




我们很高兴地宣布发布RediSearch 2.0 开发的第一个里程碑。RediSearch是一种快速的实时搜索引擎,可让您查询Redis数据以回答各种各样的复杂问题。
这个里程碑称为2.0-M01,它标志着索引与数据保持同步的方式的重新架构。无需通过索引写入数据(使用FT.ADD命令),RediSearch现在将跟踪以散列形式编写的数据并自动将其编入索引。
这里的最大优点是,您现在可以将RediSearch添加到现有的Redis实例中并创建二级索引,而不必更新应用程序代码。这样,您只需加载RediSearch模块并定义架构,即可立即开始对现有数据使用RediSearch。RediSearch 2.0有望在今年秋天全面上市。
(注意:此新功能对API(以下列出)进行了一些更改。我们尽力保持向后兼容性,但在这种情况下,这是不可能的。我们计划在以后进行调整和修复。收集客户反馈。)
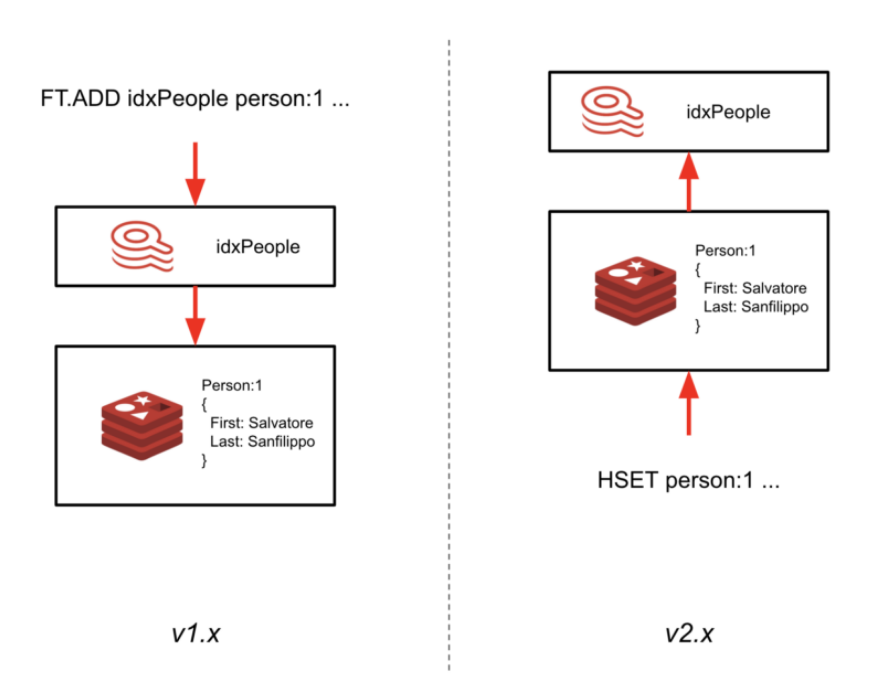
RediSearch 2.0里程碑的体系结构
API变更
如上所述,此RediSearch 2.0里程碑包括对API的一些更改:
索引不再存在于关键空间中。 例如,如果您使用索引键(idx:<索引名称>)列出数据库中的索引,则它将不再起作用。但是,我们引入了一个命令FT._LIST返回数据库中的所有索引。
必须使用前缀/过滤器创建索引。它们指定RediSearch将自动为哪些文档建立索引。您可以指定一个简单的前缀和/或一个复杂的过滤器表达式。
无法升级。如果您使用较旧版本的RediSearch创建了RDB,则RediSearch 2.0将无法读取它。当前,您将必须重新索引整个数据集。但是,我们正在为GA版本进行升级。
它仅适用于Redis 6及更高版本。
FT命令映射到它们的Redis等效命令。这 使现有应用程序仍可以与RediSearch 2.0一起使用。映射如下:
1. FT.ADD => HSET 2. FT.DEL => DEL (DD by default) 3. FT.GET => HGETALL 4. FT.MGET => HGETALL复制
倒排索引本身不再保存到RDB中。这并不意味着不支持持久性。RediSearch确实将索引定义保存到RDB,并在Redis启动后在后台对数据进行索引。您可以使用以下方法检查索引编制状态,以了解重新编制索引的时间:FT.INFO 命令。
新的API
API的最大更新是如何创建索引。在RediSearch 2.0中,命令FT创建用于创建索引。API的新增功能在此处以黄色突出显示:
FT.CREATE {index} ON {structure} [PREFIX {count} {prefix} [{prefix} ..] [FILTER {filter}] [LANGUAGE_FIELD {lang_field}] [LANGUAGE {lang}] [SCORE_FIELD {score_field}] [SCORE {score}] [PAYLOAD_FIELD {payload_field}] [TEMPORARY {seconds}] [MAXTEXTFIELDS] [NOOFFSETS] [NOHL] [NOFIELDS] [NOFREQS] [STOPWORDS {num} {stopword} ...] SCHEMA {field} [TEXT [NOSTEM] [WEIGHT {weight}] [PHONETIC {matcher}] | NUMERIC | GEO | TAG [SEPARATOR {sep}] ] [SORTABLE][NOINDEX] ...复制
让我们深入研究一些细节:
ON {structure}目前仅支持HASHPREFIX {count} {prefix}告诉索引应该索引哪些键。您可以为索引添加多个前缀。由于参数是可选的,因此默认值为* (所有键)FILTER {filter}是具有完整RediSearch 聚合表达式语言的过滤器表达式。可以使用@__key来访问刚刚添加/更改的密钥LANGUAGE和SCORE使您可以覆盖默认语言并为所有建立索引的文档评分LANGUAGE_FIELD,SCORE_FIELD,和PAYLOAD_FIELD允许您使用特定于文档的语言和评分,以及将有效负载用作文档中的字段。
其他限制和变化
RediSearch 2.0-M01 里程碑还带来了其他一些更新:
NOSAVE不再受支持。- 更新哈希值意味着将对整个文档建立索引(键空间通知不说明更改了哪些字段)。因此,部分更新将较慢。请注意,我们仍在研究在这些情况下改善性能的选项。
- 字段名称现在区分大小写,因此声明字段“ FOO”并将其索引为“ foo”将不起作用。
FT.ADD命令将被映射到hset如下所示:
FT.ADD idx doc1 1.0 LANGUAGE eng PAYLOAD payload FIELDS f1 v1 f2 v2复制
映射到:
HSET doc1 __score 1.0 __language eng __payload payload f1 v1 f2 v2复制
这意味着,索引上的分数,语言和有效负载字段必须分别称为__score,__language和__payload,以便映射能够按预期工作。
FT.ADDHASH 不再受支持。用HSET。
FT.OPTIMIZE不再受支持,RediSearch 垃圾收集功能负责优化索引。
结论
我们对这些更改感到非常兴奋,因为您现在可以将RediSearch加载到现有的Redis数据库中并为散列中存在的现有数据建立索引,而无需在处理这些文档时更新应用程序逻辑。您可以通过从GitHub获取源代码或使用1:99:1 RedisSarch Docker映像来试用此里程碑版本。
作者:Pieter Cailliau
文章来源:https://redislabs.com/blog/redisearch-2-0-hits-its-first-milestone/
