




在执行计划的操作中,全表扫描(Full Table Scan)和快速完全索引扫描(Fast Full Index Scan) 是属于读数据块读操作。我们以全部扫描为例,分别分析在 IO 代价模型和 CPU 代价模型中,其代价估算过程。
6.5.1 代价模型
IO 代价模型
在 IO 代价模型中,不考虑 CPU 代价,因而计算公式中没有 CPU 部分。此外,由于全部扫描中仅有多数据块读,不存在单数据块读(即#SRDS=0),因此其代价估算公式为:
COST = MRDCOST = #MRDS
也就是说,IO 代价模型中,仅估算多数据块读的次数。而多数据块读的次数由两个因素决定: 表的(高水位线下的)数据块数(#BLKS)和每次读取数据块的数量(Multiple Blocks Read Count,
MBRC)。
#MRDS = #BLKS/MBRC
提示:IO 代价模型中,MBRC 不受系统统计数据 MBRC 的影响。
其中,表的数据块数属于对象的统计数据,可以有数据字典获得。而对于多数据块读的读取块 数,则是由参数"db_file_multiblock_read_count"和"_db_file_optimizer_read_count"决定的。其中,
“db_file_multiblock_read_count"决定了优化器进行代价估算时和语句实际执行过程中采用多数据块读的最大数据块数量;而”_db_file_optimizer_read_count"则是优化器做代价估算时的参考参数。而 参数"_db_file_optimizer_read_count"是受到"db_file_multiblock_read_count"影响的,一旦
“db_file_multiblock_read_count"发生变化,则”_db_file_optimizer_read_count"也会被设置为相同值。而在语句的实际执行过程中,还会有一个参数"_db_file_exec_read_count"决定多数据块读的实
际读取数据块数量,而这个参数也是受到参数"db_file_multiblock_read_count"影响的,但它的修改 则不会影响"db_file_multiblock_read_count",也就是说:
• 参数"db_file_multiblock_read_count"的修改会导致参数"_db_file_exec_read_count"和
“_db_file_optimizer_read_count"这两个参数做相同修改;
• 参数”_db_file_exec_read_count"和"_db_file_optimizer_read_count"的修改不会导致
"db_file_multiblock_read_count"发生变化;
而在 IO 代价模型中,由于没有参考时间因素,不能直接对多数据块读和单数据块读做等价转换,因此,oracle 会对上述计算得到的多数据块次数乘以一个系数(ADJF)做调整,这个系数可以按照以下方式计算:
o 当对象的数据块大小(Block Size)和系统的数据块大小设置(db_block_size,默认为 8192) 相同时:
ADJF = 0.5965*POWER(1.26733682,LOG(2,MBRC))
o 当对象的数据块大小(Block Size)和系统的数据块大小设置(db_block_size,默认为 8192) 相同时:
ADJF = 0.5965POWER(1.26733682,LOG(2,OPTBLKSIZ/RELBLKSIZMBRC))/(OPTBLKSIZ/RELBLKSIZ)
其中,OPTBLKSIZ 为优化器采用的数据块大小设置(_optimizer_block_size,默认为 8192),
RELBLKSIZ 为对象的实际数据块大小,即其所在表空间的数据块大小设置。计算公式进一步写为:
#MRDS = #BLKS/MBRC*ADJF
此外,优化器还会参照一个参数"_table_scan_cost_plus_one"对计算进行微调,其含义是在对全 部扫描代价估算结果上再加一,默认值为 TRUE。同时考虑参数"_optimizer_ceil_cost"的默认设置,
IO 代价模型中全部扫描代价估算公式被写为:
COST = CEIL(#BLKS/MBRC*ADJF)+1
至此,我们可以获取到 IO 优化模型下全部扫描代价估算公式中的元数据,用以下语句来估算全部扫描在 IO 优化模式下的代价:
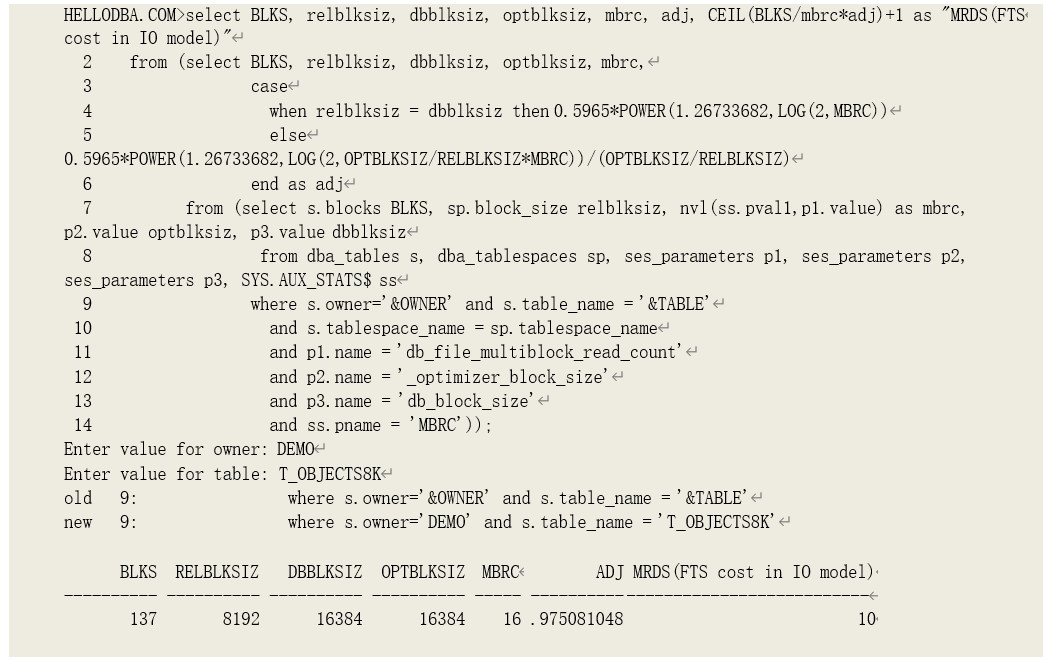
提示:上述语句是在一个 DB_BLOCK_SIZE 为 16K 的 10.2.0.4 的数据库环境中运行的,其中表
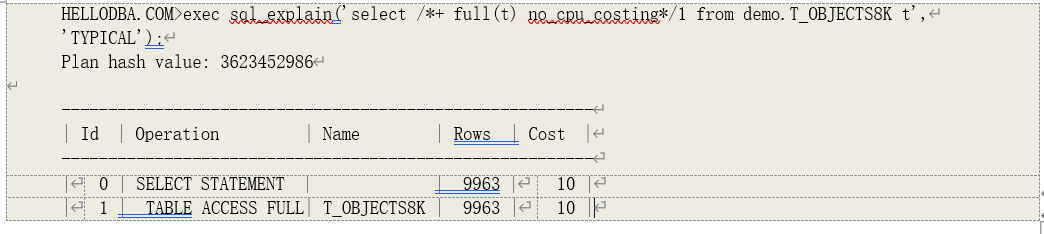
T_OBJECTS8K 创建在一个数据块大小为 8K 的表空间上。这个结果和实际结果一致:

CPU 代价模型
在 CPU 代价模型中,需要考虑 CPU 代价,因此其基本代价由两个部分组成:IO 代价和 CPU 代价:
COST = IOCOST + CPUCOST
6.5.2 IO 代价计算
在 CPU 代价模型中,全部扫描同样也不会存在单数据块读的代价,但是多数据块读的代价需要由单次多数据块读时间(MREADTIM)与单次单数据块读时间(SREADTIM)之间的关系进行转换。
IOCOST = MRDCOST = #MRDS*MREADTIM/SREADTIM
而多数据块读次数由表的数据块数和多数据块读的读取块数(MBRC)决定,即#MRDS =
#BLKS/MBRC,因此代价公式可以转换为:
IOCOST = (#BLKS/MBRC)*MREADTIM/SREADTIM
其中,MREADTIM 和 SREADTIM 受到系统统计数据的影响:
o 如果系统在 WORKLOAD 模式下收集到了统计数据,MREADTIM 和 SREADTIM 则为统计数据中的数值;
o 如果系统在 NOWORKLOAD 模式下收集到了统计数据,MREADTIM 和 SREADTIM 则由下列公式计算得出:
SREADTIM = IOSEEKTIM + OPTBLKSIZ/IOTFRSPEED MREADTIM = IOSEEKTIM + MBRC * OPTBLKSIZ/IOTFRSPEED
其中,IOSEEKTIM 和 IOTFRSPEED 为统计数据,WORKLOAD 和 NOWORLOAD 都会收集这两个数据。
在 CPU 代价模型中,对于多数据块读的读取块数(MBRC),如果系统在 WORKLOAD 模式下收集了统计数据,并且收集期间有统计到多数据块读的相关操作,MBRC 则为系统统计数据数值;否则,由参数"_db_file_optimizer_read_count"决定(提示:该参数会受
"db_file_multiblock_read_count"设置的影响)。
至此,我们可以得到 CPU 代价模型中,全部扫描的扩展的代价估算公式中的 IO 代价部分。系统统计数据在 WORKLOAD 和 NOWORKLOAD 模式的系统统计数据获取方法不同,IO 代价的计算方法也不同:
o WORKLOAD:
IOCOST = (#BLKS/MBRC)MREADTIM/SREADTIM
o NOWORKLOAD:
IOCOST = (#BLKS/MBRC)(IOSEEKTIM+MBRC*OPTBLKSIZ/IOTFRSPEED)/(IOSEEKTIM+OPTBLKSIZ/IOTFRSP EED)
提示:MREADTIM/SREADTIM 也就是多数块读 IO 代价向单数据块读 IO 代价的转换因子。在负载模
式下,这两个数是由系统收集得到;在无负载模式下,这两个数据是由其它系统统计数据计算得到。
有了上述计算公式,全表扫描的 IO 代价部分已经可以估算出来了。我们用以下语句获取 CPU
代价模型中全部扫描某张表的 IO 代价:
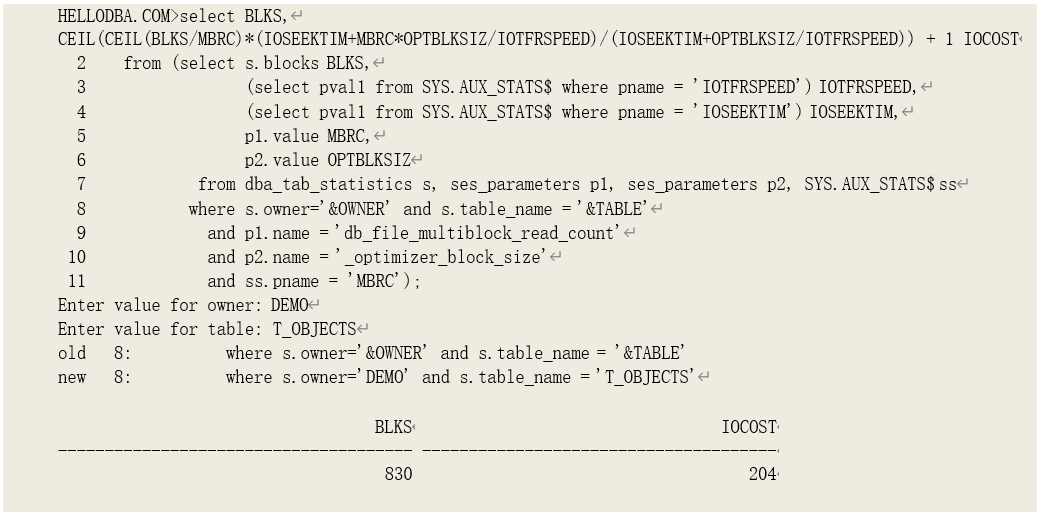
再看全表扫描该表的实际估算代价值:
IO 部分代价为 204,和我们的估算结果一致。缓存数据的影响
多数据块读的代价包含了从磁盘读入内存(Buffer Cache),再从内存传递到请求进程的过程。
而 Buffer Cache 中的数据是不会被立即置换回磁盘的,而是可以被其他进程再次利用的。如果下一个进程也请求读取这些数据,Oracle 进程则会先检查 Buffer Cache 中是否已经缓存了这些数据,对与已经缓存到 Buffer Cahce 中的数据,之间从内存中获取,而不需要再次读取磁盘,这也被称为缓存命中(Buffer Cache Hit),从缓存中读取的数据块数占总的读取的数据块数的比例则成为缓存命中率。相应的,优化器也可以将缓存命中考虑到优化过程中,并使用相应的缓存统计数据(缓存数 据块数 CACHEDBLK 和缓存命中率 CACHEHIT )。
要收集缓存统计数据(CACHEDBLK、CACHEHIT),就需要设置参数"_cache_stats_monitor"为
TRUE,它的默认值为 FALSE。如果希望优化器做代价估算时将缓存统计数据考虑进去,则需要设置参数"_optimizer_cache_stats"为 TRUE,它的默认值也是 FALSE。
提示:一旦参数"_optimizer_cache_stats"被设置为 TRUE,参数"_table_scan_cost_plus_one"将不对代价计算产生影响。
我们知道,内存中的数据传输效率是非常高,以至于内存传输时间与磁盘传输时间相比较而言, 几乎可以被忽略。因此,一旦优化器考虑了缓存统计数据,则缓存数据部分的代价被置为。
o 如果对象存在 CACHEDBLK 数据,则只考虑 CACHEDBLK 而忽略 CACHEHIT:
BLKS = BLKS(ALL) - CACHEDBLK;
o 如果仅存在 CACHEHIT,则考虑 CACHEHIT:
BLKS = BLKS(ALL)*(1-CACHEHIT);
示例:

上例中,CACHEBLK 为 100,因此,IO 部分的代价为:
IOCOST = CEIL((BLKS/MBRC)(IOSEEKTIM+MBRCOPTBLKSIZ/IOTFRSPEED)/(IOSEEKTIM+OPTBLKSIZ/IOTFRSPEED))
= CEIL(((830-100)/16)(8.373+168192/4096)/(8.373+8192/4096))
= 178 ≈ 179*0.99
要注意的是,一旦优化器启用了缓存统计数据估算代价的话,参数
"_optimizer_min_cache_blocks"确保估算过程中采用的最少缓存数据块数,其默认值为 10。如果对象没有收集缓存统计数据,估算过程则会采用该值进行估算。
提示:Buffer Cache 中的数据块是用 LRU(Last Recent Unused)链表进行管理的。即,如果需要从磁盘读取新的数据块到缓存中时,如果缓存没有足够空间,则会将最近最少被使用的数据块被置换
出缓存。对于单数据块读,新读入的数据块会被放到链表的头部,以保证它不会被很快置换出缓存; 而对于多数据块读,由于通常会读取较多数据块,为了避免多数据块读造成其他数据块的缓存命中 率下降,在 11g 之前,新读入的数据块则会被放在链表的 LRU 端,使它们会被尽快置换出缓存,而 在 11g 中,Oracle 会根据表的大小、缓存大小及其他数据决定是直接读(Direct Path Read)还是读
入缓存、放在链表的 LRU 端。我们会在后面章节更为详细的介绍 LUR 算法。
