




网页版阅读请前往博客:https://etolife.github.io/
1. 图数据库简介
1.1 什么是图数据库
图数据库是非关系型数据库(NoSQL)的一种,使用图理论对数据进行存储、管理和查询。图数据库中的数据以图结构的形式存在,即节点(node)结合和边(relationship)集合的组合,每个节点代表一个实体(entity),每条边则代表实体之间存在的关联关系,节点和边都可以拥有若干属性(property),每个属性是一个"键-值"对,泳衣对实体或关联关系进行具体描述。
1.2 为什么要引入图数据库
随着互联网的不断发展,传统的关系型数据库已经难以支撑当下的大数据量、高并发的场景。在这种背景下NoSQL(非关系型)数据库应运而生,图数据库正式NoSQL数据库中最典型的的一种。有人说“如果把传统关系型数据库比作火车的话,那么在大数据时代,图数据库就相当于高铁。”图数据库已经成为NoSQL数据库中关注度最高、发展趋势最为明显的新型数据库。
1.3 图数据库的发展趋势
在DB-Engines这个网站可以查看图数据库的最新发展趋势图:
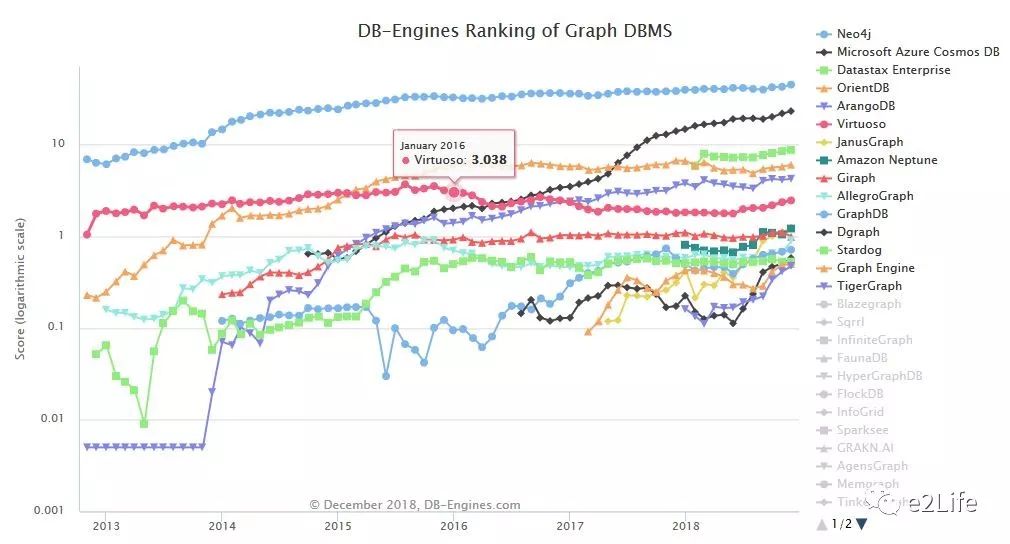
从该趋势图可以看到,Neo4j当前处于top1的位置,Neo4j是由java和scala实现的一种NoSQL数据库,相比于其他的图书库,Neo4j具有开源、跨平台、接口友好、完整支持ACID事务(事务支持是Neo4j与其他很多NoSQL的一个重要区别)等特点。
2. Neo4j的嵌入式模式和服务器模式
Neo4j最开始只是以嵌入式模式发布,Neo4j本身也是基于java开发,最开始的目标也是针对java领域,所以在嵌入式模式,java应用程序可以很方便地通过API访问Neo4j数据库,Neo4j就相当于是一个嵌入式的数据库一样。
后来随着Neo4j的慢慢普及,其应用范围开始涉及到一些非JVM的语言,所以为了支持这些非JVM语言也能使用Neo4j,所以发布了服务器模式。在服务器模式下,Neo4j数据库以自己的进程运行,客户端通过它的专用给予Http和REST API进行数据库调用。
下图显示了不同模式下对数据库访问的方式:
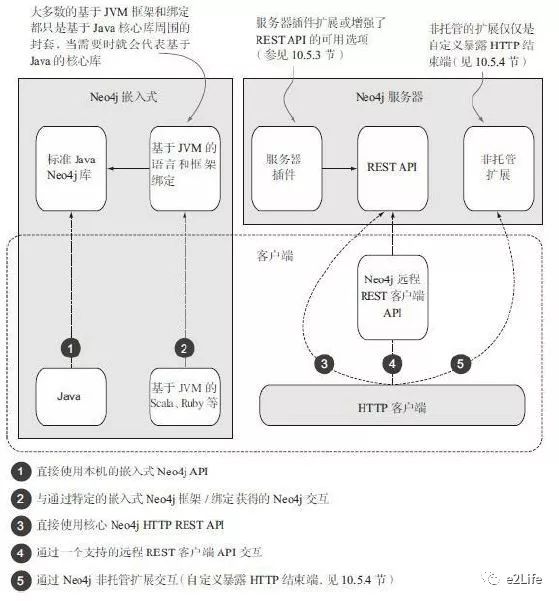
在嵌入式模式中,任何能够在JVM中运行的客户端代码都能在Neo4j中使用。可以以纯java客户端直接使用嵌入式模式,这里就是直接使用核心Neo4j库,本文后续的示例也是基于嵌入式模式,直接通过核心API调用数据库。
在服务器模式中,客户端代码通过HTTP协议,尤其是通过明确定义的REST API与Neo4j服务器交互。
3. Neo4j的安装
首先下载对应的数据库版本。
无需安装,解压就行,进入bin目录,执行批处理文件:neo4j.bat console
初始化完成后,就可以通过http://localhost:7474/browser/访问Neo4j的web页面(第一次登陆需要修改密码):

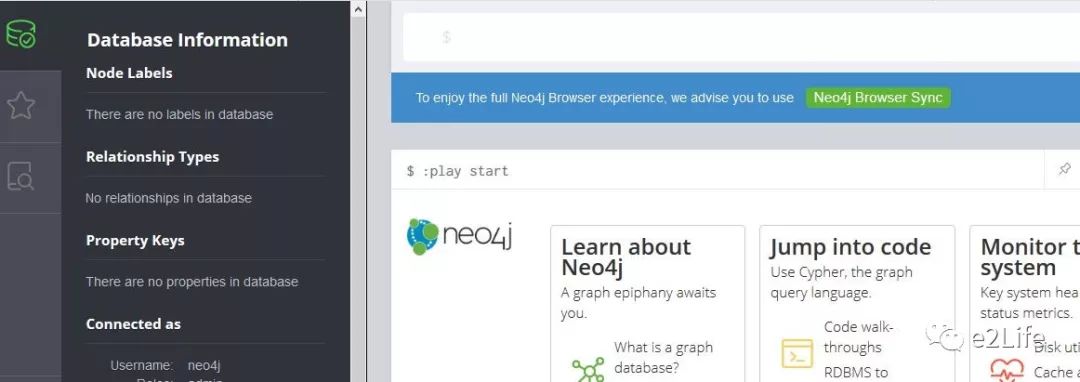
后面通过java API创建的图谱,存储到Neo4j数据库之后,web页面可以对数据库存储的内容进行一个可视化的显示。
web页面左侧的工具栏是数据库当前存储的一些节点信息以及版本信息,上面是命令行输入框,可以通过cypher语句对数据库进行操作,下面是可视化显示窗口,支持不同类型的可视化显示。
4. Neo4j应用实践
主要是通过核心API实现对Neo4j图数据的CRUD。
比如想创建如下的图谱关系:
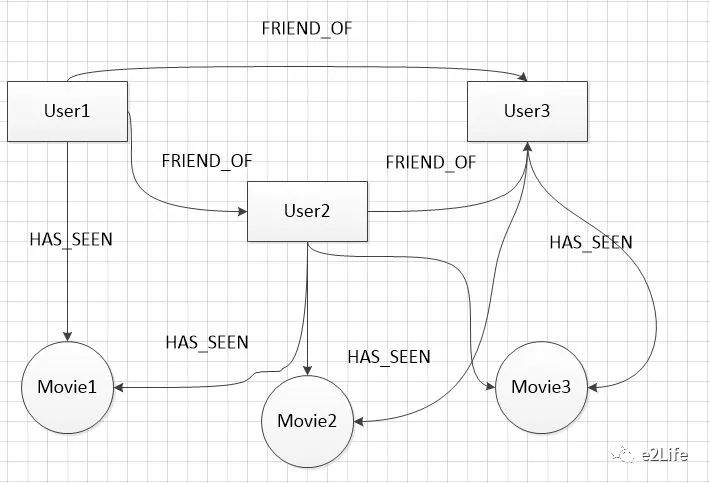
3个User节点各自具有属性,3个Movie节点,也都有不同的属性,节点间的关系如图所示,其中User节点和Movie节点间的HAS_SEEN关系还具有属性:用户对电影的评分打的星级。
step 1:创建maven工程,并导入Neo4j的依赖
<dependencies>
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j</artifactId>
<version>3.5.0</version>
</dependency>
</dependencies>
version填对应的数据库版本。
step 2:创建Neo4j数据库
通过GraphDatabaseService实例获取Neo4j数据库,传入数据库存放的位置:
String dbPath = "dataBase/graphDb";
GraphDatabaseService graphDb = new GraphDatabaseFactory().newEmbeddedDatabase(new File(dbPath));
如果是一个已经存在的数据库,就使用该数据库,如果该位置没有数据库,则创建一个空的数据库。
step 3:起事务
try (Transaction tx = graphDb.beginTx())
{
// commit transaction
tx.success();
}
这一段代码使用java 7的try-with-source语句,创建一个新的事务并定义一个事务将会使用的代码块。任何与数据库交互和在块内执行的语句将会在同一个事务中运行。
在try块末尾对success方法的调用表示当一个事务结束时应该有一个提价。当代码结束时事务完成,然后Neo4j会确保这个事务的提交,如果在对数据库操作时出现意外的情况,将不调用success方法,当事务结束时将回滚到原来的状态。Neo4j涉及是否提交或回滚的决策逻辑基于前面是否调用了success或faliure方法,如果想显示的回滚一个事务,可以调用failure方法,则事务将在程序块结束做无条件的回滚。
step 4:图谱创建及遍历
首先定义节点标签类型:
public enum SocialNetworkLabel implements Label
{
USER,
MOVIE
}
定义关系类型:
public enum SocialNetworkRelationshipType implements RelationshipType
{
FRIEND_OF,
HAS_SEEN
}
创建节点并设置属性:
Node xiaoming = graphDb.createNode(SocialNetworkLabel.USER);
xiaoming.setProperty("name", "xiaoming");
xiaoming.setProperty("age", 21);
创建关系并设置关系属性:
Relationship r1 = xiaoming.createRelationshipTo(titanic, SocialNetworkRelationshipType.HAS_SEEN);
r1.setProperty("stars", 5);
获取节点:
获取节点一般有两种方式,通过节点ID
graphDb.getNodeById(0);
以及通过遍历获取所有节点然后过滤:
Node hitUser = null;
for(Node node : graphDb.getAllNodes())
{
if(node.getProperty("name").equals("xiaoming"))
{
hitUser = node;
break;
}
}
节点遍历
我们想获取xiaoming没看过但是他的朋友们看过并且他的朋友都评价五星的电影,那么怎么对图数据库进行遍历呢?
第一种遍历: 循环遍历
Set<Node> recommendMoviesByFriends = new HashSet<>();
for(Relationship r : hitUser.getRelationships(SocialNetworkRelationshipType.FRIEND_OF))
{
Node node = r.getOtherNode(hitUser);
for(Relationship i : node.getRelationships(SocialNetworkRelationshipType.HAS_SEEN))
{
if(i.getProperty("stars").equals(5))
{
recommendMoviesByFriends.add(i.getEndNode());
}
}
}
Set<Node> recommendResult = new HashSet <>();
for(Node movie:recommendMoviesByFriends)
{
boolean newMovie = true;
for(Relationship j : movie.getRelationships(SocialNetworkRelationshipType.HAS_SEEN))
{
if(j.getStartNode().equals(hitUser))
{
newMovie = false;
}
if(newMovie)
{
recommendResult.add(movie);
System.out.println(movie.getProperty("name"));
}
}
}
第二种遍历,调Neo4j的API
// 定义遍历规则
TraversalDescription traversalMoviesFriendsLike = graphDb.traversalDescription()
.relationships(SocialNetworkRelationshipType.FRIEND_OF)
.relationships(SocialNetworkRelationshipType.HAS_SEEN, Direction.OUTGOING)
.uniqueness(Uniqueness.NODE_GLOBAL).evaluator(Evaluators.atDepth(2))
.evaluator(new RecomandEvaluator(hitUser));
Traverser traverser = traversalMoviesFriendsLike.traverse(hitUser);
Iterable<Node> moviesRecomend = traverser.nodes();
for (Node movie : moviesRecomend) {
System.out. println("Recomend Movie: " + movie.getProperty("name"));
}
先定义一个遍历规则,然后基于该规则对节点进行遍历,RecomandEvaluator为我们自己定义的遍历规则类:
public class RecomandEvaluator implements Evaluator
{
private final Node userNode;
public RecomandEvaluator(Node userNode)
{
this.userNode = userNode;
}
@Override
public Evaluation evaluate(Path path)
{
Node currentNode = path.endNode();
if (!currentNode.hasLabel(SocialNetworkLabel.MOVIE)) {
return Evaluation.EXCLUDE_AND_CONTINUE;
}
for (Relationship r : currentNode.getRelationships(Direction.INCOMING,
SocialNetworkRelationshipType.HAS_SEEN)) {
if (r.getStartNode().equals(userNode) || !r.getProperty("stars").equals(5)) {
return Evaluation.EXCLUDE_AND_CONTINUE;
}
}
return Evaluation.INCLUDE_AND_CONTINUE;
}
}
第三种遍历:通过Cypher语句遍历
Cypher基本语法后面会介绍,通过传入Cypher语句,执行execute方法,也可是实现对Neo4j数据库的访问:
String cypherQuery = "start xiaoming = node(0) match (xiaoming)-[:FRIEND_OF]-()-[r:HAS_SEEN]-(movies) where not (xiaoming)-[:HAS_SEEN]-(movies) and r.stars=5 return movies";
Map<String, Object> parameters = new HashMap<String, Object>();
try(Result result = graphDb.execute(cypherQuery, parameters))
{
while(result.hasNext())
{
Map<String, Object> row = result.next();
for(String key:result.columns())
{
System.out.printf("%s = %s%n", key, row.get(key));
}
}
}
三种方法遍历的结果都是一样的:
Recomend Movie: ShawShank
Recomend Movie: ForrestGump
5. Cypher语言基本语法
Cypher是Neo4j图数据库的查询语言,类似关系数据库中的sql查询语句。
5.1 Cypher语言的基本语法
Cypher语法由四个不同的部分组成,每一个部分都有对应的规则:
start:查询图形中的其实节点
match:匹配图形模式,可以定位感兴趣数据的字图形
where:基于指定条件对结果过滤
return:返回结果
5.2 Cypher执行
可以通过三种方式执行Cypher语句:
一. 使用shell命令执行Cypher查询
执行bin目录cypher-shell.bat文件,输入数据库的用户名密码,执行cypher语句即可:
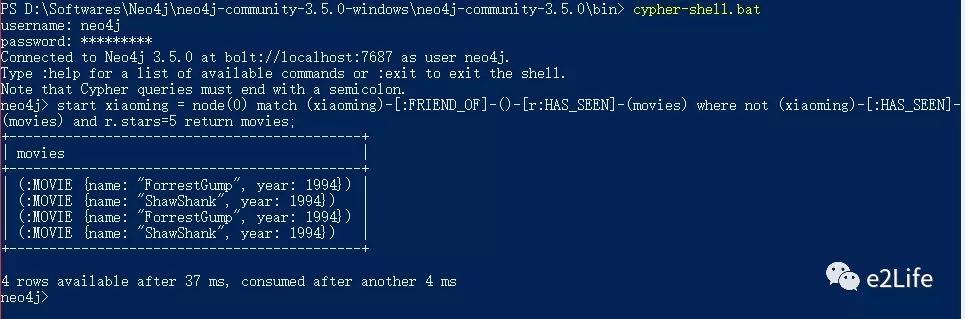
二. 通过web页面执行Cypher语句
登陆web页面,在命令行输入框执行Cypher语句即可:
三. 通过javaAPI传入Cypher语句进行执行
参照上面节点遍历中的第三种遍历方式。
5.3 Cyhper语句使用示例
结合Cypher语句的基本规则,以上面的查询遍历举例,查询xiaoming的朋友推荐的五星电影,并且是xiaoming没有看过的电影。
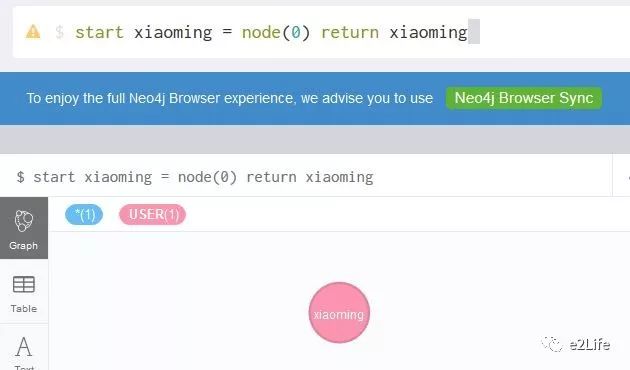
step 1:start语句查询起始节点
start xiaoming = node(0) return xiaoming
step 2:match语句进行模式匹配
match语句其实也比较简单,可以看成通过()-[]这几个符号,将想要匹配的模式图表示出来,比如想match到xiaoming的所有朋友,match (xiaoming)-[:FRIEND_OF]-()
,即表示匹配跟xiaoming这个节点具有FRIEND_OF关系的所有节点。
下面的语句,匹配xiaoming的朋友看过的电影:
start xiaoming = node(0) match (xiaoming)-[:FRIEND_OF]-()-[r:HAS_SEEN]-(movies) return movies

step 3:where语句进行条件过滤
通过where语句对匹配的结果进行条件过滤,下面的语句,过滤xiaoming没有看过的,并且他的朋友五星推荐的电影:
start xiaoming = node(0) match (xiaoming)-[:FRIEND_OF]-()-[r:HAS_SEEN]-(movies) where not (xiaoming)-[:HAS_SEEN]-(movies) and r.stars=5 return movies
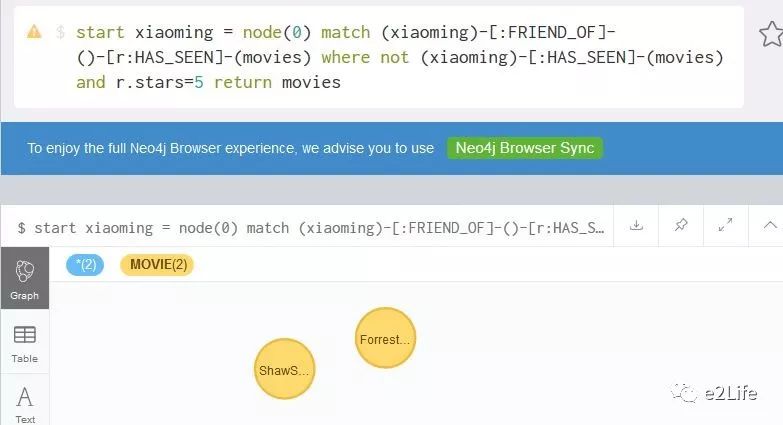
最终查询的结果,与通过java api查询的结果是一致的。
完整代码,参考GitHub
参考文献
Neo4j实战
Learning Neo4j
