今天是2020年第三天,在此祝大家新年快乐,万事如意!梦想在路上,新的一年让我们继续加油,达成梦想!
今天主要介绍达梦数据库的常用集函数和分析函数,及各个函数的使用场景,希望大家在sql的编写上能做到游刃有余。
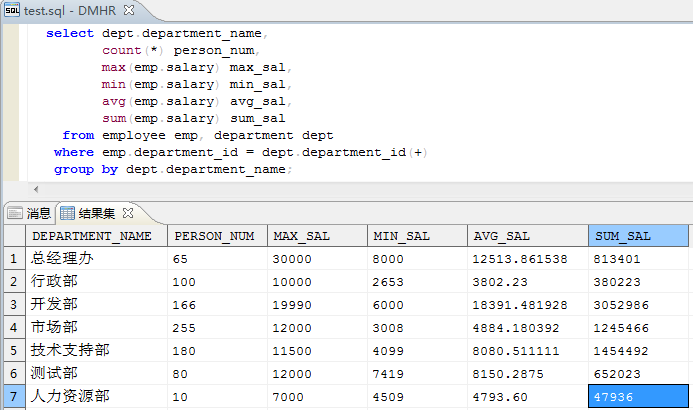
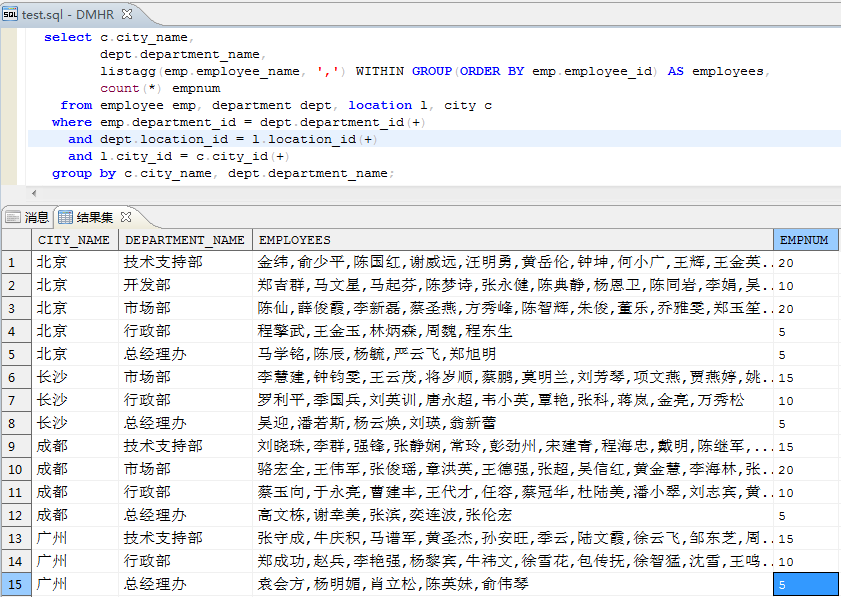
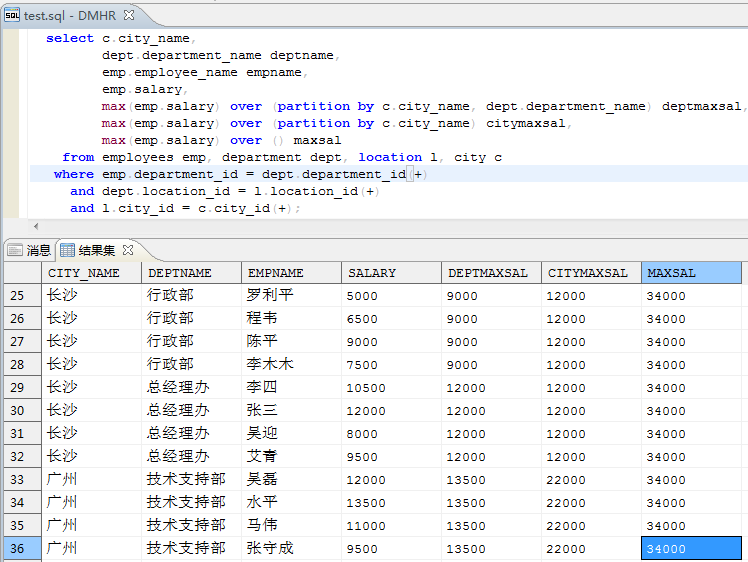
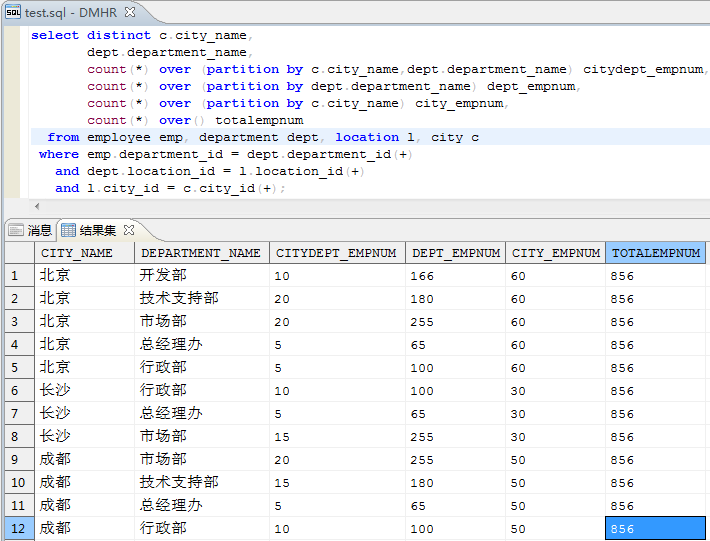
为了方便用户的使用,增强查询能力,达梦SQL 语言提供了多种内部集函数。集函数又称库函数,当根据某一限制条件从表中导出一组行集时,使用集函数可对该行集作统计操作。2. 相异集函数 AVG|MAX|MIN|SUM|COUNT(DISTINCT);3. 完全集函数 AVG|MAX|MIN| COUNT|SUM([ALL]);4.方差集函数 VAR_POP、VAR_SAMP、VARIANCE、STDDEV_POP、STDDEV_SAMP、 STDDEV;5. 协方差函数 COVAR_POP、COVAR_SAMP、CORR;7. 求区间范围内最大值集函数 AREA_MAX;8.FIRST/LAST 集函数 AVG|MAX|MIN| COUNT|SUM([ALL] ) KEEP (DENSE_RANK FIRST|LAST ORDER BY 子句);9.字符串集函数 LISTAGG/LISTAGG2。这里介绍最常用集函数AVG|MAX|MIN| COUNT|SUM和LISTAGG/LISTAGG2。 AVG|MAX|MIN|COUNT|SUM以查询DMHR样例数据库中某公司每个部门的总人数,部门最高、最低、平均薪资水平,薪资总和为例,来展示各函数的查询用途。 select dept.department_name, from employee emp, department dept where emp.department_id = dept.department_id(+) groupby dept.department_name;输出结果展示如下(数值列依次为本部门员工数,最大薪资数,最小薪资数,平均薪资数,薪资总和):字符串函数LISTAGG/LISTAGG2LISTAGG/LISTAGG2(exp1, exp2)集函数先根据 sql 语句中的 group by 分组(如果没有指定分组则所有结果集为一组),然后在组内按照 WITHIN GROUP 中的ORDER BY进行排序,最后将表达式exp1用表达式exp2串接起来。LISTAGG2 跟LISTAGG的功能是一样的,区别就是LISTAGG2返回的是clob类型,LISTAGG 返回的是 VARCHAR 类型。LISTAGG 的用法:([,]) WITHIN GROUP()LISTAGG2 的用法:([,]) WITHIN GROUP()以获取某公司各区域部门的员工名单为例,各区域各部门一条记录,sql样例参考如下:dept.department_name, listagg(emp.employee_name,',') within group(orderby emp.employee_id)from employee emp, department dept,location l, city cwhere emp.department_id = dept.department_id(+)and dept.location_id = l.location_id(+)and l.city_id = c.city_id(+)groupby c.city_name, dept.department_name;输出结果展示如下(依次为区域名称、部门名称、部门员工名单,部门员工总数):达梦数据库分析函数为用户分析数据提供了一种更加简单高效的处理方式。如果不使用分析函数,则必须使用连接查询、子查询或者视图,甚至复杂的存储过程实现。引入分析函数后,只需要简单的 SQL 语句,并且执行效率方面也有大幅提高。与集函数的主要区别是,分析函数对于每组返回多行,而集函数对于每个分组只返回一行。多行形成的组称为窗口,窗口决定了执行当前行的计算范围,窗口的大小可以由组中定义的行数或者范围值滑动。2.完全分析函数 AVG|MAX|MIN| COUNT|SUM([ALL]),这 5 个分析 函数的参数和作为集函数时的参数一致;3. 方差函数 VAR_POP、VAR_SAMP、VARIANCE、STDDEV_POP、STDDEV_SAMP、 STDDEV;4. 协方差函数 COVAR_POP、COVAR_SAMP、CORR;5.首尾函数 FIRST_VALUE、LAST_VALUE;8.排序函数 RANK、DENSE_RANK、ROW_NUMBER;9. 百分比函数 PERCENT_RANK、CUME_DIST、RATIO_TO_REPORT、 PERCENTILE_CONT、NTH_VALUE;AVG|MAX|MIN|COUNT|SUM平均值|最大值|最小值|总个数|求总和也是最常用的分析函数。① 以查询DMHR样例数据库中某公司部门人员薪资,部门最高薪资,区域最高薪资,公司最高薪资为例,来展示聚合分析函数的查询用途。dept.department_name deptname,emp.employee_name empname,max(emp.salary)over(partitionby c.city_name, dept.department_name) deptmaxsal, max(emp.salary)over(partitionby c.city_name) citymaxsal, max(emp.salary)over() maxsalfrom employees emp, department dept,location l, city cwhere emp.department_id = dept.department_id(+)and dept.location_id = l.location_id(+)and l.city_id = c.city_id(+);输出结果展示如下(数值项依次为员工个人薪资、部门最高薪资、区域最高薪资、公司最高薪资):② 以查询DMHR样例数据库中某公司区域部门人员总数,部门人员总数,区域人员总数,总司总员工人数为例,来展示聚合分析函数的查询用途。select distinct c.city_name,count(*)over(partitionby c.city_name,dept.department_name) citydept_empnum, count(*)over(partitionby dept.department_name) dept_empnum,count(*)over(partitionby c.city_name) city_empnum,count(*)over() totalempnum from employee emp, department dept,location l, city cwhere emp.department_id = dept.department_id(+) and dept.location_id = l.location_id(+) and l.city_id = c.city_id(+);输出结果展示如下(数值项依次为各区域部门员工数、各部门员工数、各区域员工数、公司员工总数):
AVG|MAX|MIN|COUNT|SUM以查询DMHR样例数据库中某公司每个部门的总人数,部门最高、最低、平均薪资水平,薪资总和为例,来展示各函数的查询用途。 select dept.department_name, from employee emp, department dept where emp.department_id = dept.department_id(+) groupby dept.department_name;输出结果展示如下(数值列依次为本部门员工数,最大薪资数,最小薪资数,平均薪资数,薪资总和):字符串函数LISTAGG/LISTAGG2LISTAGG/LISTAGG2(exp1, exp2)集函数先根据 sql 语句中的 group by 分组(如果没有指定分组则所有结果集为一组),然后在组内按照 WITHIN GROUP 中的ORDER BY进行排序,最后将表达式exp1用表达式exp2串接起来。LISTAGG2 跟LISTAGG的功能是一样的,区别就是LISTAGG2返回的是clob类型,LISTAGG 返回的是 VARCHAR 类型。LISTAGG 的用法:([,]) WITHIN GROUP()LISTAGG2 的用法:([,]) WITHIN GROUP()以获取某公司各区域部门的员工名单为例,各区域各部门一条记录,sql样例参考如下:dept.department_name, listagg(emp.employee_name,',') within group(orderby emp.employee_id)from employee emp, department dept,location l, city cwhere emp.department_id = dept.department_id(+)and dept.location_id = l.location_id(+)and l.city_id = c.city_id(+)groupby c.city_name, dept.department_name;输出结果展示如下(依次为区域名称、部门名称、部门员工名单,部门员工总数):达梦数据库分析函数为用户分析数据提供了一种更加简单高效的处理方式。如果不使用分析函数,则必须使用连接查询、子查询或者视图,甚至复杂的存储过程实现。引入分析函数后,只需要简单的 SQL 语句,并且执行效率方面也有大幅提高。与集函数的主要区别是,分析函数对于每组返回多行,而集函数对于每个分组只返回一行。多行形成的组称为窗口,窗口决定了执行当前行的计算范围,窗口的大小可以由组中定义的行数或者范围值滑动。2.完全分析函数 AVG|MAX|MIN| COUNT|SUM([ALL]),这 5 个分析 函数的参数和作为集函数时的参数一致;3. 方差函数 VAR_POP、VAR_SAMP、VARIANCE、STDDEV_POP、STDDEV_SAMP、 STDDEV;4. 协方差函数 COVAR_POP、COVAR_SAMP、CORR;5.首尾函数 FIRST_VALUE、LAST_VALUE;8.排序函数 RANK、DENSE_RANK、ROW_NUMBER;9. 百分比函数 PERCENT_RANK、CUME_DIST、RATIO_TO_REPORT、 PERCENTILE_CONT、NTH_VALUE;AVG|MAX|MIN|COUNT|SUM平均值|最大值|最小值|总个数|求总和也是最常用的分析函数。① 以查询DMHR样例数据库中某公司部门人员薪资,部门最高薪资,区域最高薪资,公司最高薪资为例,来展示聚合分析函数的查询用途。dept.department_name deptname,emp.employee_name empname,max(emp.salary)over(partitionby c.city_name, dept.department_name) deptmaxsal, max(emp.salary)over(partitionby c.city_name) citymaxsal, max(emp.salary)over() maxsalfrom employees emp, department dept,location l, city cwhere emp.department_id = dept.department_id(+)and dept.location_id = l.location_id(+)and l.city_id = c.city_id(+);输出结果展示如下(数值项依次为员工个人薪资、部门最高薪资、区域最高薪资、公司最高薪资):② 以查询DMHR样例数据库中某公司区域部门人员总数,部门人员总数,区域人员总数,总司总员工人数为例,来展示聚合分析函数的查询用途。select distinct c.city_name,count(*)over(partitionby c.city_name,dept.department_name) citydept_empnum, count(*)over(partitionby dept.department_name) dept_empnum,count(*)over(partitionby c.city_name) city_empnum,count(*)over() totalempnum from employee emp, department dept,location l, city cwhere emp.department_id = dept.department_id(+) and dept.location_id = l.location_id(+) and l.city_id = c.city_id(+);输出结果展示如下(数值项依次为各区域部门员工数、各部门员工数、各区域员工数、公司员工总数):字符串函数LISTAGG
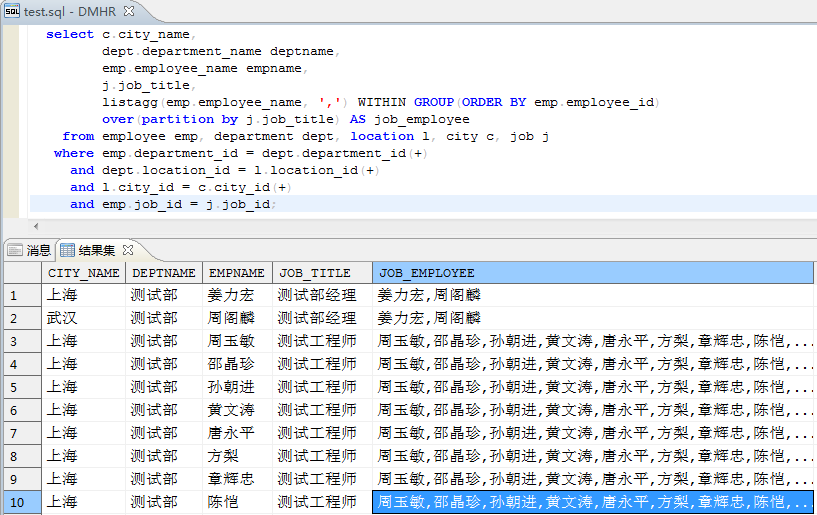
LISTAGG用于做字符串之间的连接,即可以做集函数,也可以做分析函数。LISTAGG2不支持分析函数。比如查询公司员工信息,并同步获取相同工种的员工名单,dept.department_name deptname,emp.employee_name empname,listagg(emp.employee_name,',') within group(orderby emp.employee_id)over(partitionby j.job_title)as job_employeefrom employee emp, department dept,location l, city c, job jwhere emp.department_id = dept.department_id(+)and dept.location_id = l.location_id(+)and l.city_id = c.city_id(+)and emp.job_id = j.job_id;输出结果展示如下(最后一列为该员工相同工种的员工名单):排序函数RANK,DENSE_RANK,ROW_NUMBER
此三个函数用于对数据排序,生成排行榜的场景,为每条记录产生一个从1开始至n的自然数,n的值可能小于等于记录的总数。这3个函数的唯一区别在于当碰到相同数据时的排名策略。ROW_NUMBER:当碰到相同数据时,排名按照记录集中记录的顺序依次递增。DENSE_RANK: 当碰到相同数据时,此时所有相同数据的排名都是一样的。RANK:当碰到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。① 以查询DMHR样例数据库中公司每个员工薪水在公司排行情况为例,select emp.employee_name,rank()over(orderby salary desc) rank,dense_rank()over(orderby salary desc) dense_rank, row_number()over(orderby salary desc) rownumberfrom employee emp, department deptwhere emp.department_id = 从输出结果可以看出此三个函数的区别,输出结果展示如下:② 以查询DMHR样例数据库中公司每个员工薪水及薪水在部门和公司排行情况为例,sql样例参考如下:
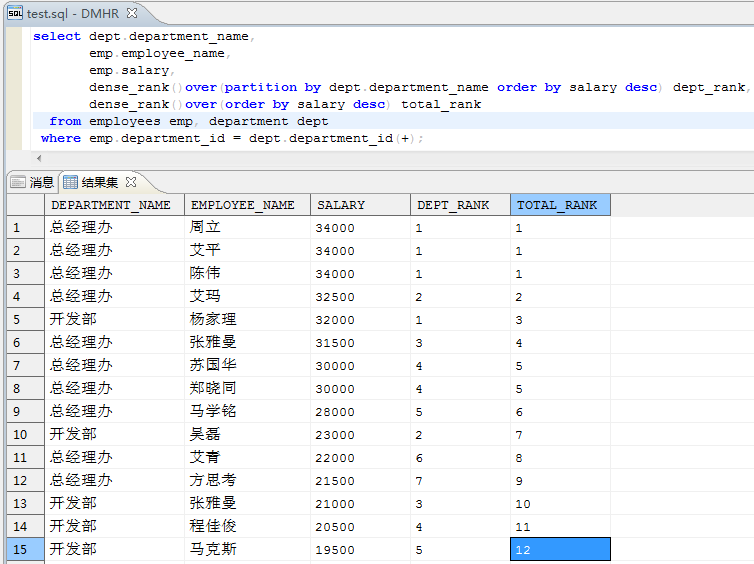
select dept.department_name,dense_rank()over(partitionby dept.department_name orderby salary desc) dept_rank,dense_rank()over(orderby salary desc) total_rankfrom employees emp, department deptwhere emp.department_id = dept.department_id(+);从输出结果中,我们可以看到每个员工薪资在自己部门和总公司的排行情况,输出结果展示如下(数值项依次为员工个人薪资、所在部门排名、所在公司排名):好了,本次常用集函数和分析函数就介绍到这了,大家有没有掌握呢。下次为大家继续介绍占比函数RATIO_TO_REPORT、相邻函数 LAG 和 LEAD等分析函数的使用,敬请期待!
最后修改时间:2020-06-12 17:43:18
文章转载自
达梦大数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。