




已经开工一周了,大家工作状态恢复的怎么样了?反正我的心还有一少部分没有从休假状态里“收”回来,哈哈,你是不是也一样啊 。
。
这应该是农历2022年的第一篇文章,开工的这段时间,正好遇到一个MySQL 8.0线上环境因硬件故障导致的主备切换问题。今天这篇文章就来记录一下问题发生后的整个修复思路和过程。Let's GO!


问题定位和环境介绍


故障环境概况及部分参数
MySQL Version:8.0.21MySQL Port:3386Xtrabackup Version:percona-xtrabackup-8.0.22-15数据同步方式:ROW + GTID + 增强半同步复制高可用架构:Keepalived + M-S(经典常见架构)一些参数配置:binlog_transaction_dependency_tracking = WRITESETtransaction_write_set_extraction = XXHASH64binlog_row_image = MINIMALinnodb_flush_log_at_trx_commit = 2sync_binlog = 0
问题发现与定位
正月十五元宵节15:46 PM,接到一个IO_Thread not running的报警。
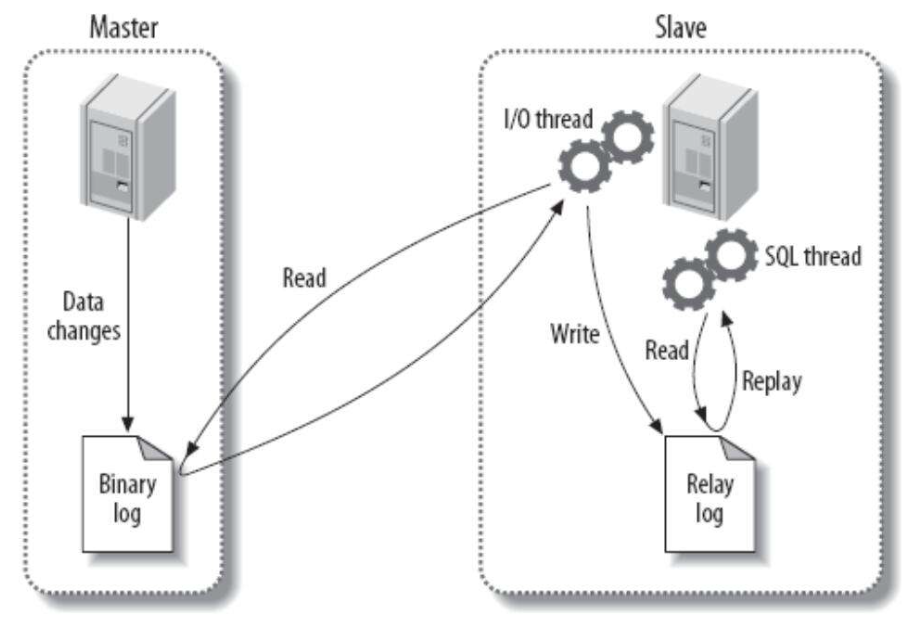
show slave status\G;
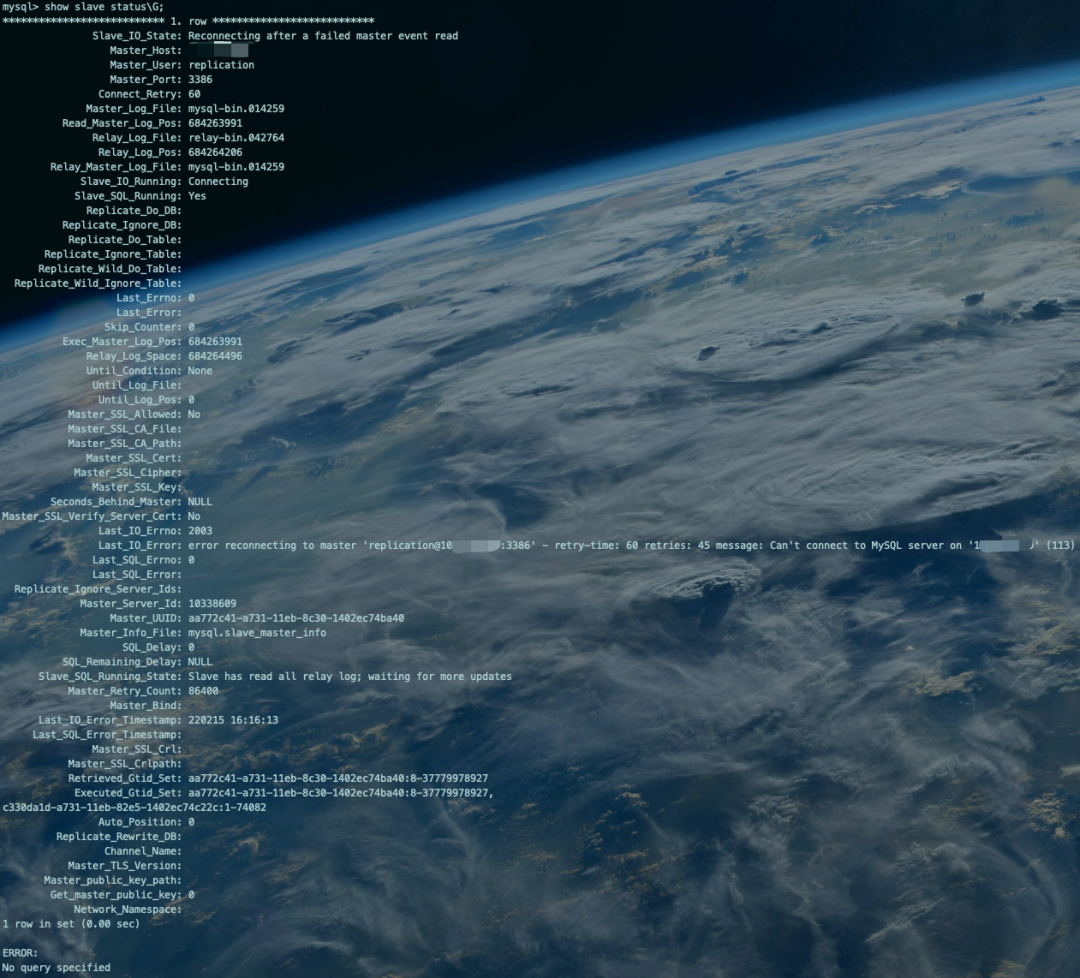
show master status\G;
接着,尝试连接主库服务器,连不上且ping不通,将机器发给SA(系统工程师)同事帮忙确认机器问题,最终定位:磁盘阵列卡故障(扩展:磁盘阵列卡是用于制作磁盘阵列的硬件设备,阵列卡和磁盘头部都会记录阵列元数据信息,如果阵列卡和磁盘只损坏一方的话,数据是不会丢失的,如果两方都损坏,就会造成数据丢失的情况)。
基于我们的高可用架构:Keepalived + M-S,自VIP漂移到从库,从库提升为主库承载业务的那一刻起,即使原主库数据没有丢失,但原主库已存在的数据也就成了历史数据了,对整个业务来说已经没有意义了。所以,目前的情况就剩下一个单独的新主库承载业务了。接着,需要在新主库(原从库上)执行清空slave信息的操作。
stop slave;reset slave all;
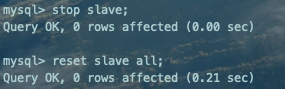
小结
至此,高可用架构在本次故障中生效,VIP漂移的的过程对业务无感知(业务方没有反馈数据库相关问题)。同时,问题定位到的同时也调整了提升为新主库的配置。
但是目前生产环境属于单实例的状态,并非高可用。所以,下一步的工作就是修复高可用架构。
高可用架构重建修复
重建修复高可用架构的思路
Keepalived + M-S的高可用架构组合,一般情况从库只作为备库进行故障时的主备切换使用,不承载任何业务流量。同时从库还有一个更重要的功能就是备份。目前我们的生产环境是每天晚上21点做一次全备。

因为原主库的数据对业务没有意义了,但新生产库单实例跑不放心,还是以尽快恢复高可用架构为原则,所以直接将前一天晚上的备份恢复到原主库,将原主库拉起成新高可用架构的从库是最快的办法。但是,又遇到了2个问题:
1、原主库硬件故障,无法直接使用。
2、没有相同配置的物理机可以补位,同时重新搭建系统、初始化环境、MySQL、备份软件的安装也需要一定时间。
工作中就是会遇到各种各样的棘手问题。因为没有补位的机器,所以只能等待原主库服务器修复,好在机房那边同事给力,有阵列卡备件,整个机器在2小时内修复了,因为只坏了阵列卡,数据库软件、原主库的数据都在,没有丢失,那这就好办了,节省了初始化环境的时间,下面就抓紧时间恢复数据拉起新从库。(PS:团队的力量是巨大的,出现突发状况时,就会显现出来,每个人都是团队不可或缺的一部分 )
)
数据恢复准备工作
因为原主库的binlog是放在datadir下的,为了防止业务侧需要,暂时保留原数据目录。要恢复的目标机器是原主库,未安装xtrabackup、qpress工具,首先安装所需工具,具体过程如下。
# 安装适应MySQL 8.0版本的Xtrabackup工具1、mkdir -p /opt/scripts2、cd /opt/scripts将安装包mysqlbackup8.tar.gz上传至/opt/scripts目录下3、解压:tar -xvf mysqlbackup8.tar.gz# 安装解压备份文件的qpress工具1、cd /root将安装包qpress-11-linux-x64.tar上传至/root2、解压:tar xvf qpress-11-linux-x64.tar3、chmod 775 qpress4、cp qpress /usr/bin
从库备份数据的方式是将备份文件流式存放至中间备机上,且目标新从库磁盘空间有限(需要同时保留了一份原始的数据目录),所以使用挂载中间备机盘符的方式直接进行恢复(中间备机的磁盘空间非常大)。
数据恢复
/opt/scripts/mysqlbackup8/percona-xtrabackup-8.0.22-15-Linux-x86_64.glibc2.17-minimal/bin/xtrabackup --defaults-file=/usr/local/mysql3386/etc/my.cnf --decompress --target-dir=/backup

备份文件解压完成。
Xtrabackup备份原理就是拷贝数据文件和追加拷贝redo log的变化写入到xtrabackup_logfile文件中。Prepare步骤就是将以"重做"的方式回放xtrabackup_log日志至备份集(拷贝的数据文件)中,实现数据恢复。
这里需要注意:MySQL 8.0的Xtrabackup工具和MySQL 5.7 xtrabackup-2.4.20工具回放日志命令的差异,MySQL 5.7是--apply-log,MySQL 8.0是--prepare,这个差别需要注意。
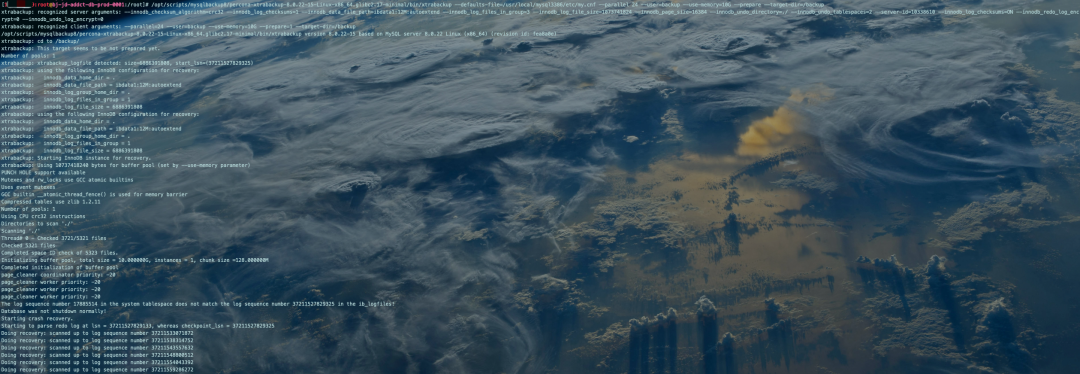
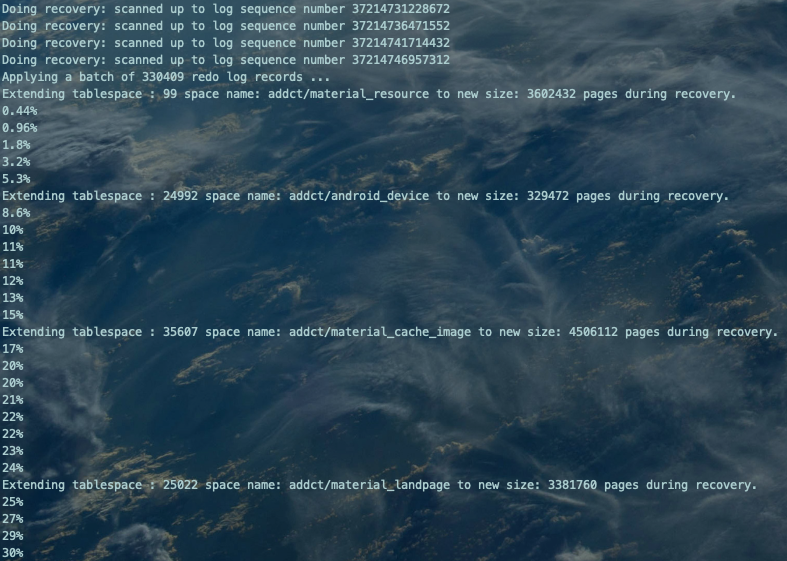
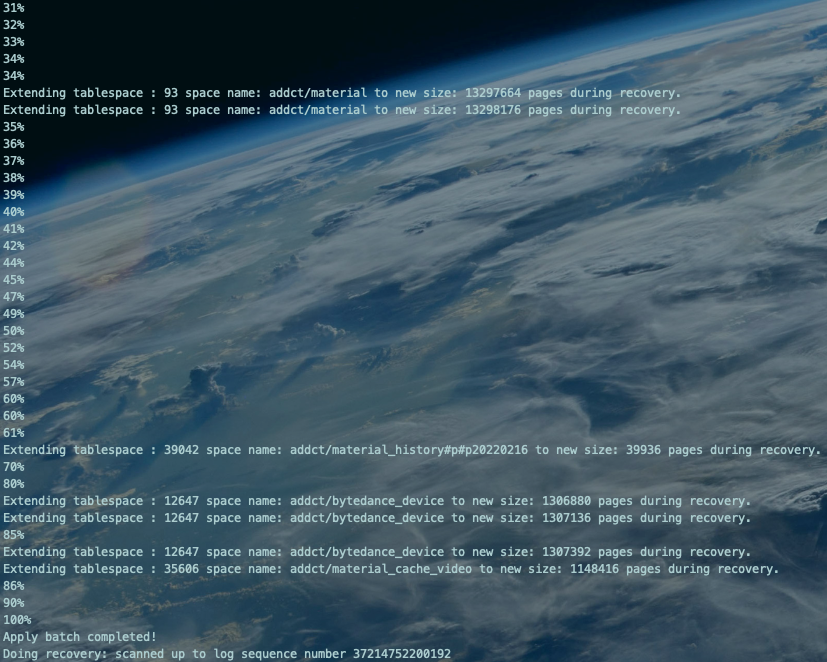
继续回放应用xtrabackup_log。。。
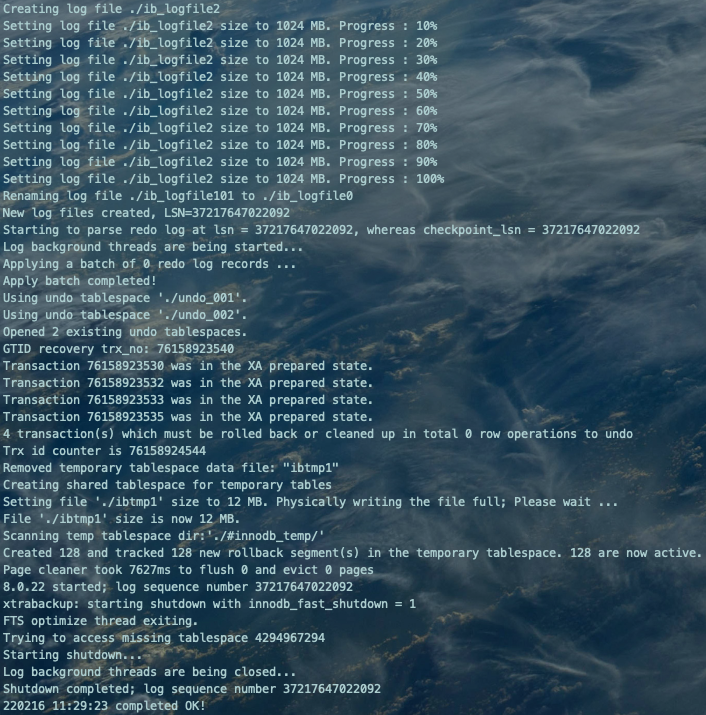
/etc/init.d/mysql3386 stop

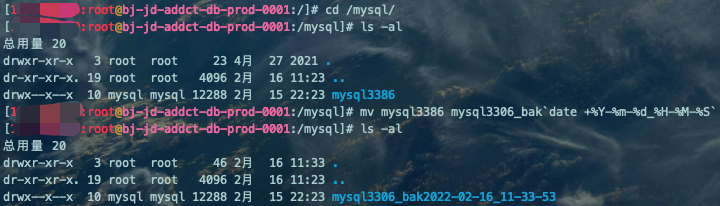
cd /mysql/ls -almv mysql3386 mysql3306_bak`date +%Y-%m-%d_%H-%M-%S`ls -al
(3)copy-back拷贝备份目录成为新的datadir。

chown -R mysql:mysql /mysql/mysql3386
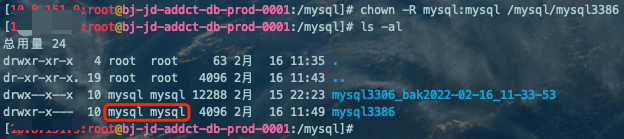
cat /mysql/mysql3386/xtrabackup_info
高可用架构的恢复
1、启动实例。
因为原主库服务器数据未发生丢失,但是,在启动MySQL实例前,还是需要仔细检查my.cnf等各种检查项(如新主库同步账户&权限、新从库的server-id是否和新主库冲突、是否需要设置skip-start-slave、各参数配置项等)。确认无误后,启动实例:
/etc/init.d/mysql3386 start

将刚恢复的新从库实例指向新主库,搭建新的主从关系。(因为我们使用的是ROW+GTID的同步方式,所以直接指定master_auto_position=1让MySQL自己识别同步信息吧 )
)
stop slave;CHANGE MASTER TO MASTER_HOST='xx.x.xxx.xx',MASTER_USER='repl',MASTER_PASSWORD='xxxxxxxx',MASTER_PORT=3386,master_auto_position=1;start slave;
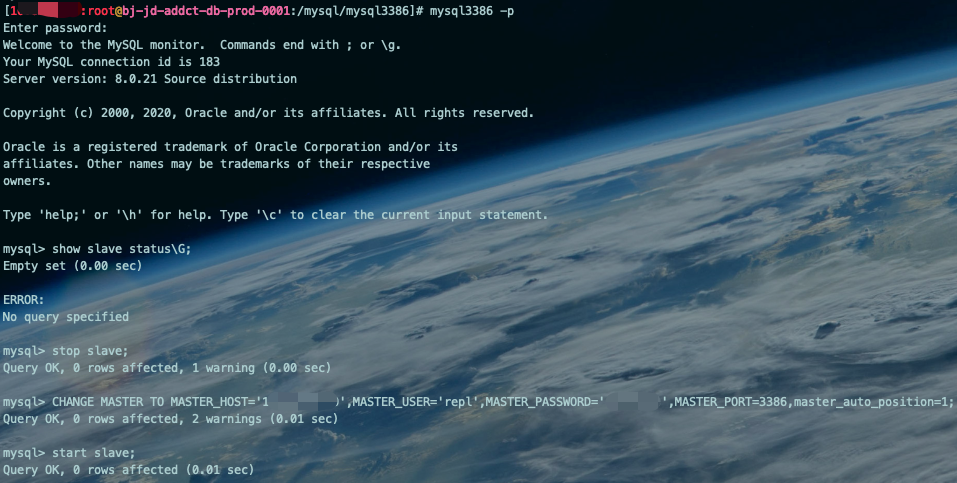
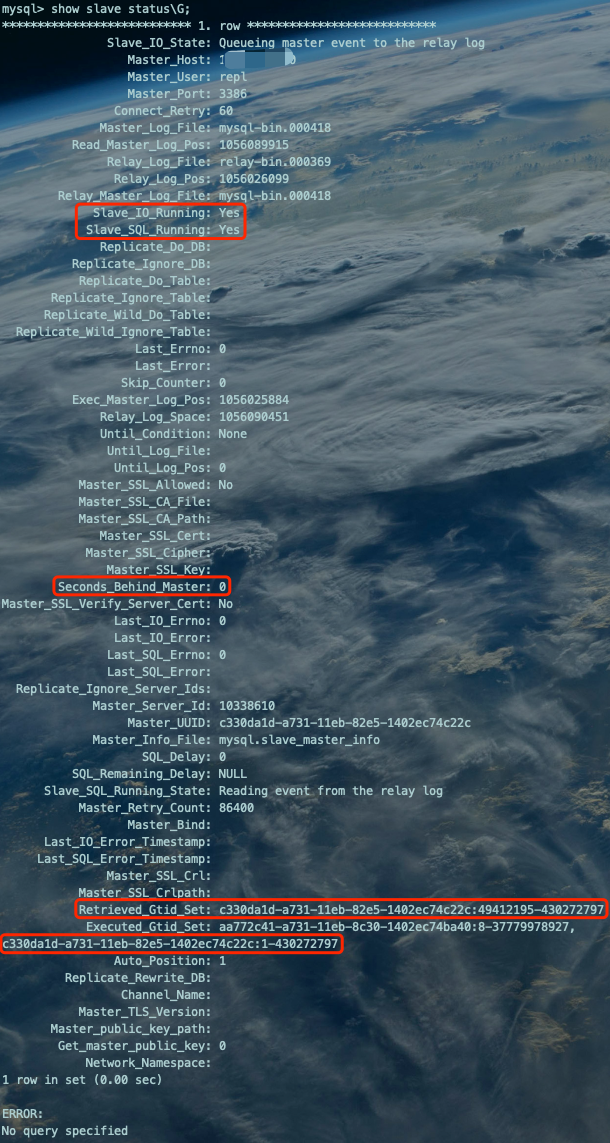
查看一下同步状态:
show slave status\G;
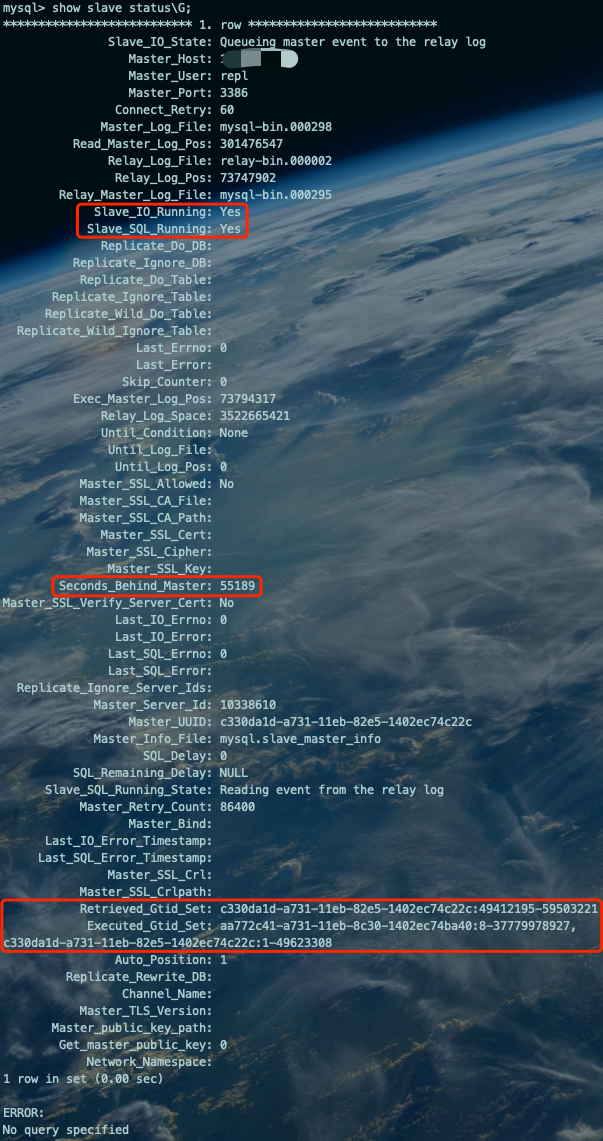
show slave status\G;
systemctl start keepalivedps -ef | grep keepalivedip a
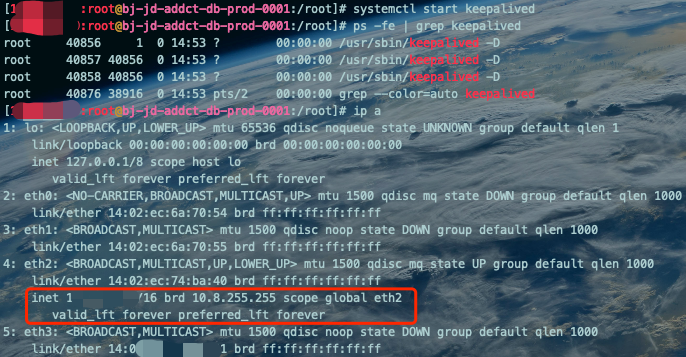
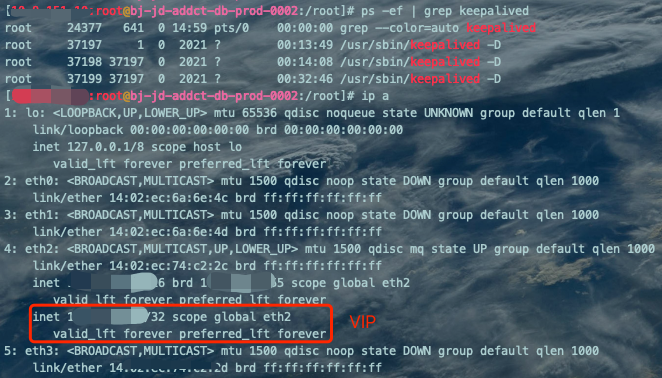
主库Keepalived服务、VIP、IP都正常。
4、收尾工作。
因为原来的主库成为新架构的从库了,所以配置好备份&定时任务,保险起见,临时做一次备份保证备份相关配置正确。
/opt/scripts/mysqlbackup8/mysqlbackup8.sh mysqlbackup8 fullcrontab -lmore /backup/backup_result.log
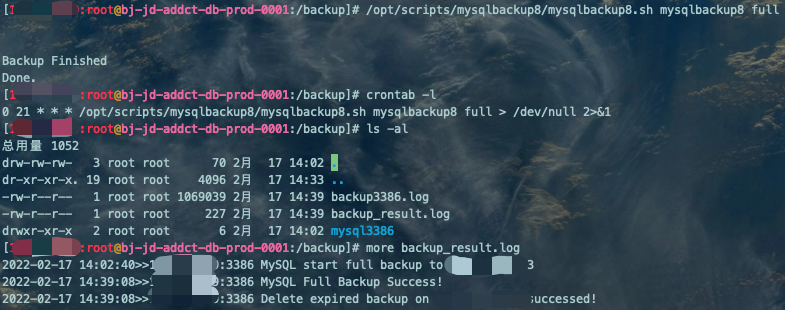
 。
。小结
以上就是今天的全部内容了,本文也说明了备份和高可用架构的重要性。不管是高可用架构还是备份,都是为了预防突发情况下数据库层面对业务造成的影响,我们的职责就是在发生突发情况时,保质保量、高效地对数据库层面故障进行修复,尽量不影响、减少对业务的冲击。
Keepalived + M-S的高可用架构是一种比较简单、常见且易维护的架构,也存在缺陷和弊端,如果业务允许,可以使用Keepalived + M-M的架构,但是,世上没有完美的事物(包括高可用架构),如MHA、MGR也都同样存在不足。同时,公司会出于成本、业务可承受风险范围等因素的考虑,也会对高可用架构进行评估选型。虽然没有完美的高可用架构,但是在能满足公司业务、自己技术能力可达的前提下,选择最适合自己的高可用架构就好,没有必要争取更高的技术,维稳才是王道。
最后,最为重要的还是部门同事间的团队协作。如果没有补位机器、没有同事配合,自己单打独斗的情况下,就会拖慢整个修复进程。正因有我们系统工程师、机房同事的相互配合,才有了高效率的修复过程。
又是收获满满的一天,每天进步一点点。大道至简,贵在坚持,与君共勉!~

扫描二维码关注
获取更多精彩
GrowthDBA

end
