




问题描述
某客户数据库Oracle RAC 环境中节点出现重启现象,几分钟后集群自动恢复,影响部分业务,分析思路如下:
问题分析
CRS日志分析,数据库无法启动,数据库监听状态异常:
2020-06-15 05:32:29.990:
[/oraapp/11.2.0/grid/bin/oraagent.bin(17438)]CRS-5011:Check of resource "testrac" failed: details at "(:CLSN00007:)" in "/oraapp/11.2.0/grid/log/testrac1/agent/crsd/oraagent_oracle/oraagent_oracle.log"
2020-06-15 05:32:49.078:
[cssd(8806)]CRS-1662:Member kill requested by node testrac2 for member number 0, group DBtestrac
2020-06-15 05:33:19.742:
[cssd(8806)]CRS-1608:This node was evicted by node 2, testrac2; details at (:CSSNM00005:) in /oraapp/11.2.0/grid/log/testrac1/cssd/ocssd.log.
2020-06-15 05:33:19.742:
[cssd(8806)]CRS-1656:The CSS daemon is terminating due to a fatal error; Details at (:CSSSC00012:) in /oraapp/11.2.0/grid/log/testrac1/cssd/ocssd.log
2020-06-15 05:33:19.742:
[cssd(8806)]CRS-1652:Starting clean up of CRSD resources.
2020-06-15 05:33:19.835:
[cssd(8806)]CRS-1608:This node was evicted by node 2, testrac2; details at (:CSSNM00005:) in /oraapp/11.2.0/grid/log/testrac1/cssd/ocssd.log.
2020-06-15 05:33:19.835:
[cssd(8806)]CRS-1604:CSSD voting file is offline: /dev/raw/raw1; details at (:CSSNM00058:) in /oraapp/11.2.0/grid/log/testrac1/cssd/ocssd.log.
2020-06-15 05:33:19.835:
[cssd(8806)]CRS-1604:CSSD voting file is offline: /dev/raw/raw3; details at (:CSSNM00058:) in /oraapp/11.2.0/grid/log/testrac1/cssd/ocssd.log.
2020-06-15 05:33:19.835:
[cssd(8806)]CRS-1604:CSSD voting file is offline: /dev/raw/raw4; details at (:CSSNM00058:) in /oraapp/11.2.0/grid/log/testrac1/cssd/ocssd.log.
2020-06-15 05:33:21.184:
[/oraapp/11.2.0/grid/bin/oraagent.bin(14932)]CRS-5016:Process "/oraapp/11.2.0/grid/opmn/bin/onsctli" spawned by agent "/oraapp/11.2.0/grid/bin/oraagent.bin" for action "check" failed: details at "(:CLSN00010:)" in "/oraapp/11.2.0/grid/log/testrac1/agent/crsd/oraagent_grid//oraagent_grid.log"
2020-06-15 05:33:21.787:
[/oraapp/11.2.0/grid/bin/oraagent.bin(14932)]CRS-5016:Process "/oraapp/11.2.0/grid/bin/lsnrctl" spawned by agent "/oraapp/11.2.0/grid/bin/oraagent.bin" for action "check" failed: details at "(:CLSN00010:)" in "/oraapp/11.2.0/grid/log/testrac1/agent/crsd/oraagent_grid//oraagent_grid.log"
2020-06-15 05:33:21.789:
[/oraapp/11.2.0/grid/bin/oraagent.bin(14932)]CRS-5016:Process "/oraapp/11.2.0/grid/bin/lsnrctl" spawned by agent "/oraapp/11.2.0/grid/bin/oraagent.bin" for action "check" failed: details at "(:CLSN00010:)" in "/oraapp/11.2.0/grid/log/testrac1/agent/crsd/oraagent_grid//oraagent_grid.log"
2020-06-15 05:33:22.052:
[cssd(8806)]CRS-1654:Clean up of CRSD resources finished successfully.
2020-06-15 05:33:22.053:
[cssd(8806)]CRS-1655:CSSD on node testrac1 detected a problem and started to shutdown.
发现数据库的asm实例也出现异常。
分析gipc日志:
2020-06-15 05:39:45.691: [GIPCDMON][1163826944] gipcdMonitorCssCheck: found node testrac2
2020-06-15 05:39:45.691: [GIPCDMON][1163826944] gipcdMonitorCssCheck: updating timeout node testrac2
2020-06-15 05:39:45.691: [GIPCDMON][1163826944] gipcdMonitorCssCheck: updating timeout node testrac2
2020-06-15 05:39:45.691: [GIPCDMON][1163826944] gipcdMonitorFailZombieNodes: skipping live node 'testrac2', time 0 ms, endp 0000000000000000, 00000000000008b9
2020-06-15 05:39:45.691: [GIPCDMON][1163826944] gipcdMonitorFailZombieNodes: skipping live node 'testrac2', time 0 ms, endp 0000000000000000, 0000000000000a09
2020-06-15 05:39:46.443: [GIPCDCLT][1168029440] gipcdClientThread: req from local client of type gipcdmsgtypeInterfaceMetrics, endp 00000000000003d5
2020-06-15 05:39:48.948: [ CLSINET][1163826944] Returning NETDATA: 1 interfaces
2020-06-15 05:39:48.948: [ CLSINET][1163826944] # 0 Interface 'bond1',ip='172.1.2.108',mac='90-e2-ba-eb-98-4c',mask='255.255.255.0',net='172.1.2.0',use='cluster_interconnect'
2020-06-15 05:39:48.998: [GIPCDMON][1163826944] gipcdMonitorSaveInfMetrics: inf[ 0] bond1 - rank 99, avgms 0.346535 [ 160 / 206 / 202 ]
2020-06-15 05:39:48.998: [GIPCDMON][1163826944] gipcdMonitorSaveInfMetrics: saving: bond1:99
2020-06-15 05:39:49.432: [GIPCDCLT][1168029440] gipcdClientThread: req from local client of type gipcdmsgtypeInterfaceMetrics, endp 0000000000000472
2020-06-15 05:39:50.452: [GIPCDCLT][1168029440] gipcdClientThread: req from local client of type gipcdmsgtypeInterfaceMetrics, endp 0000000000000121
2020-06-15 05:39:50.690: [GIPCDCLT][1168029440] gipcdClientThread: req from local client of type gipcdmsgtypeInterfaceMetrics, endp 000000000000032f
集群的心跳一直处于正常状态。
asm agent日志:
2020-06-15 05:31:44.452: [ora.asm][1207957248]{0:0:2} [check] ConnectionPool::removeConnection connection count 0
2020-06-15 05:31:44.452: [ora.asm][1207957248]{0:0:2} [check] ConnectionPool::removeConnection freed 0
2020-06-15 05:31:44.452: [ora.asm][1207957248]{0:0:2} [check] ConnectionPool::stopConnection sid +ASM1 status 1
2020-06-15 05:31:44.452: [ora.asm][1207957248]{0:0:2} [check] InstAgent::check 1 prev clsagfw_res_status 3 current clsagfw_res_status 5
2020-06-15 05:31:44.453: [ AGFW][1205856000]{0:0:2} ora.asm 1 1 state changed from: UNKNOWN to: FAILED
asm的资源已经offline。
查看数据库ash发现,故障前一段时间,数据库在做备份的动作:
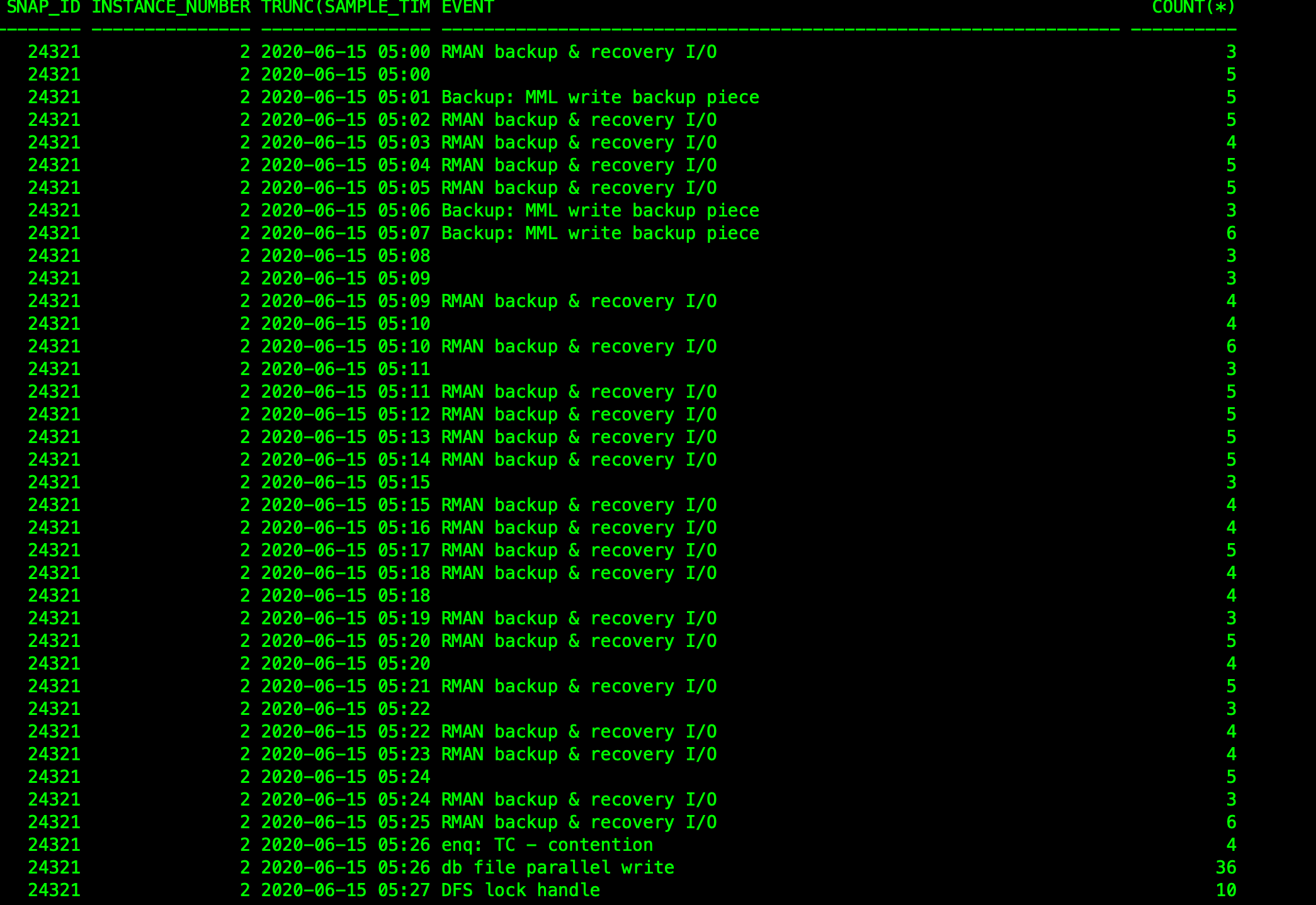
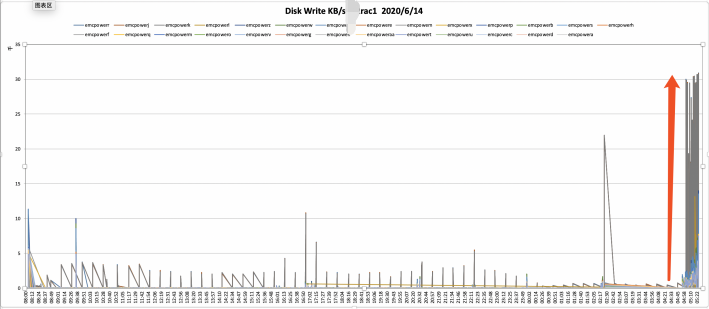

磁盘有大量的写入操作,并且有大量的换入换出动作。
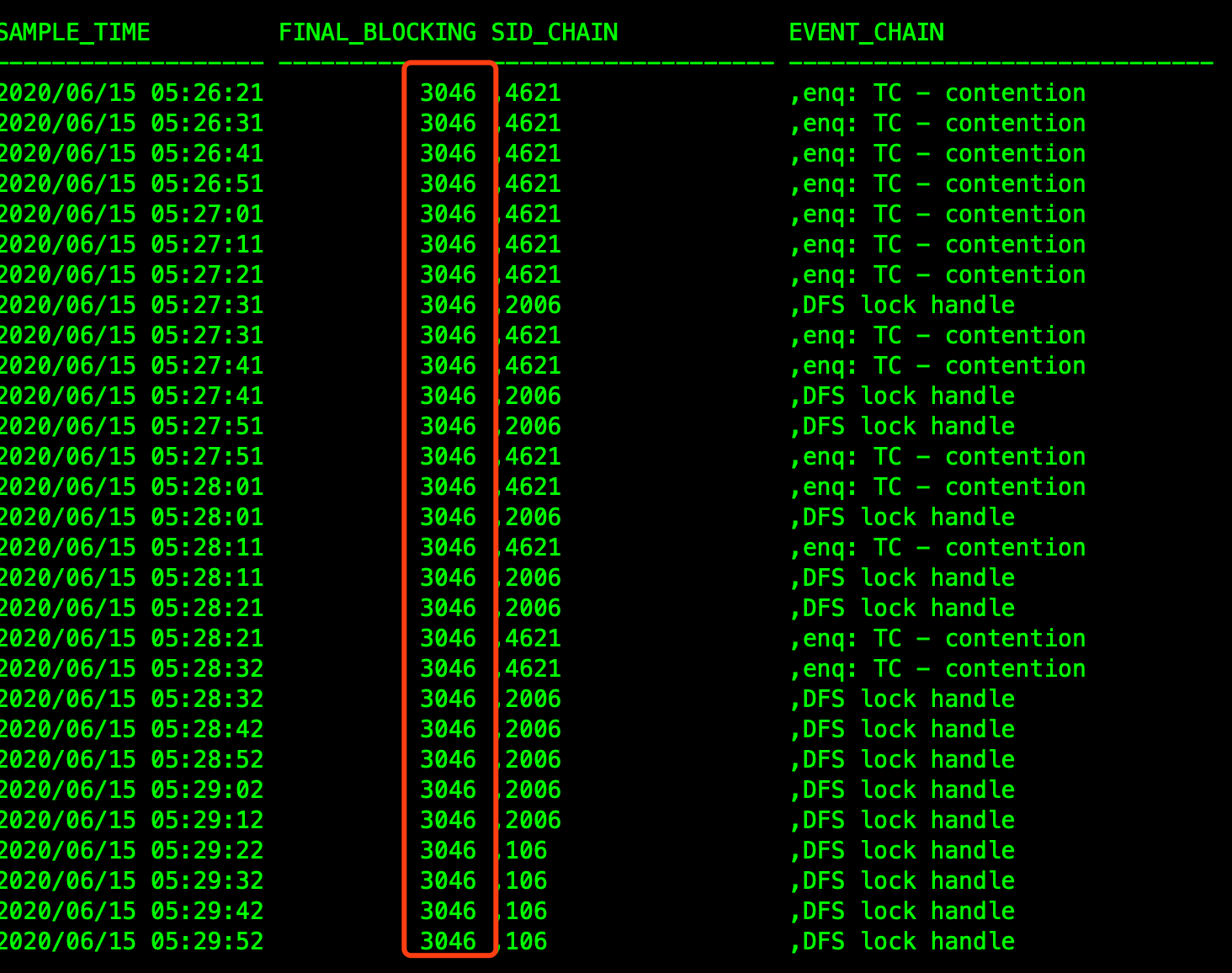

ASH里会话都被sid 3046阻塞,3046会话是ckpt进程。
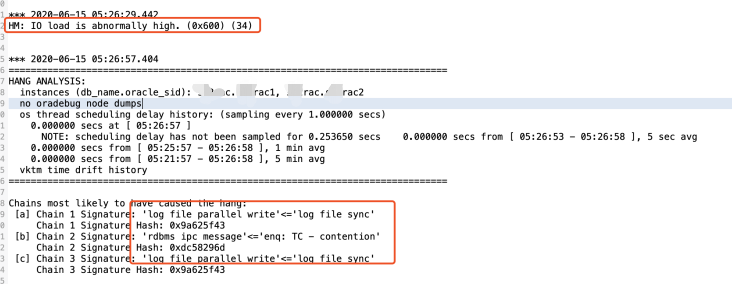
从分析ckpt进程的trace得出:
告警数据库的IO负载异常高,并且出现log file parallel write写的等待。说明当时IO出现了异常。两个节点之间也出现通讯异常。enq: TC – contention,执行ALTER TABLESPACE … BEGIN BACKUP后,将属于此表空间的所有高速缓冲区的脏块记录到磁盘上,这个过程经历enq: TC - contention等待。
OS日志:
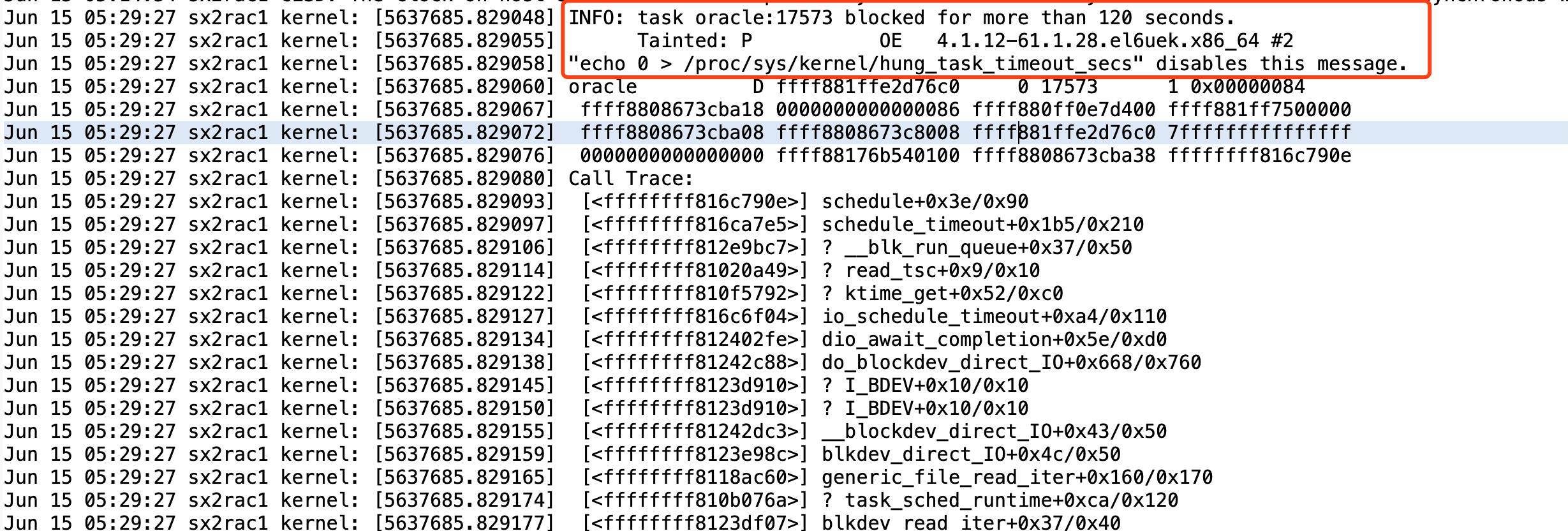
Message里出现告警:
17573 blocked for more than 120 seconds. “echo 0 > /proc/sys/kernel/hung_task_timeout_secs” disables this message.
改现象与官方mos文档:(Doc ID 1423693.1)现象一致。
问题解决
1、建议调整rman备份的策略,比如修改并发度。
2、修改内核参数
参考语句:
vm.min_free_kbytes = 262144
vm.swappiness=100
3、设置大页
使用hugepage功能时候需要禁用11g新特性 Auto Memory Management (AMM)
memory_target = 0
memory_max_target=0
参考:
