




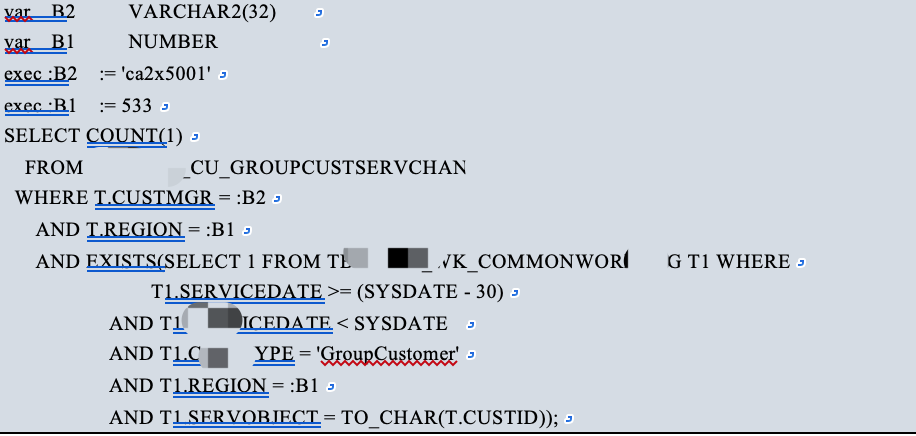
咱先来掐指一算,分析下SQL语句的结构。此语句一打眼就是个统计语句,查询包括两张表,是一个正常的表等值关联的查询语句。
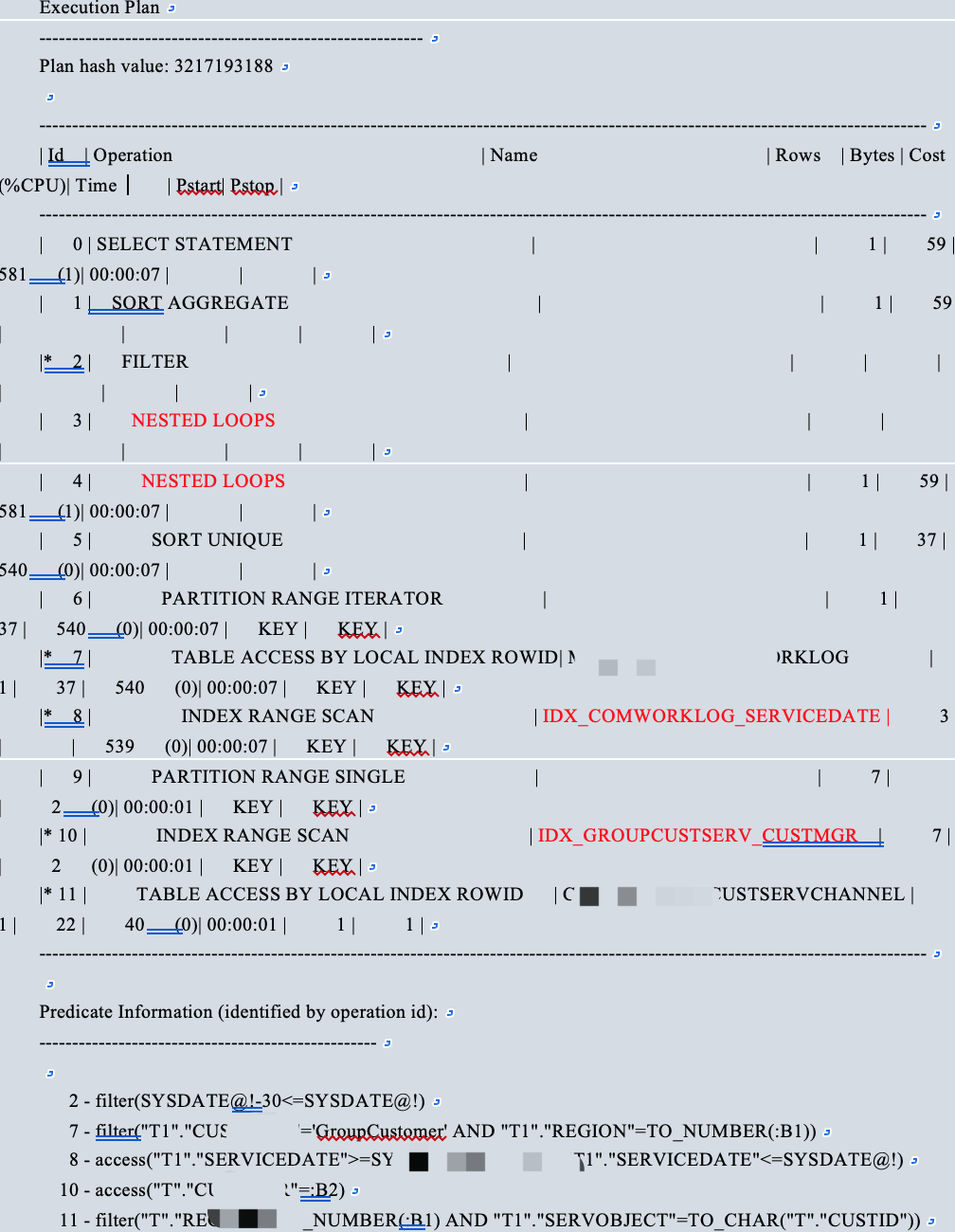
通过仔细查看发现如上执行计划是错误的。简单啰嗦一下执行计划。首先通过T1表的DATE字段选择过滤出结果集,在将表T通过CUSTMGR字段选择出结果集,再将两个查询的结果集通过NESTLOOP方式返回数据。正常情况下如果连接条件不是通过函数进行转换且CUST_ID上有索引的话,会通过索引CUST_ID进行NESTLOOP 返回结果。
那么我们怎么知道选择这种执行计划时不正确的呢?因为比之前正确的执行计划消耗更高。什么?我怎么知道的消耗更高?往下看就知道了嘛。

通过上面的查询结果,我们可以发现在3:30 ,出现了错误的执行计划。那么问题就来了,为什么会有错误的执行计划,为什么在10号发生?
我们可以推断此SQL是在每天3:30的时候进行定时执行,且10号前执行效率很高,所有2500次的执行均在秒内时间就完成了。但在10号后,由于错误执行计划出现,导致SQL执行时间变长,2500次的执行不能在规定时间内跑完,导致sql取数拖到了半天,占用白天的资源,进而影响正常的白天业务。
那么为什么会发生这样的情况呢?我们通过10053来仔细在查看一下:

可以看到提示:Usingprorated density: 0.000001 of col #9 as selectvity ofout-of-range/non-existent value pred
这个提示说明出现了越界现象。当日期判断的范围超出了统计信息记录的最大值和最小值的范围,CBO无法计算选择率,得出错误的结果集,此时通过估计值进行选择,当评估的值与实际情况差别很大时,就会出现选择偏差。

我们看到记录的最大日志是07-10,在与SQL语句SERVICEDATE>= (SYSDATE -30)执行计划出错的日期进行比较,发现8月10号-30天正好超过了记录的最大日期值。这就是执行计划变化发生在8月10日的罪魁祸首。

执行计划已正确。
 很明显与之前错误执行计划trace信息不同,得到的COST和结果集大小不同。
很明显与之前错误执行计划trace信息不同,得到的COST和结果集大小不同。1. 收集表上统计信息
2. 固定SQL的执行计划
3. 创建组合索引,CUSTMGR+时间
3.2 监控执行计划的变化
数据是千变万化的,作为一个老司机,我们多伸一下手顺带考虑通过编写监控脚本来预防问题的后续发生,发生时第一时间知晓及介入。
1. 监控系统中出现SQL_ID和PLAN_HASH_VALUE,1:N的情况,过滤掉OBJECT_STATUS失效的对象,正常一个SQL_ID与一个当前真正使用的PLAN_HASH_VALUE对应,比较执行时间进行报警。
2. 比较SQL_ID-PLAN_HASH_VALUE在历史中是否出现过,比较执行时间进行报警。
3. 使用SQL审核平台进行监控告警。
好了,本新四有好青年的首次春宫秀到此结束,咱们下回再见。
