




今天介绍的是来自澜舟科技的周明博士在CCKS-2021的报告《复杂推理的进展与挑战——从LSAT讲起》。
讲座视频点击文末“阅读原文”,或请访问:
https://event-cdn.baai.ac.cn/live/20211228-01/特邀报告2.mp4

本演讲的目的是通过介绍这些问题和实验,分析复杂推理的存在的挑战,并探索未来可能的研究方向。
01
复杂推理与LSAT

首先是复杂推理,是指理解和分析已有的信息,应用推理机制期望得到正确的推理。复杂推理有十分广泛的应用空间,如解数学题,客服和医学诊断等等。
其中LSAT就是一个复杂推理的实例,LSAT是美国法律院校的入学考试,它考察学生的综合推理能力,涉及到多个领域。
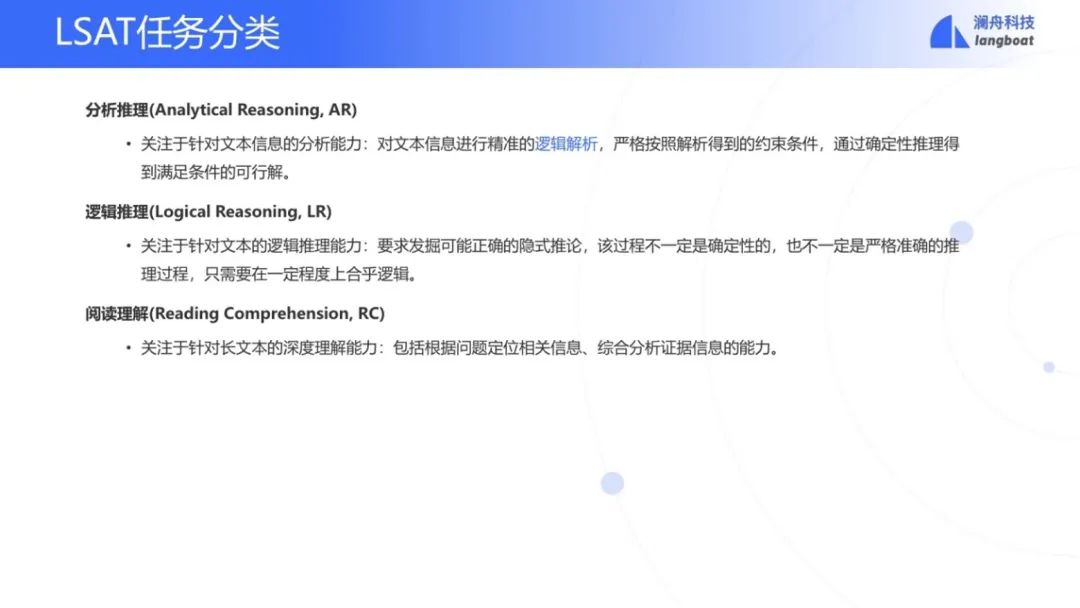
LSAT有三项任务:
分析推理 逻辑推理 阅读理解

这是三项任务的例子[1]:
分析推理(AR)。首先给出一个上下文。例如:有七个主任,ABCDEFG,要分配到两个委员会X,Y中。分配的时候要满足6个约束条件。比如说,如果A在X委员会,则B就得在Y委员会,等等。然后问题是:如果D和F都在Y委员会的话,则如下5个可能选择,哪一个有可能是正确的? 逻辑推理(LR)。也是先给一个上下文。例如:如果你不会用键盘,则不会用电脑;你不会用电脑,则你不会用词处理系统写文章。那么问题来了,如果这个上下文的说法是对的,那么下面哪一个逻辑推理是对的?比如第一个选项: 如果你有一些用键盘的技巧,你就能够用词处理系统写文章;显然选项一的推理是有问题。 阅读理解 (RC)。给一个文章作为上下文,抛出一个问题,选择一个合乎上下文的。
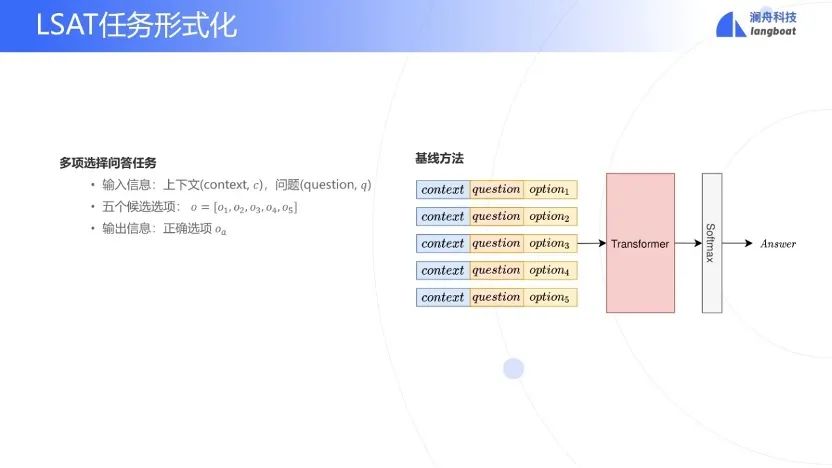
LSAT的任务,概括而言,就是一个多选QA任务。根据上下文和问题选择最佳的答案。那么可以设计这样一个baseline的方法,即上下文c,与问题q和一个选项o拼起来。把所有的选择拼的结果,都送到一个transformer中,然后输出层加一个softmax,得到每一个选择的概率,然而这种方法在LSAT任务中准确度很低。
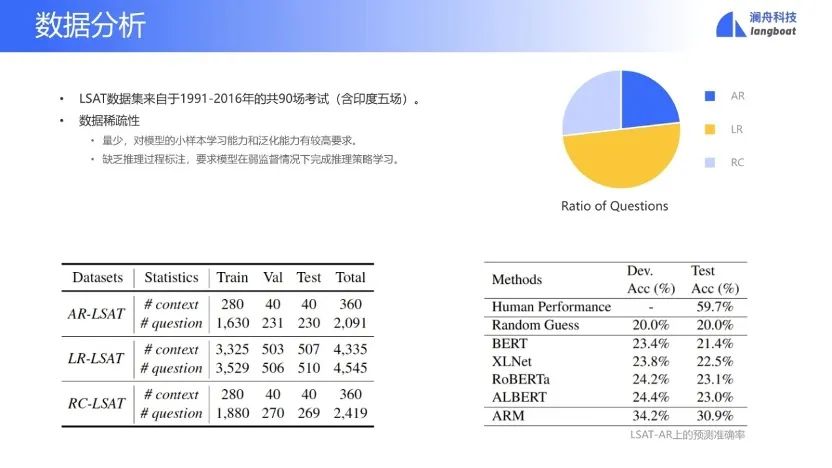
简单分析一下LSAT的数据集,一共90场考试,每场考试只有100题左右。数据的稀疏性说明模型需要小样本的学习能力,以减少对数据的依赖。
02
相关工作

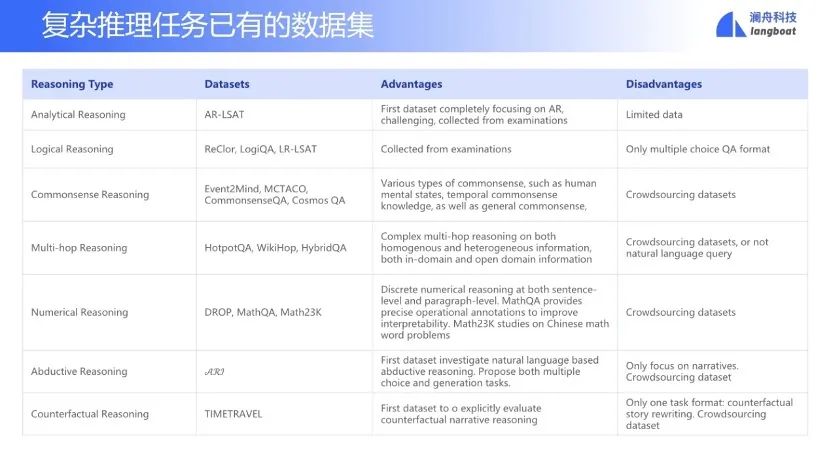
复杂推理的研究近几年呈现上升的趋势,分为以下几种类型。
逻辑推理。如LogiQA[2]中国公务员考试(类似LR) 常识推理。如CommonsenseQA[3]是只根据common sense(ConceptNet常识知识图谱)回答问题 多跳推理。如HotpotQA[4]和Wikihop[5]是常用的多跳推理问答数据集合 数字推理。如一个火车时速是60公里每小时,通过一个电线杆用了9秒钟。问火车长度多少?

基于考试的问答中,日本大学入学考试,中国高考的各科考试等,现有的方法尚不达到进入顶级大学的分数线。而这些任务面临通用的常识推理,基于常识的阅读理解的短板,并且需要对每一个科目编码相关知识。

符号模型是一种解决复杂推理的方法。用一组规则或者模板,识别推理的基本单位。执行确定和显示的推理,在离散的基本单元上预测答案。它的优势是由于人工写规则,本质上不依赖标注数据,具备不错的可读性和可解释性。而缺陷是需要专家知识和人工代价来制定规则。不容易跨不同的数据集合,抗干扰性和泛化性比较差。

使用神经网络模型,譬如预训练模型、图模型是另一种解决复杂推理的方法。它体现的是隐式的推理。优点是对噪音数据鲁棒性。不需要写繁琐规则。端对端训练。缺点是缺乏可解释性,需要依赖足够的训练数据(通常没有足够的标注数据),训练的计算代价大。

最后的模型就是神经符号模型,它融合了神经网络方法和符号方法。比如,在数字推理中,输入文本利用神经网络模块将其转换成一个逻辑表达式,然后通过一个符号系统执行这些表达式。再比如,在逻辑推理中,符号模块抽取推理单元进行推理,然后用一个神经模块学习连续向量来匹配答案。
03
分析推理

分析推理可以看作是一个约束满足问题。具体来讲,在之前举例时提到的有七个主任要分配到两个委员会的问题中,要理解有几个参与者,几个位置。理解约束条件,获得一个形式化表示(这里称之为一个program,程序)。判断每一个结论是否满足这些program,这需要一个推理过程。

这个问题有几个严峻的挑战。首先在上下文中的描述文字,并没有一个领域限制,是多样化的。第二,需要对上下文的精准的理解,有一部分出错就会完全错误。第三,这些候选答案都相似,答案不直接显式地出现在上下文中,必须要推理才行。
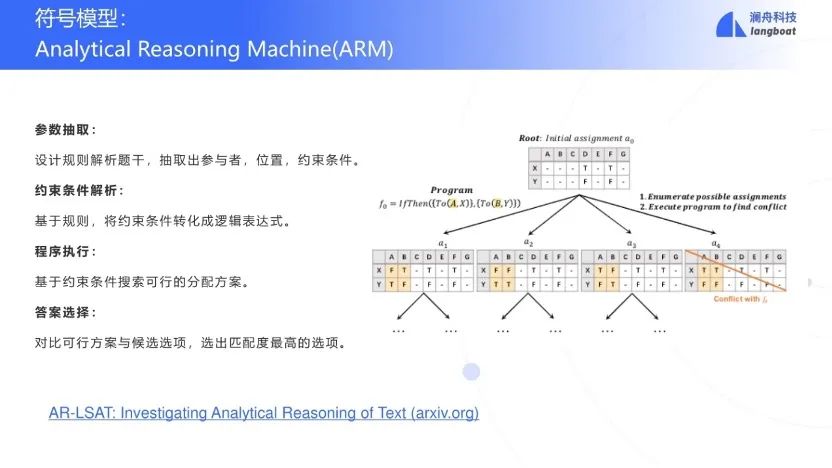
目前已经完成了一个符号系统求解这个AR问题,称之为ARM(分析推理机)[6]。首先要用NER和规则抽取论元:参与者(participant)、位置(position)和约束条件。随后利用parser将约束条件转换为程序,用执行器执行所有程序,产生一组合理的分配。最后再决定哪一个选项满足的这个合理的分配。
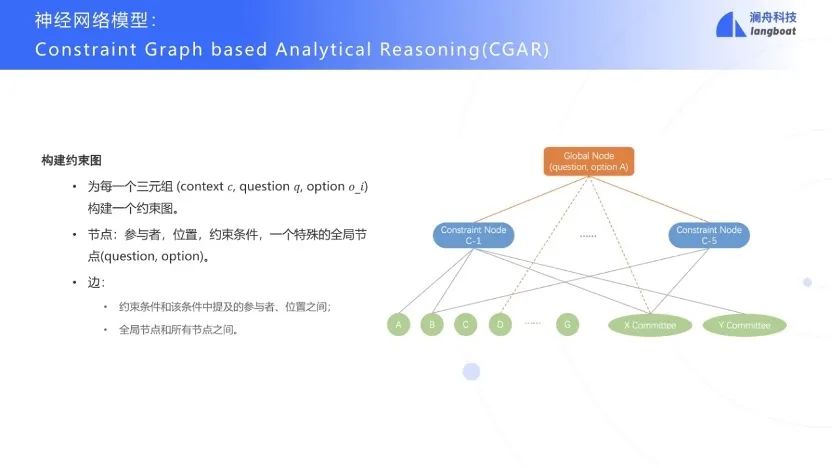
此外还设计了一个神经模块CGAR来简化ARM的人工代价。考虑到问题解决participant和position之间的约束关系,为了建模他们之间的关系结构,提出了构建约束图。这是一个异构无向图, 基于问题q,选项o构建全局节点,和所有约束条件节点链接,表示答案是否满足所有约束。

之后使用预训练模型对每个节点的文本编码,作为节点的初始表示,然后使用GCN建模约束图中节点之间的信息传递,最后使用全局节点的表示和预训练模型的表示串联起来计算当前option的得分。

最后还设计了一种神经符号系统的模型NSAR。由于训练需要标注好的program,但数据标注工作量巨大,因此仅标注了部分数据用于训练。
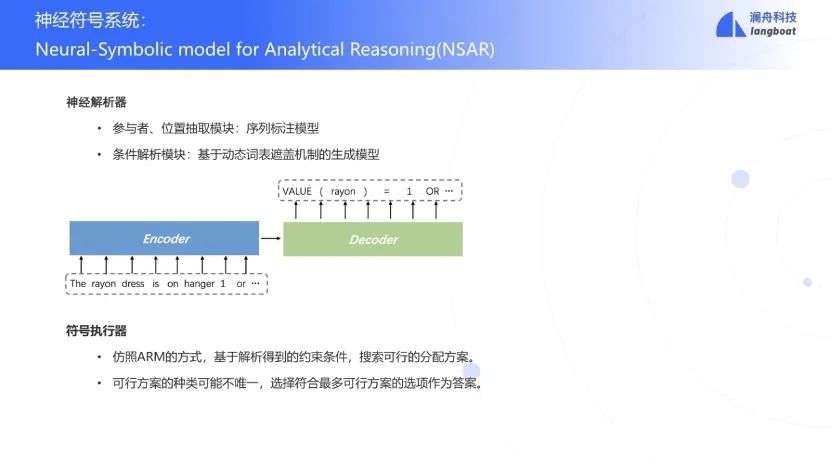
NSAR中利用NER模型抽取participant和position,然后再用encoder-decoder结构的semantic parser将每一个约束条件转换为对应的program。最后用执行器执行program得到结果。
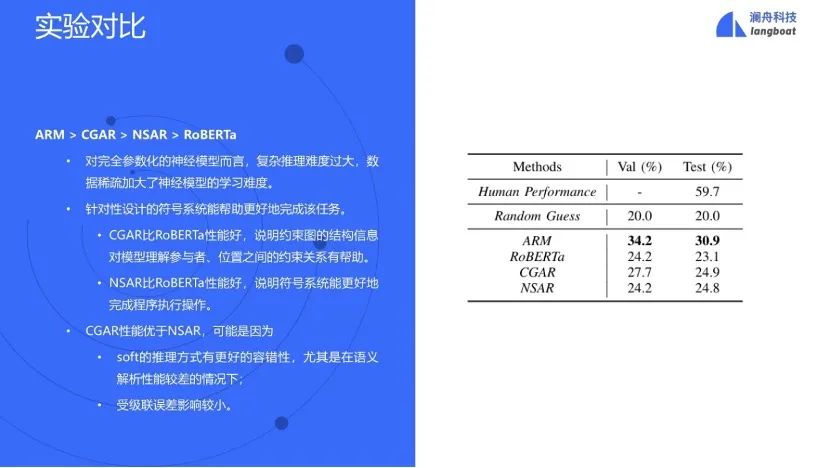
在以上几个模型的对比实验中,规则方法最好。说明现阶段全部参数化的神经模型很难处理这类AR问题。另一方面,CGAR比RoBERTa好,说明图模型的多次消息传递迭代有一定效果。NSAR比RoBERTa好,说明引入符号系统到神经模型有帮助。但是在数据标注不足的情况下,神经网络的效果不够好,会在执行器中将错误进一步扩大,导致最终的效果也不好,没有超过ARM和CGAR。

所有导致错误的情况中,有一小部分是由于participant和position没有抽取正确。此外,NSAR产生的program的rouge-L分数不低,但是精准匹配分数低。而program中只要有一点错误就会导致无法执行,或者产生错误结果,因此对于精确匹配的要求非常高。

以上的方法也有一些局限性,比如基于规则难以处理多样化的自然语言,而神经网络又依赖训练数据的数量,还有常识在模型中的缺失等等,因此未来的方向就在于如何在低资源场景下训练一个可靠的神经解析器,并且应用软推理来减少语义解析错误的影响,增加整个流程的鲁棒性。
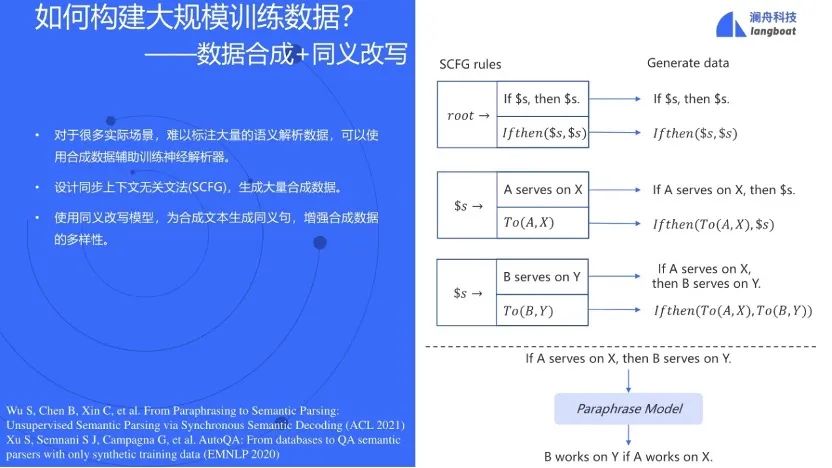
在数据缺失的情况下,可以用同步上下文无关语法SCFG来合成大量数据,即用CFG生成program的同时也生成对应的自然语言,再用同义改写(Paraphrasing)来增加数据的多样性[7, 8]。

此外,有不少语义解析的数据集也可以利用,如Text-to-SQL,Text-to-Prolog等等,训练一个基于T5的模型,使这个模型是一个拥有自然语言的逻辑理解能力的foundation model[9],最后用AR数据集finetune即可。

为了让模型能够在合成数据上也具有泛化性,采用元学习的训练方法[10, 11],让模型在同义语句上的loss尽可能相同。

根据以上两种方法设计的四组实验可以看到,仅用合成数据能达到25%的精确匹配,说明的确有效果,foundation model和元学习能进一步提升模型的结果,也证明了这些方法的有效性。
04
逻辑推理
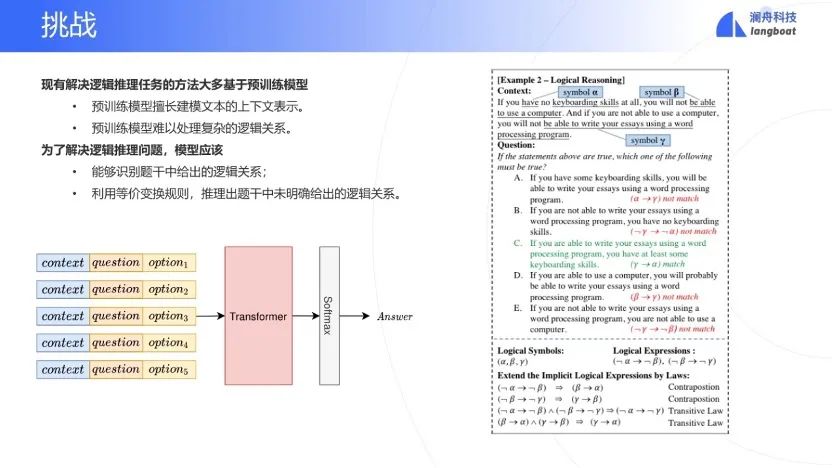
逻辑推理中,以前的方法主要依赖于预训练模型,并没有充分应用符号逻辑。而要解决LR问题,系统需要从Context中抽取重要的成分作为逻辑符号。根据逻辑等价率,执行逻辑推理,拓展逻辑表达式。

因此根据LR的特点,设计了一个新的模型LReasoner。首先抽出上下文的基本的逻辑单元,比如,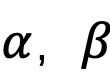 等。然后抽取其中的关系,譬如蕴含关系:
等。然后抽取其中的关系,譬如蕴含关系: 。然后利用逻辑公式做各种等价扩展。同时对选项也同样抽取逻辑单元和逻辑表达式,并增补进来。最后把这些增补的逻辑表达式转换为文字序列,用于答案匹配。
。然后利用逻辑公式做各种等价扩展。同时对选项也同样抽取逻辑单元和逻辑表达式,并增补进来。最后把这些增补的逻辑表达式转换为文字序列,用于答案匹配。

另外,模型也使用了逻辑驱动的数据增强。增加一些看起来像但是逻辑不同的context。比如删除一个逻辑表达式,对调一下逻辑符号的左右单元,取非等等。然后试用contrastive learning 来训练,增强逻辑理解能力。

与简单地用预训练模型,如BERT, RoBERTa,ALBERT等比较,LReasoner表现最佳,通过消融实验说明逻辑扩展和数据增强都对模型有很大的帮助。
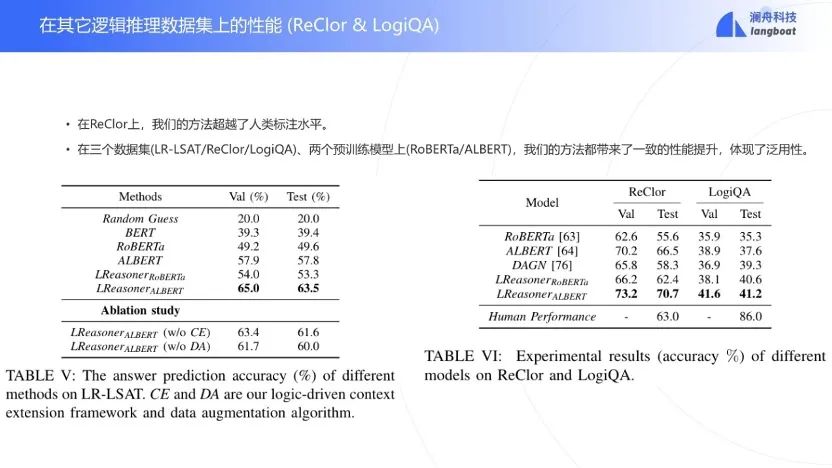
在其他数据集上也能有很好的表现,其中在ReClor[12]上甚至超过了人类的水平。

在以后的工作中,可以考虑设计一个能够有逻辑推理能力的预训练模型,并且在不同的推理任务上分开处理以达到更好的效果。
05
阅读理解
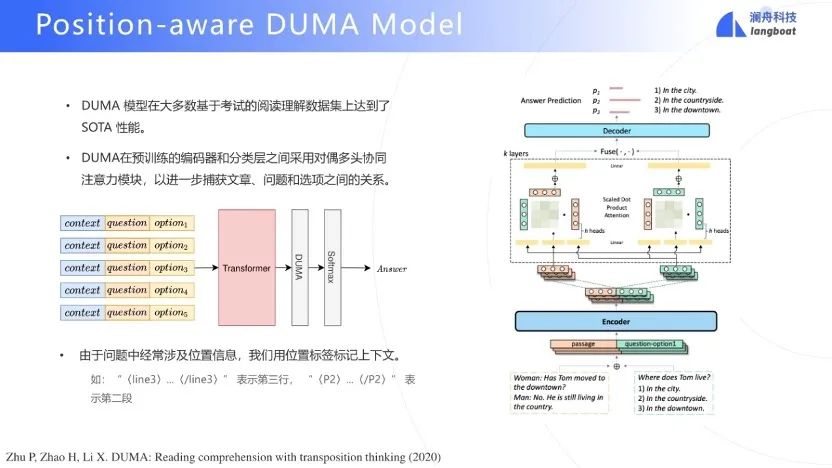
根据LSAT-RC的特点提出了position-aware的DUMA模型[13],其中DUMA指对偶多头互注意力模型。DUMA模型在LSAT-RC类型题目上是SOTA模型。基本原理是将上下文、问题、option合并在一起,多个option,多输入。经过一个DUMA层,使得context和option相互注意力。由于LSAT中会提问关于文本位置(如第xx行)的问题,在输入中加上了位置信息。
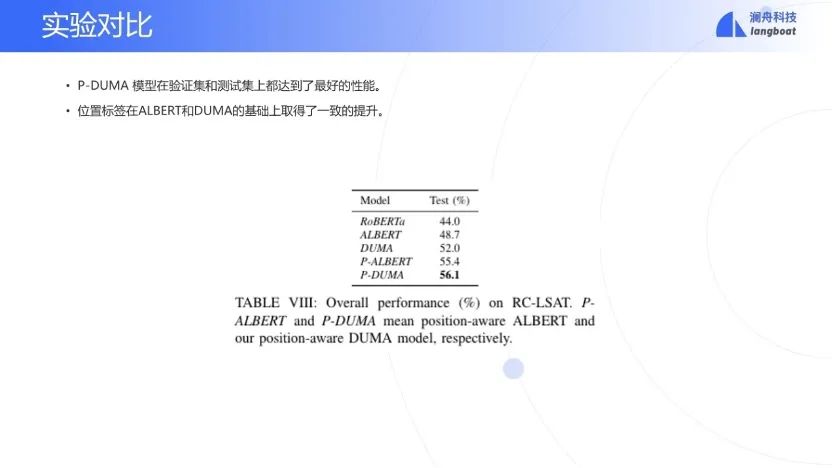
在LSAT-RC上的测试结果表明,position-aware的DUMA模型是最佳的模型。
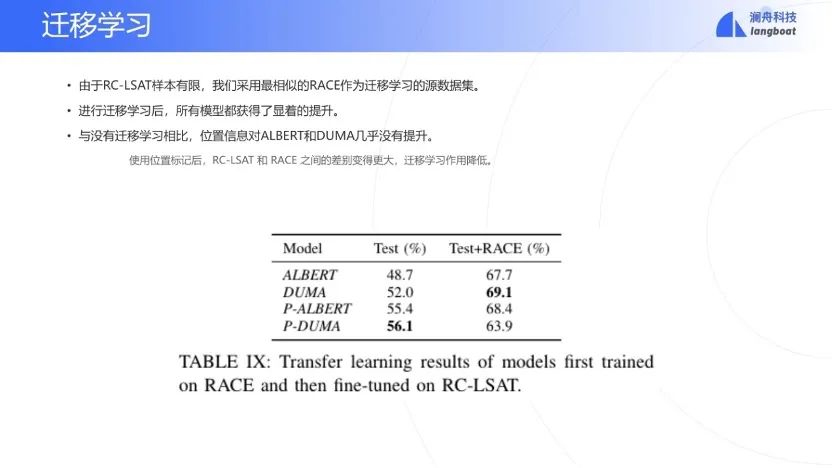
此外,由于LSAT-RC数据集样本有限,因此再测试了加入RACE数据集[14]作为迁移学习的源数据集的结果,模型获得了显著的提升,由于位置信息对RACE无用,因此迁移学习会导致P-DUMA效果提升不明显。

在LSAT-RC上的错误主要有三个问题:上下文太长;还没有加上对比较问题的处理;常识缺失导致有些问题做不对。
06
未来的发展思路
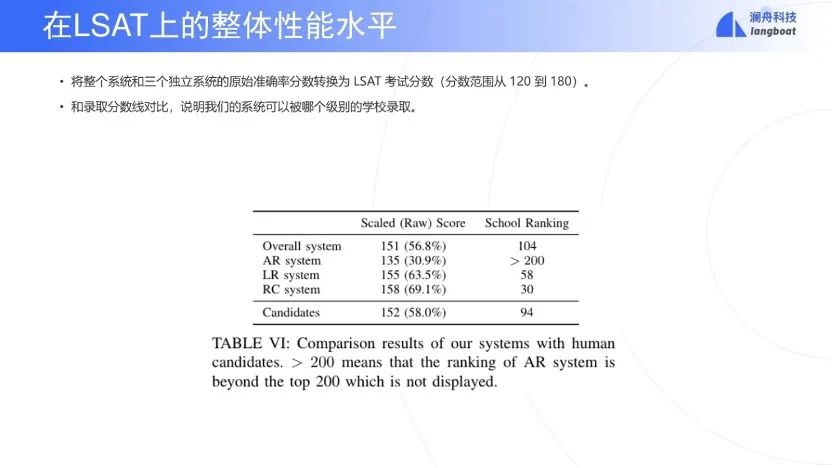
首先看一看LSAT的整体水平。LSAT的分数区间是120-180。交白卷就是120分,满分是180分。根据历年以来的一个统计,可以对应一下目前的模型可以上前多少名的大学分数线。总分可以得到151分,大概可以上到前104名的学校。AR分数差一些,只能上200名之后的学校。LR分数大概可以上第58名学校,RC分数大概可以上第30名的学校。因此目前可以考上一个一般的法律学校(学院),但是还是进不了前一百名,研究上还有很大的空间。

虽然LSAT很难,但也得到了一些正面的发现:
整体上,系统达到了一般学生的水准,说明机器有复杂推理的潜力。 RC和LR的水平可以分别被30名和58名学校录取。这两个方法都用到了预训练,也用到了跟任务相关的推理,说明这两者有一定有效性。 AR问题确实很难。现阶段求解这类问题,符号知识和符号推理还是必须的。

最后聊一下挑战和未来发展方向。首先是few-shot learning。借鉴迁移学习,转换从其他类似任务学到的推理能力,或者合成一些数据进行数据增强。

其次是模型的可解释性问题。模型可解释是关系到可信赖的推理体系,现在的神经模型缺乏可解释性。

常识推理的需求在之前的实验部分中也出现过几次,主要的挑战在于:
如何判断推理过程是否缺少常识知识,以及缺少什么样的常识知识。 常识知识比世界知识的范围更大,包含的内容更多,如何从大量相关的常识知识中精准地获取需要的知识,是非常困难的。 知识库总是不完备的,如果需要的知识无法从知识库中获取,那么应该如何应对?下方的例子中给出的就是知识库难以覆盖到的细节常识。
总体来说,常识推理的难点就在于知识库的构建和知识检索,如果完成了这两步,推理部分可以采用较为成熟的知识推理技术来完成。

最后,需要构建一个全面的评测集合。现有数据集合每一个可以深入评测复杂推理的各项主要能力。可以建立一个全面评测复杂推理的评测集合,将现有的其他评测任务可以纳入进来。比如常识推理、多跳关系和数据计算等集合。其他很少被研究的复杂推理能力,也应该予以考虑,如反事实推理,溯因推理等等。
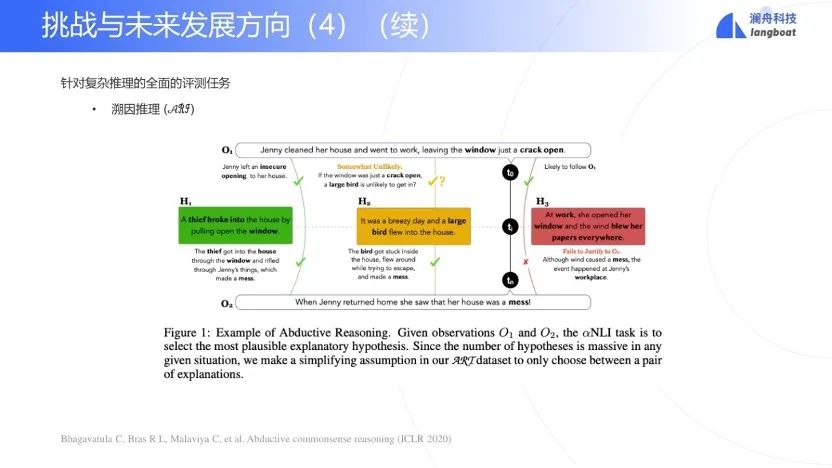
如图中例子,来自于数据集合ARI[15],给定两个observations,需要找到最有可能的解释。
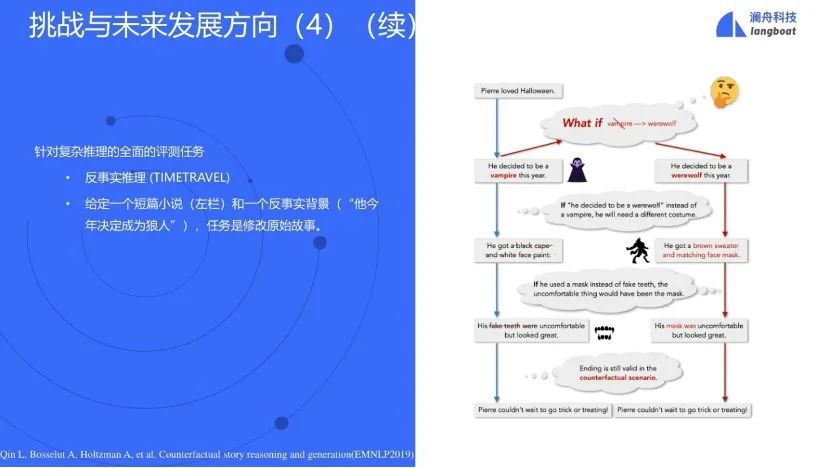
又比如,给定一个故事,如果用一个反事实更改了故事中的一个事件,需要推理出新的合理的故事结局。

总结一下,本讲座研究了LSAT三类推理问题。应用了符号方法、神经方法和混合方法。取得了一些进展。
针对AR问题,研究了符号模型、神经模型和混合模型。取得了比baseline好很多的结果。但是水准200名以外,说明还有很大差距。 针对LR问题,研究了神经-符号模型。用逻辑驱动扩展context和数据增强。 RC问题,研究了标注位置信息的对偶是多头共同注意力模型。基于预训练模型用RACE数据做模型迁移学习。
系统取得了不错的结果:LSAT的平均水准,但存在着很多挑战,如可解释性,few-shot learning,常识推理等等。

