






解析PostgreSQL系列已经过半
今天给大家分享的是Buffer Manager、Index-Only Scans、HOT
我们具体来看看崔鹏老师是怎么分析的吧
NO.1
体系架构概览
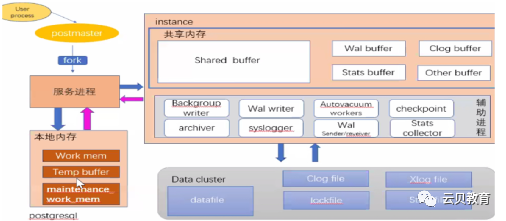
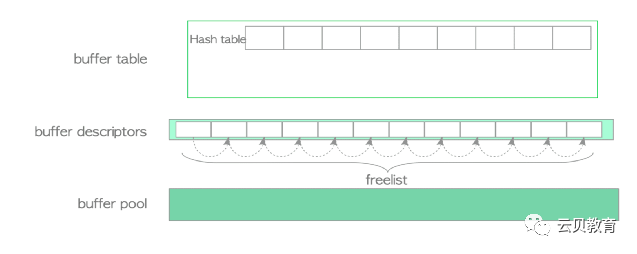
缓冲管理器结构

NO.2
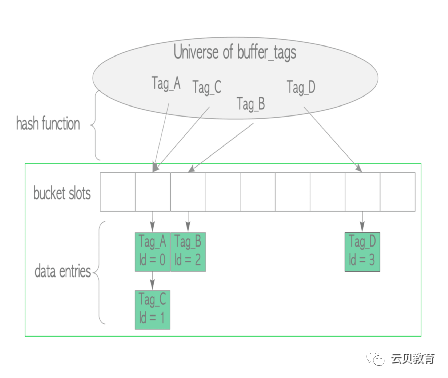
Buffer Tag(标签)
1.代表表空间、数据库、表的oid
2.关系表的分支号
2.1 主体数据文件 0
2.2 _fsm 空闲空间映射文件 1
2.3 _vm可见性映射文件 2
2.4 init文件 3 unlogged表
3.页面号
缓冲区标签由3个值组成
Buffer Tag(标签)
postgres=# select oid from pg_class where relname='test';oid-------16972(1 row)postgres=# select pg_relation_filepath('test');pg_relation_filepath----------------------base/13593/16972postgres=# select * from pg_tablespace;oid | spcname | spcowner | spcacl | spcoptions------+------------+----------+--------+------------1663 | pg_default | 10 | |1664 | pg_global | 10 | |postgres=# select ctid from test;ctid-------(0,1)(0,2)(0,3)(0,4)(0,5)(5 rows)
缓冲区标签举例:
表oid 16972数据库oid 13593表空间oid 1663主文件分支 0空闲空间映射fsm分支编号 1
缓冲区标签:
NO.3
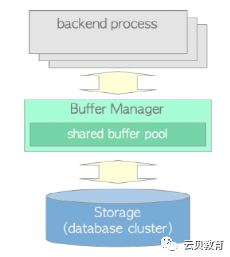
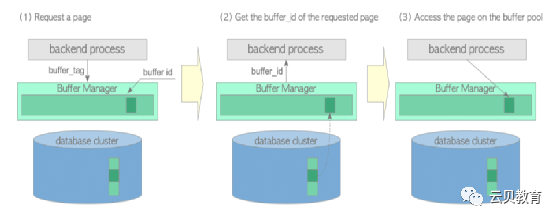
Backend Process Reads Pages
读操作
写操作
NO.4
缓冲管理器结构
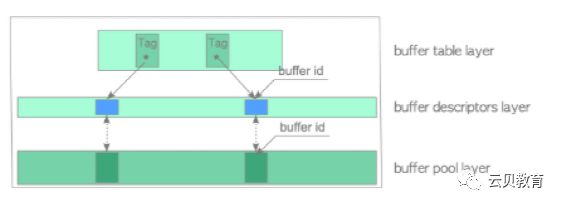
NO.5 缓冲管理器锁
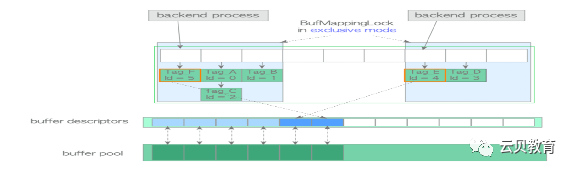
缓冲区管理器锁-缓冲表锁
自旋锁(Spin lock)
自旋锁的不足之处:
缓冲区管理器锁-内容锁
以下操作会获取独占模式的content_lock:
1.在相关元组被删除或更新行时发生更改(xmin/xmax变更)写操作
2.物理移除元组(vacuum和HOT触发)
3.FREEZE冻结
缓冲区管理器锁-IO进行锁
持有对应描述符上独占的io_in_progres_lock
typedef struct sbufdesc{BufferTag tag; /* 存储在缓冲区中页面的标识 */BufFlags flags; /* 标记位 */uint16 usage_count; /* 时钟扫描要用到的引用计数 */unsigned refcount; /* 在本缓冲区上持有PIN的后端进程数 */int wait_backend_pid; /* 等着PIN本缓冲区的后端进程PID */slock_t buf_hdr_lock; /* 用于保护上述字段的锁 */int buf_id; /* 缓冲的索引编号 (从0开始) */int freeNext; /* 空闲链表中的链接 */LWLockId io_in_progress_lock; /* 等待I/O完成的锁 */LWLockId content_lock; /* 访问缓冲区内容的锁 */} BufferDesc;
缓冲区管理器锁-自旋锁
下面是两个使用自旋锁的具体例子
钉住缓冲区描述符:
将脏位设置为"1":
1.获取缓冲区描述符上的自旋锁。
2.使用位操作将脏位置位为"1"。
3.释放自旋锁。
缓冲区管理器的工作原理
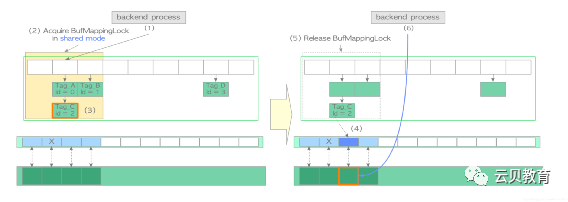
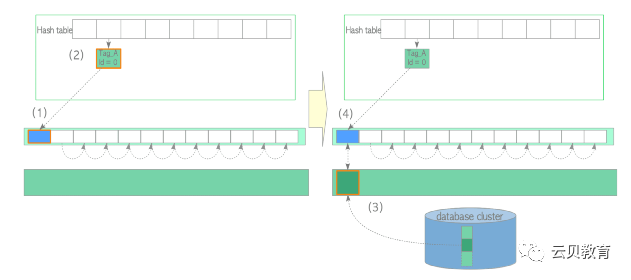
(1)查找缓冲区表(本节假设页面不存在,找不到对应页面)。创建所需页面的 buffer_tag(本例中 buffer_tag 为 ‘Tag_E’ )并计算其散列桶槽。以共享模式获取相应分区上的 BufMappingLock。查找缓冲区表(根据假设,这里没找到)。释放 BufMappingLock。(2)从 freelist 中获取空缓冲区描述符,并将其钉住。在本例中所获的描述符:buffer_id=4。(3)以独占模式获取相应分区的 BufMappingLock(此锁将在步骤(6)中被释放)。(4)创建一条新的缓冲表数据项:buffer_tag=‘Tag_E’, buffer_id=4,并将其插入缓冲区表中。(5)将页面数据从存储加载至 buffer_id=4 的缓冲池槽中,如下所示:以排他模式获取相应描述符的 io_in_progress_lock。将相应描述符的 IO_IN_PROGRESS 标记位设置为1,以防其他进程访问。将所需的页面数据从存储加载到缓冲池插槽中。更改相应描述符的状态,将 IO_IN_PROGRESS 标记位设置为"0",且 VALID 标记位设置为"1"。释放 io_in_progress_lock。(6)释放相应分区的 BufMappingLock。(7)访问 buffer_id=4 的缓冲池槽。
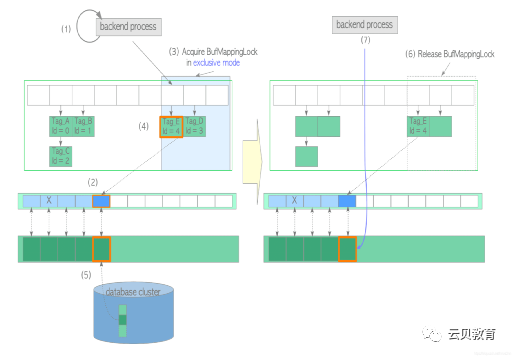
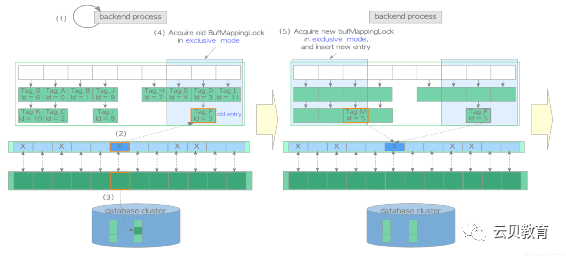
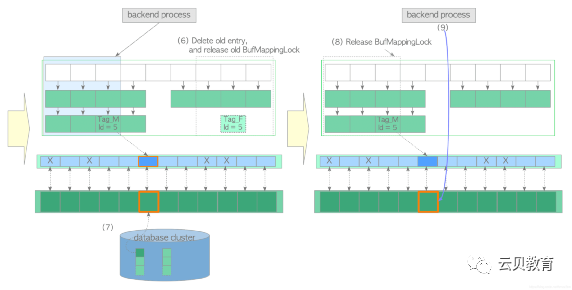
(1)创建所需页面的 buffer_tag 并查找缓冲表。在本例中假设 buffer_tag 是 ‘Tag_M’ (且相应的页面在缓冲区中找不到)。(2)使用时钟扫描算法选择一个受害者缓冲池槽位,从缓冲表中获取包含着受害者槽位 buffer_id 的旧表项,并在缓冲区描述符层将受害者槽位的缓冲区描述符钉住。本例中受害者槽的 buffer_id=5,旧表项为 Tag_F, id = 5。(3)如果受害者页面是脏页,则将其刷盘(write & fsync),否则进入步骤(4)。在使用新数据覆盖脏页之前,必须将脏页写入存储中。脏页的刷盘步骤如下:1. 获取 buffer_id=5 描述符上的共享 content_lock 和独占 io_in_progress_lock。2. 更改相应描述符的状态:相应 IO_IN_PROCESS 位设置为"1",JUST_DIRTIED 位设置为"0"。3. 根据具体情况,调用 XLogFlush() 函数将WAL缓冲区上的WAL数据写入当前WAL段文件。4. 将受害者页面的数据刷盘至存储中。5. 更改相应描述符的状态;将 IO_IN_PROCESS 位设置为"0",将 VALID 位设置为"1"。6. 释放 io_in_progress_lock和 content_lock。以排他模式获取缓冲区表中旧表项所在分区上的 BufMappingLock。(5)获取新表项所在分区上的 BufMappingLock,并将新表项插入缓冲表:创建新表项:由 buffer_tag='Tag_M’与受害者的 buffer_id组成的新表项。以独占模式获取新表项所在分区上的 BufMappingLock。将新表项插入缓冲区表中。(6)从缓冲表中删除旧表项,并释放旧表项所在分区的 BufMappingLock。(7)将目标页面数据从存储加载至受害者槽位,然后用 buffer_id=5 更新描述符的标识字段,将脏位设置为0,并按流程初始化其他标记位。(8)释放新表项所在分区上的 BufMappingLock。(9)访问 buffer_id=5 对应的缓冲区槽位。
页面替换算法:时钟扫描
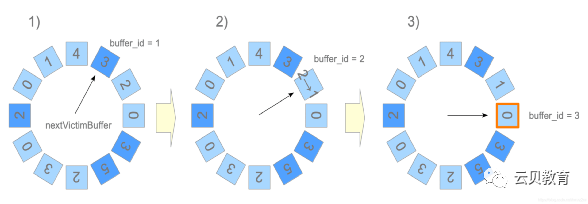
环形缓冲区
在读写大表时,PostgreSQL 会使用环形缓冲区而不是缓冲池。环形缓冲器是一个很小的临时缓冲区域。当满足下列任一条件时,PostgreSQL 将在共享内存中分配一个环形缓冲区:
COPY FROM 命令
CREATE TABLE AS 命令
CREATE MATERIALIZED VIEW 或 REFRESH MATERIALIZED VIEW 命令
ALTER TABLE 命令
脏页刷盘
为什么检查点进程与后台写入器相分离?
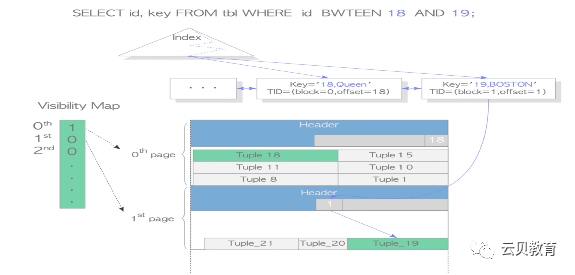
Index-Only Scans仅索引扫描
下面通过一个具体的例子,说明PostgreSQL中的index-only扫描是如何进行的。
testdb=# \d tblTable "public.tbl"Column | Type | Modifiers--------+---------+-----------id | integer |name | text |data | text |Indexes:"tbl_idx" btree (id, name)SELECT id, name FROM tbl WHERE id BETWEEN 18 and 19;id | name----+--------18 | Queen19 | Boston(2 rows)
仅索引扫描
Heap Only Tuple (HOT)
HOT作用
没有HOT更新后的索引
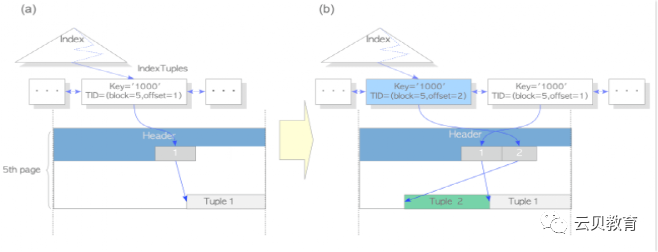
使用hot特性更新行
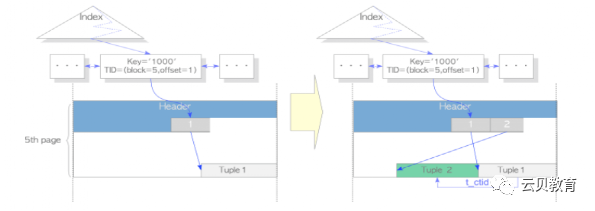

HOT-修剪
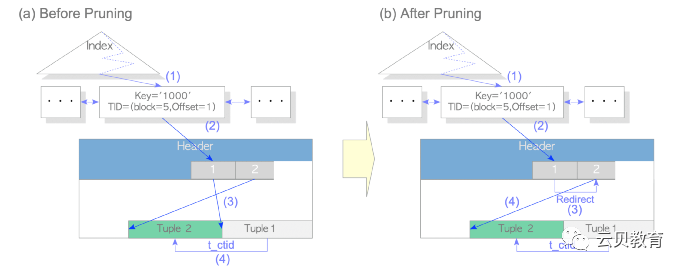
HOT-碎片整理
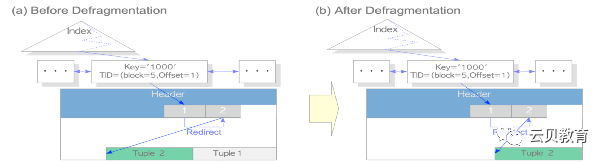
HOT 不可用的情况
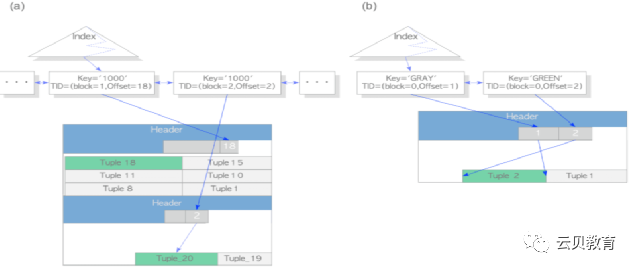

E
N
D

往期回顾
温馨提示
如果你喜欢本文,请分享到朋友圈,想要获得更多信息,请关注我 !
