




1. 控制节点单点问题
假如创建的集群只有一个控制节点,上面运行着一个 etcd 数据库。这意味着如果控制节点发生故障,您的集群可能会丢失数据,并且可能需要从头开始重新创建。
解决方法:
·
定期备份 etcd。kubeadm 配置的 etcd 数据目录位于/var/lib/etcdcontrol-plane
节点上。
·
使用多个控制节点。
2. 什么是etcd?
etcd 是一个一致的分布式key-value存储。在分布式系统中主要用作单独的协调服务。并且旨在保存可以完全放入内存的少量数据。
3. 高可用架构说明
有2种拓扑可供选择:
A.堆叠etcd拓扑

B. 外部etcd拓扑

4. 两种拓扑的优缺点
4.1 堆叠etcd拓扑优缺点
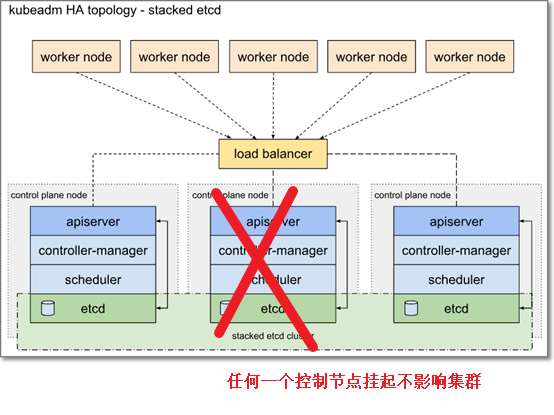
堆叠HA集群是一种拓扑结构,其中etcd提供的分布式数据存储集群堆叠在由运行控制面板组件的kubeadm管理的节点形成的集群之上。
每个控制面板节点运行kube apiserver、kube调度器和kube控制器管理器的一个实例。kube apiserver使用负载平衡器向工作节点公开。
每个控制面板节点创建一个本地etcd成员,该etcd成员仅与该节点的kube apiserver通信。这同样适用于本地kube控制器管理器和kube调度程序实例。
此拓扑将控制面板和etcd成员耦合到同一节点上。它比带有外部etcd节点的集群更容易设置,也更容易管理复制。
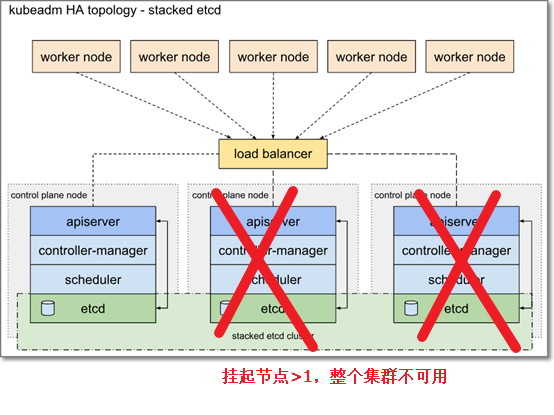
但是,堆叠集群存在耦合失败的风险。如果一个节点发生故障,etcd成员和控制面板实例都会丢失,冗余性也会受到影响。您可以通过添加更多控制面板节点来降低此风险。
因此,应该为HA群集运行至少三个堆叠的控制面板节点。
这是kubeadm中的默认拓扑。使用kubeadm init和kubeadm join--control plane时,会在控制面板节点上自动创建本地etcd成员。
4.2 外部etcd拓扑优缺点
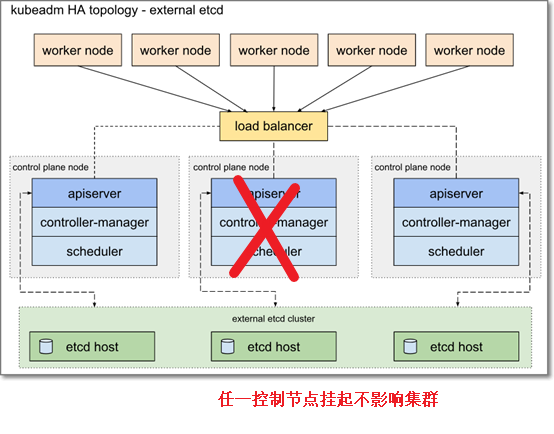
带有外部etcd的HA集群是一种拓扑结构,其中etcd提供的分布式数据存储集群位于运行控制面板组件的节点形成的集群的外部。
与堆叠etcd拓扑一样,外部etcd拓扑中的每个控制面板节点都运行kube apiserver、kube scheduler和kube controller manager的一个实例。kube apiserver使用负载平衡器向工作节点公开。然而,etcd成员在不同的主机上运行,每个etcd主机与每个控制面板节点的kube apiserver通信。
该拓扑将控制面板和etcd成员解耦。因此,它提供了一种HA设置,其中丢失控制面板实例或etcd成员的影响较小,并且不会像堆叠HA拓扑那样影响集群冗余。
但是,这种拓扑需要的主机数量是堆叠HA拓扑的两倍。对于具有此拓扑的HA群集,至少需要三台主机用于控制面板节点,三台主机用于etcd节点。
4.3
2种拓扑比较
A . 堆叠etcd,没有解耦api与etcd,一个节点故障(例如主机故障),etcd成员和控制面板实例都会丢失
B.外部etcd,解耦api与etcd,最多可以容忍任一api节点故障+任一etcd节点故障
5. Etcd集群节点容错说明
(节点数-1)
/ 2
(节点数-1)
整除 2
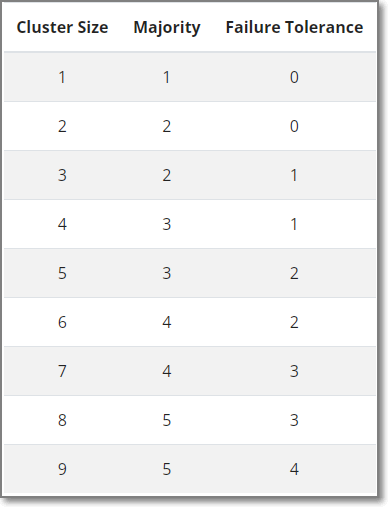
假如3节点
(3-1)/2 = 1,容错1个节点
假如5节点
(5-1)/2 = 2,容错2个节点
假如6节点
(6-1)/2 = 2,容错2个节点
6. K8s高可用容错图解
6.1
堆叠etcd拓扑图解
以三控制节点为例:红色x 代表主机故障
6.2
外部etcd拓扑图解
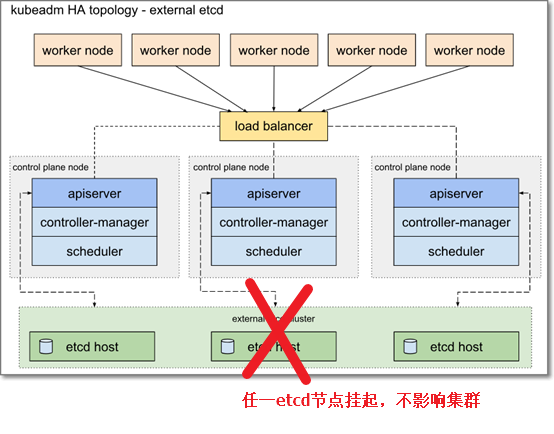
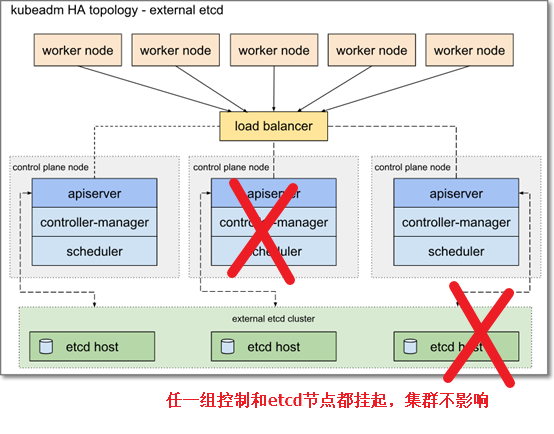

7. K8s高可用其他说明
7.1
最大集群大小是多少?
理论上,没有硬性限制。然而,一个 etcd 集群可能不应该超过七个节点。Google Chubby lock service,类似于 etcd,并在谷歌内部广泛部署多年,建议运行五个节点。一个 5 成员的 etcd 集群可以容忍两个成员的故障,这在大多数情况下就足够了。尽管较大的集群提供了更好的容错能力,但写入性能会受到影响,因为必须在更多机器上复制数据。
7.2
etcd 是否适用于跨区域或跨数据中心部署?
跨区域部署 etcd 提高了 etcd 的容错能力,因为成员位于不同的故障域中。代价是跨越数据中心边界的更高共识请求延迟。由于 etcd 依赖于成员仲裁达成共识,跨数据中心的延迟会有些明显,因为至少大多数集群成员必须响应共识请求。此外,集群数据必须在所有对等方之间复制,因此也会产生带宽成本。
由于延迟较长,默认的 etcd 配置可能会导致频繁的选举或心跳超时。
7.3
etcd节点系统要求
由于 etcd 将数据写入磁盘,因此其性能很大程度上取决于磁盘性能。因此,强烈推荐使用 SSD。要评估磁盘是否足够快用于 etcd,一种可能性是使用磁盘基准测试工具,例如fio。有关如何执行此操作的示例,请阅读此处. 为了防止性能下降或无意中使键值存储超载,etcd 强制将可配置的存储大小配额默认设置为 2GB。为避免交换或内存不足,机器应至少有足够多的 RAM 来覆盖配额。8GB 是正常环境的建议最大大小,如果配置的值超过该值,etcd 会在启动时发出警告。在 CoreOS,etcd 集群通常部署在具有双核处理器、2GB RAM 和至少 80GB SSD 的专用 CoreOS Container
Linux 机器上。请注意,性能本质上取决于工作负载;请在生产部署之前进行测试。有关更多建议,请参阅硬件。
最稳定的生产环境是amd64架构的Linux操作系统;有关更多信息,请参阅支持的平台。
7.4
外部etcd拓扑控制节点也至少3个?
拥有多个主节点可确保在主节点发生故障时服务仍然可用。为了促进 master 服务的可用性,它们应该以奇数(例如
3、5、7、9 等)部署,以便在一个或多个 master 失败时可以维持仲裁(master 节点多数)。在 HA 场景中,Kubernetes 会在每个 master 上维护一份 etcd 数据库的副本,但会选举控制节点领导者来避免kube-controller-manager和kube-scheduler冲突。工作节点可以通过负载均衡器与任何主服务器的 API 服务器进行通信。
使用多个主服务器部署是大多数生产集群的最低推荐配置。
参考:
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ha-topology/
https://netapp-trident.readthedocs.io/en/stable-v19.01/dag/kubernetes/kubernetes_cluster_architecture_considerations.html#multiple-master-compute
