




pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
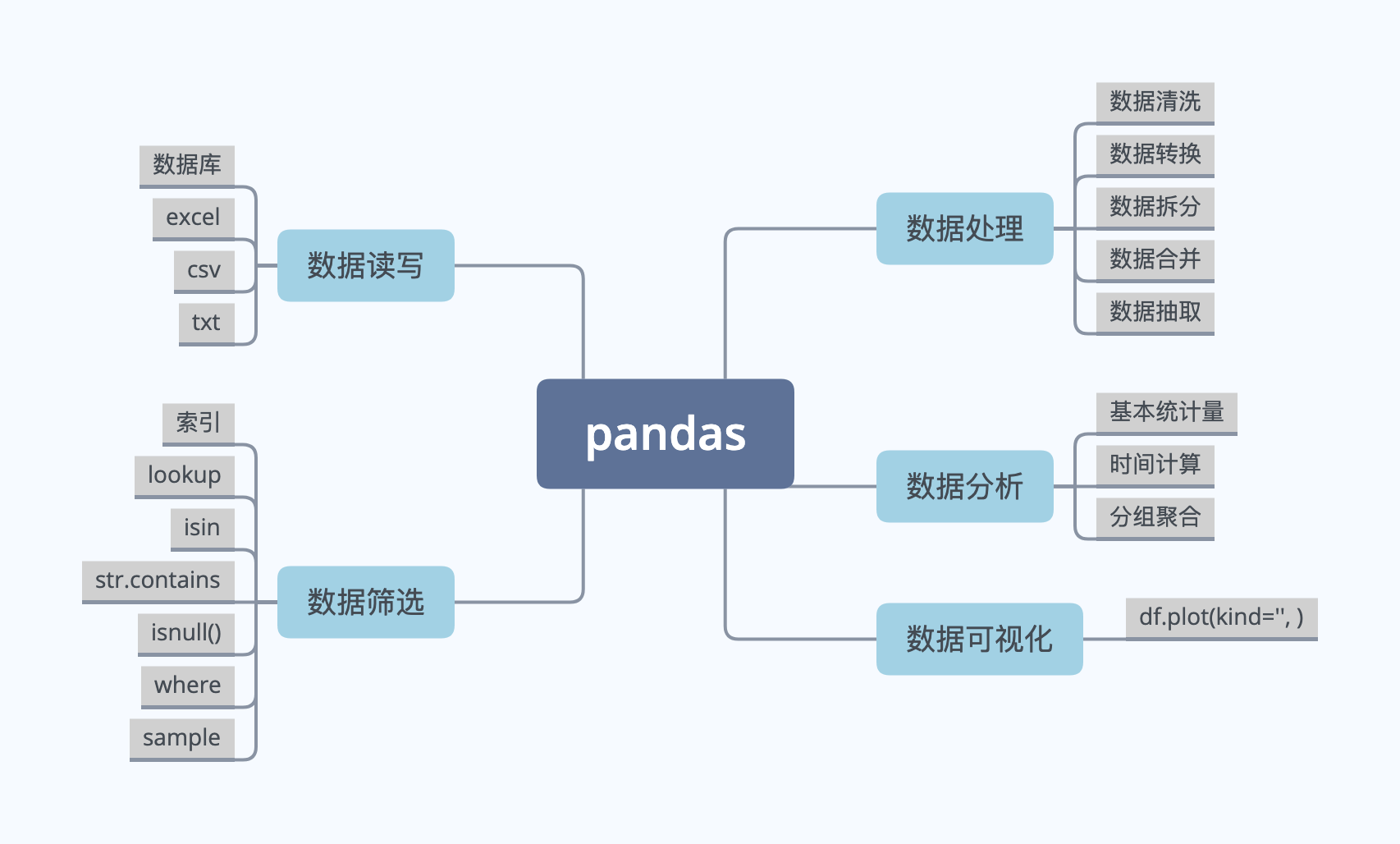
本节首先总结Pandas在数据读写上的应用。Pandas可以读取和写入数据库、excel、csv、txt等文件。
一、数据库
- 读取
import pandas as pd from sqlalchemy import create_engine db = create_engine("mysql+pymysql://用户名:用户密码@localhost:端口号(3306)/使用的数据库名?charset=utf8") sql = "select * from text" df = pd.read_sql(sql, db, index_col="index") # index_col设置索引列,默认自动生成索引复制
- 写入
sql.to_sql(df, name='test', con=db, if_exists="append",# 如果表存在:append追加 replace删除原表新建并插入 fail不插入 index=False # 设置df的索引不插入数据库 )复制
二、Excel
- 读取
df = pd.read_excel(r'file_path', sheet_name='指定sheet,默认第一个', index=False, # 不读取excel中的索引,自动生成新索引 index_col=0, # 将第0列设置为索引 header=0, # 将第n行设置为columns, 默认是0,可以设置为None(自动生成0-n的columns) usecols=[0, 2] # 只导入0, 2列 )复制
- 写入
''' 按照不同sheet写入 ''' # 创建表格 excelWriter = pd.ExcelFile('file_path/test.xlsx') # 写入表格 df.to_excel( excelWriter, sheet_name='', insex=False, # 设置df的索引不传入excel encoding='utf-8', columns=['a', 'b'], # 指定某列写入excel na_rep=0, # 缺失值处理(填充为0) inf_rep=0, # 无穷值处理(填充为0) ) # 保存(不保存不生效) excelWriter.save()复制
''' 直接写入 ''' df.to_excel('file_path/test.xlsx') # 参数:insex、encoding、columns、na_rep、inf_rep复制
三、csv
- 读取
df = pd.read( r'file_path/test.csv', sep="", # 指定分隔符,默认是逗号 nrows=2, # 指定读取行数 encoding='utf-8', engine='python', # 当路径存在中文会报错,加上这个即解决 usecols=[0, 2], # 仅导入0, 2列 index_col=0, # 将第0列设置为索引 header=0 # 将第n行设置为columns, 默认是0,可以设置为None(自动生成0-n的columns) )复制
- 写入
df.to_csv( r'file_path/test.csv', index=False, # 索引列不写入 columns=['a', 'b'], # 指定写入的列 sep=',', # 设置分隔符(默认是逗号) na_rep=0, # 缺失值填充为0 encoding='utf-8', #inf_rep=0 没有这个参数 )复制
四、txt
- 读取
pd.read_table(r'file_path/test.txt', sep='') #也可以用来读取csv文件复制
- 写入
df.to_csv( r'file_path/test.csv', index=False, # 索引列不写入 columns=['a', 'b'], # 指定写入的列 sep=',', # 设置分隔符(默认是逗号) na_rep=0, # 缺失值填充为0 encoding='utf-8', #inf_rep=0 没有这个参数 )复制
最后修改时间:2020-07-08 18:36:04
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
Hologres x 函数计算 x Qwen3,对接MCP构建企业级数据分析 Agent
阿里云大数据AI技术
639次阅读
2025-05-06 17:24:44
DataWorks Copilot 集成 Qwen3-235B-A22B混合推理模型,AI 效能再升级!
阿里云大数据AI技术
181次阅读
2025-04-30 13:39:55
阿里云 AI 搜索开放平台新增:服务开发能力
阿里云大数据AI技术
130次阅读
2025-05-08 15:34:27
python中标识符的命名规则和命名规范
周同学带您玩AI
109次阅读
2025-04-21 10:34:44
银河麒麟智算操作系统筑基,中国长城“全国产大模型智能办公一体机”亮相数字中国
麒麟软件
63次阅读
2025-05-08 10:03:01
分析型数据库与事务型数据库?核心差异与选型指南
镜舟科技
50次阅读
2025-04-22 19:34:33
解决pyqt5 textbrowser控件超链接锚点问题
zayki
43次阅读
2025-04-27 16:58:59
华东师大、PingCAP等:AutoTQA,通过多智能体LLMs实现自主式表格问答
数据库应用创新实验室
40次阅读
2025-04-30 12:18:09
告别 Navicat!QuickAPI 免费可视化神器,重新定义数据库管理与 API 开发
Anita
36次阅读
2025-04-22 19:55:23
云上玩转 Qwen3 系列之三:PAI-LangStudio x Hologres构建ChatBI数据分析Agent应用
阿里云大数据AI技术
34次阅读
2025-05-15 18:22:24
TA的专栏
Java中间件
收录0篇内容
热门文章
一次Connection reset by peer的问题排查
2021-12-07 34289浏览
Java8-Stream: no instance(s) of type variable(s) R exist so that void conforms to R
2021-02-19 32452浏览
nginx: [emerg] "user" directive is not allowed here in /etc/nginx/conf.d/nginx.conf:1
2022-02-15 24361浏览
ORA-00904: "POLTYP": invalid identifier
2019-06-19 12947浏览
PageHelper排坑,处理排序失败: net.sf.jsqlparser.JSQLParserException
2022-05-19 12859浏览
目录
