Oracle拥有当前数据库中最为复杂的共享池结构,其目的是确保在高并发下,SQL执行能以十分高效的效率进行。为了CURSOR的共享,Oracle一直在算法上做优化。Oracle 10g的Mutex锁的引入,彻底改变了以前仅仅通过library cache锁来进行串行化的模式,使Oracle在大并发场景下的CURSOR共享更为高效。为了支持同一个CURSOR大规模并发执行的问题,在Oracle 10g以后的版本中,甚至引入了CURSOR多副本的机制。今天老白从Oracle SQL执行的内部过程来探讨一些内部原理性的东西。根据Oracle官方的说法,SQL语句的执行有以下步骤:l[1] Syntactic - 语法检查
l[2] Semantic - 确认所有对象都是存在并且可以访问
l[3] View Merging - 进行查询重写优化
l[4] Statement Transformation –将复杂的查询分解
l[5] Optimization - 确定访问方式,选择优化策略
l[6] QEP Generation - 形成执行计划
l[7] QEP Execution - 执行执行计划
上面的QEP是查询执行计划的英文简称。在上面的这七个步骤中,步骤 [1]-[6] 就是通常我们所说的“分析”(PARSING),第七步就是通常所说的执行(EXECUTION)。正如我们前面几节讨论的,为了不重复解析相同的SQL语句,在第一次解析之后, Oracle将SQL语句存放在库缓存中。因此当你执行一个SQL语句时,如果它和之前的执行过的语句完全相同, Oracle就能很快获得已经被解析的语句以及最好的执行路径。 Oracle的这个功能大大地提高了SQL的执行性能并节省了内存的使用。在MOS文档Note:199273.1中提供了一张图,说明SQL的执行过程,老白把这张图翻译成中文:

我们在10046 Trace里可以很清楚的看到这些SQL执行的步骤。不过实际上的SQL执行并不像上面所述的那么清晰明了和简单。这些步骤之间可能会产生交叉和重叠。部分操作可能提前,部分操作可能滞后。比如说对于使用绑定变量情况下的BIND PEEKING,要实现PEEKING,分析中的优化步骤可能延后到执行阶段进行,因为只有在执行阶段,绑定变量的值才是明确的。 要执行一条SQL,并且尽可能使用共享的CURSOR,Oracle采用如图3-4所示的判断流程(以下流程来自Oracle官方的说明)来共享CURSOR。
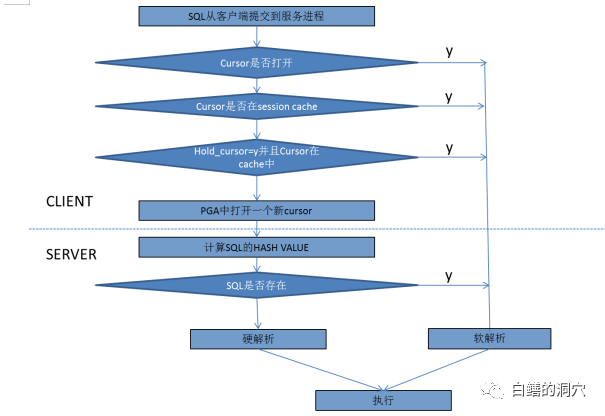
首先客户端判断在自己要执行的CURSOR是否正在打开,如果正在打开,就直接执行,否则判断CURSOR是否在UGA的SESSION CACHE中,如果在CACHE中,可以直接执行。如果在UGA中没有缓冲这个CURSOR,则需要在UGA生成一个客户端的CURSOR结构,然后计算SQL的HASH VALUE,判断CURSOR在共享池中是否存在,如果CURSOR存在,则对CURSOR做软解析,否则就要做硬解析。解析完毕后,对CURSOR进行执行。不同类型的SQL的执行中的步骤也有所不同。比如INSERT语句中就没有FETCH这个步骤,FETCH是SELECT语句的独有步骤。记得前些年有人问老白一个问题,SELECT语句执行的过程中,读数据块,从中找数据是在EXECUTE阶段完成的还是FETCH阶段完成的呢?以老白做应用架构设计的经验来说,有些SQL在FETCH一个CURSOR的时候,有可能不会把打开的CURSOR从头到尾FETCH一遍,就可能因为某种原因结束FETCH,甚至关闭CURSOR。如果SQL执行过程中,在FETCH之前就已经遍历所有的数据块,找出所有的结果数据,那么就会造成浪费。因此,在FETCH阶段才去访问数据才是最好的选择。我们可以通过一个简单的实验来验证这个问题。用PL/SQL编写一个小程序,找一张几十M以上的表来访问,打开CURSOR后,FETCH几条记录。查看这张表被缓冲的数据(当然每次开始测试前都把DB CACHE清空一下),查看相关的表被缓冲的数据的数量。通过这个实验可以看出,随着FETCH的数据量越来越多,DB CACHE中被缓冲的块也越来越多。而刚刚OPEN CURSOR的时候,是不会对所有数据进行遍历的。可以看到,随着FETCH的进行,载入内存的BLOCKS和TCH都在增长。而不FETCH数据的时候,这些数据都是静止不动的。这个例子只能证明数据是随着FETCH的进行而被访问的,那么Oracle 是否存在一些PREFETCH之类的行为呢?答案是肯定的,为了提高FETCH数据的效率,Oracle 提供了PREFETCH功能。通过下面几个参数可以控制Oracle 的PREFETCH的行为:_db_block_prefetch_limit
_db_block_prefetch_quota
_table_lookup_prefetch_size
其中_db_block_prefetch_limit和_db_block_prefetch_quota控制数据块预读的数量,_table_lookup_prefetch_size数据行预读的数量,这个参数的默认值在8.0版本为10,9i以后加大为40。对于大量FETCH数据的操作,我们一般使用BULK COLLECT 的方式来批量FETCH数据,从而提高FETCH的性能。BULK COLLECT配合以合适的_table_lookup_prefetch_size可以提高FETCH的性能。不过由于_table_lookup_prefetch_size这个参数不能会话级调整,因此这个参数的调整要十分慎重,一旦调整的不合理将会影响系统的性能。如果调整的太大,可能会由于过量的PREFETCH而增加不必要的开销。在SQL的执行的过程中,如果这个CURSOR是OPEN的,那么SQL的执行的分析开销最小,不需要做任何解析,就可以直接执行了。这种情况下没有解析产生。如果执行的CURSOR是SESSION CACHE中的,那么虽然在统计上还是统计了一次软解析,但是和一般的软解析不同,这种软解析的开销很小,TOM称之为软软解析(soft soft parse),就是用以区别于普通的软解析。其实解析的过程是十分复杂的,绝对不是hard parse,soft parse,soft soft parse这三种可以概括的。比如说,执行一条SQL的时候,如果该SQL在共享池中不存在,那么很简单,这就是硬解析,需要首先分配共享池空间,创建PARENT CURSOR的结构,然后创建一个CHILD CURSOR。如果下一次再执行一条类似的SQL,发现该SQL的PARENT CURSOR存在,再一检查CHILD CURSOR是可以共享的,而且这个CHILD CURSOR的所有关联对象在共享池中都存在,那么就可以马上执行了,这就是我们所说的SOFT SOFT PARSE,其实这也是SOFT PARSE的一种。还有一种情况是,我们发现CHILD CURSOR是不可共享的,那么我们就需要创建一个新的CHILD CURSOR(对于SQL来说,又增加了一个VERSION),解析执行计划,然后执行,这也被记录为一次SOFT PARSE,不过这个SOFT PARSE比刚才的SOFT SOFT PARSE明显开销要高很多。其实我们还经常碰到另外一种情况,当我们找到某个CHILD CURSOR的时候,发现该CURSOR相关的关联对象的数据不完整,那么我们就必须重新生成这个CHILD CURSOR,才能够执行SQL,这也是一种SOFT PARSE。为什么某个CHILD CURSOR会不完整呢?由于共享池是一种采用那个LRU机制的共享缓冲。当共享池空闲空间不足的时候,就会换出某些对象,从而腾出新的空间来给需要的会话。共享池在释放内存的时候,首先释放那些没有上锁的对象,当所有的没上锁的对象都释放了,空间还是不足的时候,才会释放带有null锁的对象。而被Pin 住的对象是不能释放的。从SQL执行的原理来看,尽可能减少硬解析,甚至减少软解析都可能给系统带来性能的提升。要想减少硬解析和软解析,那么就要让SQL能够尽可能的在共享池中多保存一段时间,并且对于那些执行十分频繁的SQL,尽可能让他们保存在共享池中。保持共享池有足够的空间存放这些对象是十分重要的,因此在共享内存自动管理的情况下,当BUFFER CACHE能够保持足够高的命中率的时候,Oracle总是尽可能的扩展共享池,这样也导致了共享池十分庞大。适当保持足够大的共享池对于OLTP系统来说是十分重要的,只有共享池足够大了,才能够让CURSOR的所有相关数据尽可能多的保存在共享池中不被换出。实际上,一套应用系统需要配置多大的共享池,和应用的总体架构以及应用系统的特点是关系十分大的。对于一些负载十分高,每秒事务处理数量达到1000左右的系统来说,可能5G左右的共享池就足够了,而对于另外一套并发处理量小10倍,每秒事务数不超过20个的系统,可能8G共享池还经常出现严重的争用。因此我们在分配共享池的大小的时候,一定要从实际应用系统出发,绝对不能以简单的规则或者固定的模式来看待这个问题。





