360公司的IaaS服务平台是基于开源Openstack研发的,历经了多次版本的迭代。2015年,360基于Liberty版本自研了公有云和支撑集团内部使用的私有云。2019年-2020年期间,360重新在Openstack Stein版本的基础上自研,打造适配ToB场景的IaaS平台360Stack,目前已发展成为可面向市场正式商业交付的成熟产品。2021年,360虚拟化团队自研主机Overlay架构适配公司的大规模场景,应用计算存储分离结构,也在持续上线更丰富的云主机功能,如弹性伸缩、可抢占实例、弹性裸金属等。最新的Stein版本功能,与早期版本相比已经有了极大的改进。目前自研Openstack Stein版已被应用于北京的两个25G新机房,但是正在公司北京、上海、郑州等六大主力机房中运行的虚拟化集群,几乎都还是Liberty版本。管理着3000多台物理机,规模巨大且运维成本高。如果能够将公司内的L版本升级到S版本,好处是显而易见的。整体客观而言,升级工作版本跨度很大,隔了7个版本,按Openstack一年2个版本的迭代速度,相当于隔了3年半。中间版本的表结构差异、功能差异非常大,两拨人马、两套代码和数据,中间断层非常严重。要达成统一,大家都默认不可行,默认接受新的用S版本,老机房都用L版本。但是360虚拟化团队基于使命必达、创新突破的价值观秉持下,我们提出一定要统一,公司底层云底座必须统一架构,并且所有机房必须支持今年上线的新能力。最后在保持统一目标下,大家群策群力,想了多种方案,比如机房迁移、挂公告ceph冷迁移、ceph双写热迁移等等。但上述方案对用户影响都比较大,我们提出能不能做到对业务无感知,这对团队的技术要求提出了更大挑战。最后大家几经研究讨论,用表结构对齐、流表补齐、组件定制升级的思路,达成了如下的横跨7个版本业务无感知的Openstack热迁移方案。该方案足够通用,理论上支持以后的任意Openstack之间版本热升级,希望能对大家有所帮助。当前IaaS业界基本上除了一些头部云厂商自研,其他IaaS厂商还是基于Openstack居多,但可能大家都是基于一个版本之后二次开发cherrypick,可能与社区渐行渐远,也有可能一些跟社区跟的比较紧的。持续跟着社区热升级也不会有这种情况。还有一些公司私有云已经没有IaaS,直接用k8s容器推动业务全面容器化,部分特殊VM需求用Kubevirt代替等。所以每家公司都有自己的独特背景和经历,做方案的时候除了技术还需要一些勇气,希望能对大家有所借鉴。
360在2015年基于Liberty版本进行自研,其中包含了大量为满足当时网络Overlay架构,云主机生命周期管理的功能特性,自研Stein版本与Liberty旧版相比,其中不仅有社区代码的变动,自研代码的差异,数据库表结构的变化,最核心的还有自研Stein版采用了主机Overlay网络结构,并采用存算分离的计算架构,这两个版本在各方面来看,差别巨大。从Openstack 这个IaaS平台服务本身看,它最根本的依赖元素是各个组件的代码、数据库和消息队列。Openstack社区在升级每个版本的时候,不仅有代码的变动,还会详细描述数据库表结构的创建升级删除操作。所以按社区的这种升级方式来操作,对目前这个现状基本是不可行的。基于虚拟化团队对Openstack多年的开发经验积累,我们探索出从控制层面的数据库入手,将L版使用的数据库对齐到S版使用的数据库中,使得集群控制面能够平滑升级到S版本。同时对计算节点,进行了软件层面的全部更新。另外,为了保证升级过程现有业务的网络无感知、零中断,还增加了网络流表补齐。综上来说,L-S架构热升级包含三方面的升级操作:控制面对齐,网络数据面对齐,软件层面全部更新。
控制面数据对齐,采用数据库导入的方式。分为三个步骤,主要应用于Nova、Cinder、Glance三个组件:2.1.1 Nova数据库对齐
下面以nova组件为例,详细讲解其中的步骤。L版到S版nova组件架构上有变动,数据库和数据表也有相应变更,从L版nova数据库53张表(忽略shadow_开头的表)到S版的148张表(包括nova_api中32张+nova_cell0中58张+nova中58张,忽略以shadow_开头的表),数据库表变化很大。虽然有这么多变化,但是我们关心的数据表主要在虚拟机和hypervisor,而hypervisor信息可由nova-compute实时上报,因此我们只需要关心存量虚拟机以及虚机周边信息的记录。以下列出与虚拟机数据表记录相关的表,其它数据表保持使用S版的。nova_cell0库存储调度失败的虚拟机信息,可忽略,无需进行迁移操作。步骤一:在L版使用的DB中创建临时数据库migrate_nova_api和migrate_nova,并依据S版数据库创建临时数据表。| 新建migrate_nova_api库,按S版表结构新建下面的表 | S版本里新增字段使用默认值或进行后期处理,删除字段无需关注。 |
| 记录Flavor信息。将L版的instance_types表迁移到flavors表,同时表中移除deleted_at、deleted字段 |
| 记录Flavor额外键值信息。将L版的instance_type_extra_specs迁移到flavor_extra_specs,同时表中移除deleted_at、deleted字段,L版instance_type_id字段变为flavor_id字段 |
| |
| 记录instance和cell的映射。先从L的instances表导入数据,之后用脚本填充cell_id信息。 |
| |
| |
| |
| 这个表在L版里不存在,通过额外的脚本对虚机进行补齐,否则在S版里做不了迁移,重装等操作。 |
| 新建migrate_nova_api库,按S版表结构新建下面的表 |
|
| |
| |
| |
| |
| |
|
|
| |
步骤二:使用MySQL内部insert into ... select from语句将L版原数据记录导入到临时数据库中;比如下面的例子。| migrate_nova_api.flavors(`created_at`,`updated_at`,`name`,`id`,`memory_mb`,`vcpus`,`swap`,`vcpu_weight`,`flavorid`,`rxtx_factor`,`root_gb`,`ephemeral_gb`,`disabled`,`is_public`) select `created_at`,`updated_at`,`name`,`id`,`memory_mb`,`vcpus`,`swap`,`vcpu_weight`,`flavorid`,`rxtx_factor`,`root_gb`,`ephemeral_gb`,`disabled`,`is_public` from instance_types where deleted=0; |
步骤三:通过shell脚本更改临时数据库中的某些字段,比如,由于不对Keystone进行升级,要将L版DB中的project和user信息替换成S版集群中的project和user,另外,需要补齐cellid和availability_zone等信息。步骤四:使用mysqldump命令将临时数据库表导出后,使用mysql命令将导出的临时数据表导入到S版数据库,要求S版数据库在导入前无杂乱数据,以便于把老数据按id序号完全导入。
2.1.2 Glance数据库对齐
原理和nova数据库一样,这里列出实际操作的数据表。| 新增migrate_glance库,按S版表结构新建下面的表 |
|
|
|
对glance数据库的补充更改:images表的owner字段,image_properties表的owner_id 和user_id字段修改为新keystone里的项目信息。另外,在S版里,使用了镜像多后端,所以在导入到S版数据库里后,对image的location在metadata里添加了backend的属性。2.1.3 Cinder数据库对齐
原理和nova数据库一样,这里列出实际操作的数据表。| 新增migrate_cinder库,按S版表结构新建下面的表 |
|
|
|
|
|
|
|
对cinder数据库的补充更改:更改volumes表和snapshots表的user_id和project_id。在S版环境中,存储是多Ceph集群多Ceph Pool模式的,对于sata这种volume_type,会对应多个不同pool,因此会对应到多个cinder_volume服务。在迁移cinder数据库的过程中,对L版集群的pool匹配对应S版的cinder-volume服务,更新对应volumes的host、service_uuid、volume_type、availability_zone等信息。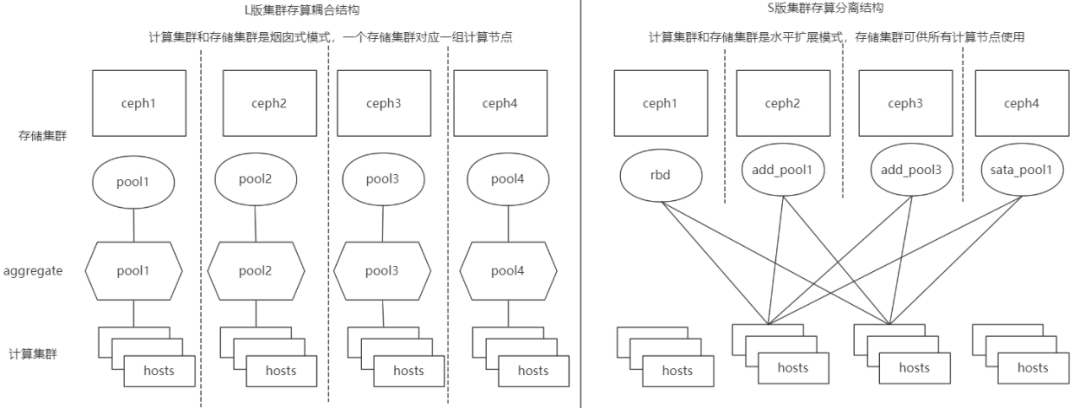
网络方面和计算的数据同步方案有些差异,一方面是我们对原生L版本的网络改动比较大,因为当时是基于网络overlay的思路去重构的虚拟化网络架构,对数据库表修改比较多,另一方面网络的数据主要是围绕port构建的,而我们通过命令构建port是很方便的。 基于如上两点,网络部分数据的同步采用如下思路:提取L版本关键信息,根据这些关键信息通过命令将port构建出来。这样做的好处是不必将大量精力耗费在L版本与S版本数据库表的差异上。- 首先提取L版本关键信息。其中包含agent、security group、network、subnet、port信息。注意这里agent信息比较特殊,因为neutron server没有创建的接口,所以需要将这些信息通过sql命令导入新版数据库,这点和之前的nova数据库对齐有些类似。如果agent信息没有对齐,会导致后面创建port时binding failed,所以这一步是必须的。另外这里说的关键信息是必须要保持一致的信息,比如id、network segment 、subnetcidr、subnet dns_server、subnetgateway_ip、port ip、port mac、port device_id等;
- 其次根据收集到的信息。在新版控制节点依次创建security group、network、subnet、port信息。注意由于网络的转发面(比如tap口)会用到port id信息,因此我们需要保证port id与之前L版本的id一致,因此创建port时需要指定id,但原生openstack并不满足这一需求,因此需要改下代码,关键代码在neutron_lib/api/attributes.py:AttributeInfo,感兴趣的同学可以了解下;
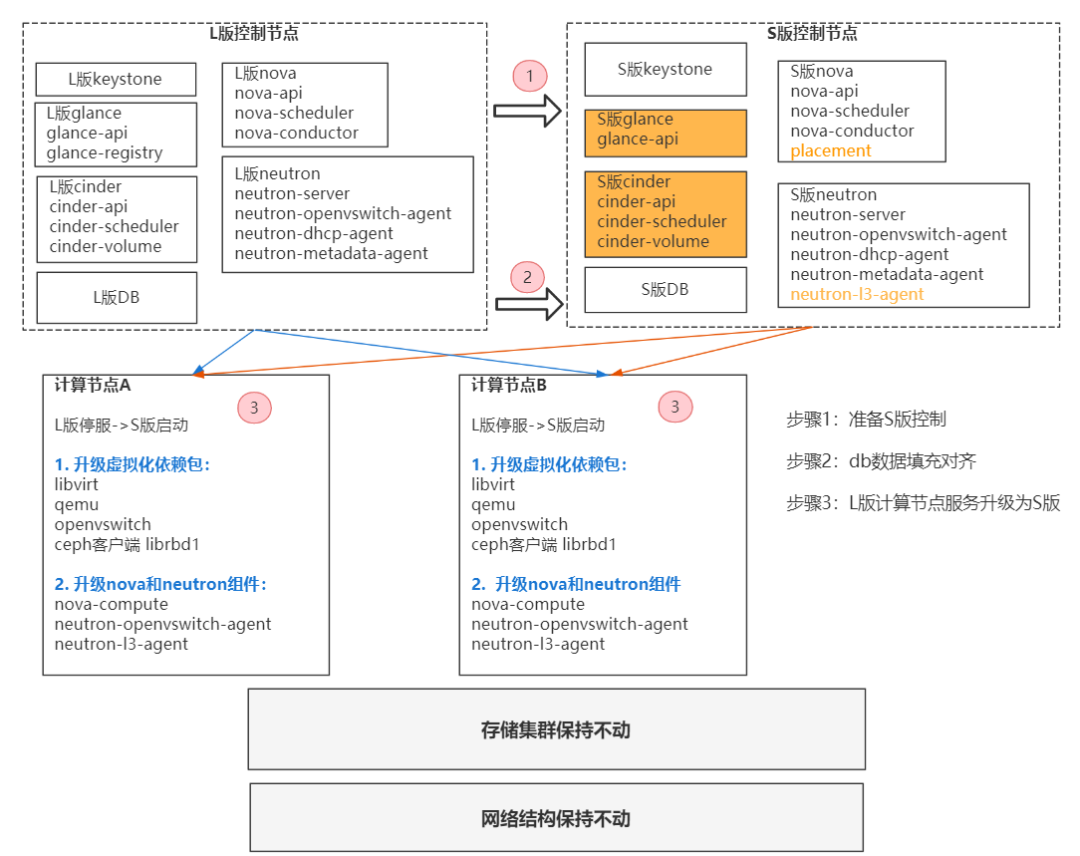
L、S版本分别使用 Puppet和 Kolla ansible 进行配置管理,Puppet 与 kolla ansible 并列社区核心项目。- Puppet 基于c /s 架构,周边生态基于完善基础设施,如 pip rpm image仓库、git仓库、代码审核平台等。Puppet 对虚拟化集群中 file、service、package 进行原子化管理。Puppet属于后期爆发类,对于部署能力较弱;
- Kolla ansible 采用容器方式去管理 Openstack 控制服务,前期部署比较轻便上手,对于后期的原子化和定制化较弱;
通过我们的对配置管理的理解和实践,最终我们选择 Kolla ansible 部署新控制节点,再通过开发新模块对现有L版本计算节点进行配置升级管理。计算节点主要包含了网络和计算控制服务,我们通过角色拆分,将其分为如下升级单元:
- 配置管理模块。将公共配置参数以集群为单位纳入目录中,如升级列表、集群公共配置参数、软件包版本,每套集群一套配置,并push至Git仓库管理;
- 升级前进行基础环境预热。卸载旧版本Python 基础库与Puppet 配置管理Agent,备份控制服务旧配置,准备完成后对当前环境检测是否达到升级标准;
- 计算、网络升级模块。主流程为优先停止服务,卸载软件包,更新软件包,下发配置,其中计算模块优先启动nova-compute,而网络控制服务在结束其它流程完成后再进行灰度单节点,主要由于升级ovs-agent会下发新流表,会有大规模断网风险;
- 存储升级模块。更新存储软件包,并在计算节点更新ceph 配置文件。
- Libvirtd升级模块。计算节点libvirtd 升级后自动刷新服务,保证服务能否正常管理kvm 虚拟机;
从更新基础软件包开始,最后灰度启动网络控制服务,为保证在升级过程中某一个服务出现问题时,可以快速定位到升级阶段问题,并根据当前细分模块进行优先级前后顺序排位,保证升级流程的可控和连贯。经过对测试集群进行的L-S的升级验证,把升级前、升级中、升级后的各项步骤整理成自动化脚本。随着对线上集群的升级,不断总结各个集群的不同点、问题发生点,同时对脚本进行不断地优化。最终在2个月的时间内,完成了方案制定、脚本编写、六个主力集群的全部升级任务。
| |
内核: 3.10.0-693
操作系统: CentOS 7.4.1708
ovs版本: 2.5.5
qemu版本: 2.6.0
libvirt版本:3.9.0 | 内核: 3.10.0-693
操作系统: CentOS 7.4.1708
ovs版本: 2.11.0
qemu版本: 2.12
libvirt版本:4.5.0存储:
多ceph集群 (glance和cinder需适配多ceph) |
有存量虚机的计算节点依然对接原始连接的ceph集群,同时支持cinder创建卷的方式,作为共享型物理机,可创建新虚机;
对存量虚机可进行:重启,停止,创建自定义镜像,热迁移,冷迁移,重装,挂载卷,卸载卷,调整配置;
无虚机的计算节点可以完全部署容器化的S版服务,作为企业级物理机;
glance服务对接已有的ceph集群,承载老镜像,能够创建新镜像,支持镜像多后端;
cinder服务,对接已有的ceph集群,支持从老镜像上创建云盘启动的虚机,支持存储多后端;
3.2.1 部署S版新控制节点
2. 收集L版集群计算,存储,镜像,网络相关信息;3. 根据收集到的信息,准备控制节点(也部署成计算用于后期验证);准备S版本的DB,LVS+域名解析,提前把控制节点的对应端口加到对应VIP端口;
确定keystone地址,region_name;
获取老ceph集群信息,准备ceph.conf;
在待升级集群中选择两台空机器部署S版控制节点,包括rabbitmq、nova-api、nova-conductor、nova-scheduler、placement-api、neutron-server、neutron-dhcp-agent、neutron-metadata-agent、neutron-openvswitch-agent、glance-api、cinder-api、cinder-volume等控制服务;
新cinder服务对接老的多ceph集群;
新glance服务对接老的多ceph集群;
3.3.1 导入计算、网络、存储、镜像数据
1. 导镜像数据: 将glance镜像信息导入到stein版glance里;2. 导计算数据:将L版的flavor,aggregate等信息导入nova_api表,将instances表等依赖信息导入nova表,生成request_specs数据表;3. 导存储数据:导cinder的volume信息;4. 命令行方式准备网络数据:创建network/subnet/port等依赖信息,因为DHCP使用的IP地址与老的相同,因此将老的DHCP端口down掉,测试虚机DHCP依然正常后,进行后续步骤;
3.3.2 升级老计算节点
1. 根据收集的老计算节点连接存储pool和ceph.conf的信息来准备nova.conf、neutron.conf等配置文件;2. 老计算节点前期准备:停止ovs-cleanup服务,获取当前nova、neutron、qemu、libvirt、ceph等版本信息,用以判断升级;3. 准备rpm包目录,分步骤升级,过程中一直执行虚机存活检测脚本,记录断网时间;
3.4.1 功能检测
1)ifdown eth0;ifup eth0是否正常
2)curl 169.254.169.254;
3. 功能检测(测试脚本:重启、停止、创建自定义镜像、挂载卷、卸载卷、热迁移、冷迁移、调整配置、重装,可创建新虚机到老物理机上);3.4.2 新集群补充初始化信息
1. 新建套餐,物理机打trait,新建网络QoS;4. 等集群全部升级完成后,删除L的endpoint;4.1.1 调度问题
对于L版本的紧耦合存储方式,计算节点和存储集群是一对一的关系,而代码升级后,原有用于存储池过滤的自研PoolFilter,用于aggregate过滤的自研TagFilter已不存在,需要使用新版本里的自研的AggregateInstanceMetadataFilter过滤器来负责存量虚拟机 metadata和aggregate metadata的匹配。因此需要将虚拟机记录的元数据从pool=xxx改为aggregate_instance_metadata:pool=xxx,使得可以与aggregate的metadata里记录的pool信息进行比较。信息一致,则表示该存量虚机可以调度到指定的aggregate里,存储池还是原有的存储池。对于新建虚机,由于计算节点和存储集群是存算分离结构,套餐内不带aggregate信息,而且是boot from volume云盘启动模式,计算不需要关心属于ceph 哪个pool集群。执行热迁移时,报错“Filter AvailabilityZoneFilter returned 0 hosts”。分析:导完aggregate等数据后,如果不重启nova-scheduler,nova-scheduler未感知到DB里的az等信息导致调度失败,因此要重启nova相关服务。处理方法:在数据库数据准备完成后,将控制节点所有服务重启一遍。placement里没有分配记录,所以placement里认为数据没有被分配,所以这里要在scheduler上加上scheduler里增加 CoreFilter、DiskFilter、RamFilter。4.1.2 Aggregate划分问题
- 原有粒度划分太小,若考虑CPU兼容性,会导致迁移域太小。
后续创建云盘启动的虚机,不做强制关联,因为热迁移的流程中:nova-conductor每次调度一台宿主机后,会检查CPU兼容性,如果不兼容则继续调度,这样的好处是不需要把宿主机划成小aggregate,提高灵活性;同时也能支持跨机型的冷迁移。4.1.3 多后端支持
由于S代码应用了多后端逻辑,需要在nova-compute在创建自定义镜像时,设置镜像的后端元数据。4.1.4 qemu升级后的兼容问题
原因分析:在qemu2.6.0里,hypervisor为windows选择的vif model是virtio, 升级到qemu2.12.0后win2k16和win2k12,win2k8选择的是e1000e,而在openstacknova的代码里kvm指定的validnetwork_model没有e1000e,所以产生”Requestedhardware 'e1000e' is not supported by the 'kvm' virt driver: UnsupportedHardware:Requested hardware 'e1000e' is not supported by the 'kvm' virt driver“报错第1种:
修改nova/virt/libvirt/vif.py 增加network_model.VIF_MODEL_E1000E, 重启openstack-nova-compute
第2种:
更改win2k12和win2k16,win2k8镜像属性 设置 hw_vif_model=virtio, 后续新建虚机不再使用e1000e;存量虚机在instance_system_metadata里添加image_hw_vif_model=virtio
4.2.1 Ceph client版本与Ceph server版本配合问题
L版集群使用的Ceph版本是较老的cephHammer 0.94.5.11版本,S版集群使用的是Ceph luminous 12.2.13-1.el7版本,升级L版本到S版本后,我们希望用Ceph 12.2.13的client版本,librbd1 也是用12.2.13版本去连接老的0.94.5.11的ceph集群。在过程中,发现ceph的0.94.5.11和12.2.13的feature支持不一致。如果不修改rbd_default_features会导致虚机挂载卷失败,为老虚机创建镜像,会报错不能clone。备注:13 = layering + exclusive-lock + object-map= 1+2+4+8, 详细features说明可查询ceph官网。
4.2.2 访问rbd是否开启认证
由于L版老集群和S版新集群在Ceph集群的认证方面,使用的密钥不一致,会强制重启失败问题,挂新volume失败,但实际上,Ceph集群是没有开启认证的,不需要ceph auth的配置。解决方法:不配置rbd_user和secret_uuid在L-S架构热升级中,最困难的点在于:如何保证在线业务0感知。在线业务数量庞大,备份复杂。业务特点不相同,无法在一个时间点能进行割接通知。在这种压力催动下,从最开始的重启物理机的方案,演进为无需重启物理机。从预计断网10分钟,到实际仅丢包1~3个,到流表补齐方案的丢包为0。在对6个机房的架构升级中,4个机房无感知,仅有2个机房的少量业务由于历史网络结构问题,受到影响。下面就总结一下常见的几个问题。4.3.1 安全组问题,qvo口和tap口并存导致网络中断
由于历史原因,老机房存在部分虚机的tap口连接到br-int(早期没有绑定安全组,不需要qbr桥),而部分虚机的tap口连接到qbr桥,因此底层虚拟化网络结构不统一。而升级到S版本后,集群默认虚机的tap口连接到qbr桥(默认绑定安全组,且用iptables规则实现),这导致控制层面与实际的转发层面不统一,会导致部分虚拟机网络不通。因此针对这种机房,除了数据库信息的同步外,还要关注转发面网络结构,针对虚机直连br-int的虚拟机,修改数据表ml2_port_bindings中的vif_details字段中ovs_hybrid_plug的值为false,这相当于告诉控制节点,该虚机不需要qbr桥。4.3.2 Ovs-cleanup服务问题
由于历史原因,老机房计算节点默认部署了neutron-ovs-cleanup服务,且该服务通过systemd进行管理,在启动和停止的时候会被激活执行,导致ovs port被全部删除,进而导致该节点上的虚拟机断网。而升级过程中由于会升级python基础库,neutron-ovs-cleanup服务会被停止,导致该服务被激活执行,进而导致断网。因此针对这种情况,需要在升级前将neutron-ovs-cleanup服务关闭但不触发执行操作。我们通过修改systemd中该服务的ExecStop动作即可。
4.3.3 并发60台升级、流表下发慢、断网15~60s
- 升级前的准备是指新控制节点的搭建、数据库信息的同步、计算节点配置的更新(比如更新nova、neutron的配置文件,关闭ovscleanup功能等),这些操作对计算节点的转发面不影响。
- 真正升级时,需要升级计算节点的基础库,更新版本并重启nova、neutron服务,这一步由于涉及到转发面流表的更新,在更新过程中可能会有流量中断,让用户感知到。
计算节点网络服务升级时(重启ovs agent)会去控制节点拉取必要的数据,用以下发流表。由于我们机房的计算节点规模相对较多,我们实测并发升级60台节点时,会有断网15——60s,只升级一台节点的话也会有十几秒中的断流,这是不可接受的。我们采取的方案是预下发流表,即在升级前下发高优先级流表,走normal转发。升级过程中,虽然会更新流表,但由于优先级低不会被匹配到,因此还走normal转发。等到升级完成后,再将该流表删除,让新版的流表生效。该方法实测是有效果的,可以做到对用户无感知,实现Openstack版本热升级。4.4.1 操作系统小版本问题
由于L 版本计算节点通过rpm 包方式安装,配置文件由puppet 管理,且L版本中基础库版本与社区中基础库存在差异化,我们把当前控制服务源代码统一做成rpm包方式,做到一次性预热和升级基础库,由于环境参差不齐,抽取多样本环境进行兼容型安装、卸载、启动测试,并总结了一套当前需要卸载和安装的软件列表作为基础,基本兼容Centos7 系列小版本计算节点升级,以减少人为升级过程中带来的流程上时间的复杂度。4.4.2 升级模块原子化
由于升级系统较多我们通过角色拆分,将其分为如下升级单元,保证升级过程中出现问题时快速停止操作进行排查。 | 升级列表,集群全局变量输入,变更软件包准备,备份配置文件,卸载旧版本 Python 基础库,传入新仓库 |
| 停止服务,卸载软件包,更新软件包,下发配置,启动服务 |
| |
| |
| |
| |
| 网络启动后,开始并发Ping 包,升级结束后统计宿主机上每台虚拟机的丢包数量 |
4.4.3 大并发升级问题
同时进行60台计算节点的软件包和neutron服务升级,业务侧收到较多报警。并发升级首先会造成控制层面突然大量的消息同步,流表更新不及时,导致大量虚机网络中断,而这些虚机可能属于一个LVS下的,进一步造成VIP down掉。解决方法:先完成升级软件包,然后再进行串行发布,串行发布以物理机为维度,一台上的虚机都通后,再进行下一台,即使业务的VIP下某个RS有问题,也不影响VIP。
4.4.4 控制节点部署问题
在将控制节点从2节点扩容为4节点时,控制节点上的rabbitmq集群不正常,导致neutron-ovs-agent重启后与neutron-server不能正常交互。解决方法:在rabbitmq容器中手动删除/var/lib/rabbitmq/mnesia文件夹,reconfig重建集群。早期部署新控制节点时,需选择合适机型配置,包括CPU,内存,磁盘大小,网卡等的考虑,避免中途扩容带来问题;对申请的数据库DB,LVS等,需考虑IDC,光纤,机房等问题,避免时延过高。虚拟化团队在2个月的时间内,完成了方案制定、脚本编写,到郑州,上海,北京6个主力机房的架构升级,4个机房无感知,仅有2个机房的少量业务由于历史网络结构问题,受到影响。整体过程可控,故障问题可快速修复,为公司IaaS底层架构做到了架构统一、运维统一、功能统一,非常有利于后续基础云的基座角色。未来,我们还将继续在多集群融合、多cell水平扩展等方面继续探索,目的是达到IaaS平台的更易管理、规模更大、更稳定健壮。最后也希望我们虚拟化团队能持续贡献有质量有参考价值的文章,不发水文。最后,有对IaaS感兴趣的仁人志士,欢迎后台私信获取在招岗位详情。简历直投地址: shiruizhen@360.cn





