




关于 CPU 的多核架构,常见的有三种主要的架构:SMP、MPP、NUMA,其设计的目的,都是为了能够让服务器或者集群拥有更好的处理性能。
2. MPP
3. NUMA
NUMA(Non-Uniform Memory Access)架构,中文翻译为“非统一内存访问架构”,是站在前人的肩膀上做出的优化设计。它融合了 SMP 和 MPP 架构的特点,能够让服务器提供更加出色的 CPU 计算能力。
随着摩尔定律的持续发挥作用,服务器 CPU 主频越来越高,并且开始往多核架构的方向狂奔。但是在 SMP 架构下,多处理器共用北桥来读取内存的设计,已经成为限制多处理器性能的瓶颈。
天才的设计师们于是就想到:如果将内存访问器也做拆分,问题不就迎刃而解吗?每个处理器分配独立的内存,就不会再有 SMP 架构下受北桥读取内存的性能影响。
1. NUMA 对系统的影响
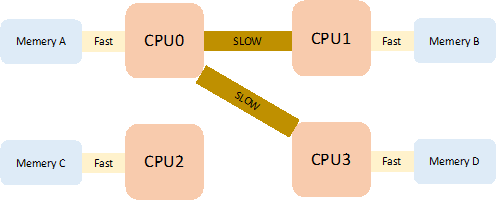
在 NUMA 架构下,内存是直接 attach 到各个 CPU 上,CPU 访问自身内存资源的性能是访问别的 CPU 的内存资源的三倍。
NUMA 特性被打开,线程申请内存优先从本 CPU 中获取内存资源;
系统缺少内存动态分配策略,使得在某些 CPU 中出现内存倾斜;
如果某个 CPU 中持续出现严重的内存资源紧张,则会触发系统的 kswapd 服务开始做内存回收操作;
如果内存资源小于最小的 kernel 中的 min_free_kbytes 设置,则还会触发 Linux 系统的 OOM 机制,启动进程 Killer 操作。
2. NUMA 对数据库的影响
NUMA 架构,实际就是系统为了让 CPU 能够尽可能利用高性能的内存资源,而导致内存资源分配不均匀的问题。
NUMA 架构对于数据库的影响,存在以下负面影响:
某些 CPU 单元的内存资源紧张,或者持续触发 kswapd 服务,影响性能;
文件系统缓存不足,导致cache 数据被释放,降低数据库访问时的内存命中率;
整体系统剩余大量的内存,但是数据库却遇到 OOM 错误,甚至被 Killer 强行退出服务的现象;
操作系统出现内存不足问题,导致大量数据被暂时保存于Swap交换空间中,系统响应速度降低,甚至出现卡死现象;
3. NUMA 对内存分配的影响
以 Linux Centos 7.6 为例,如果服务器的 CPU 存在 48 cores,总内存大小为256GB,如果一个 SequoiaDB 的数据节点 PID=175039,在没有对 NUMA 做任何的调整,通过社区中的Jeremy Cole (https://blog.jcole.us/) 提供的 numa-maps-summary.pl 程序 (http://jcole.us/blog/files/numa-maps-summary.pl) 可以看到每个 CPU zone 对内存的分配极其不均衡。
$> numactl --hardwareavailable: 2 nodes (0-1)node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46node 0 size: 130976 MBnode 0 free: 1415 MBnode 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47node 1 size: 131072 MBnode 1 free: 946 MBnode distances:node 0 10: 10 211: 21 10$> perl numa-maps-summary.pl < proc/175039/numa_mapsN0 : 2118702 ( 8.08 GB)N1 : 8729319 ( 33.30 GB)active : 1327629 ( 5.06 GB)anon : 428874 ( 1.64 GB)dirty : 428875 ( 1.64 GB)kernelpagesize_kB: 8232 ( 0.03 GB)mapmax : 906 ( 0.00 GB)mapped : 10419213 ( 39.75 GB)
4. NUMA 架构下优化策略
资深的 DBA 们,或多或少对 NUMA 架构都有曾经被统治的恐惧,但如果明白了 NUMA 架构下的调优策略,其实可以避免很多不必要的烦恼。在关于 NUMA 和数据库之间的爱恨情仇,网上广泛流传两篇神作,就是 Jeremy Cole 发表的分析 NUMA 架构的作用和影响 (https://blog.jcole.us/2010/09/28/mysql-swap-insanity-and-the-numa-architecture/),以及NUMA架构下对MySQL的调优方式 (https://blog.jcole.us/2012/04/16/a-brief-update-on-numa-and-mysql/)。
针对 NUMA 架构的原理和其对 Linux 的影响,Jeremy Cole 建议:
1. 使用 numactl --interleave=all CMD 启动数据库服务,以实现数据库进程无视 NUMA 关于 CPU 内存分配的策略,可以使得各个 CPU 区域的内存均匀分配;
2. 在启动数据库进程前,采用清空操作系统的环境方式,以释放更多的内存资源;
在 SequoiaDB 信息中心中,对 NUMA 架构的建议,更加简单、直接,“关闭 NUMA 设置”。
以 Linux Centos 7.6环境为例,如果服务器拥有 CPU 48 cores,总内存大小为256GB,并且关闭了 NUMA 设置,假设 SequoiaDB 的数据节点 PID=243123,通过检查数据节点的内存分配,可以发现服务器的内存资源以一个大内存池形式进行管理和分配。
$> numactl --hardwareavailable: 1 nodes (0)node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47node 0 size: 262044 MBnode 0 free: 3094 MBnode distances:node 00: 10$> perl numa-maps-summary.pl < proc/243123/numa_mapsN0 : 3238724 ( 12.35 GB)active : 381544 ( 1.46 GB)anon : 89479 ( 0.34 GB)dirty : 89479 ( 0.34 GB)kernelpagesize_kB: 1348 ( 0.01 GB)mapmax : 1056 ( 0.00 GB)mapped : 3149310 ( 12.01 GB)
1. 检查NUMA设置
$> numactl --hardwareavailable: 1 nodes (0)node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47node 0 size: 262044 MBnode 0 free: 3094 MBnode distances:node 00: 10
如果 available = 1 nodes,则证明无需做其他 NUMA 的设置。
如果出现 available > 1 nodes,则证明存在多个内存区域,需要主动关闭 NUMA 设置。
$> numactl --hardwareavailable: 2 nodes (0-1)node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46node 0 size: 130976 MBnode 0 free: 1415 MBnode 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47node 1 size: 131072 MBnode 1 free: 946 MBnode distances:node 0 10: 10 211: 21 10
2. 关闭NUMA
以 Linux Centos 7.6 系统为例,使用 root 用户对 etc/default/grub 文件进行编辑,在 GRUB_CMDLINE_LINUX 参数的末尾增加 :numa=off,例如:
GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=vg_root/root rd.lvm.lv=vg_root/swap rhgb quiet numa=off"
如果系统中存在/etc/grub2.cfg 文件(MBR 分区表),则执行
grub2-mkconfig -o etc/grub2.cfg
如果系统中存在/etc/grub2-efi.cfg 文件(EFI + GPT分区表),则执行
grub2-mkconfig -o etc/grub2-efi.cfg
然后重启服务器,再检查系统的启动日志,可以发现系统已经主动关闭了NUMA的设置。
$> grep -i numa var/log/dmesg…[ 0.000000] Command line: BOOT_IMAGE=/vmlinuz-3.10.0-693.21.1.el7.x86_64 root=/dev/mapper/vg_root-root ro crashkernel=auto rd.lvm.lv=vg_root/root rd.lvm.lv=vg_root/swap rhgb quiet numa=off[ 0.000000] NUMA turned off[ 0.000000] Kernel command line: BOOT_IMAGE=/vmlinuz-3.10.0-693.21.1.el7.x86_64 root=/dev/mapper/vg_root-root ro crashkernel=auto rd.lvm.lv=vg_root/root rd.lvm.lv=vg_root/swap rhgb quiet numa=off…
附录
$ cat numa-maps-summary.pl#!/usr/bin/perl# Copyright (c) 2010, Jeremy Cole <jeremy@jcole.us># This program is free software; you can redistribute it and/or modify it# under the terms of either: the GNU General Public License as published# by the Free Software Foundation; or the Artistic License.## See http://dev.perl.org/licenses/ for more information.## This script expects a numa_maps file as input. It is normally run in# the following way:## # perl numa-maps-summary.pl < proc/pid/numa_maps## Additionally, it can be used (of course) with saved numa_maps, and it# will also accept numa_maps output with ">" prefixes from an email quote.# It doesn't care what's in the output, it merely summarizes whatever it# finds.## The output should look something like the following:## N0 : 7983584 ( 30.45 GB)# N1 : 5440464 ( 20.75 GB)# active : 13406601 ( 51.14 GB)# anon : 13422697 ( 51.20 GB)# dirty : 13407242 ( 51.14 GB)# mapmax : 977 ( 0.00 GB)# mapped : 1377 ( 0.01 GB)# swapcache : 3619780 ( 13.81 GB)#use Data::Dumper;sub parse_numa_maps_line($$){my ($line, $map) = @_;if($line =~ /^[> ]*([0-9a-fA-F]+) (\S+)(.*)/){my ($address, $policy, $flags) = ($1, $2, $3);$map->{$address}->{'policy'} = $policy;$flags =~ s/^\s+//g;$flags =~ s/\s+$//g;foreach my $flag (split / , $flags){my ($key, $value) = split /=/, $flag;$map->{$address}->{'flags'}->{$key} = $value;}}}sub parse_numa_maps(){my ($fd) = @_;my $map = {};while(my $line = <$fd>){&parse_numa_maps_line($line, $map);}return $map;}my $map = &parse_numa_maps(\*STDIN);my $sums = {};foreach my $address (keys %{$map}){if(exists($map->{$address}->{'flags'})){my $flags = $map->{$address}->{'flags'};foreach my $flag (keys %{$flags}){next if $flag eq 'file';$sums->{$flag} += $flags->{$flag} if defined $flags->{$flag};}}}foreach my $key (sort keys %{$sums}){printf "%-10s: %12i (%6.2f GB)\n", $key, $sums->{$key}, $sums->{$key}/262144;}
 往期技术干货
往期技术干货巨杉Tech | SequoiaDB高可用原理详解
巨杉Tech | 分布式数据库负载管理WLM实践
巨杉Tech | 巨杉数据库的HTAP场景实践
巨杉Tech | SequoiaDB SQL实例高可用负载均衡实践
巨杉Tech | 并发性与锁机制解析与实践
巨杉Tech | 几分钟实现巨杉数据库容器化部署
巨杉Tech | “删库跑路”又出现,如何防范数据安全风险?
巨杉Tech | 分布式数据库千亿级超大表优化实践
社区分享 | SequoiaDB + JanusGraph 实践
巨杉Tech | 巨杉数据库的并发 malloc 实现



