




Patroni 具有丰富的 REST API, Patronictl 自身在 leader 竞选中使用了 patronictl 工具, 以执行故障转移/切换/重新初始化/重新启动/新加载, 通过 HAProxy 或任何其他类型的负载平衡器来执行 HTTP 健康检查 , 当然也可以用于监视。
可以分为:终端健康检查、监控终端、集群状态终端、配置终端、切换和故障转移终端、重启终端、重载终端、重新初始化终端。
终端健康检查
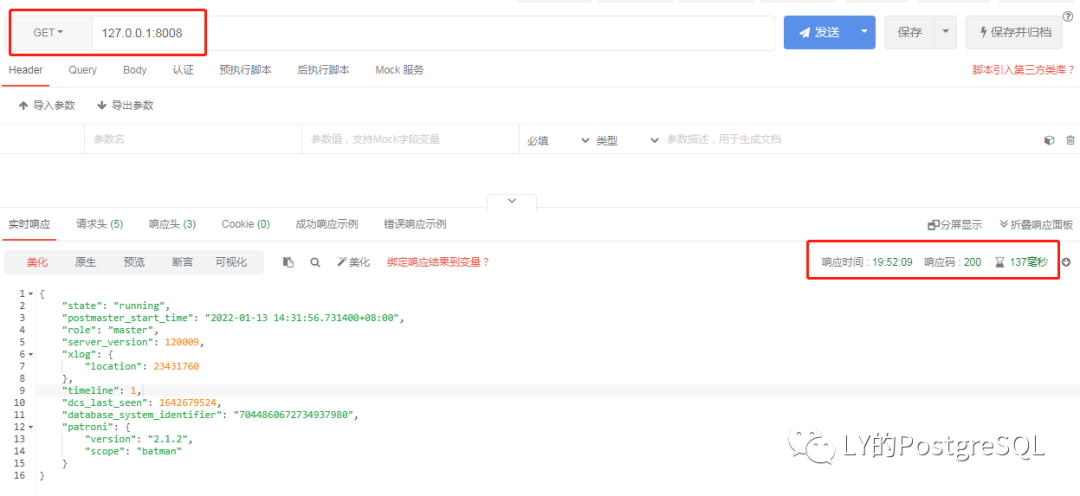
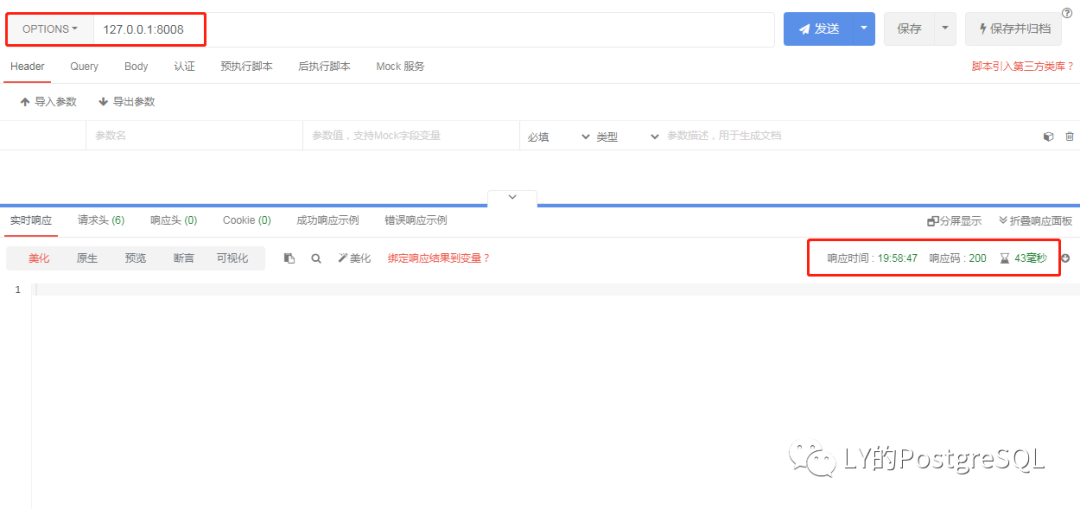
对于运行状况检查, GET 请求 Patroni 返回一个 JSON 文档以及该节点的状态以及 HTTP 状态代码。不需要 JSON 文档,则可以考虑使用 OPTIONS 方法。
GET 方法:
OPTIONS 方法:
当 Patroni 节点作为领导者运行时, 以下对 Patroni REST API 的请求将返回 HTTP 状态代码 200:
GET /GET /masterGET /leaderGET /primaryGET /read-write
GET /standby-leader:当 Patroni 节点作为备用集群中的领导者运行时,才返回 HTTP 状态代码 200。
GET /leader:当 Patroni 节点拥有领导锁(leader lock)时,返回HTTP状态代码200。与前两个端点的主要区别在于,它没有考虑PostgreSQL 是作为 primary 还是 standby_leader 运行。
GET /replica:副本(replica)运行状况检查。仅当 Patroni 节点处于running 状态、角色(role)为 replica 且未设置 noloadbalance 标记时,它才会返回 HTTP 状态代码 200。
GET /replica?lag=<max-lag>:副本检查端点。除了从副本检查外, 它还检查复制延迟并仅在低于指定值时才返回状态码 200。DCS 的 key:cluster.last_leader_operation 用于计算 Leader wal 和副本上由于性能原因产生的延迟。max-lag 可以字节(整数)或可读的值指定范围, 例如 16kB, 64MB, 1GB。
GET /replica?lag=1048576GET /replica?lag=1024kBGET /replica?lag=10MBGET /replica?lag=1GB
GET /replica?tag_key1=value1&tag_key2=value2:副本检查。此外,它还将在yaml配置管理的标记部分检查用户定义的标记 key1 和 key2 及其各自的值。如果没有为实例定义标记,或者 yaml 配置中的值与查询值不匹配,它将返回HTTP状态代码503。
在以下请求中,由于我们正在检查 leader 或 standby-leader状态,Patroni 不会应用任何用户定义的标记,它们将被忽略。
GET /?tag_key1=value1&tag_key2=value2GET /master?tag_key1=value1&tag_key2=value2GET /leader?tag_key1=value1&tag_key2=value2GET /primary?tag_key1=value1&tag_key2=value2GET /read-write?tag_key1=value1&tag_key2=value2GET /standby_leader?tag_key1=value1&tag_key2=value2GET /standby-leader?tag_key1=value1&tag_key2=value2
GET /read-only:与上述端点一样, 也包括主要端点。
GET /synchronous 或 GET /sync:仅当 Patroni 节点作为同步备用运行时,才返回HTTP状态代码200。
GET /asynchronous 或 GET /async:仅当 Patroni 节点作为异步备用运行时,才返回HTTP状态代码200。
GET /asynchronous?lag=<max-lag> 或 GET /async?lag=<max-lag>:异步备用检查端点。除了从异步或异步检查外, 它还检查复制延迟并仅在低于指定值时才返回状态码 200。DCS 的 key:cluster.last_leader_operation 用于计算 Leader wal 位置和副本上由于性能原因产生的延迟。max-lag 可以字节(整数) 或人类可读的值指定, 例如 16kB, 64MB, 1GB。
GET /async?lag=1048576GET /async?lag=1024kBGET /async?lag=10MBGET /async?lag=1GB
GET /health:仅在PostgreSQL启动并运行时返回HTTP状态代码200。
GET /liveness:始终返回 HTTP 状态码 200, 仅表示 Patroni 在运行。可以用于 livenessProbe。
GET /readiness:当 Patroni 节点作为领导者运行或 PostgreSQL 启动并运行时, 返回 HTTP 状态代码 200。如果无法使用 Kubenetes 端点进行领导者选举(OpenShift) , 则可以将该端点用于 readinessProbe。
readiness和 liveness 端点是非常轻量的不需要执行 SQL。
探针的配置方式应使其在引导密钥到期时的某个时间开始失效。默认
值 ttl 为 30 秒, 示例探针如下所示:
readinessProbe:httpGet:scheme: HTTPpath: /readinessport: 8008initialDelaySeconds: 3periodSeconds: 10timeoutSeconds: 5successThreshold: 1failureThreshold: 3livenessProbe:httpGet:scheme: HTTPpath: /livenessport: 8008initialDelaySeconds: 3periodSeconds: 10timeoutSeconds: 5successThreshold: 1failureThreshold: 3
监控端点
GET /patroni 在 leader 竞选中被 Patroni 使用。监视系统也可以使用它。该端点生成的 JSON 文档与运行健康检查端点生成的 JSON 具有相同的结构。
$ curl -s http://localhost:8008/patroni | jq .{"state": "running","postmaster_start_time": "2019-09-24 09:22:32.555 CEST","role": "master","server_version": 110005,"cluster_unlocked": false,"xlog": {"location": 25624640},"timeline": 3,"database_system_identifier": "6739877027151648096","patroni": {"version": "1.6.0","scope": "batman"}}
集群状态端点
GET /cluster 端点生成一个 JSON 文档来描述当前集群的拓扑结构和状态:
$ curl -s http://localhost:8008/cluster | jq .{"members": [{"name": "postgresql0","host": "127.0.0.1","port": 5432,"role": "leader","state": "running","api_url": "http://127.0.0.1:8008/patroni","timeline": 5,"tags": {"clonefrom": true}},{"name": "postgresql1","host": "127.0.0.1","port": 5433,"role": "replica","state": "running","api_url": "http://127.0.0.1:8009/patroni","timeline": 5,"tags": {"clonefrom": true},"lag": 0}],"scheduled_switchover": {"at": "2019-09-24T10:36:00+02:00","from": "postgresql0"}}
GET /history 端点提供了有关集群切换/故障切换历史的视图。格式与 pg_wal 目录中历史文件的内容非常相似。唯一的区别是显示新时间线创建时间的时间戳字段。
$ curl -s http://localhost:8008/history | jq .[[1,25623960,"no recovery target specified","2019-09-23T16:57:57+02:00"],[2,25624344,"no recovery target specified","2019-09-24T09:22:33+02:00"],[3,25624752,"no recovery target specified","2019-09-24T09:26:15+02:00"],[4,50331856,"no recovery target specified","2019-09-24T09:35:52+02:00"]]
配置端点
GET /config:获取动态配置的当前版本:
$ curl -s localhost:8008/config | jq .{"ttl": 30,"loop_wait": 10,"retry_timeout": 10,"maximum_lag_on_failover": 1048576,"postgresql": {"use_slots": true,"use_pg_rewind": true,"parameters": {"hot_standby": "on","wal_log_hints": "on","wal_level": "hot_standby","max_wal_senders": 5,"max_replication_slots": 5,"max_connections": "100"}}}
PATCH /config:更改现有配置。
$ curl -s -XPATCH -d \'{"loop_wait":5,"ttl":20,"postgresql":{"parameters":{"max_connections":"101"}}}' \http://localhost:8008/config | jq .{"ttl": 20,"loop_wait": 5,"maximum_lag_on_failover": 1048576,"retry_timeout": 10,"postgresql": {"use_slots": true,"use_pg_rewind": true,"parameters": {"hot_standby": "on","wal_log_hints": "on","wal_level": "hot_standby","max_wal_senders": 5,"max_replication_slots": 5,"max_connections": "101"}}}
上面的 REST API 调用修补了现有配置, 并返回了新配置。
让我们检查节点是否处理了此配置。首先它应该每 5 秒开始打印日志行(loop_wait = 5) 。更改 max_connections 需要重新启动, 因此应显示“pending_restart” 标志:
$ curl -s http://localhost:8008/patroni | jq .{"pending_restart": true,"database_system_identifier": "6287881213849985952","postmaster_start_time": "2016-06-13 13:13:05.211 CEST","xlog": {"location": 2197818976},"patroni": {"scope": "batman","version": "1.0"},"state": "running","role": "master","server_version": 90503}
删除参数:
如果要删除(重置)某些设置,只需使用 null 进行修补:
$ curl -s -XPATCH -d \'{"postgresql":{"parameters":{"max_connections":null}}}' \http://localhost:8008/config | jq .{"ttl": 20,"loop_wait": 5,"retry_timeout": 10,"maximum_lag_on_failover": 1048576,"postgresql": {"use_slots": true,"use_pg_rewind": true,"parameters": {"hot_standby": "on","unix_socket_directories": ".","wal_level": "hot_standby","wal_log_hints": "on","max_wal_senders": 5,"max_replication_slots": 5}}}
上述操作在动态配置中移除了 postgresql.parameters.max_connections。
PUT /config:还可以无条件地对现有动态配置执行完全重写:
$ curl -s -XPUT -d \'{"maximum_lag_on_failover":1048576,"retry_timeout":10,"postgresql":{"use_slots":true,"use_pg_rewind":true,"parameters":{"hot_standby":"on","wal_log_hints":"on","wal_level":"hot_standby","unix_socket_directories":".","max_wal_senders":5}},"loop_wait":3,"ttl":20}' \http://localhost:8008/config | jq .{"ttl": 20,"maximum_lag_on_failover": 1048576,"retry_timeout": 10,"postgresql": {"use_slots": true,"parameters": {"hot_standby": "on","unix_socket_directories": ".","wal_level": "hot_standby","wal_log_hints": "on","max_wal_senders": 5},"use_pg_rewind": true},"loop_wait": 3}
切换和故障转移端点
POST /switchover 或者 POST /failover 这些端点彼此非常相似。但是有一些细微的差异:
故障转移端点允许在没有健康节点的情况下执行手动故障转移,但同时不允许调度切换。
切换端点是相反的。它仅在集群运行状况良好(有领导者) 时起作用, 并允许在给定时间安排切换。
如果要在特定时间安排切换, 则必须在 POST 请求的 JSON 正文中至少指定 leader或 candidate 字段以及可选的 scheduled_at 段。
示例:执行一个故障转移到指定节点上:
$ curl -s http://localhost:8009/failover -XPOST -d '{"candidate":"postgresql1"}'Successfully failed over to "postgresql1"
示例: 在指定时间调度一个切换, 在一个集群中从 leader 到一些健康的副本节点上:
$ curl -s http://localhost:8008/switchover -XPOST -d \'{"leader":"postgresql0","scheduled_at":"2019-09-24T12:00+00"}'Switchover scheduled
根据情况, 请求可能以不同的 HTTP 状态代码和内容结束。成功完成切换或故障转移后, 将返回状态码 200。如果成功安排了切换,则 Patroni 将返回 HTTP 状态代码 202。一旦出现问题, 错误状态代码(400、 412 或 503 之一) 将在响应正文中返回并包含一些详细信息。有关更多信息, 请检查 patroni/api.py:do_POST_failover() 方法的源代码。
DELETE /switchover:删除计划切换。
POST /switchover 和 POST failover 端点被分别用于 patronictl switchover 和 patronictl failover
DELETE /switchove 用于patronictl flush <cluster-name> switchover
重启端点
POST /restart:通过执行POST /restart调用,可以在特定节点上重新启动Postgres。在 POST 请求的 JSON 正文中,可以选择性地指定一些重启条件:
restart_pending: boolean, 如果设置为 true, Patroni 仅在重新启动挂起时才会重新启动 PostgreSQL, 以便在 PostgreSQL 配置中应用某些更改。
role: 仅当节点的当前角色与 POST 请求中的角色匹配时, 才执行重新启动。
postgres_version: 仅当前版本的 postgres 小于 POST 请求中指定值时, 才执行重新启动。
timeout: PostgreSQL 开始接受连接之前应该等待多长时间。
覆盖 master_start_timeout。schedule: 带时区的时间戳记, 安排在将来某个地方重新启动。
DELETE /restart:删除一个计划重启
POST /restart和 DELETE /restart 端点分别被用于 patronictl restart 和 patronictl flush <cluster-name> restart。
重载端点
POST /reload 将命令 Patroni 重新读取并应用配置文件。这等效于向 Patroni 进程发送 SIGHUP 信号。如果您更改了一些需要重新启动的 Postgres 参数(例如 shared_buffers),您仍然必须通过调
用 POST /restart 端点或借助 patronictl restart 显式地重新启动 Postgres。重新加载端点被用于 patronictl reload。
重新初始化端点
POST /reinitialize: 在指定节点上重新初始化 PostgreSQL 数据目录。 只允许在副本上执行它。 一旦调用, 它将删除数据目录并启动 pg_basebackup 或其他复制副本创建方法。
如果 Patroni 处于尝试恢复(重新启动) 失败的 Postgres 的循环
中, 则调用可能会失败。 为了克服这个问题, 可以在请求正文中指定
{"force":true}。
重新初始化端点用于 patronictl reinit。
