




访问路径(Access Path)方法
以下操作为对数据库对象的访问方法及其相关操作。括号中为操作选项。根据访问对象不同, 还可以将这类操作分为表访问操作、索引访问操作、固态表访问操作和物化视图访问操作。
表访问操作
o TABLE ACCESS (FULL)
全表扫描,通过完全扫描的方式访问表。
提示:在这种访问方式下,会读取表的高水位线以下的所有数据块,并且会一次读取多个数据块。

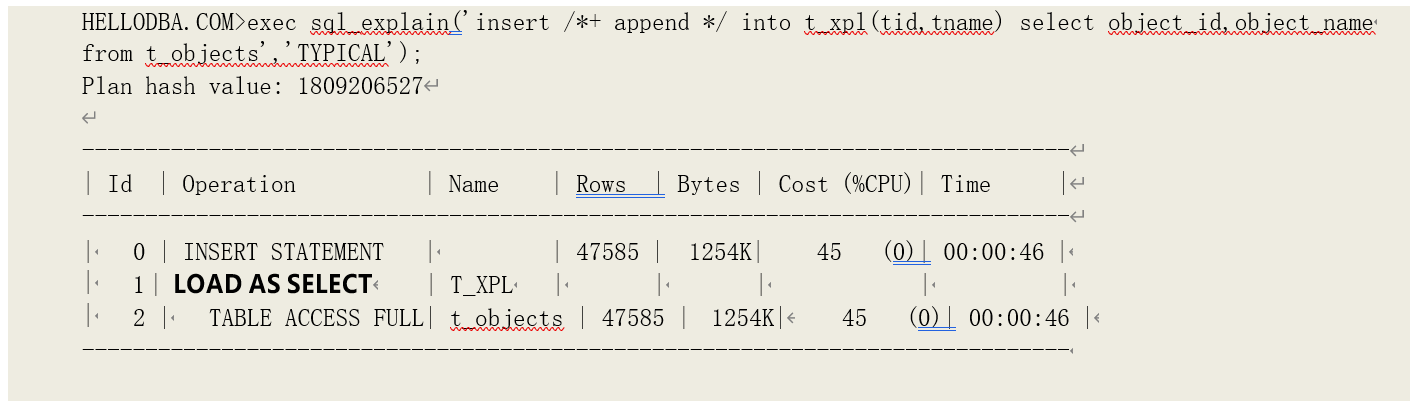
o LOAD AS SELECT
以追加(APPEND)模式向表中插入数据
o TABLE ACCESS (BY INDEX ROWID)
通过由索引中获取到的 ROWID 访问表。
关键词释义:
ROWID 是可以唯一鉴别一条数据行的标识符。通过 ROWID 可以直接定位数据行的物理位置。
ROWID 中包含了文件编号、数据块以及记录序号信息。在索引中,每一条索引记录中包含该记录中索引键值所指向的数据行的 ROWID 信息。


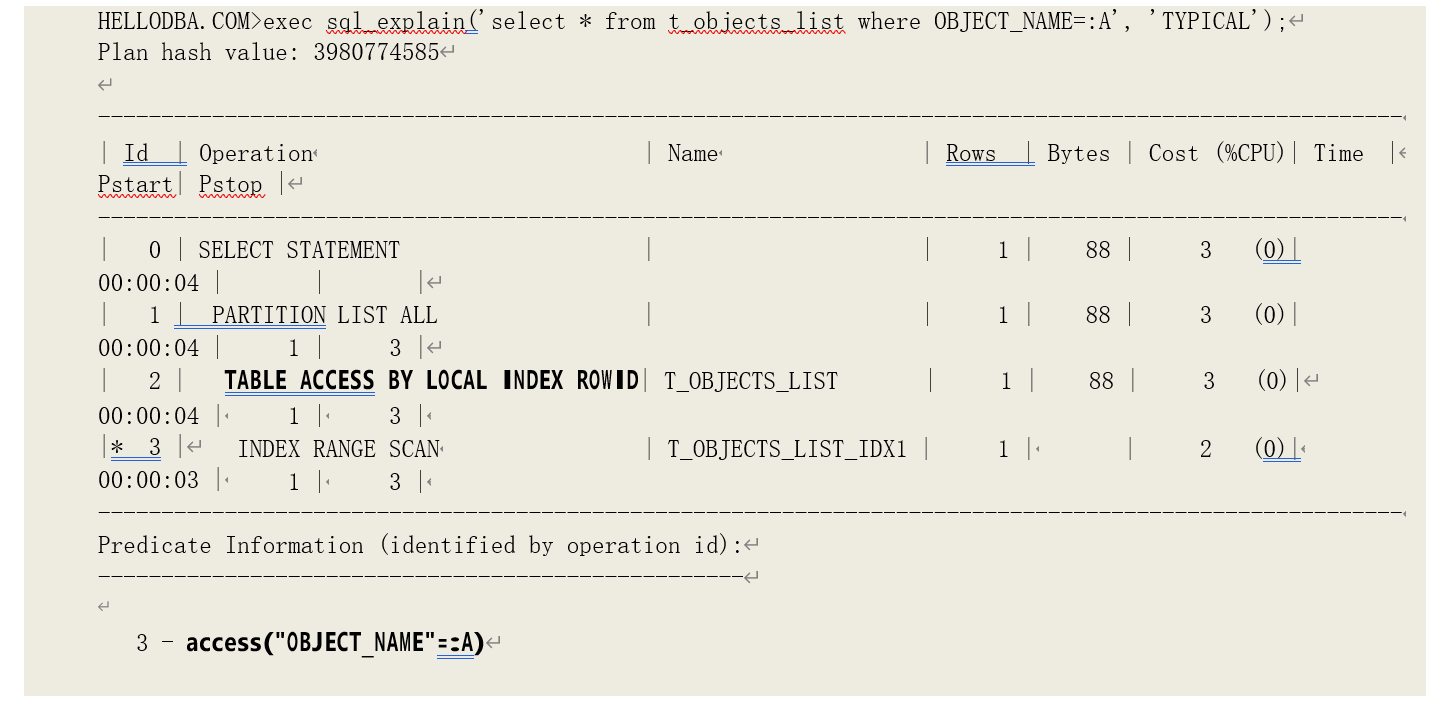
o TABLE ACCESS BY LOCAL INDEX ROWID
通过由本地分区索引中获取到的 ROWID 访问表。
关键词释义:
分区表:我们可以将表中的数据安装特定规则分开存储在不同的位置,这样的表即为分区表。每个
分区都作为一个单独的段进行管理。在分区表上创建索引时,可以指定索引是否也按照相同相同规 则分开存储。如果索引也分开存储,就是本地分区索引;否则为全局分区索引。
o TABLE ACCESS (BY GLOBAL INDEX ROWID)
通过由全局分区索引中获取到的 ROWID 访问表。


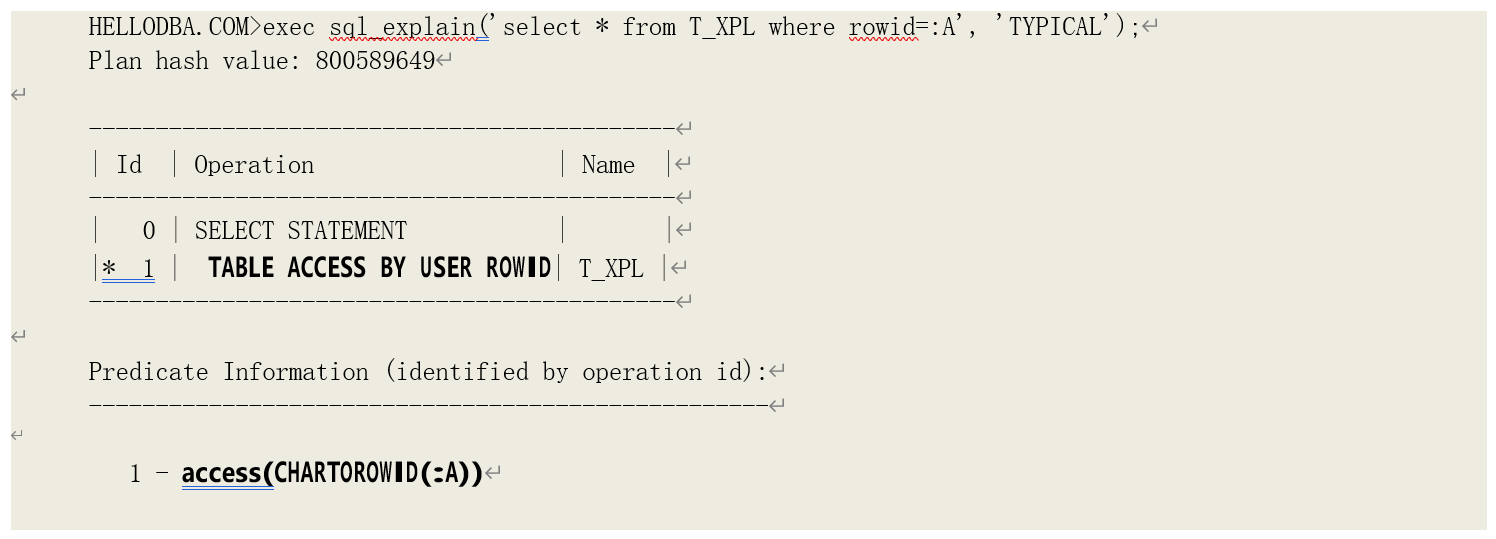
o TABLE ACCESS (BY USER ROWID)
通过用户输入或者从子查询中获取到的 ROWID 访问表。
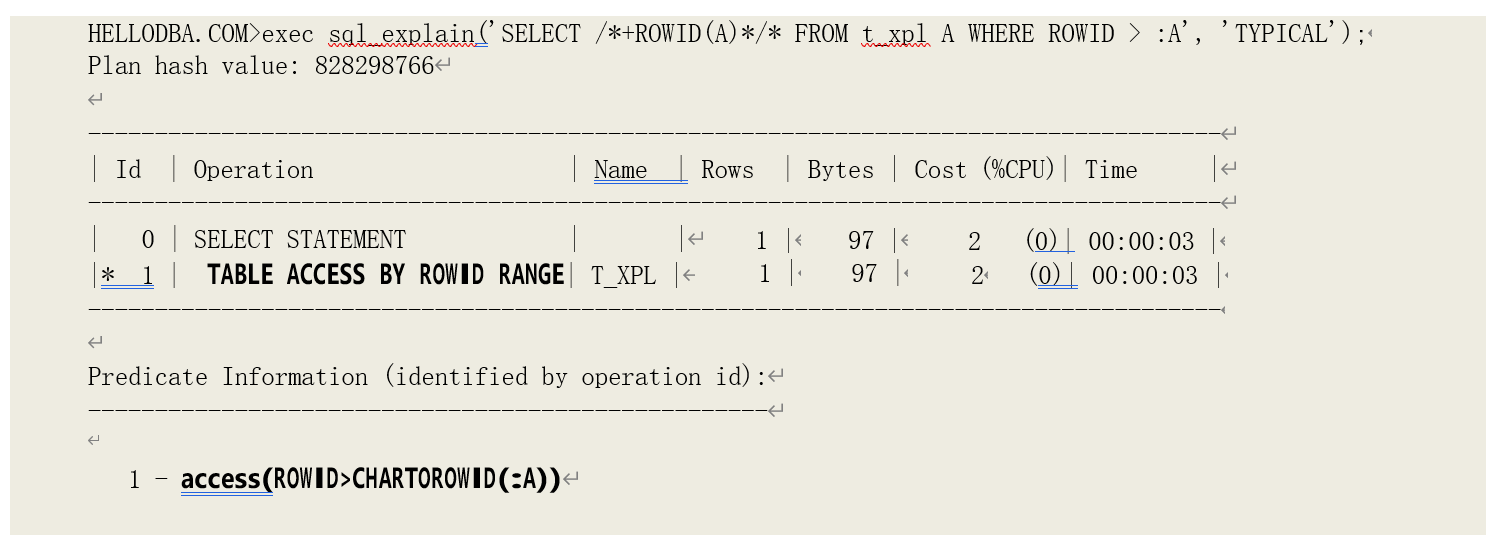
o TABLE ACCESS (BY ROWID RANGE)
通过一段范围的多个 ROWID 来访问表
提示:我们可以通过 SQL“提示”来强制语句执行计划中进行特定的操作。
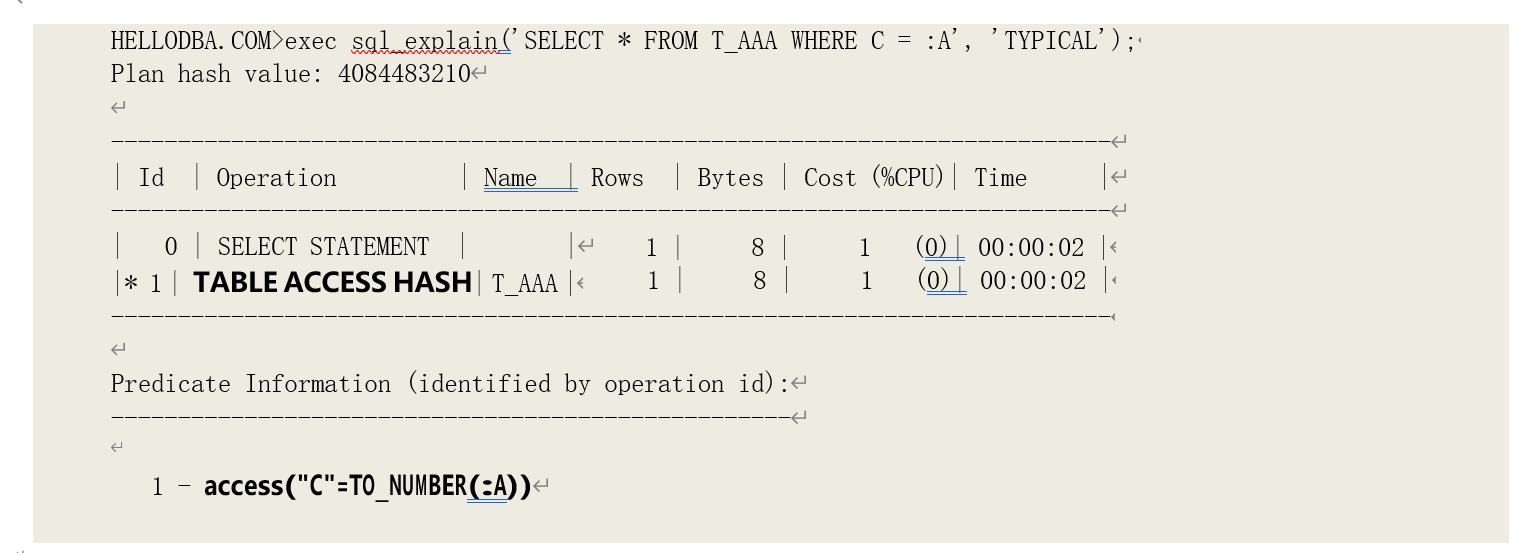
o TABLE ACCESS (CLUSTER)
通过簇来访问表。
关键词释义:
簇(Cluster):如果多个表可以共享一个或多个字段的数据,并且需要经常通过这些字段关联访问
这些表时,我们可以将这些字段创建为一个簇,而这些表则可以围绕该簇创建为簇表。簇是一个单独的物理对象。
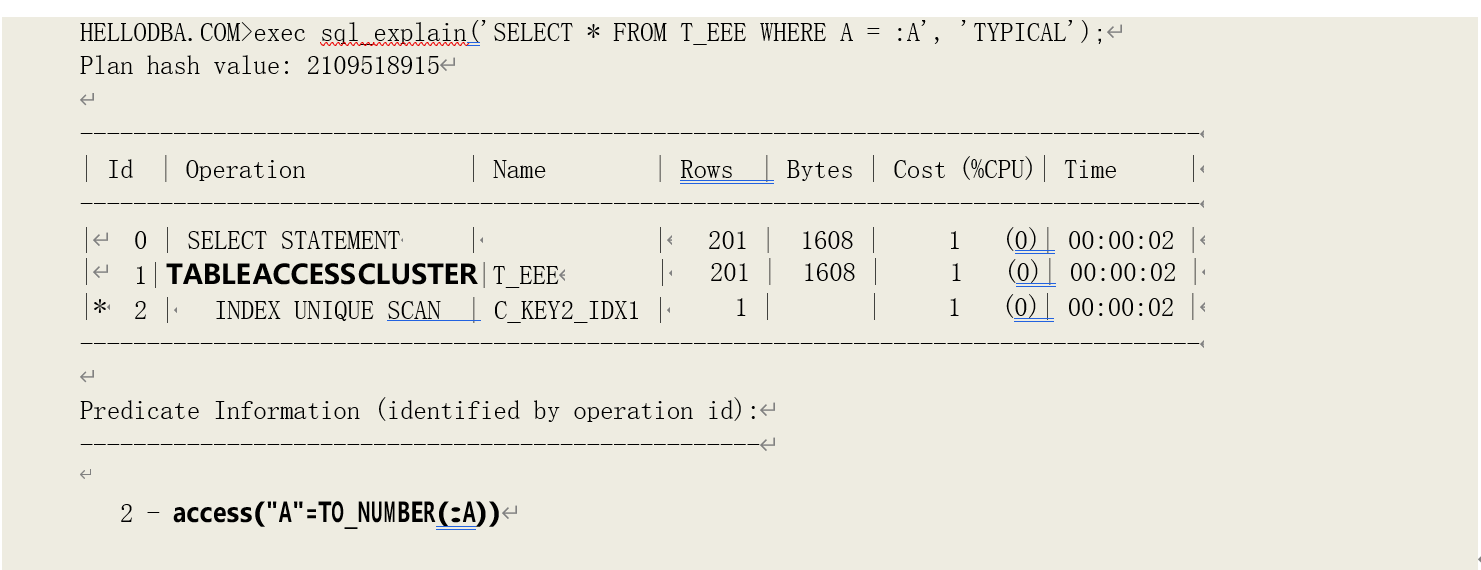
o TABLE ACCESS (HASH)
通过哈希簇来访问表。
提示:簇的存储结构有两种。一种是索引簇,即按照普通 B树的结构存储;另外一种是哈希簇, 即按照数据的哈希值进行存储。
o TABLE ACCESS (SAMPLE)
抽样访问表,即以多数据块读取的方式扫描表的部分数据块。
某些时候,我们可能并不需要的到一个精确的结果,而是通过取样的方式访问表中的数据,然 后按取样比例计算出大概结果。此时,我们就可以通过取样的方式访问表。

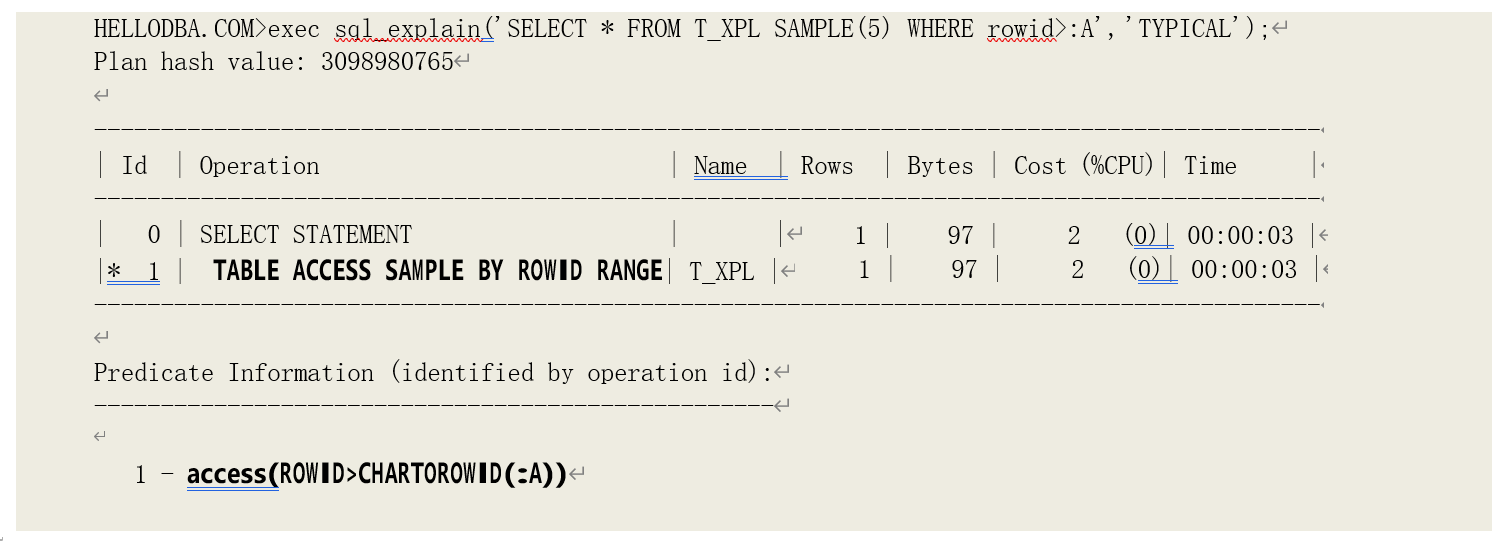
o TABLE ACCESS (SAMPLE BY ROWID RANGE)
通过对指定的一段范围的 ROWID,以取样的方式访问表。
索引访问操作
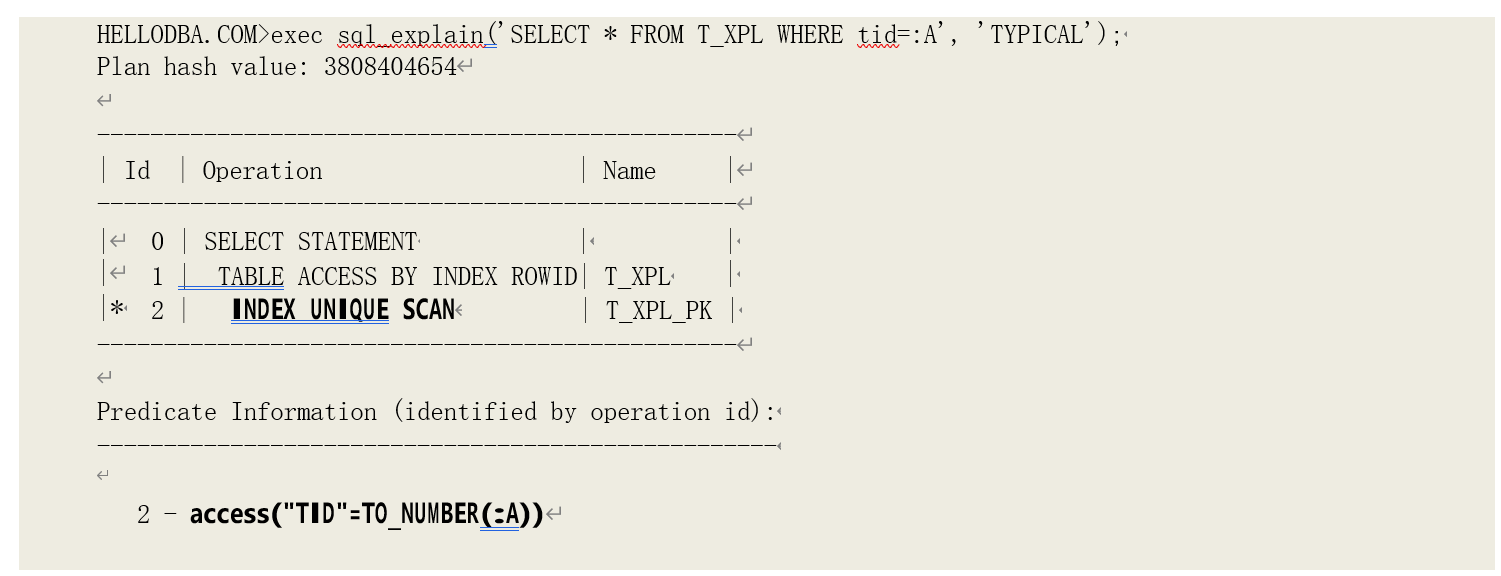
o INDEX (UNIQUE SCAN)
唯一索引扫描,即对唯一索引进行单一匹配访问。
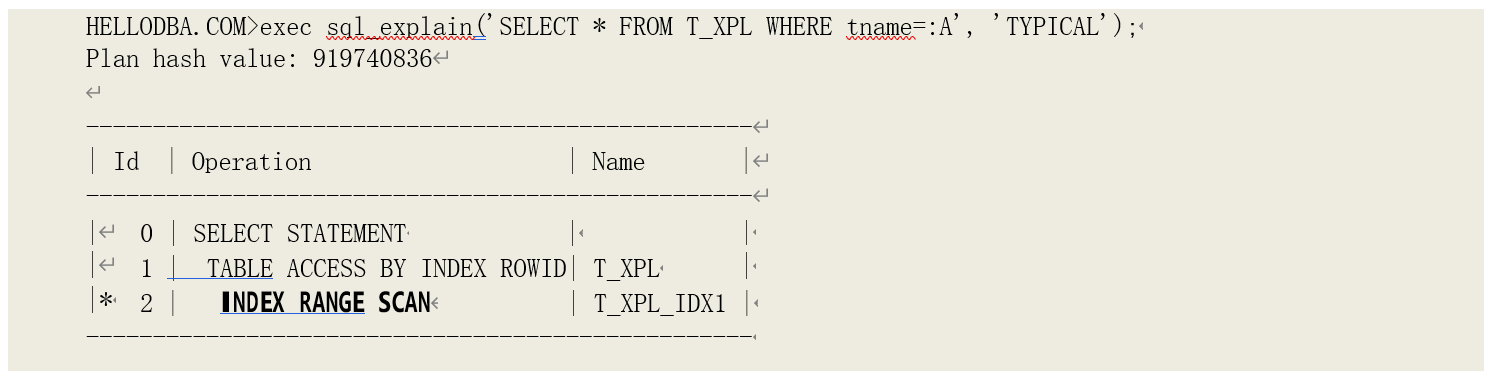
o INDEX (RANGE SCAN)
索引范围扫描,即对(唯一或非唯一)索引进行范围匹配(>、<、>=、<=、like)访问,或者对非 唯一索引进行单一匹配访问。

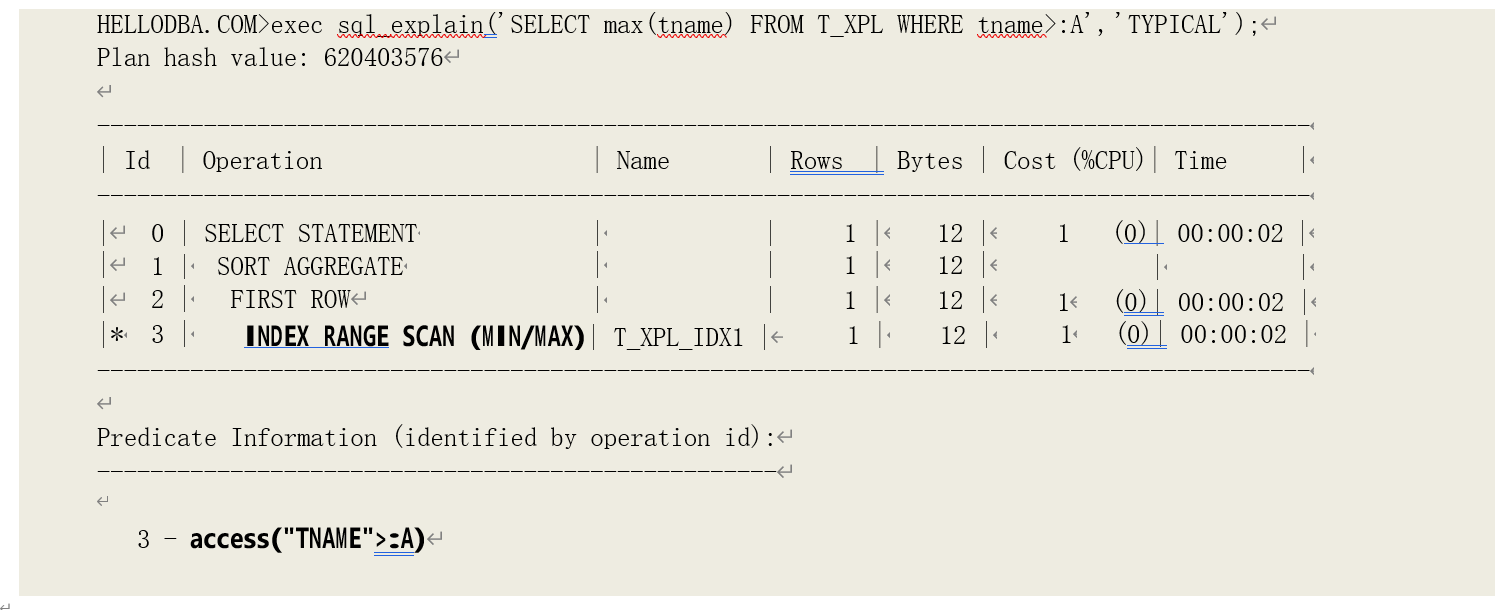
o INDEX (RANGE SCAN (MIN/MAX))
即对索引进行范围扫描,以获取索引字段的最大、最小值。
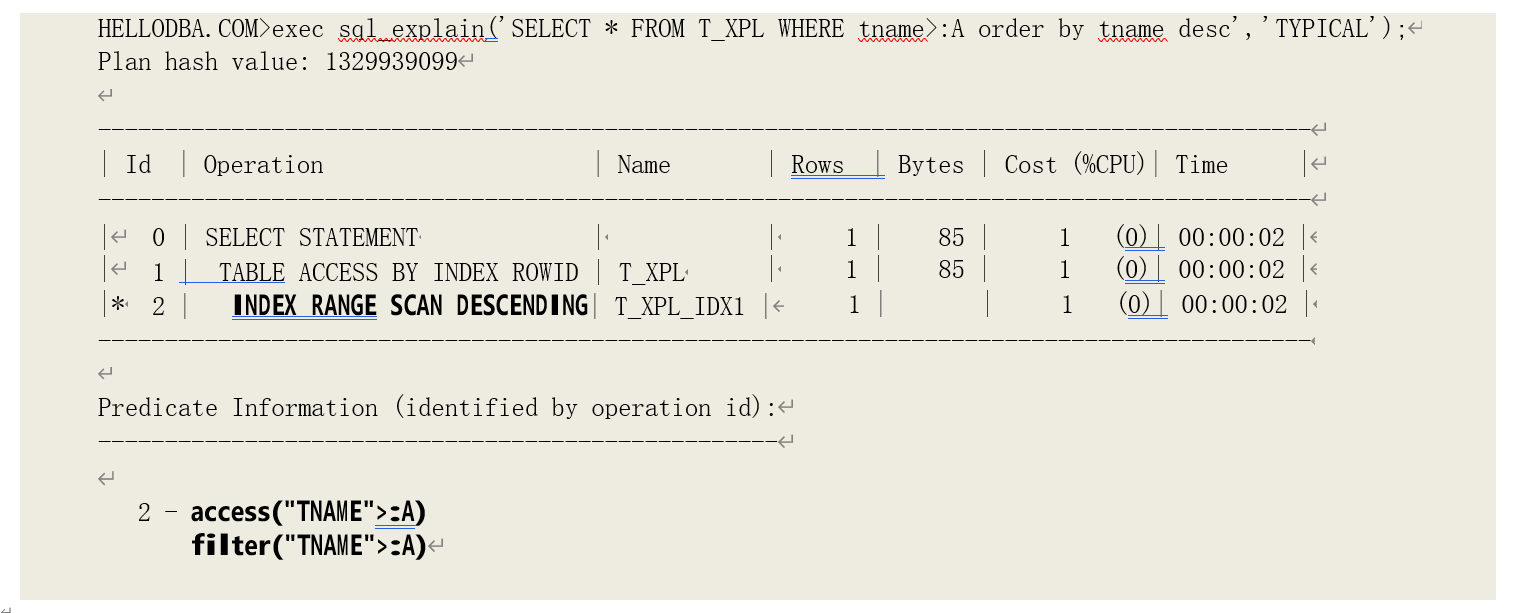
o INDEX (RANGE SCAN DESCENDING)
按照与索引的逻辑顺序的相反顺序对索引进行范围扫描。
o INDEX (FAST FULL SCAN)
快速完全索引扫描,对索引进行快速完全扫描访问。这种访问方式中,不会按照索引的逻辑顺 序访问,而是按照物理顺序读取所有的索引数据块,并且能够每次读取多个数据块。


