




聚类
今天说聚类,但是必须要先理解聚类和分类的区别,很多业务人员在日常分析时候不是很严谨,混为一谈,其实二者有本质的区别。
-
分类
分类其实是从特定的数据中挖掘模式,作出判断的过程。比如Gmail邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选“垃圾”或“不是垃圾”,过一段时间,Gmail就体现出一定的智能,能够自动过滤掉一些垃圾邮件了。这是因为在点选的过程中,其实是给每一条邮件打了一个“标签”,这个标签只有两个值,要么是“垃圾”,要么“不是垃圾”,Gmail就会不断研究哪些特点的邮件是垃圾,哪些特点的不是垃圾,形成一些判别的模式,这样当一封信的邮件到来,就可以自动把邮件分到“垃圾”和“不是垃圾”这两个我们人工设定的分类的其中一个。 -
聚类
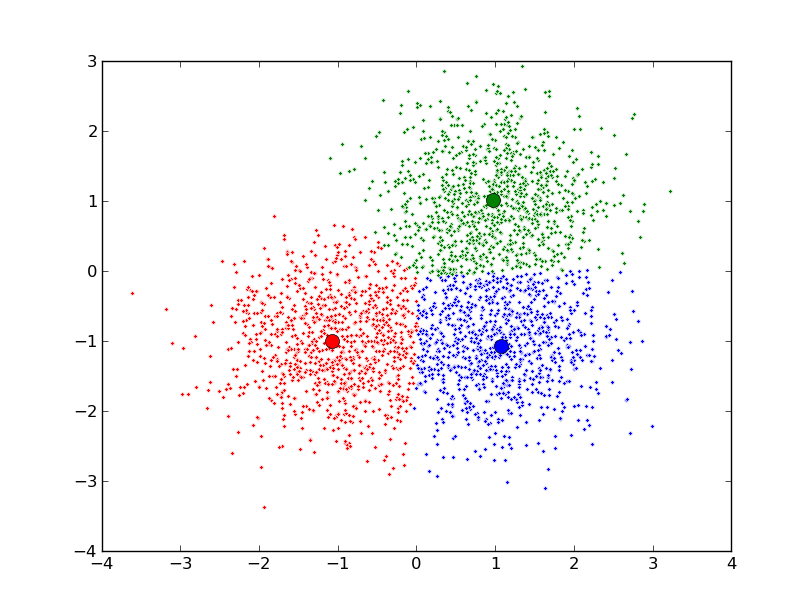
聚类的的目的也是把数据分类,但是事先我是不知道如何去分的,完全是算法自己来判断各条数据之间的相似性,相似的就放在一起。在聚类的结论出来之前,我完全不知道每一类有什么特点,一定要根据聚类的结果通过人的经验来分析,看看聚成的这一类大概有什么特点。 -
K-Means
聚类算法有很多种(几十种),K-Means是聚类算法中的最常用的一种,算法最大的特点是简单,好理解,运算速度快,但是只能应用于连续型的数据,并且一定要在聚类前需要手工指定要分成几类。
k均值聚类算法(k-means clustering algorithm)的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
Oracle中SQL使用K-Means示例
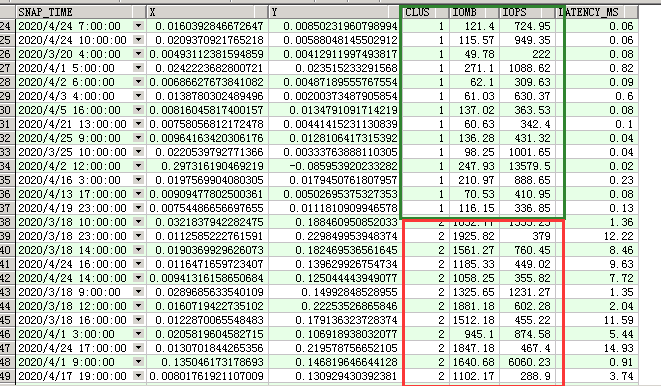
这个做个简单测试,使用python,主要关注SQL部分,简单展示了对于监控数据IOPS,IO吞吐量,延迟3个性能指标进行的聚类,自动分开了异常时间点与正常时间点
import cx_Oracle
import matplotlib.pyplot as plt
import numpy as np
connstr='user/password@192.168.56.210:1521/perfdb'
conn=cx_Oracle.connect(connstr)
c=conn.cursor()
#聚类,降纬,可视化
sqlstr="""
with t as (select trunc(SNAP_TIME,'hh24') SNAP_TIME,round(avg(IOMBS_PS),2) IOMB,round(avg(IOREQUESTS_PS),2) IOPS,round(avg(AVG_SB_READ_LATENCY),2) LATENCY_MS from gm.db_sysmetric
where instance_name='ORARPT1' AND SNAP_TIME>SYSDATE-40
group by trunc(SNAP_TIME,'hh24'))
,t2 /*降维*/as (
select snap_time,feature_id,value from (select snap_time,/*降维*/feature_set(into 2 using IOMB,IOPS,LATENCY_MS) over () fset
from t ),table(fset))
,t3 as(SELECT * FROM t2
PIVOT
( SUM(value) FOR feature_id in (1 as x,2 as y)
))
,t4 /*聚类*/ as (SELECT /*聚类*/ CLUSTER_ID(INTO 2 USING IOMB,IOPS,LATENCY_MS)over()AS clus,SNAP_TIME, IOMB,IOPS,LATENCY_MS FROM t order by clus)
select a.snap_time,a.x,a.y,b.clus, IOMB,IOPS,LATENCY_MS from t3 a,t4 b where a.SNAP_TIME=b.SNAP_TIME order by b.clus
"""
r=c.execute(sqlstr)
rs=r.fetchall()
x=np.array(rs)
plt.scatter(x[:,1],x[:,2],c=x[:,3])
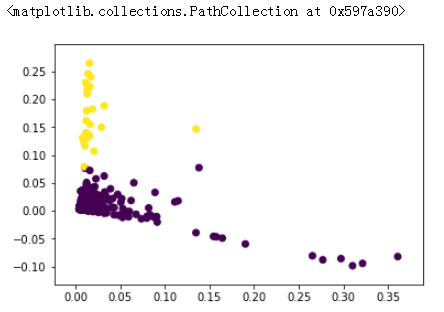
数据预处理,转换
该步骤对于数据分析模型/机器学习模型的准确性很重要
这里列了Oracle Machine learning文档中的相关内容参考
Binning
| Binning Method | Description |
|---|---|
| Top-N Most Frequent Items | You can use this technique to bin categorical attributes. You specify the number of bins. The value that occurs most frequently is labeled as the first bin, the value that appears with the next frequency is labeled as the second bin, and so on. All remaining values are in an additional bin. |
| Supervised Binning | Supervised binning is a form of intelligent binning, where bin boundaries are derived from important characteristics of the data. Supervised binning builds a single-predictor decision tree to find the interesting bin boundaries with respect to a target. It can be used for numerical or categorical attributes. |
| Equi-Width Binning | You can use equi-width binning for numerical attributes. The range of values is computed by subtracting the minimum value from the maximum value, then the range of values is divided into equal intervals. You can specify the number of bins or it can be calculated automatically. Equi-width binning must usually be used with outlier treatment. |
| Quantile Binning | Quantile binning is a numerical binning technique. Quantiles are computed using the SQL analytic function NTILE. The bin boundaries are based on the minimum values for each quantile. Bins with equal left and right boundaries are collapsed, possibly resulting in fewer bins than requested. |
Normalization
| Transformation | Description |
|---|---|
| Min-Max Normalization | This technique computes the normalization of an attribute using the minimum and maximum values. The shift is the minimum value, and the scale is the difference between the maximum and minimum values. |
| Scale Normalization | This normalization technique also uses the minimum and maximum values. For scale normalization, shift = 0, and scale = max{abs(max), abs(min)}. |
| Z-Score Normalization | This technique computes the normalization of an attribute using the mean and the standard deviation. Shift is the mean, and scale is the standard deviation. |
Outlier Treatment
| Transformation | Description |
|---|---|
| Trimming | This technique trims the outliers in numeric columns by sorting the non-null values, computing the tail values based on some fraction, and replacing the tail values with nulls. |
| Windsorizing | This technique trims the outliers in numeric columns by sorting the non-null values, computing the tail values based on some fraction, and replacing the tail values with some specified value. |
