





“重睛鸟”代码溯源及安全审查系统完全自主研制,包括代码溯源、许可证分析及感染性漏洞分析三个模块软件。本文主要介绍代码溯源模块的工作原理和关键技术,并首次提出了开源软件度量的新维度——基于代码溯源的开源软件演进过程量化分析方法,并选取开源操作系统、办公软件、数据库等软件,在业内首次通过代码继承性的量化分析,刻画软件的进化过程。

研究背景
授权/开源模式已成为重要的软件开发模式。据Gartner报告,99%的企业软件系统中引入了开源软件[1]。与此同时,在芯片领域,通过IP授权、架构授权和开源方式大量引用第三方代码或设计的情况普遍存在,RISC-V的快速兴起更助推了芯片领域的开源开发模式。2020年中国信息通信研究院发布的《开源生态白皮书》指出,我国使用开源技术的企业比例也已达到87.4%,较2018年增长了0.7个百分点[2]。开源代码的引入,为企业带来了高效率和低成本,然而由其衍生出的软件稳定性降低、代码库冗余和漏洞传递等问题也日益突出[3]。国际知名安全公司Black Duck对1000个商业代码库审计发现,有96%的企业使用开源软件,其中因引用开源软件而造成安全漏洞的比例超过60%[4]。厘清代码溯源关系,是摸清安全底数、修复通过引用代码的输入性漏洞、确定自主可控度的前提。该方向长期被国外垄断,不仅费用高昂且需提供代码,风险极大。
本文介绍了“重睛鸟”代码溯源及安全审查系统。该系统基于多级特提取、上下文敏感的值提取和基于特征元信息的搜索剪枝优化等溯源关键技术,提供软件/芯片RTL代码的溯源分析、文件/组件级许可证风险分析、输入性开源漏洞检测、代码级漏洞修复建议,并可视化展示分析结果。该系统已广泛应用于党政军权威单位,并即将通过中国计算机学会的GITLINK平台开放使用,对厘清代码引用链、评估国产化水平、核算开发成本、高效发现并消除漏洞感染链、实施开源治理发挥了重要作用。
研究现状
国外学者对代码克隆的研究始于20世纪70年代,相似度检测技术主要是基于属性计数(Attribute Counting)和结构度量(Structure Metrics)两类。相对于国外,国内在该研究领域起步的较晚一些。尽管国内学者在程序相似度度量领域开展了不少理论研究,但仍未出现相对成熟的相似度检测系统。根据对源代码信息使用程度的不同,代码克隆检测方法通常分为以下四个层次。
1.基于文本:将源代码表示为文本或token序列,使用模式匹配技术检查代码行间的相似度。主要包括Duploc、NICAD、Dup、Clone-Detective、CCFinder、CP-Miner等。该方法检测精度高,复杂度低,但由于信息损失量大而只能识别简单类型的代码克隆[3]。
2.基于度量值:将源代码切分成比较代码单元,然后通过抽取代码单元中的度量值进行代码克隆检测。有学者以函数为单元计算多种度量值,包括代码行数、函数的调用个数和McCabe圈复杂度等用于识别相似代码[5,6]。如,Kontogiannis等[7]选取了改进Albrecht的函数点度量值和改进的Henry-Kafura信息流质量度量值等5个度量值来捕获程序的数据与控制流信息,最后使用动态规划技术逐语句比较begin-end块检测代码克隆。此类方法复杂度低,准确率高,但漏检率会随比较代码单元粒度的增大而升高。
3.基于结构:提取源代码的语法级别信息,通过语法分析构建抽象语法树(Abstract Syntax Tree, AST),使用树匹配对子树进行相似检测。Baxter等[8]使用基于结构的方法开发了CloneDR工具,将代码转换成AST,通过识别AST子树计算所得的hash值,识别相似AST子树。Bulychev等[9]创建了Clone-Digger,并使用anti-unification计算AST间的距离用于检测相似度。李亚军等[10]提出用二叉树抽象语法树(Binary Abstract Syntax Tree, BAST)表示源程序的抽象语法,通过判断各语句BAST子树的同构性识别出相似的语句序列。基于语法的方法虽具有较高的准确性,但由于复杂度高,不适于过大规模相似代码的识别。
4.基于图:将源代码抽象为语义级别的程序依赖图,通过匹配算法得到相似子图。Mishne等使用概念图来表示程序代码,建立代码检索模型,与传统检索模型相比,使用含有代码结构和内容的概念图建模更利于高结构化代码文档的检索[11]。Komondoor等[12]提出通过使用程序切片识别PDG中的同构子图来识别克隆代码。国内研究者Liu等[13]开发了GPlag,通过PDG子图同构测试检测剽窃代码。虽然基于图的代码识别方法可获得较高精度,但该方法计算复杂度高、对代码多样化的识别能力有限,从而存在漏检等问题。
系统设计
系统介绍
“重睛鸟”代码溯源及安全审查系统是一款完全自主研发、面向主流语言的代码溯源及安全审查大数据平台,主要功能包括:软件源代码溯源分析、自主度评估、开源漏洞检测与预警、开源许可证合规性分析。平台目前覆盖了500多万个开源项目、1700多亿行源代码、1500多个许可证协议、20多万条漏洞信息,构建了国内最大的代码多级特征库,以及覆盖操作系统、数据库、中间件、办公软件等基础软件常用开源组件的安全漏洞库,支持分析结果多层次可视化展示。图1以OpenEuler测试结果为例,展示该平台对检测结果的综览:
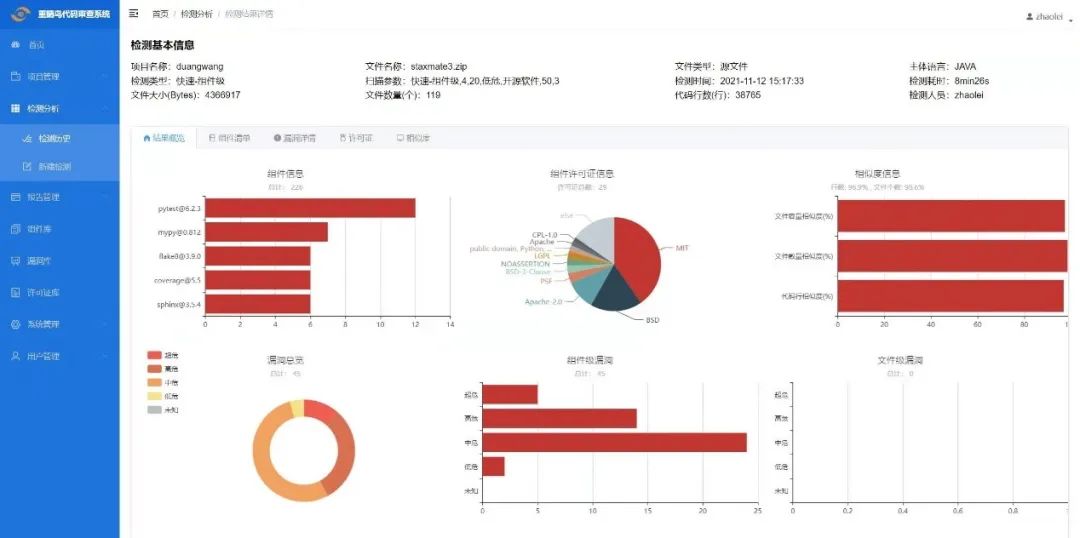
图1 “重睛鸟”代码溯源及安全审查系统检测结果概览
海量代码溯源模块介绍
“重睛鸟”代码审查系统突破混淆代码海量空间比对难题,使用多级特征提取技术、上下文敏感的值特征提取技术建立海量代码特征库,通过基于特征元信息的搜索剪枝优化技术缩小待测软件与代码特征库的比对空间,提高匹配效率,最终通过哈希字典的字符串匹配技术进行代码相似度的检测分析,可100%识别软件中大量存在的替换变量、函数名,增删语句等混淆情况,将匹配复杂度从O(n2)降低到O(n)。图2为海量代码溯源模块工作流程示意图:
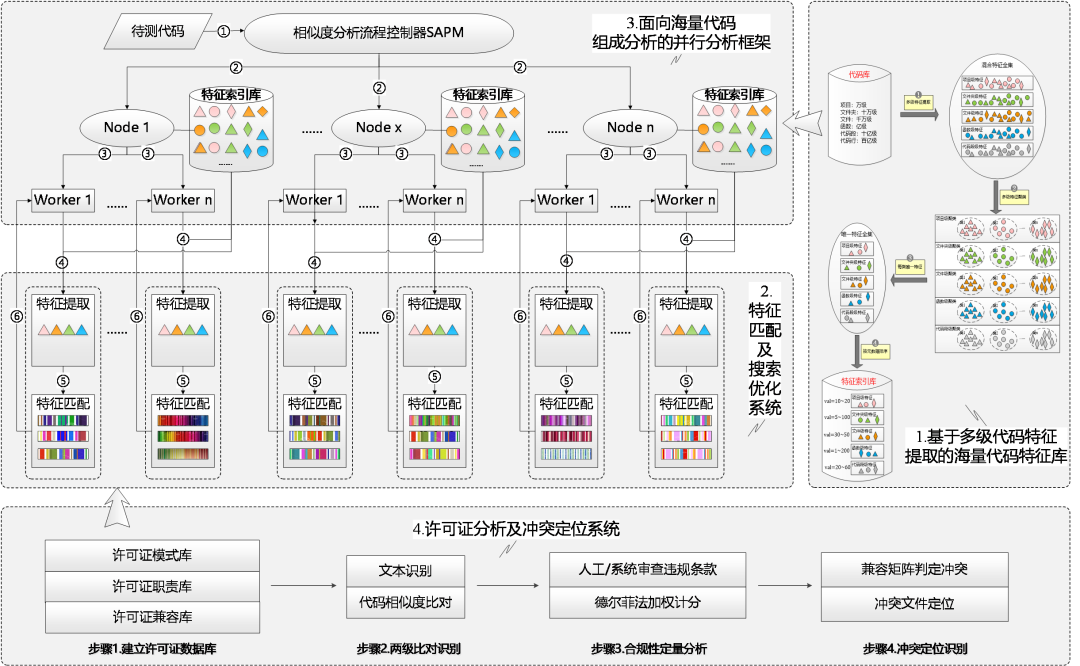
图2 “重睛鸟”系统的海量代码溯源模块流程示意图
海量代码溯源关键技术
基于聚类排重的海量代码特征库构建技术
为减少海量代码重复比对造成的冗余计算,本文提出使用聚类算法实现海量代码特征的冗余排重以及第三方库检测技术,显著降低了相同代码的搜索和比较次数。
针对万级项目规模的源代码,经过多级特征提取,生成具有项目级、文件级等特征的混合特征全集;接着分别对每个级别的特征进行聚类,并在每个聚类中都选用唯一特征表达该类的代码,生成特征全集;最后,计算唯一特征全集中每个特征的元数据,并将同一级别特征按元数据排序,生成特征索引库,如图3所示:
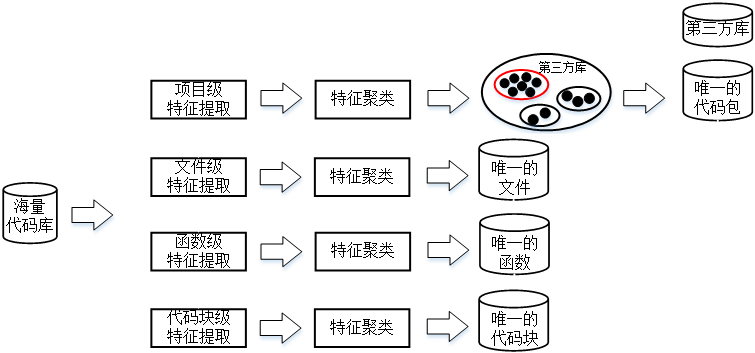
图3 基于聚类排重的海量代码特征库构建技术
基于上下文敏感信息的多级特征提取
系统采用多级特征提取方法,在代码库中预先获取并存储代码库中各软件项目全面的混合特征集合,使之可以表征软件项目的代码在文件级别和代码段级别两种尺度的信息。
使用变量在整个代码段的词频统计信息细化为在不同上下文(循环、分支、计算、访存等)中的词频构建上下文敏感的值特征,采用值特征匹配上下文敏感的设计结构进行代码相似度的检测。系统通过对软件项目两级特征的提取构成混合特征全集,根据不同的测试需求,提取待检测软件相应的混合特征子集用于匹配,从而很好的实现代码相似度检测分析。首先为代码段构建特征矩阵(如图4示),计数向量是对于变量在不同的上下文中出现的次数的组合。由于每个计数向量都代表了代码片段中的一个变量,把所有的计数向量组合到一起构建计数矩阵,该矩阵是对代码片段的全面概括。其次,在特征统计过程中,不同属性数据出于各自量纲的不同和属性差异的影响,统计结果存在较大的差别,导致数据之间难以进行有效比较,不利于结果的评估。为了消除数据属性差异的影响,本文对统计的原始数据进行适当的变换,以消除属性带来的差异影响。分别选择均值归一化和向量标准化用于消除属性差异的不良影响,并保证变换后的数据计算结果在[0,1]之间。
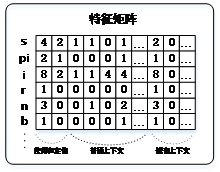
图4 特征矩阵
基于深度学习的特征匹配技术
系统引入了基于特征元信息的搜索剪枝优化技术,用于在源代码相似度检测中降低代码块比对空间和特征矩阵匹配的时间复杂度,以提高代码特征的匹配效率。该技术在特征矩阵匹配步骤之前根据代码块的代码典型特征,通过深度学习,选择与待测代码块接近的代码块,对代码库中的代码块进行过滤,缩小代码块比对空间。然后在特征矩阵匹配阶段,根据变量典型特征对特征矩阵进行按行排序,比对时待测代码块特征矩阵的每行只会与代码库中代码块特征矩阵相同行的上下几行进行比较,缩小比对行范围,进一步降低时间复杂度,即将O(m2)的时间复杂度降低为O(m)。
在此基础上,采用基于哈希字典的字符串匹配技术,通过构建两段代码的哈希字典,可以在线性时间复杂度和空间复杂度内实现字符串的匹配。具体操作步骤为:(1)将两段待匹配token序列进行哈希处理;(2)根据哈希值建立两段token的位置对应关系字典(即,哈希字典);(3)根据哈希字典进行两个token序列的最大公共子序列匹配(如图5所示)。
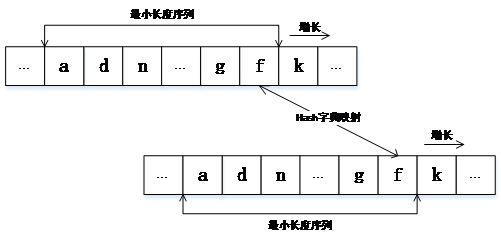
图5 基于哈希字典的字符串匹配技术
典型软件系统继承性分析
Linux内核
Linux已成为当前使用最广泛、影响力最大的开源软件。由于Linux内核庞大(如LinuxV5.13含72210个文件,30947449行代码)、迭代快、开发者众多,不同版本之间的继承度和差异迄今缺乏深入的量化统计。本文使用“重睛鸟”对现有66个Linux内核三级版本进行代码相似度比对,量化Linux内核进化过程。由于多数Linux临近版本间的比对结果相似,图6只展示部分具有代表性的比对结果。
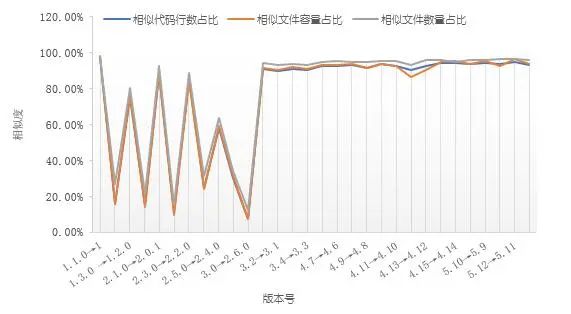
图6 Linux临近版本继承性分析
图6显示,三种相似度随时间的变化趋势接近,在绝对比例上存在少许差距。版本间相似度在发布初期上下波动幅度较大,后期随着版本的不断演进趋于稳定。其中,V3.0之前,各版本间经常出现较大的差异性,如V2.2.0与V2.1.0的相似代码行数占比仅10.57%,显示在系统功能建设方面进行了很大的改动。同样,V3.0与V2.6.0的相似代码行数占比仅7.17%,版本发布时间间隔8年,经历39个三级版本,在各方面都有很大提升,如 Btrfs文件系统整理、sendmmsg函数调用、支持CleanCache、支持Berkeley Packet Filter实时过滤等,解释了V2.6.0与V3.0之间的显著差异性。
经前期震荡,从V3.0版本开始,Linux内核系统趋于稳定,版本间具有很高的继承性(相似代码行数占比平均值为92.75%),且继承性呈缓慢上升趋势,显示Linux内核已经迈入成熟阶段。Linus Torvalds曾指出,V4.12是V4.9之后最重大的版本更新,其主要更新包括新增支持AMD Radeon RX Vega显卡,Nvidia GeForce GTX 1000 “Pascal”加速支持,启用BFQ和Kyber block I/O调度器等。图6中的数据印证了Linus Torvalds 的表述。通过对比临近版本的相似代码行数占比发现,V4.12对V4.11的继承性(90.32%)显著低于V4.11对V4.10和V4.13对V4.12的继承性(分别为92.37%和92.82%)。Linux4.12之后,继承度普遍在平均值以上微微震荡上行。
综上,本文认为,LinuxV3.0(2011年)是Linux步入成熟期的拐点,而LinuxV4.12(2017年)是Linux趋于稳定完善的里程碑版本。
MySQL数据库
开源数据库MySQL作为数据存储系统,具有体积小、性能优、安全、查询优化、效率高等优点,是广泛使用的开源数据库。由于MySQL V6.0版在开发过程中被中止,MySQL V 7.0版已在MySQL Cluster应用,本文分析了V4.0、V5.0和V8.0的三级版本间的代码相似度,结果如图7所示:
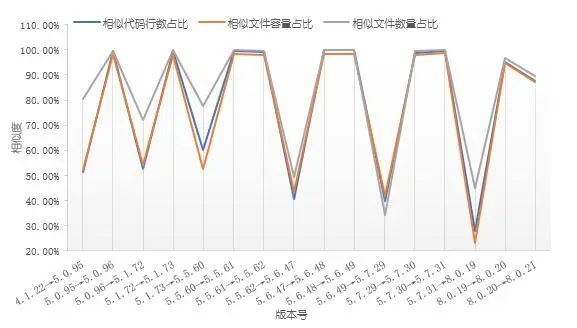
图7 MySQL临近版本继承性分析
图7显示,MySQL临近三级版本间的相似度极高,多数高达95%以上;临近二级版本间的相似度显著降低,相似度多降至40%左右;MySQL一级版本间的差异性最大,如V4.1.22和V5.7.31之间的相似代码行数占比只有5.4%。由此可见,MySQL小版本的更新迭代速度快,但每次更新的内容有限,一二级版本的更新周期长,却在性能、功能上有很大改动。通过相似度比较发现,V4.0、V5.0版本间的相似度较V5.0、V8.0版本间的低,即V5.0.95和V8.0.21的代码继承度高于V4.1.22和V5.7.31之间的继承度。这表明V4.0、V5.0系列版本处于快速迭代优化阶段,同时,V4.1至V5.7的代码内容可能发生重大变动。由MySQL的版本变更声明可知,在V5系列版本中,V5.5较V5.0增加了对Stored procedures、Views、Cursors、Triggers、XA transactions、slow query log的支持以及INFORATION_SCHEMA系统数据库,V5.5还引入了新的性能架构(performancn_shema, P_S),用于监控MySQL监控服务器运行时的性能,印证了本文的继承性分析结果。
GCC编译器
GCC编译器最初是为GNU操作系统专门编写一款编译器,现已被大多数类Unix操作系统(如Linux、BSD、MacOS X等)采纳为标准的编译器。本文使用“重睛鸟”对GCC各版本进行了代码相似度比对。

图8 GCC临近版本继承性分析
图8给出了GCC临近版本的代码相似度结果。随着GCC版本的增大,代码相似度呈现由低到高的变化过程,尤其是V5.0后,相似度数值快速升至80%以上,说明开发趋于稳定。而在V1.0至V5.0版本的进化阶段,代码相似度均处于较低水平。其中,V1.42与V2.95.1间的相似度最低,相似文件容量占比和相似代码行数占比仅为1.20%,经查询,造成这一现象的原因可能是1999年自由软件基金会(FSF)同意在GCC中接受EGCS代码,并于当年7月发布了首个整合EGCS和GCC的版本V2.95。
LibreOffice办公软件
LibreOffice是一款流行的开源办公软件,用于处理文本文档、电子表格、演示文稿、绘图以及公式编辑。2011年1月LibreOffice V3.3正式版首次发布,目前已升级至V7.1版。本文使用“重睛鸟”对各LibreOffice版本间的代码继承度进行了评估,考察LibreOffice的进化过程。
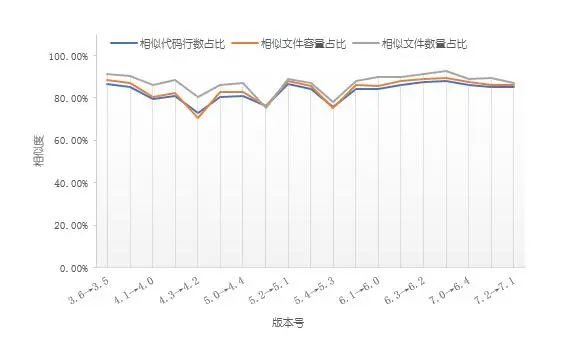
图9 LibreOffice临近版本继承性分析
如图9所示,LibreOffice临近版本间代码相似度变化幅度较小,相似文件容量占比平均值为84.04%,其中,V4.3与V4.2间的相似文件容量占比最低约为70.55%,表明LibreOffice在首版本发布时已具有很高的稳定性和成熟度。经分析,原因可能是LibreOffice是OpenOffice.org办公套件的衍生版,而OpenOffice.org是从StarOffice继承得来,在LibreOffice正式版本发布前,无论StarOffice还是OpenOffice.org都经历过版本的升级优化。因此,LibreOffice在推出时功能已经相对完善,版本升级发生的代码改动幅度相对较小,但目前仍处于不断优化阶段。
结论
本文介绍了“重睛鸟”代码溯源和安全审查系统中的代码溯源模块,并首次提出了开源软件度量的新维度——基于代码溯源的开源软件演进过程量化分析方法。选取开源操作系统、办公软件、数据库和编译软件,在业内首次通过代码继承性的量化分析,刻画软件的进化过程。下一步,我们将在提高知识库覆盖度、降低漏洞误报率方面进一步开展研究。
参考文献

程华
CCF理事。江南计算技术研究所研究员。主要研究方向为国产计算机系统一线研制和评测。主持研制“重睛鸟”代码溯源和安全审查平台。chenghua@ncic.ac.cn

谢美
国家超级计算无锡中心高级工程师。主要研究方向为信息产品成熟度评估、软件供应链安全治理。
xiemeisf@163.com

严婷婷
国家超级计算无锡中心中级工程师。主要研究方向为代码溯源与安全审查。yantingtingustb@163.com
特别声明:中国计算机学会(CCF)拥有《中国计算机学会通讯》(CCCF)所刊登内容的所有版权,未经CCF允许,不得转载本刊文字及照片,否则被视为侵权。对于侵权行为,CCF将追究其法律责任




点击“阅读原文”,查看更多CCCF文章。
