




Kafka作为一个消息中间件(后面Kafka逐渐转向一个流失处理平台KafkaStream),消息最终的存储都落在日志中。
Kafka的消息最终发送是以topic下的分区为最终目标的,因此Kafka的日志存储也是以分区为单位。
配置文件中log.dir参数决定了kafka数据文件的存放目录,该参数可以在kafka配置文件中进行配置。

上图给出了三个目录,代表Topic名称为message-store的三个分区,三个目录下面分别存储了三个分区的数据文件,从目录可以看出,分区目录的创建规则是TopicName-分区编号。下面我们挑选0分区,看一下下面存储了哪些文件。
LogSegement(日志段)
Kafka中写入日志的方式是以顺序追加的方式写入的,当日志文件达到一定大小就会做切分,形成一个新的日志文件,这里可以把一个一个的日志文件作为一个日志段。日志段的引入方便了Kafka数据的查询(二分查找)与定位。
日志段分为活跃日志段和非活跃日志段,只有活跃日志段(当前日志段,一个分区只可能存在一个)可以被写入和读取,非活跃日志段只能被读取。
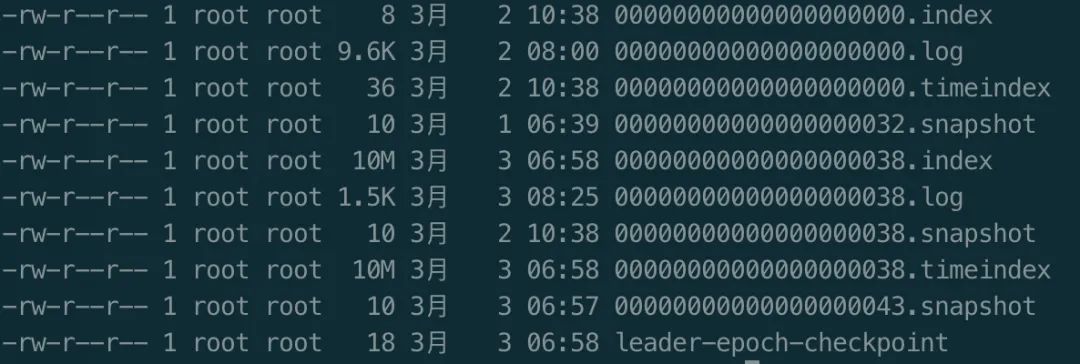
日志文件有很多后缀,如上图所述有.index、.log、.snapshot、.timeindex
| 类别 | 作用 |
|---|---|
| .index | 偏移量索引文件 |
| .log | 日志文件 |
| .snapshot | 日志快照 |
| .timeindex | 时间戳索引文件 |
| leader-epoch-checkpoint | 用于副本同步的检查点文件 |
每个文件的命名是有固定的格式的,文件名长度20位,以该日志中的第一条消息的offset值命名,不够的补0,因此00000000000000000038.log中第一条消息的偏移量为38。
# 该命令可以查看Kafka的日志文件,结果如下图
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000038.log --print-data-log
 从日志文件中我们可以看出,我们可以看出消息集合的起始位移、结束位移、时间戳以及具体的消息的位移、时间戳、header还有内容(payload)等信息。
从日志文件中我们可以看出,我们可以看出消息集合的起始位移、结束位移、时间戳以及具体的消息的位移、时间戳、header还有内容(payload)等信息。
# 该命令可以查看Kafka的offset索引文件
bin/kafka-dump-log.sh --files 00000000000000000000.index
bin/kafka-dump-log.sh --files 00000000000000000038.index
# 该命令可以查看Kafka的时间戳索引文件
bin/kafka-dump-log.sh --files 00000000000000000000.timeindex


日志和索引文件
| 配置项 | 默认值 | 说明 |
|---|---|---|
| log.index.interval.bytes | 4096 (4K) | 增加索引项字节间隔密度,会影响索引文件中的区间密度和查询效率 |
| log.segment.bytes | 1073741824 (1G) | 日志文件最大值 |
| log.roll.ms | 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值允许的最大范围,毫秒维度 | |
| log.roll.hours | 168 (7天) | 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值允许的最大范围,小时维度 |
| log.index.size.max.bytes | 10485760 (10MB) | 触发偏移量索引文件或时间戳索引文件分段字节限额 |
日志分段
日志段有当前日志段和过往日志段。Kafka在进行日志分段时,会开辟一个新的文件。触发日志分段主要有以下条件:
当前日志段日志文件大小超过了log.segment.bytes配置的大小
当前日志段中消息的最大时间戳与系统的时间戳差值超过了log.roll.ms配置的毫秒值
当前日志段中消息的最大时间戳与当前系统的时间戳差值超过log.roll.hours配置的小时值,优先级比log.roll.ms低
当前日志段中索引文件与时间戳索引文件超过了log.index.size.max.bytes配置的大小
追加的消息的偏移量与当前日志段中的之间的偏移量差值大于Interger.MAX_VALUE,意思就是因为要追加的消息偏移量不能转换为相对偏移量。原因在于在偏移量索引文件中,消息基于baseoffset的偏移量使用4个字节来表示。
索引文件在做分段的时候首先会固定好索引文件的大小(log.index.size.max.bytes),在新的分段的时候对前一个分段的索引文件进行裁剪,文件的大小才代表实际的数据大小。
消息查找
offset查找(.index)
偏移量索引文件由4字节的相对位移(offset)和4字节的物理地址(postion)组成。
Kafka内部维护了一个ConcurrentSkipListMap来保存在每个日志分段,通过跳跃表方式,定位到具体的日志偏移量索引文件,然后在此文件中,根据二分法来查找不大于需要查找的offset对应的postion,然后在日志文件中从postion处往后遍历,找到offset等于要查找的offset对应的消息。
时间戳查找(.timeindex)
时间戳索引文件是由8字节的时间戳和4字节的相对偏移量组成。时间戳查找的时候首先拿要查找的时间戳和每个时间戳索引文件的最后一条记录进行比较,如果最后一条记录的时间戳小于等于0,就和文件修改时间比较,找到不小于查找时间戳的时间索引文件。找到对应的日志段时间戳索引文件以后,二分法查找不大于查找时间戳的offset,再根据此offset进行偏移量文件查找。
偏移量索引文件offset是递增的,但在时间戳索引文件时间戳不是递增的,除非broker段将log.message.timestamp.type参数设置为LogAppendTime,时间戳可以保持单调增长。因为在新版的Kafka Producer中允许客户端设置时间戳,如果log.message.timestamp.type参数的设置为CreateTime,就会造成实际戳索引文件中的乱序。
日志清理
关于日志清理,将会在下一节中讲述。
