




磁盘组add disk,报错:ORA-15041 thrown in ARB0 for group number
在ASM中,每一个文件的extent都均匀的分布在它所在磁盘组的所有磁盘上,无论是在文件第一次创建或是文件创建之后的重新resize都是如此,这也意味着我们始终能保持磁盘组中的每一个磁盘上都有一个平衡的空间分配。
当我们ASM磁盘空间不够时,一般我们都会选择扩容,往磁盘组中添加新的磁盘,然后等待完成rebalance即可。但是,当我们没有注意到一些情况时,可能就会扩容失败。下面就说一种可能之前没有注意到的地方,导致扩容失败的场景。
故障现象
有套oracle 11.2.0.4 2节点rac的环境,监控显示,磁盘组data的剩余空间告警。所以登录环境,查看具体信息:
磁盘组详细信息:
grid@drrac01 ~]$ asmcmd lsdg State Type Rebal Sector Block AU Total_MB Free_MB Req_mir_free_MB Usable_file_MB Offline_disks Voting_files Name MOUNTED NORMAL N 512 4096 1048576 1966080 27640 32768 -2564 0 N DATA/ MOUNTED EXTERN N 512 4096 1048576 3584000 6791 0 6791 0 N DATADG01/ MOUNTED HIGH N 512 4096 1048576 10240 8984 4096 1629 0 Y OCR_VOTING/复制
可以看到,data磁盘组为normal冗余,剩余空间只剩20多个G,Usable_file_MB已经成为负值,说明已经不能保证数据的冗余度,如果此时有块磁盘offline了,那么就有可能丢数据。所以继续磁盘组扩容。
经过主机分配资源,我们往磁盘组中添加磁盘:
alter diskgroup data add disk ‘xxx’ rebalance power 10;
但是,还没等返回成功信息,就报错了。报错如下:
ERROR: ORA-15041 thrown in ARB0 for group number 1
Errors in file /u01/oracle/app/grid/base/diag/asm/+asm/+ASM1/trace/+ASM1_arb0_16655.trc:
ORA-15041: diskgroup “DATA” space exhausted
问题分析
[oracle@oracle11g ~]$ oerr ora 15041
15041, 00000, “diskgroup “%s” space exhausted”
// *Cause: The diskgroup ran out of space.
// *Action: Add more disks to the diskgroup, or delete some existing files.
//
官方的意思指出,磁盘组空间耗尽。我们应该添加更多的磁盘或者删除一些文件。
和我们的场景有点类似,我们确实是空间已经耗尽(Usable_file_MB为负值)。但是我们确实是在添加磁盘,但是报错了,所以官方解释对我们没有帮助。
而且存储空间问题不是直接存储扩容就完事了?可惜,本例无论你添加再多的磁盘也无济于事。
参考mos:ORA-15041 IN A DISKGROUP ALTHOUGH FREE_MB REPORTS SUFFICIENT SPACE (Doc ID 460155.1)
我们很容易就能验证:
1、添加新磁盘前,60块磁盘大小都一致,为32GB;
2、磁盘状态都正常,没有DROPPING / HUNG状态的磁盘;
3、我们添加新磁盘的命令根本就没成功。
那么导致它的根因是什么哪?
我们通过查询,会发现有个别磁盘的free_mb过小,甚至为0。由于rebalance需要每个磁盘的一些可用空间,最终会导致normal模式下由于部分disk无法分配有效空间触发ORA-15041。
这里有个更严重的问题:
手工或自动rebalance的前提条件是每个磁盘必须要有50M~100M的可用空间,目前部分disk的free_mb=0,所以即使表空间使用率再高,情况再紧急,无论你有再多的新盘使劲地往DATA_DG添加也无济于事。
根因:
当磁盘组中有部分磁盘的free_mb<300MB的时候,rebalance就会报错,因为重新平衡操作需要每个磁盘中的一些可用空间,也就会报错ORA-15041。
解决方法
本案例通过下面直接手工rebalance的方式是无法成功的:
alter diskgroup name rebalance power level;
建议处理的方式有两种:
1.删除磁盘组上部分数据,以释放空间来满足rebalance的需要;
2.新建ASM磁盘组,进行disk group迁移。
删除数据文件的风险过大,时间窗口和多余磁盘允许下,建议使用迁移磁盘组的方式处理。
解决过程
1、查看asm磁盘使用率:
set linesize 300;
set pagesize 20;
col name for a15;
col state for a15;
col header_status for a15;
col path for a40;
col failgroup for a15;
select dk.group_number,dk.name,dk.header_status,dk.state,dk.mode_status,dk.failgroup,dk.os_mb,dk.total_mb,dk.free_mb,dk.path from v$asm_disk dk where group_number=1 order by dk.group_number,dk.failgroup,dk.path;
GROUP_NUMBER NAME HEADER_STATUS STATE MODE_STATUS FAILGROUP OS_MB TOTAL_MB FREE_MB PATH
------------ --------------- --------------- --------------- -------------- --------------- ---------- ---------- ---------- ----------------------------------------
1 DATA_0000 MEMBER NORMAL ONLINE DATA_0000 32768 32768 1338 /dev/asm-diskaa
1 DATA_0001 MEMBER NORMAL ONLINE DATA_0001 32768 32768 893 /dev/asm-diskab
1 DATA_0002 MEMBER NORMAL ONLINE DATA_0002 32768 32768 432 /dev/asm-diskac
1 DATA_0003 MEMBER NORMAL ONLINE DATA_0003 32768 32768 0 /dev/asm-diskad
1 DATA_0004 MEMBER NORMAL ONLINE DATA_0004 32768 32768 11239 /dev/asm-diskae
1 DATA_0005 MEMBER NORMAL ONLINE DATA_0005 32768 32768 10779 /dev/asm-diskaf
1 DATA_0006 MEMBER NORMAL ONLINE DATA_0006 32768 32768 10322 /dev/asm-diskag
1 DATA_0007 MEMBER NORMAL ONLINE DATA_0007 32768 32768 9879 /dev/asm-diskah
1 DATA_0008 MEMBER NORMAL ONLINE DATA_0008 32768 32768 9409 /dev/asm-diskai
1 DATA_0009 MEMBER NORMAL ONLINE DATA_0009 32768 32768 9423 /dev/asm-diskaj
1 DATA_0010 MEMBER NORMAL ONLINE DATA_0010 32768 32768 9414 /dev/asm-diskak
1 DATA_0011 MEMBER NORMAL ONLINE DATA_0011 32768 32768 9415 /dev/asm-diskal
1 DATA_0012 MEMBER NORMAL ONLINE DATA_0012 32768 32768 9419 /dev/asm-diskam
1 DATA_0013 MEMBER NORMAL ONLINE DATA_0013 32768 32768 9410 /dev/asm-diskan
1 DATA_0014 MEMBER NORMAL ONLINE DATA_0014 32768 32768 9413 /dev/asm-diskao
1 DATA_0015 MEMBER NORMAL ONLINE DATA_0015 32768 32768 9413 /dev/asm-diskap
1 DATA_0016 MEMBER NORMAL ONLINE DATA_0016 32768 32768 9414 /dev/asm-diskaq
GROUP_NUMBER NAME HEADER_STATUS STATE MODE_STATUS FAILGROUP OS_MB TOTAL_MB FREE_MB PATH
------------ --------------- --------------- --------------- -------------- --------------- ---------- ---------- ---------- ----------------------------------------
1 DATA_0017 MEMBER NORMAL ONLINE DATA_0017 32768 32768 9412 /dev/asm-diskar
1 DATA_0018 MEMBER NORMAL ONLINE DATA_0018 32768 32768 9414 /dev/asm-diskas
1 DATA_0019 MEMBER NORMAL ONLINE DATA_0019 32768 32768 9410 /dev/asm-diskat
1 DATA_0020 MEMBER NORMAL ONLINE DATA_0020 32768 32768 9416 /dev/asm-diskau
1 DATA_0021 MEMBER NORMAL ONLINE DATA_0021 32768 32768 9414 /dev/asm-diskav
1 DATA_0022 MEMBER NORMAL ONLINE DATA_0022 32768 32768 9414 /dev/asm-diskaw
1 DATA_0023 MEMBER NORMAL ONLINE DATA_0023 32768 32768 9412 /dev/asm-diskax
1 DATA_0024 MEMBER NORMAL ONLINE DATA_0024 32768 32768 9417 /dev/asm-diskay
1 DATA_0025 MEMBER NORMAL ONLINE DATA_0025 32768 32768 9418 /dev/asm-diskaz
1 DATA_0026 MEMBER NORMAL ONLINE DATA_0026 32768 32768 9405 /dev/asm-diskba
1 DATA_0027 MEMBER NORMAL ONLINE DATA_0027 32768 32768 9414 /dev/asm-diskbb
1 DATA_0028 MEMBER NORMAL ONLINE DATA_0028 32768 32768 9412 /dev/asm-diskbc
1 DATA_0029 MEMBER NORMAL ONLINE DATA_0029 32768 32768 9415 /dev/asm-diskbd
1 DATA_0030 MEMBER NORMAL ONLINE DATA_0030 32768 32768 9415 /dev/asm-diskbe
1 DATA_0031 MEMBER NORMAL ONLINE DATA_0031 32768 32768 9412 /dev/asm-diskbf
1 DATA_0032 MEMBER NORMAL ONLINE DATA_0032 32768 32768 9420 /dev/asm-diskbg
1 DATA_0033 MEMBER NORMAL ONLINE DATA_0033 32768 32768 9416 /dev/asm-diskbh
GROUP_NUMBER NAME HEADER_STATUS STATE MODE_STATUS FAILGROUP OS_MB TOTAL_MB FREE_MB PATH
------------ --------------- --------------- --------------- -------------- --------------- ---------- ---------- ---------- ----------------------------------------
1 DATA_0034 MEMBER NORMAL ONLINE DATA_0034 32768 32768 9415 /dev/asm-diskbi
1 DATA_0035 MEMBER NORMAL ONLINE DATA_0035 32768 32768 9417 /dev/asm-diskbj
1 DATA_0036 MEMBER NORMAL ONLINE DATA_0036 32768 32768 9415 /dev/asm-diskbk
1 DATA_0037 MEMBER NORMAL ONLINE DATA_0037 32768 32768 9418 /dev/asm-diskbl
1 DATA_0038 MEMBER NORMAL ONLINE DATA_0038 32768 32768 9416 /dev/asm-diskbm
1 DATA_0039 MEMBER NORMAL ONLINE DATA_0039 32768 32768 9419 /dev/asm-diskbn
1 DATA_0040 MEMBER NORMAL ONLINE DATA_0040 32768 32768 9414 /dev/asm-diskbo
1 DATA_0041 MEMBER NORMAL ONLINE DATA_0041 32768 32768 9414 /dev/asm-diskbp
1 DATA_0042 MEMBER NORMAL ONLINE DATA_0042 32768 32768 9411 /dev/asm-diski
1 DATA_0043 MEMBER NORMAL ONLINE DATA_0043 32768 32768 9413 /dev/asm-diskj
1 DATA_0044 MEMBER NORMAL ONLINE DATA_0044 32768 32768 9416 /dev/asm-diskk
1 DATA_0045 MEMBER NORMAL ONLINE DATA_0045 32768 32768 9422 /dev/asm-diskl
1 DATA_0046 MEMBER NORMAL ONLINE DATA_0046 32768 32768 9415 /dev/asm-diskm
1 DATA_0047 MEMBER NORMAL ONLINE DATA_0047 32768 32768 9417 /dev/asm-diskn
1 DATA_0048 MEMBER NORMAL ONLINE DATA_0048 32768 32768 9411 /dev/asm-disko
1 DATA_0049 MEMBER NORMAL ONLINE DATA_0049 32768 32768 9423 /dev/asm-diskp
1 DATA_0050 MEMBER NORMAL ONLINE DATA_0050 32768 32768 9415 /dev/asm-diskq
GROUP_NUMBER NAME HEADER_STATUS STATE MODE_STATUS FAILGROUP OS_MB TOTAL_MB FREE_MB PATH
------------ --------------- --------------- --------------- -------------- --------------- ---------- ---------- ---------- ----------------------------------------
1 DATA_0051 MEMBER NORMAL ONLINE DATA_0051 32768 32768 9414 /dev/asm-diskr
1 DATA_0052 MEMBER NORMAL ONLINE DATA_0052 32768 32768 9865 /dev/asm-disks
1 DATA_0053 MEMBER NORMAL ONLINE DATA_0053 32768 32768 10323 /dev/asm-diskt
1 DATA_0054 MEMBER NORMAL ONLINE DATA_0054 32768 32768 10774 /dev/asm-disku
1 DATA_0055 MEMBER NORMAL ONLINE DATA_0055 32768 32768 11226 /dev/asm-diskv
1 DATA_0056 MEMBER NORMAL ONLINE DATA_0056 32768 32768 0 /dev/asm-diskw
1 DATA_0057 MEMBER NORMAL ONLINE DATA_0057 32768 32768 432 /dev/asm-diskx
1 DATA_0058 MEMBER NORMAL ONLINE DATA_0058 32768 32768 895 /dev/asm-disky
1 DATA_0059 MEMBER NORMAL ONLINE DATA_0059 32768 32768 1350 /dev/asm-diskz
1 DATA_0060 MEMBER NORMAL ONLINE DATA_0060 512000 512000 388283 /dev/asm-disksdce
61 rows selected.
复制可以看到结果中总共61块盘,前60块盘都为32G,最后一块为新添加的512G,normal冗余模式下,每块磁盘都是默认添加,自己是自己的failgroup。但是前60块磁盘的磁盘使用率都不一致,按照ASM使用率均衡的原理,所有磁盘的剩余空间应该都一样才对。在磁盘组中每个磁盘大小不一致的情况下,才有可能使用率可能不一致。但是这里有大有小,而且有两块盘的剩余空间已经为0。
手工或自动rebalance的前提条件是每个磁盘必须要有50M~100M的可用空间,目前部分disk的free_mb=0,无法rebalance,所以报错ORA-15041。无论你有再多的新盘使劲地往DATA_DG添加也无济于事。
所以现在想办法要把那两块盘的free_mb调整为不是0.那么唯一的办法就是把数据文件挪到其他位置,释放点空间。
2、resize 释放空间。
SQL> set pages 999 lines 300
SELECT /*+ parallel(8) */ d.tablespace_name "TB Name",d.status "Status",TO_CHAR((a.bytes / 1024 / 1024/1024),'99,999,990.90') "Size (G)",
TO_CHAR((a.bytes - f.bytes) / 1024 / 1024/1024,'99,999,990.90') "Used G", round(((a.bytes - f.bytes) / a.bytes) * 100, 2) "% Used" FROM sys.dba_tablespaces d,sys.sm$ts_avail a, sys.sm$ts_free f WHERE d.tablespace_name =a.tablespace_name AND f.tablespace_name (+) =d.tablespace_name order by ((a.bytes - f.bytes) / a.bytes) desc;SQL> 2
TB Name Status Size (G) Used G % Used
------------------------------ --------- -------------- -------------- ----------
ZFPT_KF ONLINE 4,140.61 3,770.38 91.06
SYSAUX ONLINE 31.65 26.50 83.72
ZFPT_ZW ONLINE 30.00 23.43 78.11
SYSTEM ONLINE 3.94 2.61 66.22
DUBBO ONLINE 0.10 0.01 9.63
UNDOTBS1 ONLINE 68.63 5.77 8.4
ZFPT_CFG ONLINE 3.00 0.01 .37
USERS ONLINE 3.00 0.00 .08
CMS_DATA ONLINE 30.00 0.02 .06
UNDOTBS2 ONLINE 94.00 0.04 .04
OGG ONLINE 5.00 0.00 .02
11 rows selected.
SQL> select file_name,file_id,tablespace_name from dba_data_files where tablespace_name='CMS_DATA';
FILE_NAME FILE_ID TABLESPACE_NAME
-------------------------------------------------- ---------- ------------------------------
+DATA/hyzf/datafile/cms_data.1353.997352165 6 CMS_DATA
SQL> select file_name,file_id,tablespace_name,bytes/1024/1024/1024 from dba_data_files where tablespace_name='CMS_DATA';
FILE_NAME FILE_ID TABLESPACE_NAME BYTES/1024/1024/1024
-------------------------------------------------- ---------- ------------------------------ --------------------
+DATA/hyzf/datafile/cms_data.1353.997352165 6 CMS_DATA 30
SQL> alter database datafile 6 resize 1G;
Database altered.
SQL> select file_name,file_id,tablespace_name,bytes/1024/1024/1024 from dba_data_files where tablespace_name='UNDOTBS2';
FILE_NAME FILE_ID TABLESPACE_NAME BYTES/1024/1024/1024
-------------------------------------------------- ---------- ------------------------------ --------------------
+DATA/hyzf/datafile/undotbs2.265.997301983 5 UNDOTBS2 30
+DATA/hyzf/datafile/undotbs2.1369.997353267 22 UNDOTBS2 30
+DATA/hyzf/datafile/undotbs2.256.997432009 24 UNDOTBS2 30
+DATA/hyzf/datafile/undotbs2.1303.1027270551 52 UNDOTBS2 1
+DATA/hyzf/datafile/undotbs2.1302.1027270555 53 UNDOTBS2 1
+DATA/hyzf/datafile/undotbs2.1301.1027270557 54 UNDOTBS2 1
+DATA/hyzf/datafile/undotbs2.1300.1027270561 55 UNDOTBS2 1
7 rows selected.
SQL> alter database datafile 5 resize 1G;
Database altered.
SQL> alter database datafile 22 resize 1G;
Database altered.
SQL> alter database datafile 24 resize 1G;
Database altered.
SQL> select file_name,file_id,tablespace_name,bytes/1024/1024/1024 from dba_data_files where tablespace_name='UNDOTBS1';
FILE_NAME FILE_ID TABLESPACE_NAME BYTES/1024/1024/1024
-------------------------------------------------- ---------- ------------------------------ --------------------
+DATA/hyzf/datafile/undotbs1.261.997301819 3 UNDOTBS1 30
+DATA/hyzf/datafile/undotbs1.1308.1027270475 47 UNDOTBS1 7.125
+DATA/hyzf/datafile/undotbs1.1307.1027270509 48 UNDOTBS1 7.375
+DATA/hyzf/datafile/undotbs1.1306.1027270513 49 UNDOTBS1 7.75
+DATA/hyzf/datafile/undotbs1.1305.1027270515 50 UNDOTBS1 8
+DATA/hyzf/datafile/undotbs1.1304.1027270523 51 UNDOTBS1 8.375
6 rows selected.
SQL> alter database datafile 3 resize 6G;
Database altered.
复制此时可以观察到,那两块盘的free_mb,已经不为0了,通过日志,可以看到rebalance可以继续了。
Wed Jan 19 17:35:35 2022
NOTE: ASM did background COD recovery for group 1/0x90482d19 (DATA)
NOTE: starting rebalance of group 1/0x90482d19 (DATA) at power 10
Starting background process ARB0
Wed Jan 19 17:35:38 2022
ARB0 started with pid=34, OS id=20360
NOTE: assigning ARB0 to group 1/0x90482d19 (DATA) with 10 parallel I/Os
cellip.ora not found.
但是过一会,又会有相同的报错。
Wed Jan 19 17:38:23 2022
ERROR: ORA-15041 thrown in ARB0 for group number 1
Errors in file /u01/oracle/app/grid/base/diag/asm/+asm/+ASM1/trace/+ASM1_arb0_20360.trc:
ORA-15041: diskgroup “DATA” space exhausted
Wed Jan 19 17:38:23 2022
NOTE: stopping process ARB0
NOTE: rebalance interrupted for group 1/0x90482d19 (DATA)
报错信息:rebalance interrupted。rebalance未完成。
此刻查看那两块盘的free_mb又为0了,难怪rebalance不能完成。
此处就有疑问1 ,按理是扩容,现有磁盘的free_mb,应该增大,新增磁盘的free_mb应该较少才对,。但是我们在观察的过程中,那两块盘的free_mb一直在减小,不知道为什么?
3、看来还是空间不够,需要再释放空间。那么还需要释放多少空间那?此处可以参考mos:Exadata Create TableSpace Fails with ORA-01119 ORA-17502 ORA-15041 Diskgroup Space Exhausted Despite Plenitude of Free Space is Present (Doc ID 2372651.1)。计算大概需要的rebalance空间,但是我们当时没有计算。
现在摆在我们面前的就两条路:一是新建磁盘组,进行diskgroup迁移。但是存储已无多余磁盘来创建新的磁盘组。
二是删除数据文件。删除是不允许的,我们可以把磁盘组里面的数据文件移动到其他位置,如文件系统或者另一个磁盘组。此处刚好另一个磁盘组datadg01还有剩余空间,我们就选择把data里面的数据文件移动部分到datadg01里面,释放空间。
4、既然是这两块盘的使用率很高,剩余空间为0,那么我们就可以针对这两块盘进行数据文件移动,即看哪几个数据文件存储在这两块盘里面,然后又针对性的移动,就会很快释放这两块的空间。
参考mos:ORA-15041 DURING REBALANCE OR ADD DISK WHEN PLENTY OF SPACE EXISTS (Doc ID 473271.1)
select group_kfdat "group #",
number_kfdat "disk #",
count(*) "# AU's"
from x$kfdat a
where v_kfdat = 'V'
and not exists (select *
from x$kfdat b
where a.group_kfdat = b.group_kfdat
and a.number_kfdat = b.number_kfdat
and b.v_kfdat = 'F')
group by GROUP_KFDAT, number_kfdat;SQL> 2 3 4 5 6 7 8 9 10 11
group # disk # # AU's
---------- ---------- ----------
1 56 33152
1 3 33152
SQL> select name, file_number
from v$asm_alias
where group_number in (select group_kffxp
from x$kffxp
where group_kffxp=1
and disk_kffxp in (3,56)
and au_kffxp != 4294967294
and number_kffxp >= 256)
and file_number in (select number_kffxp
from x$kffxp
where group_kffxp=1
and disk_kffxp in (3,56)
and au_kffxp != 4294967294
and number_kffxp >= 256)
and system_created='Y'; 2 3 4 5 6 7 8 9 10 11 12 13 14 15
NAME FILE_NUMBER
------------------------------------------------------------ -----------
UNDOTBS2.256.997432009 256
group_8.257.997354099 257
group_7.258.997354099 258
group_6.259.997354087 259
SYSAUX.260.997301819 260
UNDOTBS1.261.997301819 261
group_4.263.997354391 263
group_1.264.997354227 264
UNDOTBS2.265.997301983 265
group_5.267.997354075 267
TEMP.268.997301931 268
group_2.269.997301929 269
group_3.270.997354229 270
Current.271.997301927 271
SYSTEM.272.997301819 272
ZFPT_KF.1291.1036749283 1291
ZFPT_KF.1292.1035909701 1292
ZFPT_KF.1293.1032861029 1293
ZFPT_KF.1294.1032860827 1294
ZFPT_KF.1295.1028968735 1295
USERS.1296.1027420239 1296
SYSTEM.1297.1027420191 1297
SYSAUX.1298.1027420153 1298
ZFPT_KF.1299.1027420039 1299
UNDOTBS2.1300.1027270561 1300
UNDOTBS2.1301.1027270557 1301
UNDOTBS2.1302.1027270555 1302
UNDOTBS2.1303.1027270551 1303
UNDOTBS1.1304.1027270523 1304
UNDOTBS1.1305.1027270515 1305
UNDOTBS1.1306.1027270513 1306
UNDOTBS1.1307.1027270509 1307
UNDOTBS1.1308.1027270475 1308
ZFPT_KF.1309.1027269461 1309
ZFPT_KF.1310.1027269459 1310
ZFPT_KF.1311.1027269457 1311
ZFPT_KF.1312.1027269455 1312
ZFPT_KF.1313.1027269451 1313
ZFPT_KF.1314.1027269435 1314
ZFPT_KF.1315.1027269433 1315
ZFPT_KF.1316.1027269431 1316
ZFPT_KF.1317.1027269427 1317
ZFPT_KF.1318.1027269425 1318
ZFPT_KF.1319.1027269421 1319
ZFPT_KF.1320.1027269349 1320
ZFPT_KF.1321.1022256547 1321
ZFPT_KF.1322.1022256531 1322
ZFPT_KF.1323.1022256521 1323
ZFPT_KF.1324.1022256491 1324
ZFPT_KF.1325.1022256477 1325
ZFPT_KF.1326.1022256457 1326
ZFPT_KF.1327.1022256437 1327
ZFPT_KF.1328.1014300783 1328
DUBBO.1329.997640731 1329
ZFPT_CFG.1330.997466985 1330
CMS_DATA.1353.997352165 1353
ZFPT_KF.1355.997352277 1355
ZFPT_KF.1356.997352329 1356
ZFPT_KF.1357.997352367 1357
ZFPT_KF.1358.997352403 1358
ZFPT_KF.1359.997352479 1359
ZFPT_KF.1360.997352653 1360
ZFPT_KF.1361.997352725 1361
ZFPT_KF.1362.997352767 1362
ZFPT_KF.1363.997352803 1363
ZFPT_KF.1364.997352843 1364
ZFPT_KF.1365.997352897 1365
ZFPT_KF.1366.997352933 1366
ZFPT_KF.1367.997352969 1367
ZFPT_KF.1368.997353017 1368
UNDOTBS2.1369.997353267 1369
OGG.1370.997353311 1370
72 rows selected.
复制排除redo和undo,我们移动ZFPT_KF对应的数据文件。
5、参考mos:How to move ASM database files from one diskgroup to another ? (Doc ID 330103.1)
我们采用rman的方式移动数据文件。此方法需要停相应的业务。
具体步骤如下:
1、数据库打开为归档模式。
2、offline表空间
SQL> alter tablespace ZFPT_KF offline;
Tablespace altered.
复制3、备份
[oracle@drrac01 ~]$ rman target /
Recovery Manager: Release 11.2.0.4.0 - Production on Wed Jan 19 18:45:32 2022
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
connected to target database: HYZF (DBID=3226644262)
RMAN> backup as copy datafile 8 format '+DATADG01';
RMAN> backup as copy datafile 9 format '+DATADG01';
RMAN> backup as copy datafile 10 format '+DATADG01';
RMAN> backup as copy datafile 11 format '+DATADG01';
RMAN> backup as copy datafile 12 format '+DATADG01';
RMAN> backup as copy datafile 13 format '+DATADG01';
RMAN> backup as copy datafile 14 format '+DATADG01';
RMAN> backup as copy datafile 15 format '+DATADG01';
RMAN> backup as copy datafile 16 format '+DATADG01';
RMAN> backup as copy datafile 17 format '+DATADG01';
RMAN> backup as copy datafile 18 format '+DATADG01';
RMAN> backup as copy datafile 19 format '+DATADG01';
RMAN> backup as copy datafile 20 format '+DATADG01';
复制4、修改控制文件中数据文件路径
RMAN> switch datafile 8,9,10,11,12,13,14,15,16,17,18,19,20 to copy;
datafile 8 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.376.1094410053"
datafile 9 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.377.1094410133"
datafile 10 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.378.1094410155"
datafile 11 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.379.1094410241"
datafile 12 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.380.1094410257"
datafile 13 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.381.1094410315"
datafile 14 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.382.1094410343"
datafile 15 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.383.1094410377"
datafile 16 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.384.1094410417"
datafile 17 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.385.1094410451"
datafile 18 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.386.1094410493"
datafile 19 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.387.1094410541"
datafile 20 switched to datafile copy "+DATADG01/hyzf/datafile/zfpt_kf.388.1094410559"
SQL> select file_name,file_id,tablespace_name,bytes/1024/1024/1024 from dba_data_files where file_id in(8,9,10,11,12,13,14,15,16,17,18,19,20)
FILE_NAME FILE_ID TABLESPACE_NAME BYTES/1024/1024/1024
-------------------------------------------------- ---------- ------------------------------ --------------------
+DATADG01/hyzf/datafile/zfpt_kf.376.1094410053 8 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.377.1094410133 9 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.378.1094410155 10 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.379.1094410241 11 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.380.1094410257 12 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.381.1094410315 13 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.382.1094410343 14 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.383.1094410377 15 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.384.1094410417 16 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.385.1094410451 17 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.386.1094410493 18 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.387.1094410541 19 ZFPT_KF 30
+DATADG01/hyzf/datafile/zfpt_kf.388.1094410559 20 ZFPT_KF 30
13 rows selected.
复制5、online回来表空间
SQL> alter tablespace ZFPT_ZW online;
Tablespace altered.
复制6、此时rebalance可以正常完成。
Wed Jan 19 19:06:31 2022
NOTE: GroupBlock outside rolling migration privileged region
NOTE: requesting all-instance membership refresh for group=1
Wed Jan 19 19:06:36 2022
GMON updating for reconfiguration, group 1 at 47 for pid 37, osid 18419
NOTE: group 1 PST updated.
Wed Jan 19 19:06:36 2022
NOTE: membership refresh pending for group 1/0x90482d19 (DATA)
GMON querying group 1 at 48 for pid 18, osid 49741
SUCCESS: refreshed membership for 1/0x90482d19 (DATA)
NOTE: Attempting voting file refresh on diskgroup DATA
NOTE: Refresh completed on diskgroup DATA. No voting file found.
Wed Jan 19 19:36:28 2022
NOTE: stopping process ARB0
SUCCESS: rebalance completed for group 1/0x90482d19 (DATA)
7、rebalance完。磁盘使用率还是不一致。

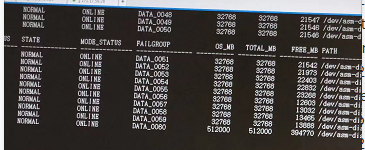
参考mos:ORA-15041 Diskgroup Space Exhausted (Doc ID 1367078.1)
元数据的差异导致使用率不均衡,执行:
alter diskgroup <diskgroup name> check all norepair;
This can be run safely on active system. Once this command completes, check the ASM alert.log if it reports any "mismatch" of AT and DD. Something like
NOTE: disk <diskgroup name>, used AU total mismatch: DD=32169, AT=32172
If yes, then run:
alter diskgroup <diskgroup name> check all repair;
This can be run safely on active system and is meant to fix the AT and DD discrepancy. An AT and DD ASM Metadata discrepancy might manifest because of previous failed file allocation in the diskgroup. After the check all repair command, run a manual rebalance
alter diskgroup <diskgroup name> rebalance power <n>;
复制曾今有过check all repair导致磁盘组挂掉的经历,所以没有执行,让他继续不均衡着,但是也不打算往这个磁盘组里面添加数据文件了。至此,修复完成。
8、还有人说我们可以drop disk 3号和56号磁盘,让其重新触发rebalance。因为此刻add disk的rebalance被hang,所以此刻,drop disk的rebalance根本无法触发,而且即使触发了,3和56号盘上面有数据,他们的数据rebalance到哪里去哪?很有可能会丢数据。drop那块新添加的磁盘也是一样的道理,上面已经有rebalance的数据了,删除会丢数据。
总结
本次故障中,有几点值得今后的系统注意:
1、asm磁盘组扩容前,应该仔细检查:
1)是否有offline或者hang状态的磁盘;
2)查询每个磁盘的使用率,是否均衡,是否有free_mb为0的情况。
2.ASM磁盘组中尽量使用大小规格统一的磁盘。
3.ASM扩容注意监控rebalance的结果。
4.ASM使用率的监控,建议深化监控到disk级别。参考:Information to gather when diagnosing ASM space issues (Doc ID 351117.1)
遗留问题
虽然问题解决了,但是有2个疑问:
1、一般都是类似alter tablespace add datafile这种,要在asm磁盘中分配空间的时候,检测到某块盘磁盘耗尽,才会报错。但是我们此次情况是扩容,按理说是把空间耗尽盘的数据挪到新添加的磁盘上,以到达空间均衡。是扩容而不是分配空间,按理说是不会报这种错误的,但是不知道为什么?会报这个错误。但是唯一能确定的是确实有磁盘空间耗尽。
2、rebalance的时候,第一次处理的时候,已经挪出了50G的空闲空间,所有磁盘的剩余空间都有,但是在它第二次rebalance的时候,我们可以明显的看到那两块使用率高的磁盘的剩余空间还在一直不断减少,一直到0,最后报错。按理说,原来的盘在rebalance的时候,会把原来磁盘组中的数据挪到新盘,所有原来磁盘组中的磁盘剩余空间应该不会减少,而是会增大。但是相反。所以最后又剩余了0,报错。但是能确定的是加盘之前,asm中没有其他rebalance的操作。
疑问1参考:mos:ORA-15041 Diskgroup Space Exhausted (Doc ID 1367078.1)可以得出答案。
3] If any one or more disk in the diskgroup has very less space ( say < 300 MB ), then manual rebalance/add of new disks will not help. Because rebalance operation needs some amount of free space in each disk. Also add of a new disk will invoke an automatic rebalance that will also fail with ORA-15041. In this case, you should look to remove/move some files from the diskgroup. Check for obsolete RMAN/dump files, temp files etc. Once we remove/move some files, from the diskgroup, query v$asm_disk.free_mb for each disk. If the free_mb is say > 300 MB, run a manual rebalance ( or add disk )
alter diskgroup
也就是说,当磁盘的free_mb<300MB的时候,那么手动重新平衡/添加新磁盘将无济于事。 因为重新平衡操作需要每个磁盘中的一些可用空间。 此外,添加新磁盘将调用自动重新平衡,该重新平衡也会因 ORA-15041 而失败。
也就是说,不管是给磁盘组扩容,增加空间,还是使用空间,给数据库添加数据文件。当磁盘组中有部分磁盘的free_mb<300MB的时候,rebalance就会报错(重新平衡操作需要每个磁盘中的一些可用空间),就会报错ORA-15041。
参考
ORA-15041 IN A DISKGROUP ALTHOUGH FREE_MB REPORTS SUFFICIENT SPACE (Doc ID 460155.1)
ORA-15041 DURING REBALANCE OR ADD DISK WHEN PLENTY OF SPACE EXISTS (Doc ID 473271.1)
Information to gather when diagnosing ASM space issues (Doc ID 351117.1)
评论

 0 点赞
0 点赞



