




“ 学习笔记来自极客时间购买的课程《Linux性能优化实战》见以下链接地址”

作为一名Linux运维工作人员,经常自我强调自己,技术的本质就是解决问题的能力,那么如何快速解决问题,找到问题的本质根源,就需要我们平常多下功夫,多操练,才能在事情出现后,游刃有余的去解决
废话少说,疫情期间,自我隔离中,找找事情 写写文档 ~~
01
—
如何理解系统的平均负载
日常工作中,经常会使用uptime查看系统的平均负载情况

在上图中,可以看到系统的1分钟 5分钟 15分钟描述的平均负载
如何理解平均负载呢?
平均负载就是单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数
可运行状态: 正在使用CPU或者正在等待CPU的进程,处于 R 状态(Running 或 Runnable)的进程
不可中断状态: 正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题
那么经过以上两个概念可以分析出,在uptime查到的系统负载数值中,并不一定是反应CPU的使用率高,也要关注下是否有不可中断状态的进程在占用引起的I/O问题,也会导致平均负载数值过高问题
平均负载理想的状态是等于CPU的逻辑个数
# 查看CPU逻辑核心数grep 'model name' /proc/cpuinfo | wc -l
CPU使用率,是单位时间内CPU繁忙情况的统计,跟平均负载不一定完全对应,例如以下几种场景
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
02
—
案例分析
如果使用uptime查看系统负载高的情况下,可以使用以下两个工具,来进一步分析
mpstat: 查看CPU性能指标工具
pidstat: 查看进程性能分析工具
以下案例,通过stress来模拟故障问题,引用本章的思路来排查
场景一: CPU密集型进程
# 通过stress压测,模拟一个cpu使用率百分百的情况$ stress --cpu 1 --timeout 600
我的系统是2核 4G内存 Ubuntu 18.04
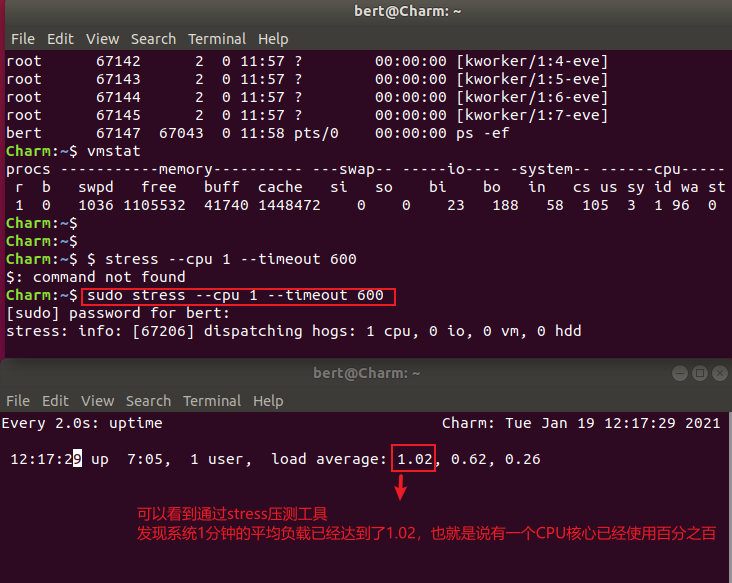
遇到这种情况,我们可以使用mpstat来查看CPU的性能指标
# -P 查看所有CPU核心 5: 每隔5秒输出一组数据$ mpstat -P ALL 5

在上图中,每一组数据有标记两个红框,%usr代表用户态 1个CPU已经负载很高甚至到达了%100,%idle代表CPU的空闲状态,当CPU使用率越高,idle的值也就越低,代表没有空闲,非常繁忙的状态
在以上数据分析,得出属于用户态的1个CPU使用率很高,查看和iowait没有关系,因此接下来我们要继续分析,是哪个进程占用CPU使用率高
# 查看进程性能指标$ pidstat -u 5 1 # 每隔5秒输出一组信息
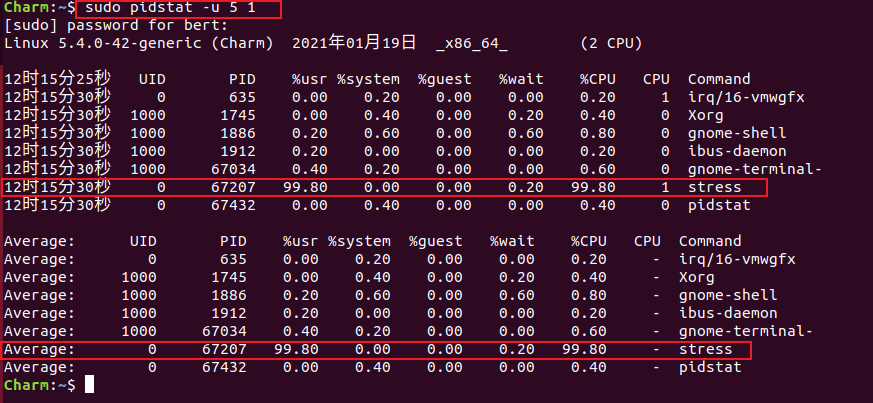
经过以上分析,可以看出是stress的进程占用CPU比较高
以上属于CPU密集型进程
场景二: I/O密集型进程
先看下当前uptime负载情况

# 使用stress-ng工具压测 I/O性能$ stress-ng -l 1 --hdd 1 --timeout 600
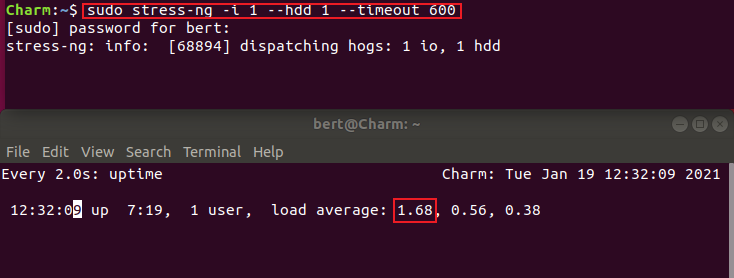
可以看到1分钟平均负载又飙升上去了,使用mpstat查看CPU性能指标
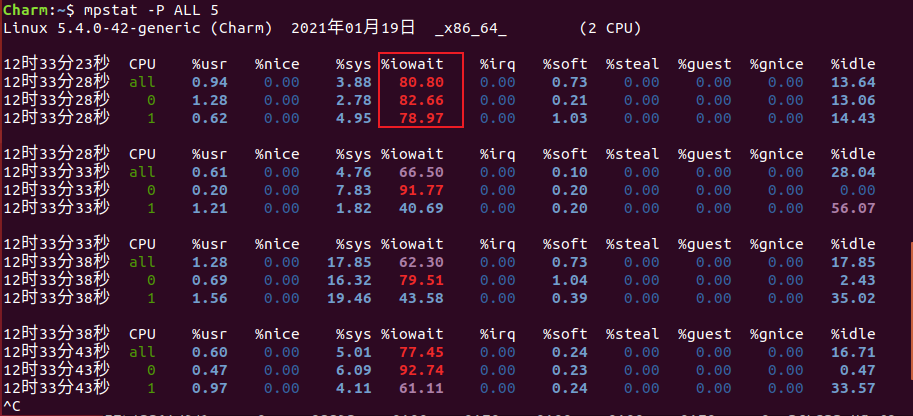
在上图中可以看到,%usr %sys 内核态和用户态的CPU使用率并不高,在%iowait值很高,这说明当前系统有I/O负载高问题,有大量写操作正在执行,导致I/O负载过高,同样继续使用pidstat查看是哪个进程在占用I/O过高
$ pidstat -u 5 1
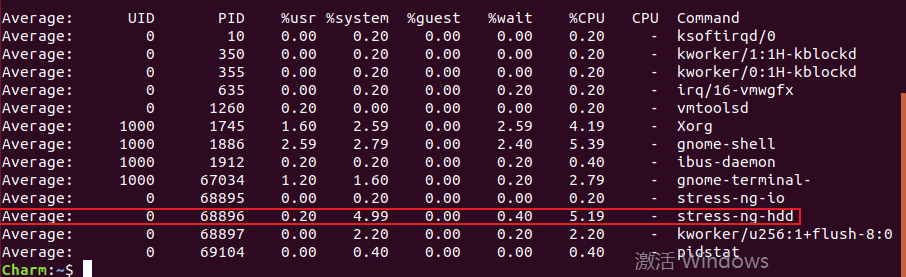
可以看到是stress-ng-hdd的进程,就是我们模拟的stress-ng工具 在不断的sync操作
场景三: 大量进程的场景
当系统中运行进程超出cpu运行能力时,就会出现等待CPU的进程
我们使用stress模拟8个进程
$ stress -c 8 --timeout 600
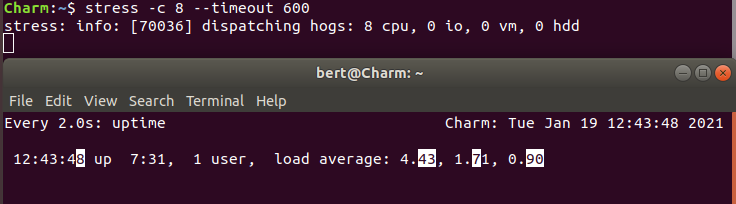
我当前CPU核心数是2,明显比8个进程要少的多,因为CPU的平均负载严重过载状态,平均负载4.43
使用pidstat查看进程的状态
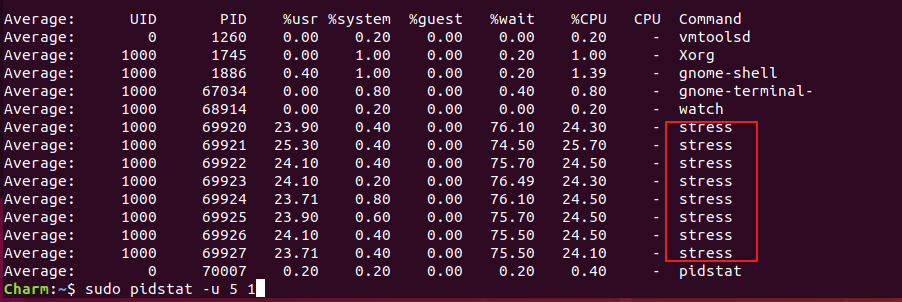
可以看到这8个进程,在争抢2个CPU,每个进程等待CPU的时间高达76%, 也就是上图中%wait的值,这些超出CPU计算能力的进程,导致CPU负载过高
03
—
总结
通过上述描述,可以总结为:
平均负载反馈了系统整体的性能指标,在理解平均负载时,也要注意以下几点
平均负载高有可能是 CPU 密集型进程导致的;
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
使用mpstat pidstat分析具体瓶颈问题
