




“ 全方位解读 Kafka 架构及基本原理、高吞吐、高性能核心技术及最佳应用场景......建议收藏备读!”

魏小言,公众号:code杂坛全方位解读 Kafka 架构及基本原理、应用场景...
前篇文章,我们已经了解 kafka 基本架构及各组件统筹策略。接下来介绍 kafka 高吞吐量、高性能的核心技术及最佳应用场景。
01
—
消费组派发策略缺陷
在 range 策略中,单 topic 状态是 ok 的,多 topic 主题下会导致数据倾斜! 在 轮询 策略中,多 topic 分区规模一致状态是 ok 的,多 topic 主题下分区数量的差异会导致数据倾斜!
 :为什么会这样呢?
:为什么会这样呢?单 topic 主题下,range 、轮询 策略状态如下:
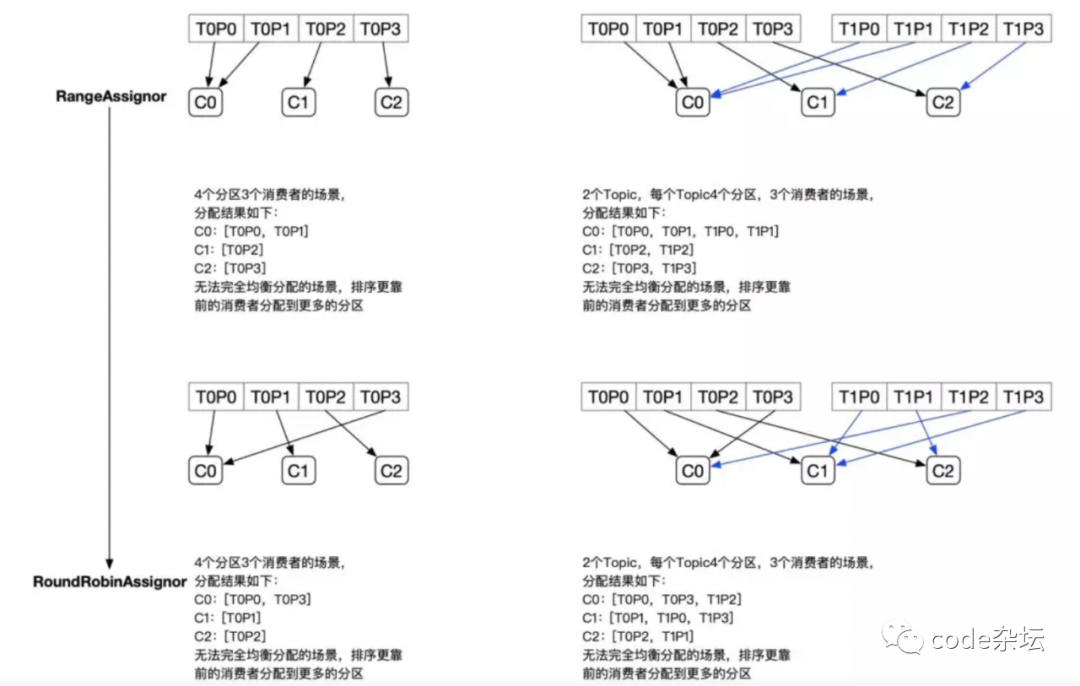
多 topic 主题下分区数量的差异状态下,轮询策略状态如下:
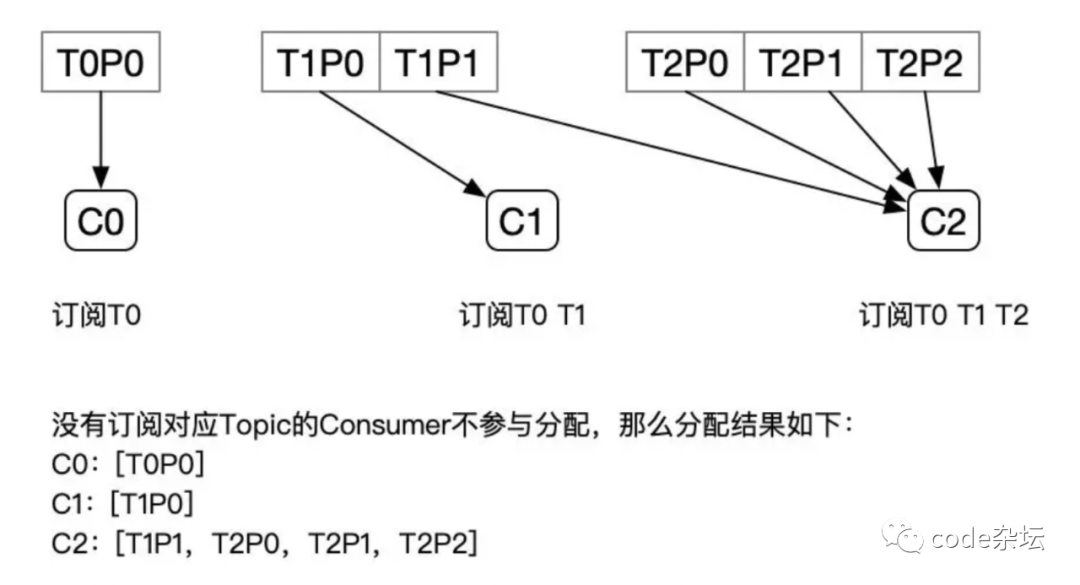
02
—
消费者推拉模式
:kafka 消费处理模式为什么就选择 pull 模式呢?“我们来对比一下两种模式的优劣,看哪一种模式最终会胜出!“
push 模式
优点:
缺点:
pull 模式
- 由于消息存在处理延迟问题,所以 pull 模式支持数据的聚合和批量拉取的特征;
03
—
kafka 中的协调者
在 kafak 架构/组成中,存在 zookeeper 组件作为协调者。
:zookeeper 在 kafka 中发挥了什么作用呢?kafka 主要利用 zookeeper 的共识算法,保证数据的一致性特点。
拆开来讲,
提案KIP-500
KIP-500 是 kafka 社区正在逐步实现的一个提案,主旨是接触对 zookeeper 的依赖。
:kafka 为什么要解除对 zookeeper 的依赖呢?
总体概括有这么几点,
KIP-500 用 Quorum Controller 代替之前的 Controller,Quorum 中每个 Controller 节点都会保存所有元数据,通过 KRaft 协议保证副本的一致性。
这样即使 Quorum Controller 节点出故障了,新的 Controller 迁移也会非常快。
consumer offset 迁移
随着 KIP-500 提案的提出,一些实际策略也逐渐落地。比如,新版本中已经将 消费者提交的 offset 及 消费组信息 由原来的 zookeeper 替换至了 kafka 的 consumer_offset 主题存储….
在云原生的背景下,使用 Zookeeper 给 Kafka 的运维和集群性能造成了很大的压力。去除 Zookeeper 的必然趋势!
04
—
kafka 高吞吐、高性能核心技术
几十、上百万的吞吐量及毫秒级的数据处理等特性是收市场青睐的主要因素之一。
:kafka 高吞吐、高性能核心依赖技术设计都有哪些呢?
顺序读写
在 product 写入数据时,分区的 segment 文件中是以追加的形式进行,并且会给每个消息分配唯一的 offset 标识;在 consumer 读数据时,以 offset 作为偏移量,顺序读出数据。
“ 现在感觉顺序读写好像理应就应该这样设计,下面给出一组数据对比一下,就知道这种设计是多么的优越!“
当磁盘顺序读或写的速度可达 400M/s,而随机读写的速度只有 几十到几百 K/s,两者差距极大!顺序读写可最大程度的利用磁盘的存储特性进行提速!
零拷贝
介绍零拷贝之前,先介绍两种 Linux 技术,分别是 sendfile、mmap。
sendfile :可直接将数据从网卡读至内存[内核空间],反之亦然;交互过程省略应用缓存区[用户空间]的数据暂存。
mmap:建立磁盘文件与内存的映射关系,内存变更将反射至磁盘[数据内存会暂存,实际落地由系统 flash 时机决定];实现修改内存即变更磁盘。
通过两种技术的结合,可实现 kafka 消息数据读写磁盘的零拷贝,吞吐量较使用传统技术提升 3 倍以上!
在 product 写入数据时,broker 直接从 socket 缓冲区读出数据利用 sendfile 技术写入内存,而利用 mmap 技术可完成内存与磁盘的状态映射,此刻就已经完成了数据的写入;反之,当 consumer 读数据时,直接把 磁盘数据 读至 网卡[socket]即可。
在传统的技术中,磁盘数据的读写,至少需要经历四个过程…...
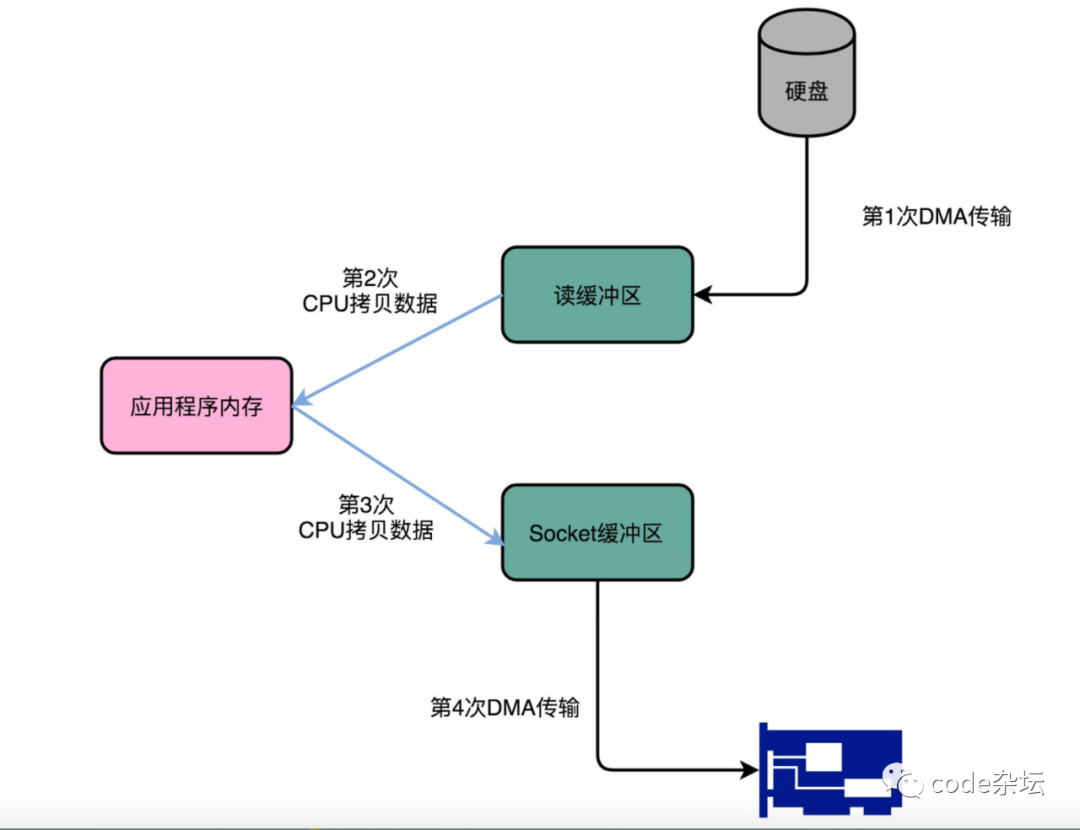
在 读数据 的时候,先把数据从 磁盘 写入 内核缓冲区;再从 内核缓冲区 写入 应用程序缓冲区;再由 应用程序缓冲区 写入 socket 缓冲区;最后由 socket 缓冲区 写入 网卡缓冲区……反之写数据亦然。
这个时候,你可以回过头看看这个过程。我们只是要“搬运”⼀份数据,结果却整整搬运了四次。而且过程中,其实都是把同一份数据在内存里面搬运来搬运去,特别没有效率!
05
—
kafka 流式处理中扮演的角色
kafka 在流式处理中扮演着重要的角色,以 监控系统设计为例。
filebeat + kafka + Elasticsearch + Logstash + Kibana
随着 trace 技术的不断发展、业务数据规模的膨胀,传统的监控框架 ELK [Elasticsearch + Logstash + Kibana] 不足日渐显露。
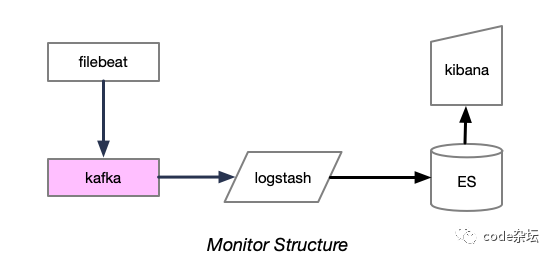
通过 Filebeat 部署进行日志收集,促使模块解耦,组件部署更加简单且轻量的同时,数据收集更加实时、准确;
通过引入 kakfa 组件实现数据的冗余备份的同时,也支撑了整个框架的横向扩展;更是对数据进行了消峰填谷,提升服务可用性。
filebeat 、 kafka 组件其出色的设计和特性,对传统监控框架的等各方面性能提升具有极大的意义!
欢迎关注,不会迷路!
#架构|高可用|高性能|高容错|ISR|Zookeeper|优秀设计|宕机|面试|顺序|同步|异步#
