




本节总结Pandas在数据计算分析上的应用,主要包括:描述统计计算、时间计算、分组聚合、数据标准化。
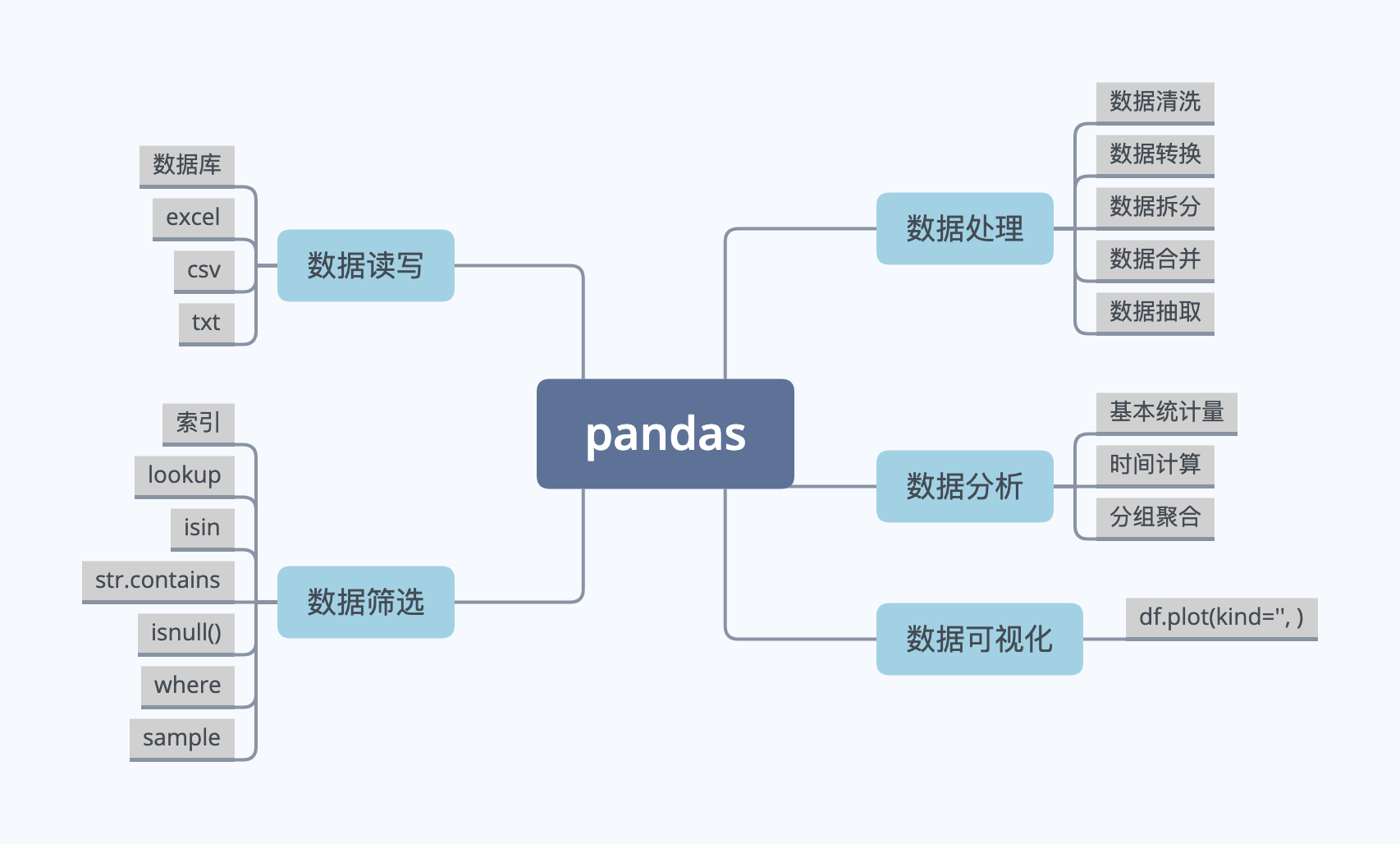
一、基本统计量
# 按行求和 df['row_sum'] = df.apply(lambda x: x.sum(), axis=1) # 按列求和 df.loc['col_sum'] = df.apply(lambda x: x.sum())复制
二、时间计算
- 生成时间
# 生成时间序列(period「生成个数」,freq「10天一个值, 与end不共存」) pd.date_range(start='2020-03-01', end='2020-12-03', periods=10, freq='10D')复制
- 重采样
# 重采样 df = df.set_index('time', drop=True) # 要先把时间列设为索引列 df = df.resample('M').sum() # 将一个月的聚合在一起复制
- 时间的计算
# 时间偏移计算 from datetime import timedelta df['time'] = df['time'] + timedelta(days=10) # 往后推10天 # 计算时间差(dt用来抽取时间) df['date_cha'] = (datetime.now() - data['time']).dt.days复制
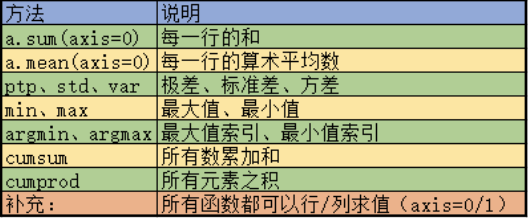
三、分组聚合
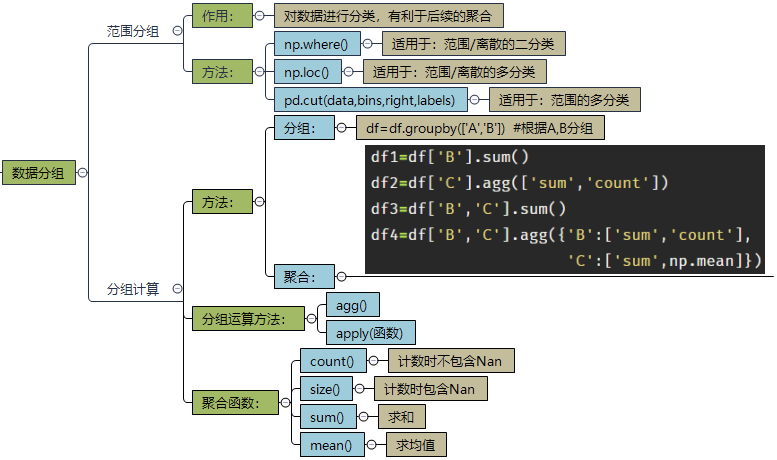
- 范围分组演示
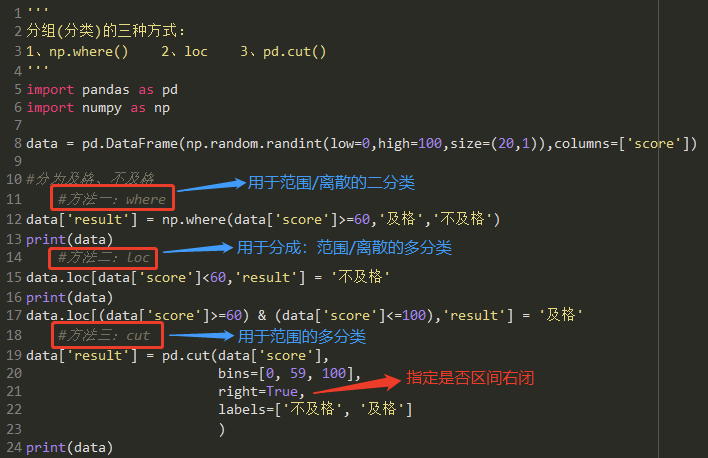
- 另外cut,还可以不指定分组范围列表,直接指定分组数

- 离散的分类

- 另外cut,还可以不指定分组范围列表,直接指定分组数

附加:数据标准化
# 公式 x* = (x - min) / (max - min) # 实现 df = (df - df.min()) / (df.max() - df.min())复制
最后修改时间:2020-07-08 18:36:42
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
[MYSQL] 服务器出现大量的TIME_WAIT, 每天凌晨就清零了
大大刺猬
179次阅读
2025-04-01 16:20:44
官宣,Milvus SDK v2发布!原生异步接口、支持MCP、性能提升
ZILLIZ
116次阅读
2025-04-02 09:34:13
[MYSQL] query_id和STATEMENT_ID在不同OS上的关系
大大刺猬
86次阅读
2025-03-26 19:08:13
用友畅捷通基于阿里云 MaxCompute 搭建智能数仓的落地实践
阿里云大数据AI技术
73次阅读
2025-04-09 09:58:18
什么是 OLAP 数据库?企业如何选择适合自己的分析工具
镜舟科技
48次阅读
2025-03-29 20:34:09
新发布 | 时序数据分析 AI 智能体来啦!
TDengine
48次阅读
2025-03-25 10:37:40
WingPro for Mac 强大的Python开发工具 v10.0.9注册激活版
一梦江湖远
45次阅读
2025-03-29 10:33:27
python操作MySQL数据库
怀念和想念
44次阅读
2025-03-30 23:22:07
【活动回顾】StarRocks Singapore Meetup #2 @Shopee
StarRocks
40次阅读
2025-03-27 10:22:40
如何高效使用 Text to SQL 提升数据分析效率?四个关键应用场景解析
镜舟科技
39次阅读
2025-04-15 18:58:40



TA的专栏
Java中间件
收录0篇内容
热门文章
一次Connection reset by peer的问题排查
2021-12-07 33931浏览
Java8-Stream: no instance(s) of type variable(s) R exist so that void conforms to R
2021-02-19 32354浏览
nginx: [emerg] "user" directive is not allowed here in /etc/nginx/conf.d/nginx.conf:1
2022-02-15 24268浏览
ORA-00904: "POLTYP": invalid identifier
2019-06-19 12929浏览
PageHelper排坑,处理排序失败: net.sf.jsqlparser.JSQLParserException
2022-05-19 12769浏览
目录
