在巡检时发现大量UNDO相关的等待事件,enq: US - contention,latch: undo global data
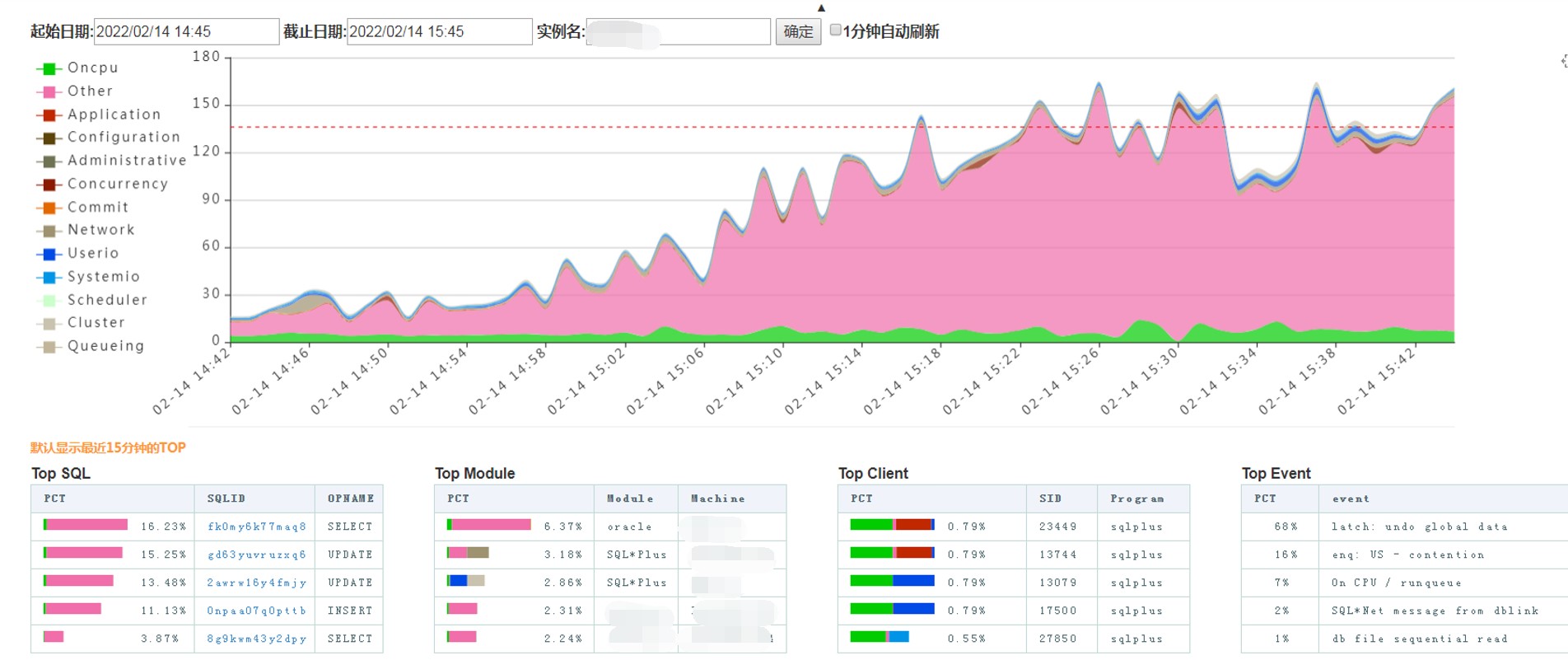
latch: undo global data一般发生在UNDO表空间不足时,应急处理为增加UNDO表空间,或者把UNDO RETENTION调小(如UNEXPIRED EXTENTS较多时有效)。
接下来分析一下产生这个问题的原因,由于查看了当前没有大事务,死事务排除活动事务占用的情况,这时推测为过去某个时间点大量UNDO占用,还未超过UNDO RETENTION,导致UNDO EXTENT不能重用。可以通过v$undostat分析这个情况。
select begin_time,(END_TIME-begin_time)360024 s,undoblks,txncount,MAXCONCURRENCY, EXPSTEALCNT,EXPBLKRELCNT,EXPBLKREUCNT,EXPIREDBLKS from v$undostat where begin_time>sysdate-1 order by begin_time;
可以看到在问题发生前确实有UNDOBLKS分配量,事务量突增的情况,这时可以看一下UNDO RETENTION,根据这个产生速率算一下是不是有大量UNDO BLOCKS还未过期。

接下来查找哪些事务导致的UNDO占用突增。一般可以通过下面两种途径分析
1、ASH查找大事务,按XID分组,如果单个XID活动时间过长,或过滤SQL_OPNAME IN(‘INSERT’,‘DELETE’,‘UPDATE’),按SQL分组,查找是不是有执行量突增的DML。
2、通过分析AWR中的SEG STATS,查询BLOCK CHANGE突增的对象。

通过上面的分析也没找到异常点,接下来就比较难找了,这里运气比较好,通过对比SQL的执行量、执行情况,找到了如下PLSQL匿名块在UNDO BLOCKS产生速率高的时间点执行,执行量也与UNDO BLOCKS的波动一致。以下为伪代码。
declare
cnt number;
begin
for i in 1..100000 loop
select count(*) into cnt from test.tobj@test;<<<<
if cnt>10 then
insert test.t values (cnt);<<<<<后面统计这个INSERT不怎么执行,cnt>10这个条件不成立。
end if;
commit;
end loop;
end;
一个使用DBLINK的查询执行量大,INSERT几平不怎么执行。
这里的问题点
1、每次循环DBLINK查询会生一个事务(DBLINK为分布式事务)。
2、每次循环都会提交。
根据之前看到的UNDOSTATS的统计,UNDO BLOCKS使用量,事务量的增长,推测为循环DBLINK查询,每次产生新的分布式事务分配新ROLLBACK SEGMENT导致UNDO使用突增。以下在虚拟机模拟验证这一猜测。
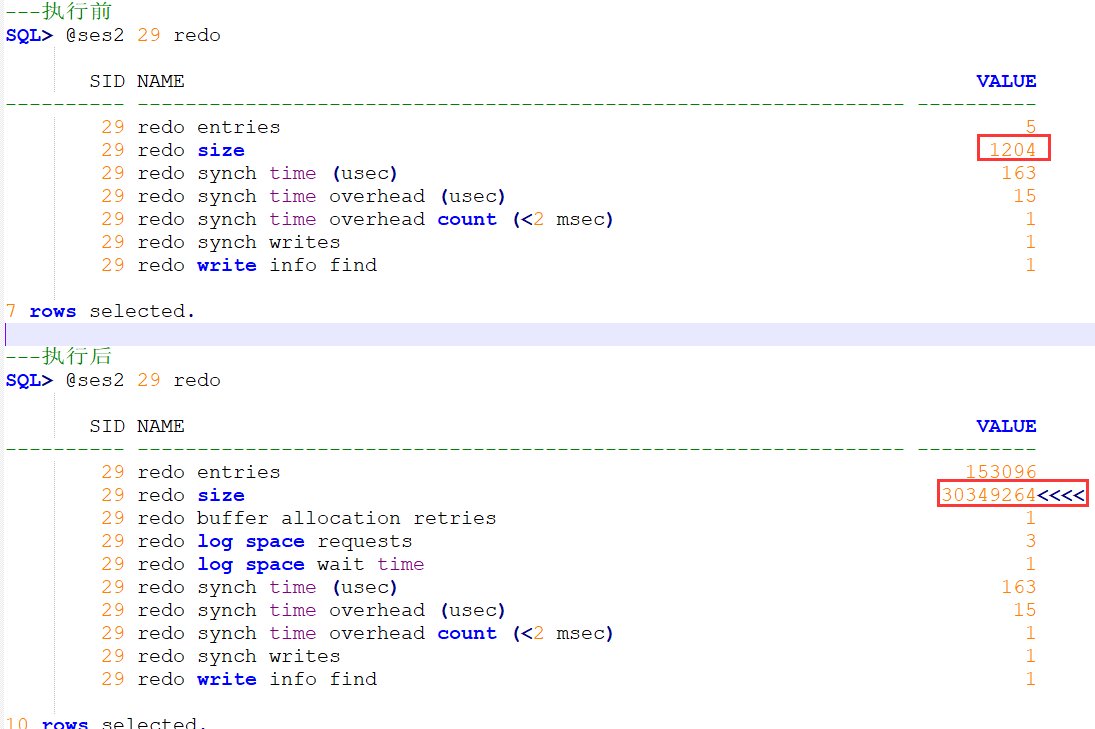
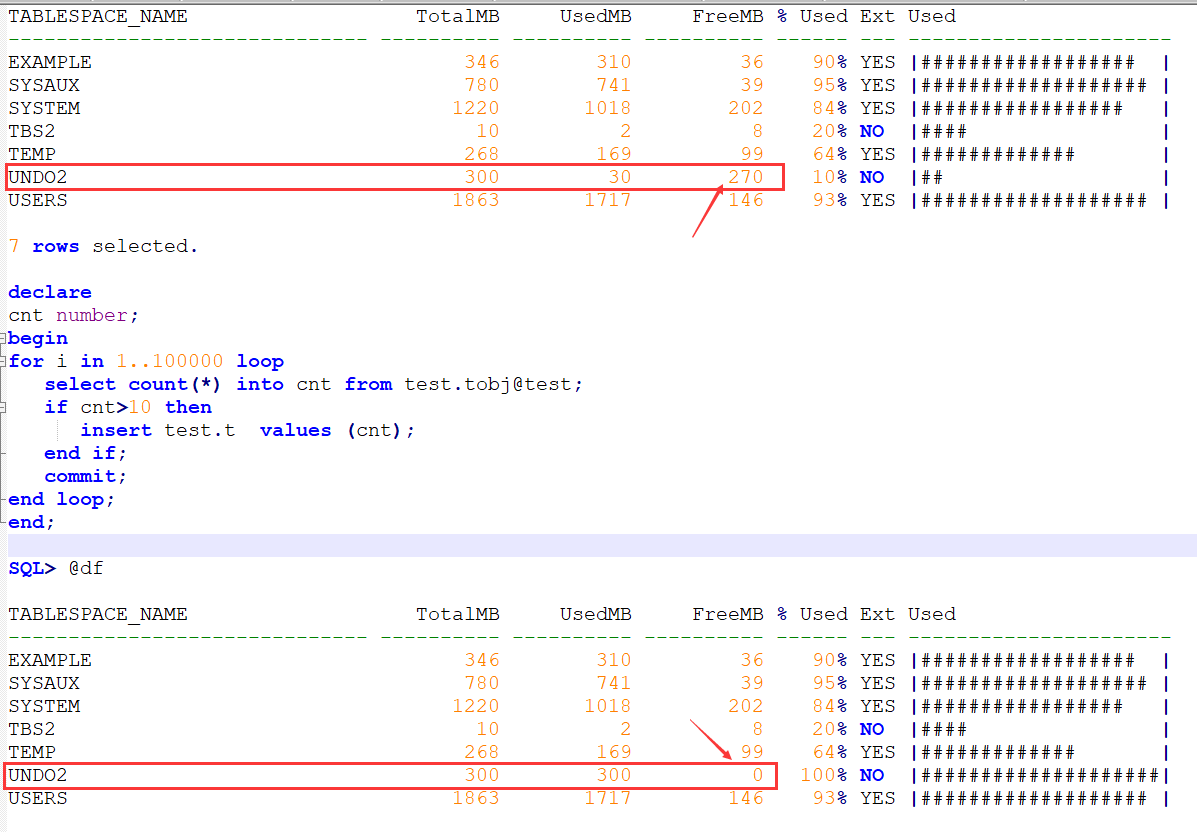
可以看到这个循环执行前UNDO FREE 270M,执行这个PL/SQL块,很快就用完了.(里面的IF判断不会成立,INSERT不会执行)
XIDUSN XIDSLOT XIDSQN 一直在变化,说明频繁产生新事务
USED_UBLK 为1,每个事务使用1个UNDO BLOCK
SQL> @trans
SID SERIAL# USERNAME TADDR SES_ADDR USED_UBLK USED_UREC 0xFLAG STATUS START_DATE XIDUSN XIDSLOT XIDSQN XID PRV_XID PTX_XID
---------- ---------- ------------------------------ ---------------- ---------------- ---------- ---------- --------- ----------------------------- ----------------- ---------- ---------- ---------- ---------------- ---------------- ----------------
29 6967 SYS 0000000081B40EC8 0000000084693E40 1 1 421603 ACTIVE 20220211 22:55:55 273 7 682 11010700AA020000 0000000000000000 0000000000000000
中间可以观察到这个session一直在分配新的rollback segment,每次使用一个UNDO BLOCK
SQL> @trans
SID SERIAL# USERNAME TADDR SES_ADDR USED_UBLK USED_UREC 0xFLAG STATUS START_DATE XIDUSN XIDSLOT XIDSQN XID PRV_XID PTX_XID
---------- ---------- ------------------------------ ---------------- ---------------- ---------- ---------- --------- ----------------------------- ----------------- ---------- ---------- ---------- ---------------- ---------------- ----------------
29 6967 SYS 0000000081B06B68 0000000084693E40 1 1 421603 ACTIVE 20220211 22:56:04 273 6 758 11010600F6020000 0000000000000000 0000000000000000
SQL> @trans
no rows selected
SQL> @trans
SID SERIAL# USERNAME TADDR SES_ADDR USED_UBLK USED_UREC 0xFLAG STATUS START_DATE XIDUSN XIDSLOT XIDSQN XID PRV_XID PTX_XID
---------- ---------- ------------------------------ ---------------- ---------------- ---------- ---------- --------- ----------------------------- ----------------- ---------- ---------- ---------- ---------------- ---------------- ----------------
29 6967 SYS 0000000081B9AC18 0000000084693E40 1 1 421603 ACTIVE 20220211 22:56:09 275 27 760 13011B00F8020000 0000000000000000 0000000000000000
还可以看到这个DBLINK查询导致了REDO的增长。这也是除了延迟块清除之外的另一个查询产生REDO的例子。