a36, mask = 0x6a, op = clear
GMON updating disk modes for group 3 at 18 for pid 27, osid 15728952
ERROR: no read quorum in group: required 2, found 0 disks
复制-
MOS 文章:ASM diskgroup dismount with “Waited 15 secs for write IO to PST” (Doc ID 1581684.1)
-
通常这种消息在以下情况下出现在 ASM alert日志文件中:
Delayed ASM PST heart beats on ASM disks in normal or high redundancy diskgroup,causes the affected disks to go offline.By default, it is 15 seconds.
Diskgroup will get dismounted if ASM cannot issue the PST heart beat to majority of the PST copies in a diskgroup with respect to redundancy.
i.e. Normal redundancy diskgroup will get dismounted if it failed to update two of the copies.
By the way the heart beat delays are sort of ignored for external redundancy diskgroup.
ASM instance stop issuing more PST heart beat until it succeeds PST revalidation,but the heart beat delays do not dismount external redundancy diskgroup directly.
- ASM 磁盘可能会无响应,通常在以下情况下:
+ Some of the paths of the physical paths of the multipath device are offline or lost
+ During path 'failover' in a multipath set up
+ Server load, or any sort of storage/multipath/OS maintenance
复制The Doc ID 10109915.8 briefs about Bug 10109915(this fix introduce this underscore parameter). And the issue is with no OS/Storage tunable timeout mechanism in a case of a Hung NFS Server/Filer. And then _asm_hbeatiowait helps in setting the time out.
- 解决方案
1] Check with OS and Storage admin that there is disk unresponsiveness.
2] Possibly keep the disk responsiveness to below 15 seconds.
This will depend on various factors like
+ Operating System + Presence of Multipath ( and Multipath Type ) + Any kernel parameter复制
So you need to find out, what is the ‘maximum’ possible disk unresponsiveness for your set up.
For example, on AIX rw_timeout setting affects this and defaults to 30 seconds.
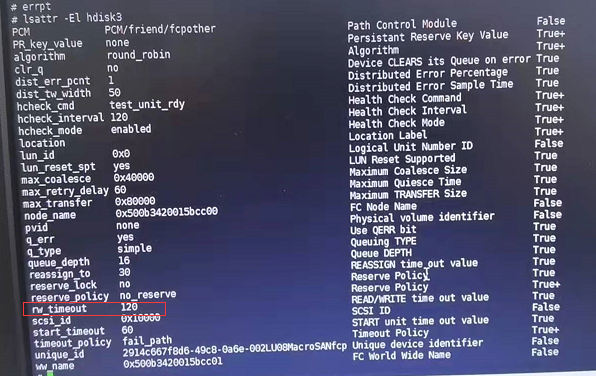
Another example is Linux with native multipathing. In such set up, number of physical paths and polling_interval value in multipath.conf file, will dictate this maximum disk unresponsiveness.
So for your set up ( combination of OS / multipath / storage ), you need to find out this.
3] If you can not keep the disk unresponsiveness to below 15 seconds, then the below parameter can be set in the ASM instance ( on all the Nodes of RAC ):
_asm_hbeatiowait复制
As per internal bug 17274537 , based on internal testing the value should be increased to 120 secs, which is fixed in 12.1.0.2
Run below in asm instance to set desired value for _asm_hbeatiowait
alter system set "_asm_hbeatiowait"=<value> scope=spfile sid='*';
复制And then restart asm instance / crs, to take new parameter value in effect.
Note:_asm_hbeatiowait parameter is valid from 11.2.0.3
