





作者介绍
贺春旸,凡普金科爱钱进DBA团队负责人,《MySQL管理之道:性能调优、高可用与监控》第一、二版作者,曾任职于中国移动飞信、安卓机锋网。三次荣获dbaplus年度MVP,致力于MariaDB、MongoDB等开源技术的研究,主要负责数据库性能调优、监控和架构设计。
MHA(Master High Availability)是目前中小公司使用的常见MySQL高可用架构,但有些云厂商不支持虚拟VIP,或者VIP不是同网段的,固无法实现基于MHA或Keepalived漂移VIP形式的高可用使用场景。
于是针对这种情况,衍生出Cousul服务发现+MHA这种架构,架构如下图所示:
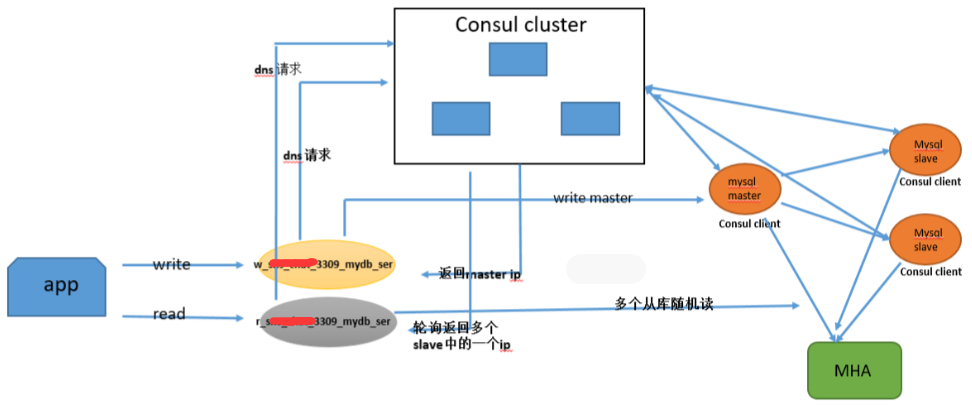
客户端PHP/JAVA应用程序访问Consul服务集群DNS域名,从Consul获取到后端MySQL的master地址,然后将写请求发送到master。MHA负责主从Failover故障转移和Switchover切换,当主从角色变化后,Consul服务能智能识别新的master,在这里Consul相当于一个Proxy代理中间件。另外,你需要额外自定义脚本来结合Consul,判断当前MySQL是主节点还是从节点。
细心的读者应该会发现一个问题,这个方案的成本是不是有些高了?我既得部署MHA,又得部署Consul,且自定义脚本可能缺乏测试和灵活性,显然恢复应该是自动的、经过全面测试的,并且最好包含在现有数据库可伸缩性环境中。
生产环境架构通常是越简单,排查定位问题越容易,能否再简单一些?我改几个配置文件,启动服务就可以完成上述功能呢?
答案是:Of course。
本文笔者讲述的MariaDB官方出品的Maxscale,集成了Consul+MHA的所有功能,不再依赖第三方工具,可以让你快速在Cloud云端上部署一套高可用架构,即使你的公司没有聘请专业MySQL DBA也完全ok。
为了满足此需求,MariaDB MaxScale 2.2版本里,在支持原有读写分离的基础上,又添加了主从复制集群管理功能,在最新版MaxScale 2.5版本里,实现了GUI图形化、可视化监控管理web页面。
(请注意!Failover以及Switchover和Rejoin仅支持基于GTID的复制一起使用,并且仅适用于简单的一主多从拓扑架构:即1个master后面跟着多个slave。)
Mariadbmon守护进程,会实时探测主从复制状态,可以通过执行故障转移,在线切换和重新加入来修改复制群集。
1)Failover:用最新的slave替换发生故障的master,故障转移分为Manual Failover和Automatic Failover。在当前已存在的主从复制环境中,MaxScale可以监控master主机故障,并且故障自动转移。
需要把loss-less无损半同步复制(semi replication)开启,参数rpl_semi_sync_master_wait_point=AFTER_SYNC,确保slave已经接收到了master的binlog,因为master宕机,MaxScale无法远程拷贝scp那一缺失的binlog,那么数据就出现不一致了。
2)Switchover:在线主从切换,类似MHA的masterha_master_switch --master_state=alive。
如果机器需要维护,将master角色在线切换到其他主机上(例如更换原master坏掉的硬盘),这并不是master进程崩溃引起的故障转移。在线切换通常在0.5-2秒左右,并且会阻塞写(在原master上执行SET GLOBAL read_only=1命令设置全局只读,且执行FLUSH TABLES把所有的表强制关闭),建议在凌晨业务低峰期执行在线切换。
3)Rejoin:重新加入到新集群作为slave,即死掉的原master如何与提升为新的master建立同步复制关系?由于Maxscale是基于GTID模式的主从复制,全局事务号是唯一的,会自动执行CHANGE MASTER TO NEW_MASTER, MASTER_USE_GTID = current_pos命令,无需人工参与。
(请确保所有MySQL主从节点参数log_slave_updates=ON开启。)
Maxsclae:127.0.0.1,端口:4006
Master:127.0.0.1,端口:3312
Slave1:127.0.0.1,端口:3314
Slave2:127.0.0.1,端口:3316

1)安装MaxScale
# wget
https://dlm.mariadb.com/1092038/MaxScale/2.5.1/centos/7/x86_64/maxscale-2.5.1.centos.7.tar.gz
# tar zxvf maxscale-2.5.1.centos.7.tar.gz -C usr/local/
# groupadd maxscale
# useradd -g maxscale maxscale
# cd usr/local/
# ln -s maxscale-2.5.1.centos.7 maxscale
# mkdir -p maxscale/var/mysql/plugin
# chown -R maxscale.maxscale maxscale/
2)创建密钥文件
# maxkeys usr/local/maxscale/var/lib/maxscale/
密钥文件.secrets存放在/usr/local/maxscale/var/lib/maxscale/目录下。
3)创建加密密码
# maxpasswd usr/local/maxscale/var/lib/maxscale/ 123456
这里是对密码123456做加密,会生成如下加密字符串:
5CD3AF1688D20ECED2BECEF15C075BC6B02375FE27FFCAC3A12A5FFCBE4FB16C
这些加密后的字符串请保存好,之后要粘贴在maxscale.cnf配置文件里。
4)修改文件描述符65535
# vim etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
# vim etc/sysctl.conf
fs.file-max=65535
net.ipv4.ip_local_port_range = 1025 65000
net.ipv4.tcp_tw_reuse = 1
# 修改完毕后,reboot重启服务器生效
5)创建Maxscale监控账号
CREATE USER 'monitor_user'@'%' IDENTIFIED BY 'my_password';
GRANT REPLICATION CLIENT on *.* to 'monitor_user'@'%';
GRANT SUPER, RELOAD on *.* to 'monitor_user'@'%';
注:如果你用MariaDB 10.5最新版,Replication复制权限命名发生了变化。
① SHOW MASTER STATUS语句更名为SHOW BINLOG STATUS
② REPLICATION CLIENT权限更名为BINLOG MONITOR
③ SHOW BINLOG EVENTS语句需要BINLOG MONITOR权限
④ SHOW SLAVE HOSTS语句需要REPLICATION MASTER ADMIN权限
⑤ SHOW SLAVE STATUS语句需要REPLICATION SLAVE ADMIN和SUPER权限
⑥ SHOW RELAYLOG EVENTS语句需要REPLICATION SLAVE ADMIN权限
MariaDB 10.5版本里,改为:
GRANT REPLICATION SLAVE, REPLICATION SLAVE ADMIN,
REPLICATION MASTER ADMIN, REPLICATION SLAVE ADMIN,
BINLOG MONITOR, SUPER, RELOAD
ON *.* TO 'monitor_user'@'%' IDENTIFIED BY 'my_password';
6)配置MaxScale服务
# cat usr/local/maxscale/etc/maxscale.cnf
[maxscale] #全局模板
threads=auto #根据服务器的CPU核数,自动设置CPU线程数
log_info=1
log_warning=1
log_notice=1
admin_host=0.0.0.0 #打开GUI图形管理页面
admin_secure_gui=false #不设置HTTPS服务
[server1] #主机模板
type=server
address=127.0.0.1
port=3312
protocol=MariaDBBackend
[server2]
type=server
address=127.0.0.1
port=3314
protocol=MariaDBBackend
[server3]
type=server
address=127.0.0.1
port=3316
protocol=MariaDBBackend
[MariaDB-Monitor] #故障转移监控模板
type=monitor
module=mariadbmon #核心监控模块
servers=server1,server2,server3
user=monitor_admin
password=5CD3AF1688D20ECED2BECEF15C075BC6B02375FE27FFCAC3A12A5FFCBE4FB16C
monitor_interval=2000 #每隔2秒探测一次
auto_failover=true #打开自动故障转移
auto_rejoin=true #打开自动重新加入
failcount=3
failover_timeout=90
switchover_timeout=90
verify_master_failure=true
master_failure_timeout=10
[RW_Split_Router] #服务模板
# 基于statement SQL解析的方式
type=service
router=readwritesplit
servers=server1,server2,server3
enable_root_user=1
# 默认禁止root超级权限用户访问,设置为1开启。
user=appuser_rw
# 应用读写分离账号
password=5CD3AF1688D20ECED2BECEF15C075BC6B02375FE27FFCAC3A12A5FFCBE4FB16C
master_accept_reads=true
# 默认读是不被路由到master,设置为true允许master用于读取。
causal_reads=local
causal_reads_timeout=10
max_slave_replication_lag=1
max_slave_connections=2
max_connections=5000
# Maxscale连接到后端MySQL主库的最大连接数,0为不限制
[RW_Split_Listener] #服务监听模板
type=listener
service=RW_Split_Router #服务模板
protocol=MariaDBClient
port=4006
# 读写分离端口,应用连接这个端口,可以自定义端口。
maxscale.cnf配置文件分为全局模板、主机模板、故障转移监控模板、服务模板和服务监听模板,五大部分。
重要参数详解:
① 故障转移监控模板
[MariaDB-Monitor]
auto_failover=true
#打开自动故障转移,false为关闭,需要人工执行命令去做故障转移,通常为true。
auto_rejoin=true
#打开自动重新加入,false为关闭,需要人工执行CHANGE MASTER TO NEW_MASTER, MASTER_USE_GTID = current_pos命令,通常为true。
failcount=3
# 3次连接失败,认定主库down掉,开始启动故障转移,默认是5次尝试。
failover_timeout=90
# 假定slave库有延迟,在默认90秒时间内,没有同步完,自动关闭故障转移。通常默认值即可。
switchover_timeout=90
# 假定slave库有延迟,在默认90秒时间内,没有同步完,自动关闭在线切换。通常默认值即可。
verify_master_failure=true
# 当Maxscale连接不上master时,开启其他slave再次验证master是否故障。这样的好处是:防止网络抖动误切换(脑裂),造成数据不一致,其实现原理为:投票机制,当Maxscale无法连接MySQL主库,会试图从其他slave机器上去连接MySQL主库,只有双方都连接失败,才认定MySQL主库宕机。假如有一方可以连接MySQL主库,都不会切。
类似MHA的masterha_secondary_check命令二次检查,默认开启,无需关闭。
master_failure_timeout=10
# 这个参数依赖于verify_master_failure,当开启后,从库在默认10秒内无法连接master,认定主库down掉。通常默认值即可。
② 服务模板
这里我们要定义一个服务,路由选择读写分离模块。你可以分离一部分select读取操作到slave从库上。它是基于statement的,解析SQL语句。在这里前端程序不需要修改代码,通过MaxScale对SQL语句解析,把读写请求自动路由到后端数据库节点上,从而实现读写分离。开源Percona ProxySQL中间件也是基于statement方式实现读写分离。
[RW_Split_Router]
master_accept_reads=true
# 如果你担心数据有延迟,担心数据准确性问题,可以设置在主库上查询。默认读是不被路由到master,设置为true允许master用于读取。
max_slave_connections=2
# 允许两个slave进行读取
max_slave_replication_lag=1
# 定义超过延迟1秒,把请求转发给master
causal_reads=local
# 由于Maxscale通过参数monitor_interval=2000,每隔2秒探测一次,可能存在主从延迟检测不到的情况。
例如主库上写入了一条数据,从库还没来得写入该记录。那么可以通过设置causal_reads=local,此时客户端在从库上查询会hang住,直至等待causal_reads_timeout=10,默认10秒,超时后请求会强制转发给master。
③ 服务监听模板
我们在上面已经完成了服务定义,那么为了让客户端可以请求访问,我们需再定义一个tcp协议端口。
[RW_Split_Listener]
service=RW_Split_Router
# 这里的RW_Split_Router模块名,要对应服务模块的名字
port=4006
# 读写分离端口,应用连接这个端口,可以自定义端口。
7)启动服务
# usr/local/maxscale/bin/maxscale --user=maxscale
--basedir=/usr/local/maxscale/
--config=/usr/local/maxscale/etc/maxscale.cnf
日志信息会记到到/usr/local/maxscale/var/log/maxscale/maxscale.log
此时所有的slave机器都自动设置为只读模式,可通过select @@read_only查看。
8)查看Maxscale后台管理信息
我们可以通过maxctrl后台管理命令查看主从复制集群状态信息,命令如下:
# maxctrl list servers
查看我们刚才注册的服务,命令如下:
# maxctrl list services

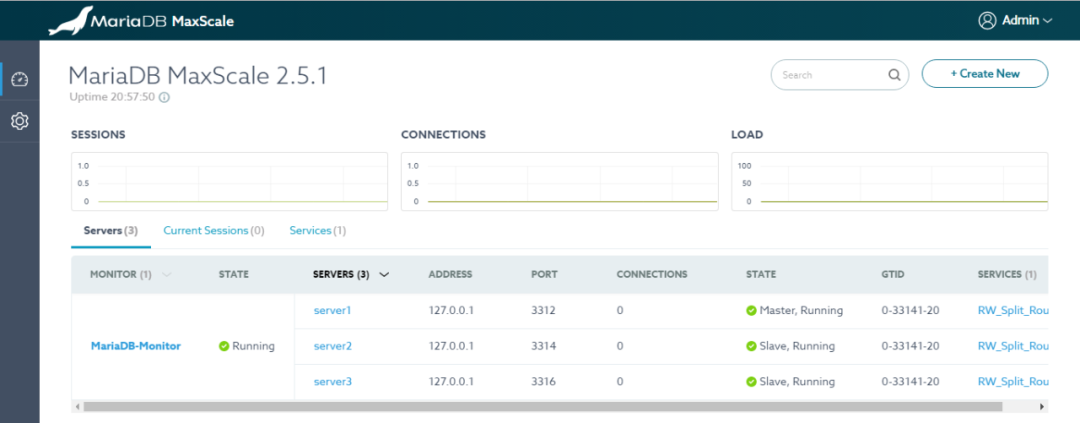
也可以通过GUI WEB图形页面查看,访问http://yourip:8989端口,登录名admin,密码mariadb,如下图所示:
通过mysqladmin shutdown命令关闭主库的mysqld进程。
Failover细节:
1)选择最新的slave作为master,依照以下顺序标准排列:
gtid_IO_pos(中继日志中的最新事件)。
gtid_current_pos(处理最多的事件)。
log_slave_updates已开启。
磁盘空间不低。
如果以上条件都满足,按照maxscale.cnf主机模板的顺序进行故障转移,例如server2挂了,将切换到server3上,依次类推。
2)如果最新的slave具有未处理的中继日志,会根据参数failover_timeout=90等待90秒,超过90秒数据未同步完,则关闭故障转移。通过判断gtid_binlog_pos和gtid_current_pos值是否相等。
3)准备新的master
① 在最新的slave上,关闭复制进程执行命令:
SET STATEMENT max_statement_time=1 FOR STOP SLAVE
并清空同步复制信息执行命令。
SET STATEMENT max_statement_time=1 FOR RESET SLAVE ALL;
② 在最新的slave上,关闭只读read_only 执行命令。
SET STATEMENT max_statement_time=1 FOR SET GLOBAL
read_only=0
③ 在最新的slave上,启用EVENT事件(MySQL定时任务)。
④ 接收客户端读写请求。
4)重定向所有slave指向新的master进行同步复制
① 停止同步复制,执行命令
SET STATEMENT max_statement_time=1 FOR STOP SLAVE
② 指向新的master进行复制,执行命令
SET STATEMENT
max_statement_time=1 FOR CHANGE MASTER '' TO
MASTER_HOST = '127.0.0.1', MASTER_PORT = 3314,
MASTER_USE_GTID = current_pos, MASTER_USER = 'admin',
MASTER_PASSWORD = '123456'
③ 开启同步复制,执行命令
SET STATEMENT max_statement_time=1 FOR START SLAVE
5)检查所有slave复制是否正常,执行命令SHOW ALL SLAVES STATUS判断Slave_IO_Running和Slave_SQL_Running值是否都为双Yes。
通过以下命令可以实现手工故障切换:
# maxctrl call command mariadbmon failover MariaDB-Monitor
这里的切换细节跟自动故障转移是一样的,为了节省篇幅,这里不再介绍。
目前的主是server1,从是server2。
通过以下命令可以实现在线切换:
# maxctrl call command mariadbmon switchover MariaDB-Monitor server2 server1
注:server2代表即将成为新的master,server1代表是原来旧的master。
Switchover细节
准备降级的旧master:
1)在旧的master上,开启只读read_only 执行命令。
SET STATEMENT max_statement_time=1 FOR SET GLOBAL
read_only=1禁止数据写入。
2)终止SUPER权限超级用户的连接,通过以下命令找到超级用户连接Id:
SELECT DISTINCT * FROM (SELECT P.id,P.user FROM
information_schema.PROCESSLIST as P INNER JOIN mysql.user
as U ON (U.user = P.user) WHERE (U.Super_priv = 'Y' AND
P.COMMAND != 'Binlog Dump' AND P.id != (SELECT
CONNECTION_ID()))) as tmp;
然后执行KILL命令,因为read_only只读不影响SUPER权限超级用户更改数据。
3)执行FLUSH TABLES把所有表强制关闭。
4)执行FLUSH LOGS刷新二进制日志,以便所有binlog都刷到磁盘上。
5)在旧master上执行:SELECT @@gtid_current_pos, ,@@gtid_binlog_pos记录gtid事务号。
在新master上执行:SELECT MASTER_GTID_WAIT('GTID');如果执行结果都为0,表示已经完成数据同步,可以进行下一步切换,否则需要一直等待完成。
6)后面的步骤跟故障转移一样。
生产环境中,至少部署两个Maxscale服务,可以和后端MariaDB部署在一起,这样节省了网络IO请求转发带来的额外损耗,另外将Maxscale挂在云服务SLB后面做负载均衡。
注:由于GTID实现方式不同,Maxscale最新版暂不支持MySQL和Percona的故障转移切换,仅支持读写分离功能,这里特别要注意下。
《从自研演进看分布式数据库》中国银联 云计算中心团队主管 周家晶
《开源数据库MySQL在民生银行的应用实践》民生银行 项目经理 徐春阳
《TDSQL在金融行业数据库上云实战》腾讯云 高级经理 陈琢
《如何构建数据库容器化PaaS》爱可生 资深方案架构师 徐阳

