关联操作
以下操作为数据集关联(JOIN)的操作
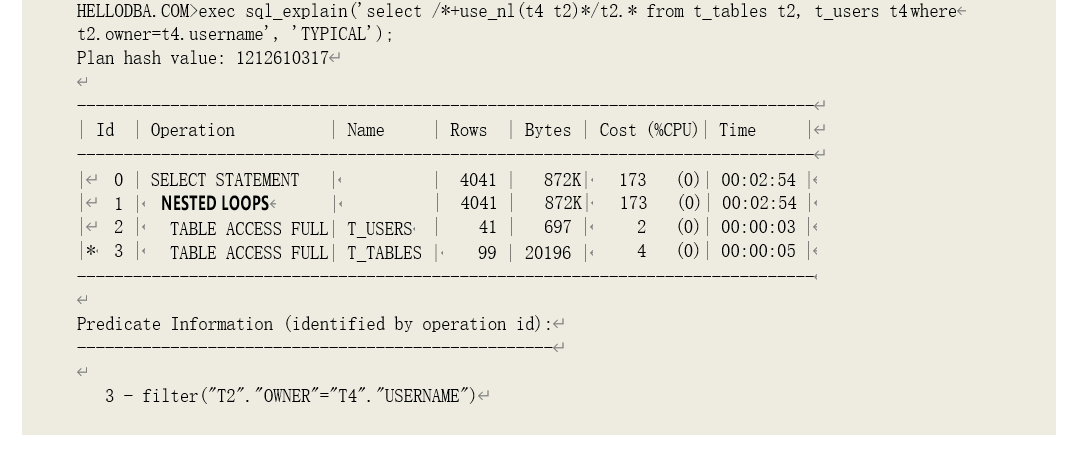
o NESTED LOOPS
通过嵌套循环获取关联数据。
提示:在进行嵌套循环关联时,第一个数据集是驱动数据集,即嵌套循环中的外循环。
o NESTED LOOPS (ANTI)
通过嵌套循环获取非关联数据。
在 NESTED LOOPS (ANTI)的过程中,如果发现外循环中读取到的数据在内循环中能够匹配到, 则立即终止内循环、丢弃该数据,开始下一轮循环。

o NESTED LOOPS (SEMI)
通过嵌套循环获取不完整关联数据。
在 NESTED LOOPS (SEMI)的过程中,如果发现外循环中读取到的数据在内循环中能够匹配到, 则立即终止内循环、返回该数据,开始下一轮循环。

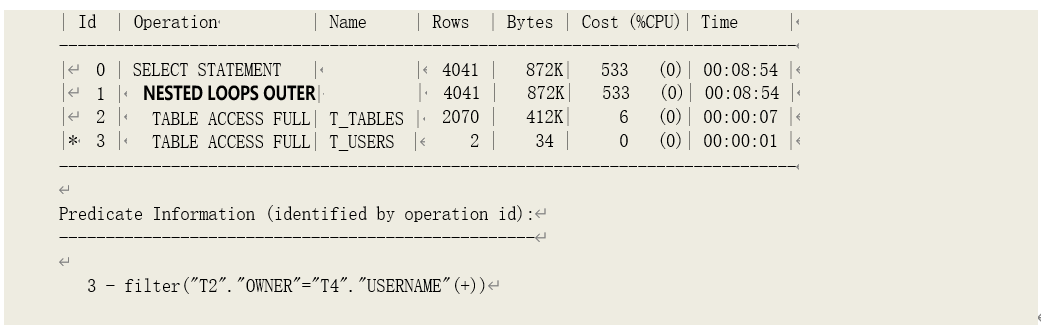
o NESTED LOOPS (OUTER)
通过嵌套循环进行外连接,获取关联数据。
我们通常说的连接,如果没有特别指明,都是说内连接。而外连接与内连接的不同之处在于, 外循环中的数据无论在内循环中是否找到匹配数据都会被返回。

o NESTED LOOPS (PARTITION OUTER)
以左外连接的左边数据集(或右外连接的右边数据集)为外循环,将左外连接的右边数据集
(或右外连接的左边数据集)分组(分区)进行外连接匹配。
提示:对于分区左(右)外连接,从逻辑上看,左(右)表需要与右(左)表中的数据分组(分区) 分别做外连接。如果实际操作也按照这个逻辑实现,则意味着每次与一组数据进行连接,都要读取 一次左(右)表数据。而再 NESTED LOOPS PARTITION OUTER 中,第一次读取左(右)表数据后,
就被缓存在私有内存中,从而避免了多次重复读取共享内存数据。

o HASH JOIN
通过数据集的哈希值匹配获取关联数据。
进行哈希关联时,先用哈希函数对左数据集(也称为构建数据集)按哈希值分区,并且创建哈希表,映射哈希键值与分区;然后逐条扫描右数据集(也称为探测数据集)的数据记录,用相同的 哈希函数获取哈希值,并与哈希表进行匹配,找到相应的构建数据集的哈希分区,然后再用分区中的数据进行精确匹配。
哈希值与原始数据之间的关系是一对多的关系。即对于同一个哈希算法,一条原始数据只会有 一个哈希值,且多条不同数据的哈希值可能相同。

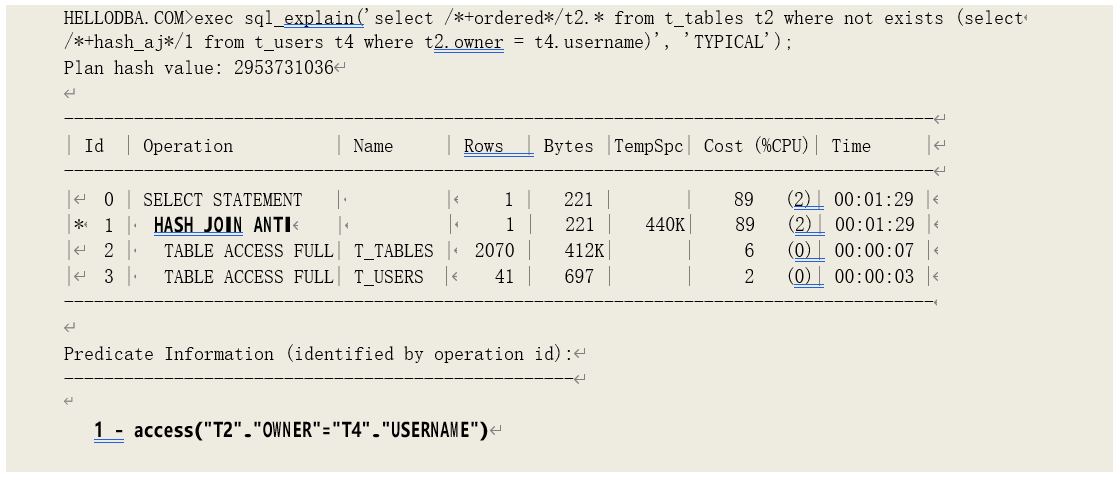
o HASH JOIN (ANTI)
通过数据集的哈希值匹配获取非关联数据。
在匹配的过程中,如果哈希值相同、且数值匹配,则立即终止对关联哈希表中的剩余哈希值的 匹配、丢弃该条数,开始下一轮匹配。
提示:如果作为驱动的数据集的哈希表非常大,以至于内存中哈希空间无法一次性完成两边哈希表
的匹配的话,则会将驱动哈希分为一个小的哈希表,一次匹配一个,其它的则暂时存储到临时表空间上去。我们可以注意到上述执行计划中有对临时表空间的估算值(TempSpc)。
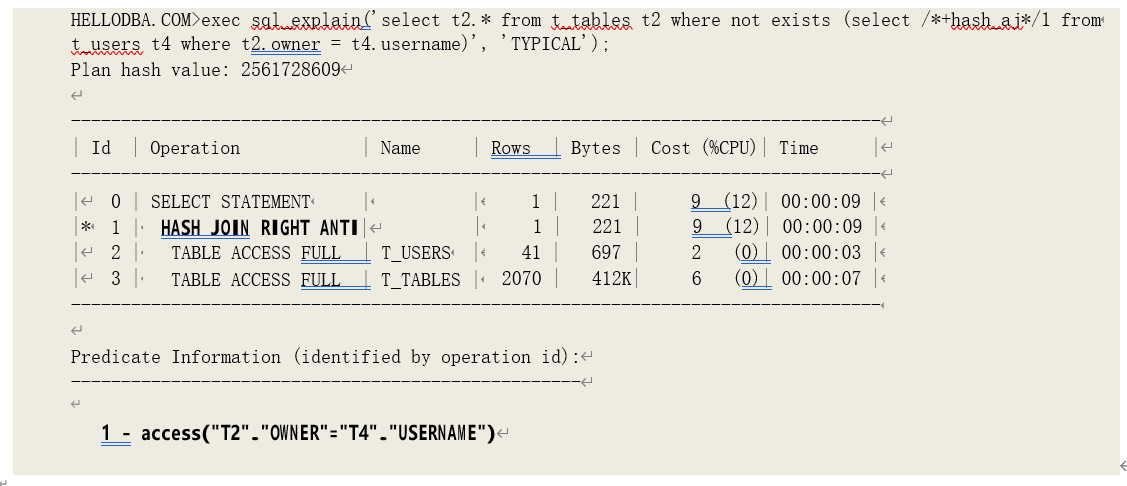
o HASH JOIN (RIGHT ANTI)
取右边数据集做驱动,通过数据集的哈希值匹配获取非关联数据。
如果驱动数据集太大,以至于需要分配临时空间暂存哈希表,优化器则会考虑采用数据量较少的关联数据集作为驱动。此时,就需要 HASH JOIN RIGHT ANTI 进行关联:同样,在匹配的过程中, 如果两边的哈希值相同、且数值匹配,则立即终止对关联哈希表中的剩余哈希值的匹配、丢弃该条 数,开始下一轮匹配;不同的是,如果所有记录都未匹配,则返回关联数据集中的数据,而非驱动 数据集的数据。
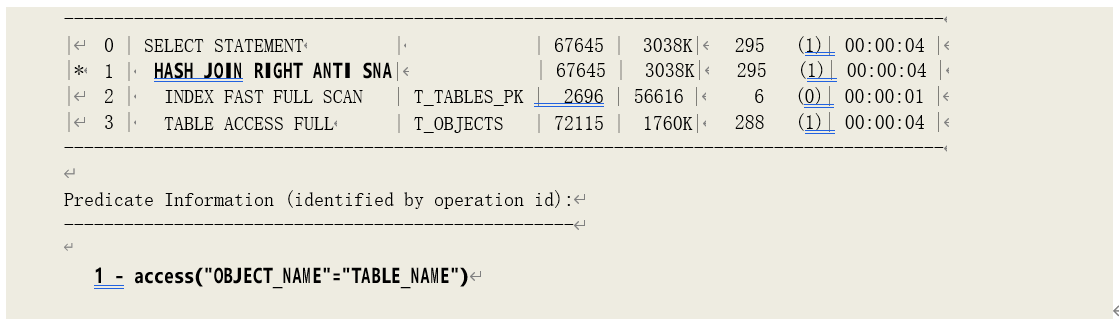
o HASH JOIN (ANTI SNA)
通过数据集的哈希值匹配获取非关联数据,并且同时关注是否有空值。这一操作是在 11g 中引入的。
提示:非关联查询时,是否进行检测控制,可以由优化器参数"_optimizer_null_aware_antijoin"控制。

o HASH JOIN (RIGHT ANTI SNA)
取右边数据集做驱动,通过数据集的哈希值匹配获取非关联数据,并且同时关注是否有空值。 这一操作是在 11g 中引入的。
示例(11.2.0.1):

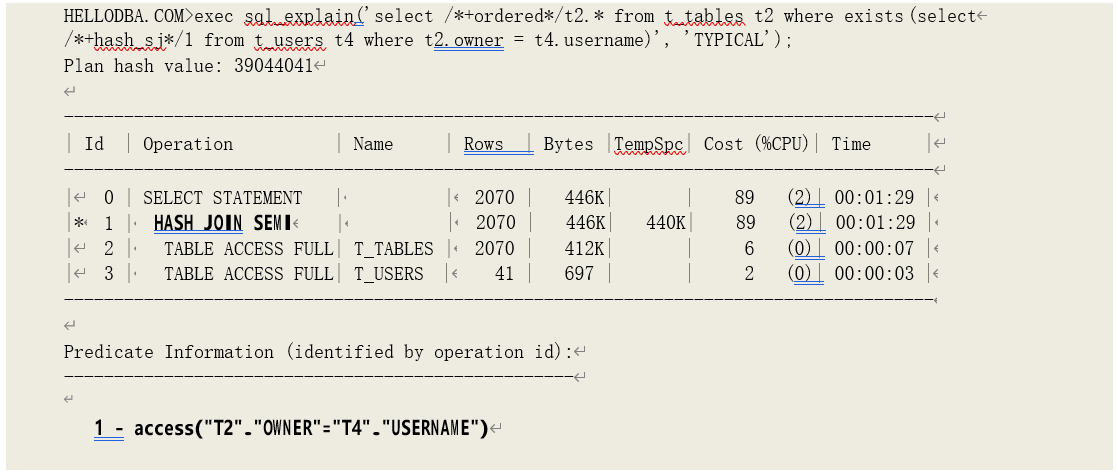
o HASH JOIN (SEMI)
通过数据集的哈希值匹配获取不完整关联数据。
在匹配过程中,如果哈希值相同、且数值匹配,则立即终止对关联哈希表中的剩余哈希值的匹配、返回该条数,开始下一轮匹配。
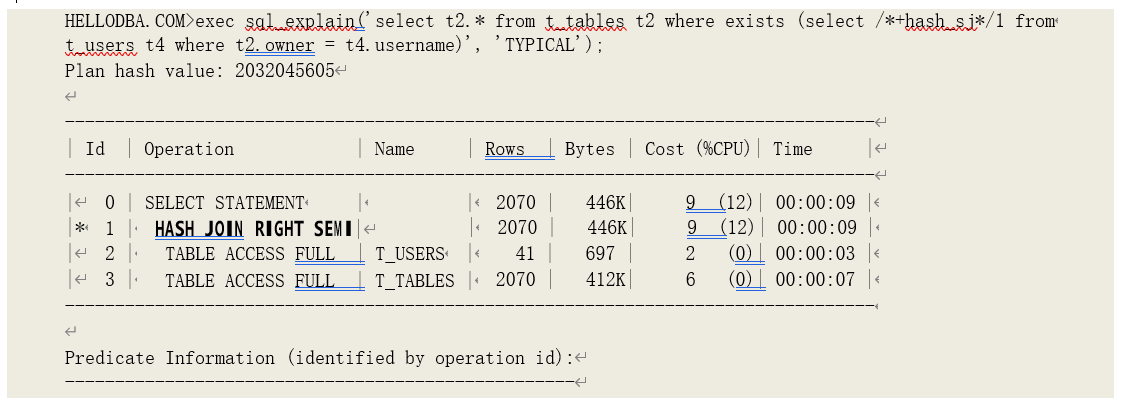
o HASH JOIN (RIGHT SEMI)
取右边数据集做驱动,通过数据集的哈希值匹配获取不完整关联数据。
如果驱动数据集太大,为了避免读写临时表空间,优化器会考虑通过 HASH JOIN RIGHT SEMI 进行关联:同样,在匹配过程中,如果哈希值相同、且数值匹配,则立即终止对关联哈希表中的剩余 哈希值的匹配、返回关联数据集中的条数,开始下一轮匹配;返回关联数据集中的数据,而非驱动数据集的数据。

HASH JOIN (OUTER)
通过数据集的哈希值匹配进行外(左)连接数据关联。
这里的外连接,实际上就是左外连接。通过哈希值匹配进行外连接操作时,左数据集的数据无论是否匹配到右数据集,都会被获取

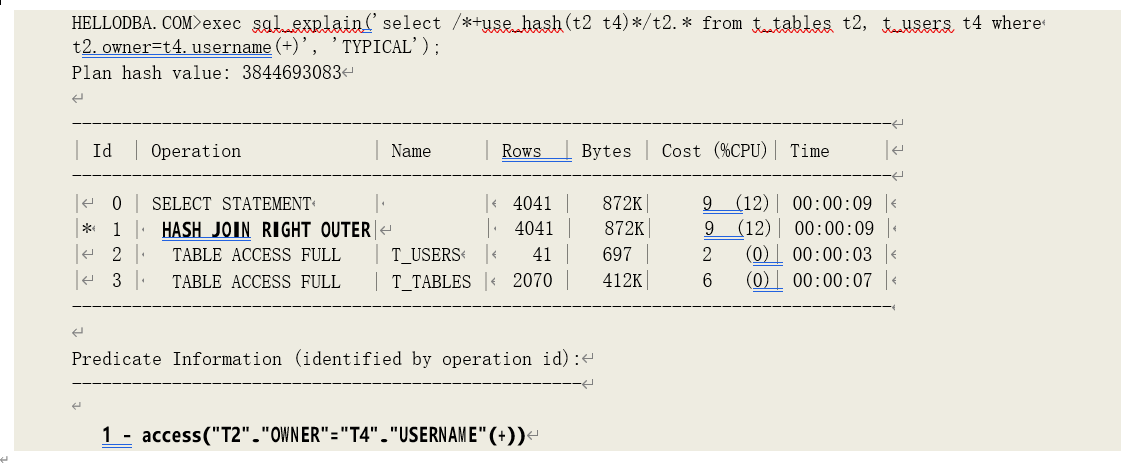
o HASH JOIN (RIGHT OUTER)
通过数据集的哈希值匹配进行右外连接数据关联。
o HASH JOIN (FULL OUTER)
通过数据集的哈希值匹配进行连接数据完全关联。
提示:该操作在 10.2.0.4 以后引入。


o MERGE JOIN
通过合并已排序的数据进行关联。示例参见下例。
进行合并关联时,分别从两个数据集的首位开始对数据进行比较,如果相等,则说明数据匹配,则对两边数据集的下一条数据进行比较;如果不相等,则获取较小数值(如果为降序,则是大数值) 所在数据集的下一条记录;当两边数据集都存在多条相等的记录时,需要在这多条记录之间进行多 重投影匹配(Multiple Cast)。
o SORT (JOIN)
对进行数据合并关联(Merge Join)而进行排序。
提示:在做合并关联(Merge Join)时,要求两边数据集已经排好序

o MERGE JOIN (ANTI)
通过进行数据合并关联(Merge Join)获取非关联数据。
通过合并关联获取非关联数据时,如果左指针指向的数据大于右边数据,则右指针向后移一位, 进行下一次比较;如果相等,两边指针都向后移一位;如果左边数据小于右边数据,则返回左数据
(因为右边不会存在与其相等的数据了),并且指针向后移动。
由于右数据集只是起到数据比较的作用,而不需要返回数据,因此会对右数据集进行唯一性排序,排除重复数据,以减少匹配次数。

o MERGE JOIN (OUTER)
通过进行数据合并关联获取进行(左)外连接,获取关联数据。
通过合并关联进行左外连接时,右边数据记录大于、等于左边数据记录都属于匹配记录。

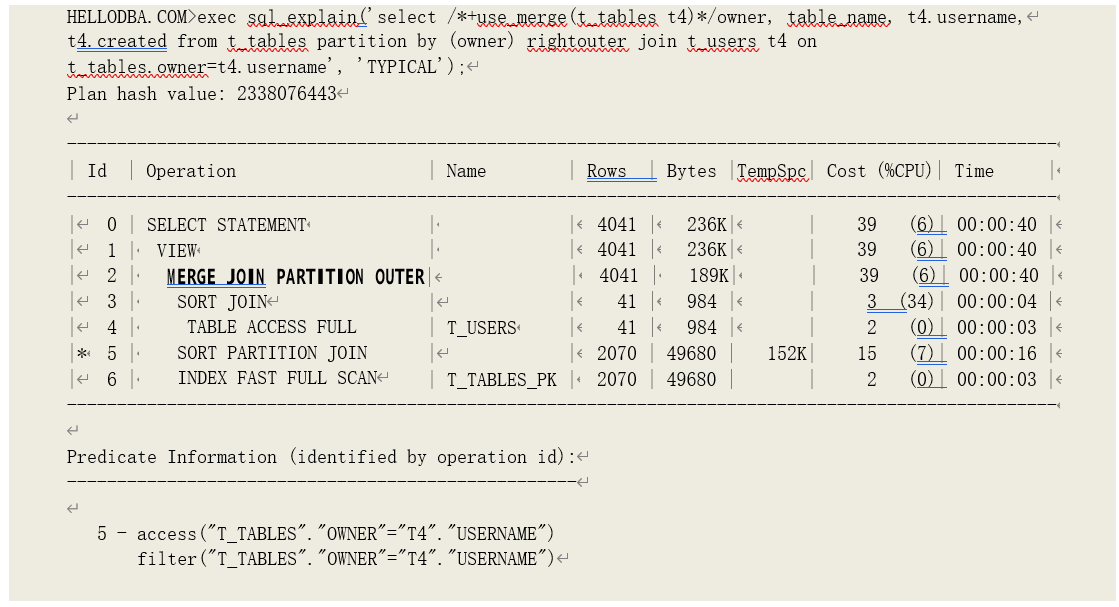
o MERGE JOIN (PARTITION OUTER)
将右边数据集分组(分区),左数据集分别与每组数据进行合并外连接,以获取关联数据。
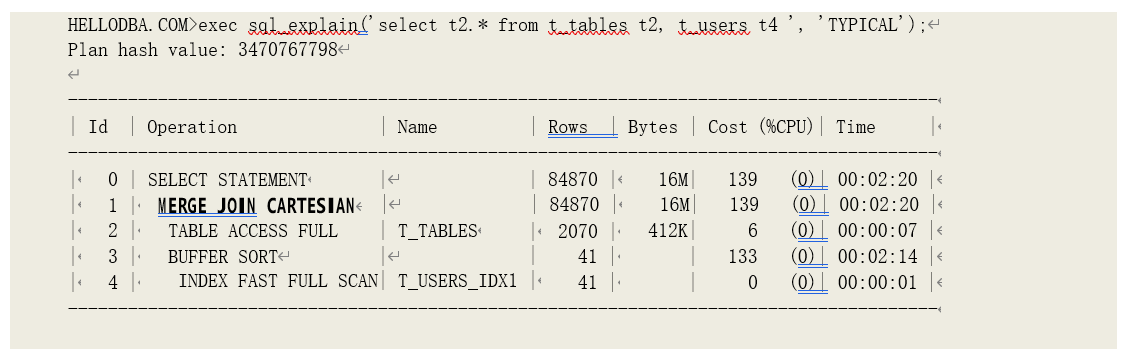
o MERGE JOIN (CARTESIAN)
通过合并关联对数据集进行笛卡尔关联。
提示:进行笛卡尔关联时,两边数据集中的任何一条数据记录都会与关联数据集中的任何一条记录匹配;也就是说,它们之间不存在关联条件。
排序后的数据是缓存是私有内存中,因而可以减少对共享缓存的访问次数和锁阀(Latch)的争用。
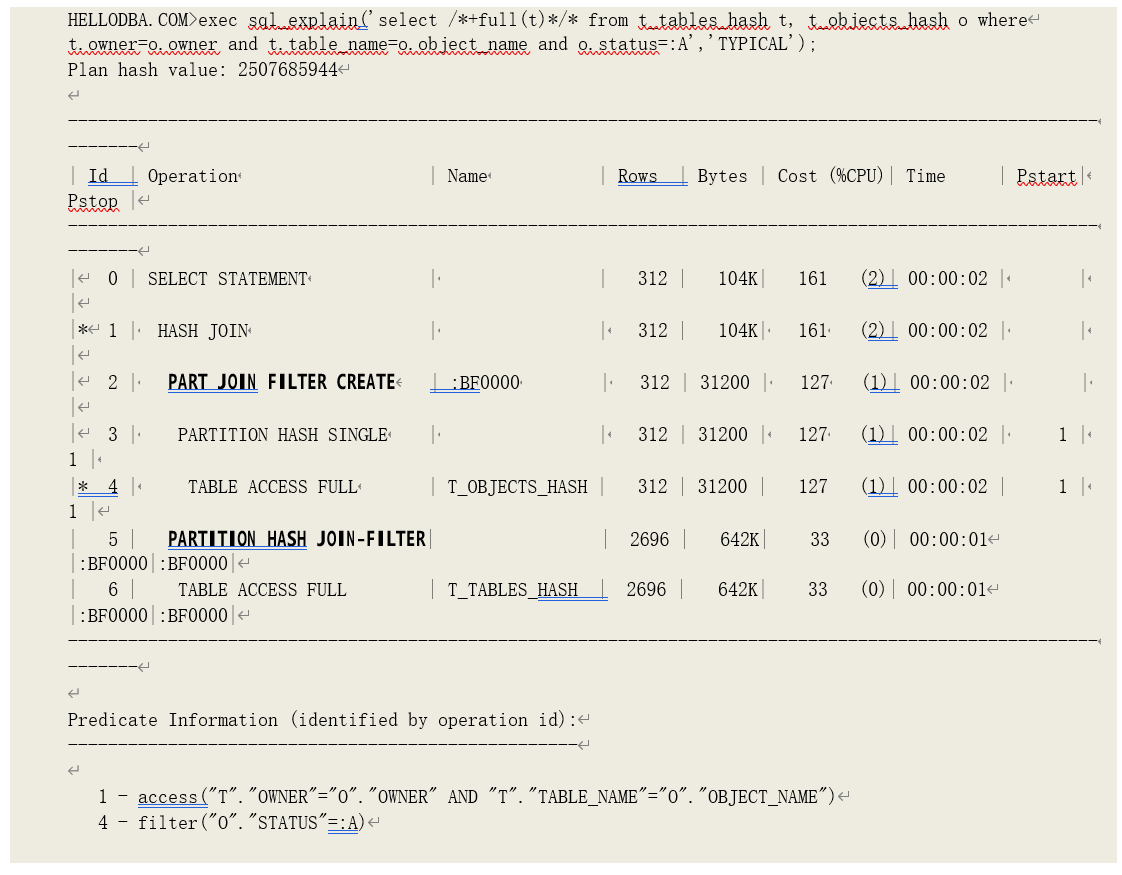
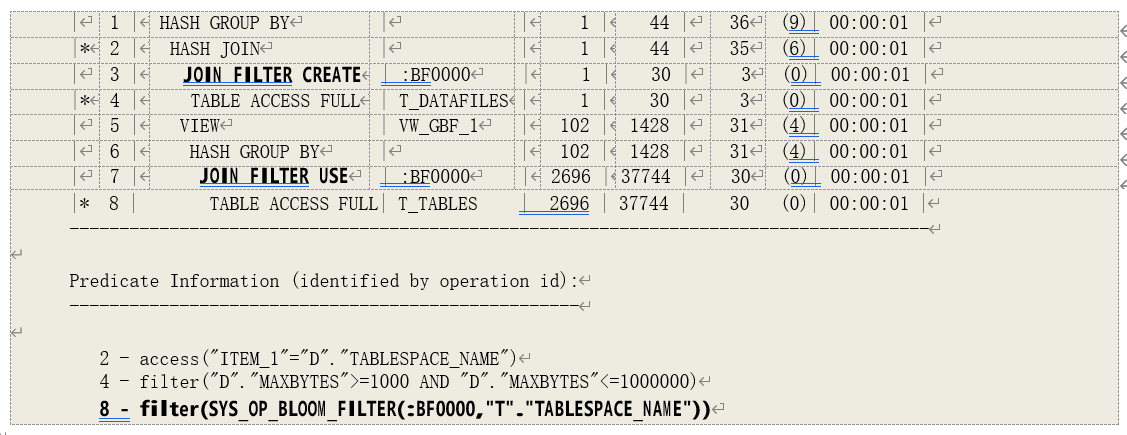
o JOIN FILTER (CREATE)
创建一个过滤器,以用于布隆过滤(Bloom Filter),示例参见下例。
o JOIN FILTER (USE)
使用系统创建额过滤器进行布隆过滤。
关键词释义:布隆过滤器(Bloom Filter)是用于判断一个元素是否属于一个数据集的数据结构。其基本思想就是用一个或多个哈希函数对数据集中的每个成员做映射,映射结果不是存在完整的哈希表中,而是一个位向量(bit vector)中。位向量所有位初始都为 0,根据哈希结果将位向量中相应位置 1。对数据集中的所有成员的 hash 计算完成后,就得到了该数据集的位向量。当需要判断一个元素是否属于该数据集时,也用相同的哈希函数对其映射得到它的位向量,然后将其位向量上所有为 1 的位与数据集位向量上相应位比较,如果发现数据集的位向量上某个位为 0 的话,可以判断这个元素不属于该数据集,这样的一个结果是肯定的。而如果所有相应位都为 1 的话,那么该元素可能属于这个数据集。
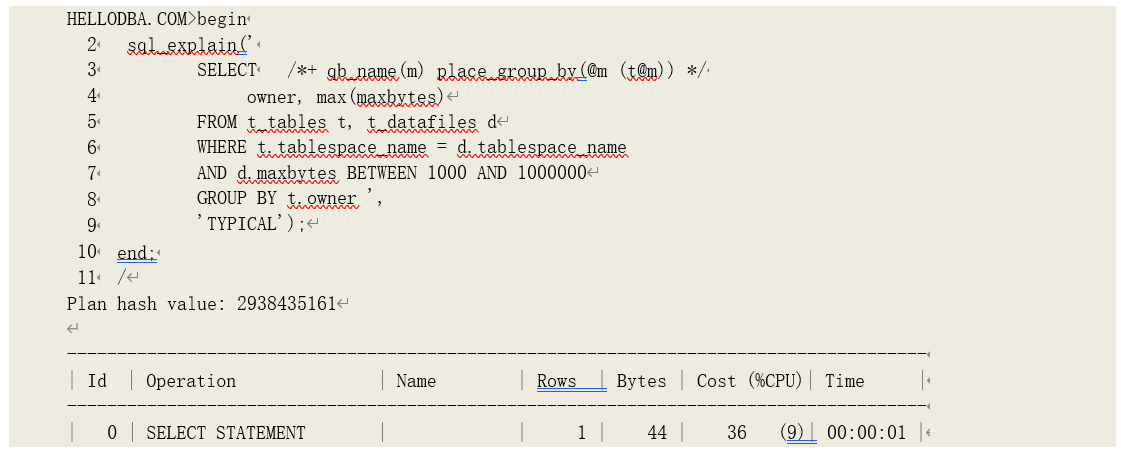
示例 1(需在 11gR2 中运行),利用哈希关联的哈希算法建立布隆过滤器:

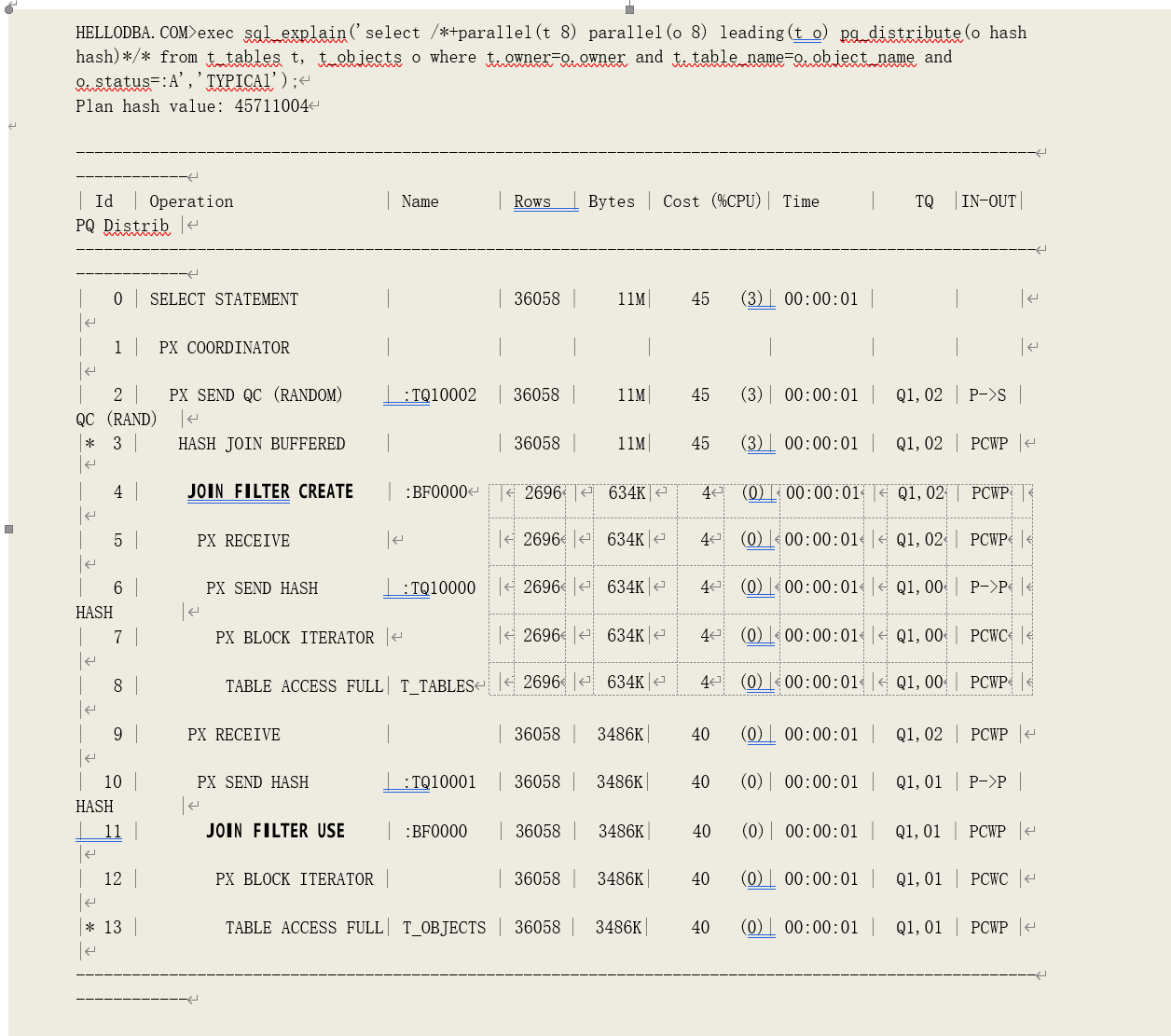
示例 2,(需在 11gR2 中运行),利用并行哈希关联的哈希算法建立布隆过滤器:

o PART JOIN FILTER (CREATE)
在哈希关联时创建布隆过滤,用于分区裁剪。该操作在 11g 被引入。示例参见下例。
o PARTITION HASH (JOIN-FILTER)
利用布隆过滤,进行分区裁剪。
示例(11.2.0.1):