





 从ALERT LOG看,在客户据说的故障发生前,出现了DBWR导致的数据块实例宕机现象,不过这个宕机和出现ORA-8103是不一定有关系的:
从ALERT LOG看,在客户据说的故障发生前,出现了DBWR导致的数据块实例宕机现象,不过这个宕机和出现ORA-8103是不一定有关系的:
Fri May 25 10:46:252007
Errors in file/ora/app/oracle/admin/ora9/bdump/ora9_pmon_65086.trc:
ORA-00471: DBWR processterminated with error
Fri May 25 10:46:25 2007
PMON: terminating instance dueto error 471
Instance terminated by PMON,pid = 65086
据现场DBA的描述,2007年5月23日-2007年5月25日期间,软件开发商历史数据进行了迁移,在2007年5月25日10点46分左右,由于dbwr进程出现故障而导致数据库宕机,系统重启后部分表出现了逻辑坏块。接下来2007年6月份也相应地出现了坏块现象,都通过跳过坏块,重建表的方式解决掉了。
7月开始发现的是另外一种坏块的形式,在yh_dnb表的某个extent中,在高水位下有个BLOCK对应的type是错误的,当对该表进行扫描或者访问到某个记录的时候,访问到这种块就会出现ora-8103报错,操作无法正常进行。如果存在这种形式的坏块,无法对表进行全表扫描,也无法将该表exp出来。
幸运的是,这张表有一个主键索引是好的,于是通过主键索引找到这张表的所有行,然后一行一行的去查找数据,如果某行报错,就把ROWID打印出来,通过对该表的检查,发现坏块的rdba是:72/13283,检查结果如下:
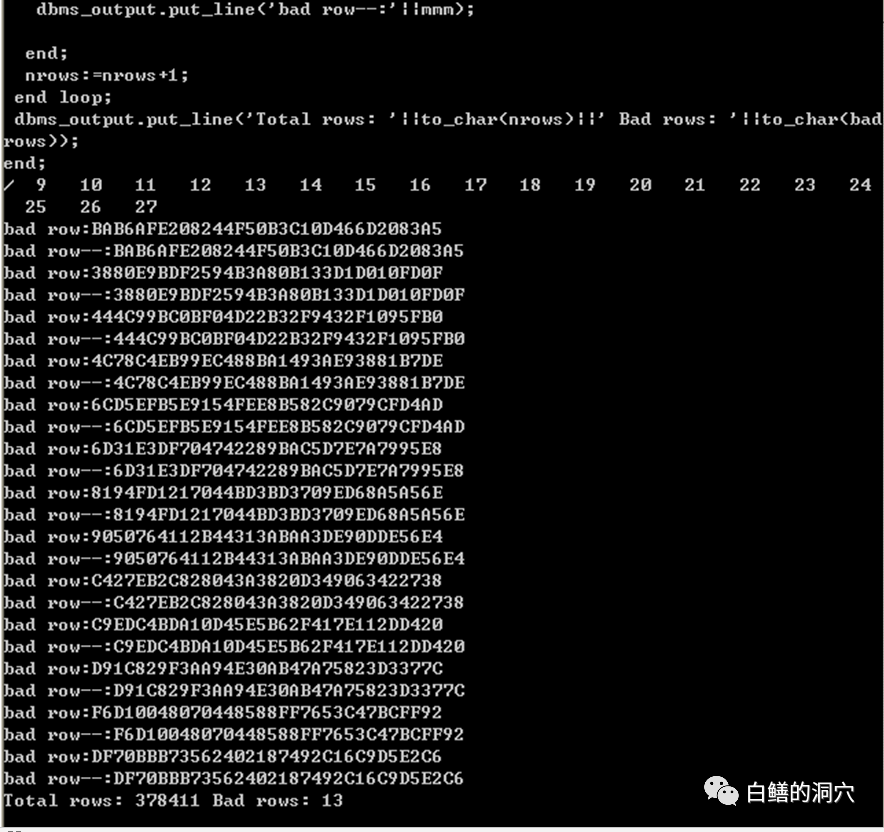
这张表的坏块中,有13行数据。从这个情况来看,还是比较乐观的。除了这13行数据,其他数据都是好的。于是处置这个问题的最简单方案就形成了。写一个存储过程,把除了这十三行数据的其他数据都取出来,插入到一张新表中,把有问题的这十三条记录的主键存储到另外一张表中,然后把旧表rename,把新表renname为这张表的名称。再通过档案数据补齐这十三条数据就可以了。
set serveroutput on
declare
nrows number;
badrows number;
VYHDABH VARCHAR2(50);
VFGSBH VARCHAR2(50);
VJBH VARCHAR2(50);
begin
badrows:=0;
nrows:=0;
fori in (select *+ index (tab1) */ rowid,FGSBH from ld_data.yh_dnb tab1) loop
begin
insert into ld_data.newtb select
*
from ld_data.yh_dnb where rowid=i.rowid;
if (mod(nrows,20000)=0) then commit; end if;
exception when others then
badrows:=badrows+1;
select /*+ index(a YH_DNB_IND_2) */ yhdabh,FGSBH,JBH into VYHDABH,VFGSBH,VJBH from ld_data.yh_dnb a whererowid=i.rowid;
insert into bad_rows values (i.Rowid,VFGSBH,VYHDABH,VJBH);
commit;
end;
nrows:=nrows+1;
endloop;
dbms_output.put_line('Total rows:'||to_char(nrows)||' Bad rows: '||to_char(badrows));
Commit;
end;
/
大多数ORA-8103错误都是一顿操作猛如虎的后果,处理ORA-8103的方法也是比较简单的,不过也提醒我们DBA,在做故障处置的时候一定要谨慎。
