




PostgreSQL数据库优化一优化概述及操作系统调优
优化概述及操作系统调优
优化概述
思路
把一些无用的步骤或用处不大的步骤去掉就是一种优化。
做同样的一件事情,能够更快地做,如让SQL做到更优的执行计划上。
度量指标
响应时间RT:衡量数据库系统与用户交互式多久能够发出响应。
吞吐量QPS/TPS:衡量在单位时间里可以完成的数据库任务。
常见依赖因素
环境:机器配置、网络带宽和时延、HA架构(同步/异步复制)、数据库参数(刷盘参数等)
业务场景:表定义、数据量、SQL、事务隔离级别、并发度
优化是什么
合规性检查
数据库上线前的一次性检查,是否符合规范
配置优化
数据库系统运行过程中多次优化调整
对象优化
表分区、物化视图、碎片整理、索引重建等
SQL优化
慢SQL,TopSQL
调优类型
- 预定义的:DBA制定调优的目标,来达到预定的效果;
- 主动式的:周期性去采集信息,目标不明确,主要范围是集中在数据库实例级别;
- 被动式的:客户抱怨出现问题,这类优化主要集中在SQL语句级。
调优阶段
调优设计
架构设计(单机或主从)、应用设计(模块设计)
调优操作系统
共享内存段大小、文件缓存大小、网络配置、文件系统、存储缓存、异步IO等
调优I/O
使用表空间、存储对象分布,文件存储分布等
调优内存
数据库共享内存、维护工作内存、工作内存、临时内存
调优竞争
锁等待
调优应用
代码调优、应用存储对象调优
主动式性能调优的基本步骤
-
详细了解业务特性和优化需求调优应用
-
设计合理的性能优化目标
-
收集并记录当前性能信息(包括数据库和操作系统)
-
确定当前操作系统和数据库的性能瓶颈
-
结合性能指标、用户描述和性能信息分享瓶颈原因
-
确定合适的优化方法优化相关性能问题
-
逐步实施优化方法,记录实施更改过程及场景
-
在业务稳定运行后重新收集性能信息,确定是否达到优化要求
-
如果没有成功,重复前面的步骤,直到满足优化目标
平衡性能与数据库健壮性的需求
- Raid方式(读多,可使用raid5,写多,可使用raid10)
- 频繁的检查点
- 备份数据文件
- 执行归档
- 异地容灾等
优化关注的问题
- 稳
- 改善用户的使用体验
- 帮助客户省钱
硬件优化
操作系统硬件
CPU、内存、磁盘
CPU选择及调优工具
-
< V9.6
单核计算能力强的CPU
-
<= V9.6
多核

[root@lxs1 ~]# cd /usr/lib/tuned
[root@lxs1 tuned]# mkdir pg_performance
[root@lxs1 tuned]# vi pg_performance/tuned.conf
[main]
summary=Tuned profile for PostgreSQL Instances
[bootloader]
cmdline=transparent_hugepage=never
[cpu]
force_latency=1
governor=performance
energy_perf_bias=performance
min_perf_pct=100
[disk]
readahead=>4096
[vm]
transparent_hugepages=never
[sysct1]
kernel.sched_min_granularity_ns = 10000000
kernel.sched_wakeup_granularity_ns = 15000000
# checkpoint performance
vm.dirty_background_bytes = 67108864
vm.dirty_background_ratio = 5
vm.dirty_bytes = 536870912
vm.dirty_ratio = 10
vm.dirty_expire_centisecs = 500
vm.dirty_writeback_centisecs = 250
vm.overcommit_memory= 2
net.ipv4.tcp_timestamps=0
#VM
vm.swappiness=1
[root@lxs1 tuned]# tuned-adm profile pg_performance
[root@lxs1 tuned]# tuned-adm active
Current active profile: pg_performance
[root@lxs1 tuned]#
CPU性能测试
通过使用generate_series函数对100万个整数相加测试CPU
\timing
select sum(generate_series) from generate_series(1,1000000);
create table test (id integer primary key);
insert into test values (generate_series(1,1000000));
explain analyze select count(*) from test;
postgres=# \timing
Timing is on.
postgres=# select sum(generate_series) from generate_series(1,1000000);
sum
--------------
500000500000
(1 row)
Time: 429.659 ms
postgres=# create table test (id integer primary key);
CREATE TABLE
Time: 8.689 ms
postgres=# insert into test values (generate_series(1,1000000));
INSERT 0 1000000
Time: 4556.109 ms (00:04.556)
postgres=# explain analyze select count(*) from test;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=11302.17..11302.18 rows=1 width=8) (actual time=127.750..130.163 rows=1 loops=1)
-> Gather (cost=11301.95..11302.16 rows=2 width=8) (actual time=127.103..130.147 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (cost=10301.95..10301.96 rows=1 width=8) (actual time=118.579..118.580 rows=1 loops=3)
-> Parallel Seq Scan on test (cost=0.00..9126.56 rows=470156 width=0) (actual time=0.058..81.504 rows=333333 loops=3)
Planning Time: 0.478 ms
Execution Time: 130.249 ms
(8 rows)
Time: 131.683 ms
postgres=#
内存
到底应该给数据库分配多大内存?
- 如果所处理的数据量相对于系统RAM来说非常小,此时需要使用更快的处理器。
- 当数据库进行表扫描操作,但这些表的数据量远远大于可以我数据库分配的内存,这时候需要选取更快的硬盘,而不是增加内存。
内存评测
-
Memtest86+
http://www.memtest.org
-
STREAM
http://www.cs.virginia.edu/stream/ref.html
https://github.com/jeffhammond/STREAM
磁盘设置
磁盘驱动器
- ATA驱动SATA磁盘
- SCSI启动SAS磁盘
RAID技术
- raid0 – 提高读写性能、安全性较低
- raid1 – 安全性根据组里实体硬盘数增长,空间利用率低
- raid5 – 兼顾空间利用率与数据安全性(常用)
- raid10 – 先建立两组raid1,在其基础上促成raid0,代价较贵。
磁盘性能测试
-
dd block=250,000 * RAM(GB)
time sh -c “dd if=/dev/zero of=bigfile bs=8k count=${blocks} && sync”
time dd if=bigfile of=/dev/null bs=8k
-
fio/sysbench
sysbench fileio --file-total-size=15G --file-test-mode-rnderw --time=300 --max-requests=0 prepare
sysbench fileio --file-total-size=15G --file-test-mode-rnderw --time=300 --max-requests=0 run
sysbench fileio --file-total-size=15G --file-test-mode-rnderw --time=300 --max-requests=0 cleanup
磁盘设置
-
scheduler(调度策略)
- noop(SSD)
- deadline(低延迟高吞吐)
- cfq(默认平衡策略)
-
read-ahead(预读)
-
分配足够IO能力的磁盘(足够多的磁盘)
-
raid组的设计
磁盘布局
| Location | Disks | RAID Level | Purpose |
|---|---|---|---|
| /(root) | 2 | 1 | OS |
| $PGDATA | 6+ | 10 | Database |
| $PADATA/pg_wal | 2 | 1 | WAL |
| Tablespace | 1+ | None | Temporary files |
| Function | Cache Flushes | Access Pattern |
|---|---|---|
| OS | Rare | Mix of sequential and random |
| Database | Regularly | Mix of sequential and random |
| WAL | Constant | Sequential |
| Templorary | Never | More random as client increases |
操作系统优化
文件系统及缓存
回写缓存write-back cache
预防write-back cache出故障的措施
- 确保系统完整实现了fsync调用或者类似机制的功能(wal_sync_method)。
- 监控磁盘控制器电池。有些控制卡自身会监控其状态,如果发现掉电或者工作不正常时,会从write-back改成write-through模式,当然其性能会下降。
- 禁止任何磁盘的write-cache模式。大部分RAID卡会来做这点,他们会优先使用BBC模式。
磁盘阵列一般都用write-back cache,因为他配置了电池,一般称为battery-backed write cache(BBC or BBWC)
文件系统
- 选择合适的文件系统
- ext4
- xfs
- zfs/btrfs
- 文件系统规划
- PG_WAL命令
- PGDATA数据目录
- 归档目录
- 挂载参数
- noatime
- nobarrier
系统缓存
- 预留足够的物理内存,用于文件的读写CACHE
- 根据业务系统的特点与硬件的IO能力调整脏块刷新频率
如果物理IO性能很强,则降低刷新频率,减少脏块比例,如果物理IO性能较弱,则往反方向调整。
操作系统内核参数
共享内存参数
-
kernel.shmmax
丹哥共享内存段的最大大小,以字节为单位
-
kernel.shmall
服务器上所有进程可以使用的共享内存的总页数
-
kernal.sem = 250 32000 32 128
进程通信的系统信号量
[root@lxs1 ~]# more kernel.sh
#!/bin/bash
# simple shmsetup script
page_size=`getconf PAGE_SIZE`
phys_pages=`getconf _PHYS_PAGES`
shmall=`expr $phys_pages / 2`
shmmax=`expr $shmall \* $page_size`
echo kernel.shmmax = $shmmax
echo kernel.shmall = $shmall
[root@lxs1 ~]# sh kernel.sh
kernel.shmmax = 16868265984
kernel.shmall = 4118229
[root@lxs1 ~]#
VM参数
-
内存与换页策略
-
vm.swappiness
建议设置为小于10(比如0或者1)
-
vm.overcommit_memory
0系统会判断剩余可用的内存大小,如果可用内存不足就会失败(试探性分配)
1系统不进行任何检查,允许超量使用内存,知道内存用完为止(超分配)
2不允许超过可用内存的大小(超分配时做检查)
-
vm.overcommit_ratio
-
-
文件缓存脏块回写策略
- vm.dirty_background_ratio = 5(10–>5)
- vm.dirty_ratio = 10~15
LIMITS设置
postgres soft nofile 1048576
postgres hard nofile 1048576
postgres soft nproc 131072
postgres hard nproc 131072
postgres soft memlock unlimited
postgres hard memlock unlimited
postgres soft core unlimited
postgres hard core unlimited
postgres soft stack unlimited
postgres hard stack unlimited
# core - limit the core file size (KB)
# memlock - max locked-in-memory address space (KB)
# nofile - max number of open files
# nproc - max number of processes
HugePages设置
-
HugePages
- SESSION数量很大的情况下,分配给进程的页表(PAGETABLE)数量会增多。这种内存占用带来的系统换页、内存碎片化问题在某些场景下回变得十分严重。
- 对于会话数很多,并发访问量较大的PG数据库来说,一定要考虑HugePages的设置,否则内存的页表占据很大的空间,同时页表过大会引起整个OS性能下降
-
Transparent HugePages
- 为了解决HugePages配置的变化需要重启服务器的问题,Linux推出了透明大页技术。虽然透明大页可以解决普通大页管理的弊端,不过这种透明大页对于一些高负载的应用场景,可能带来内存严重碎片,影响操作系统内存分配性能的问题。在某些环境中,数据库与操作系统的透明大页技术并未实现很好的融合,使用透明大页可能带来一些负面的影响。因此在PG上暂时不建议使用透明大页,并且在一些高负载的大型数据库系统中建议关闭操作系统的透明大页功能。
- transparent_hugepage = never
NUMA设置
- 大多数情况,我们可以在BIOS层面关闭NUMA支持,并且在OS启动参数中设置numa off参数,那么我们再OS上就可以不用关注NUMA问题了。
- 如果在OS上没有关闭NUMA,也可以通过下面的手段让PG数据库在分配内存的时候不理会NUMA的远程内存。
vm.zone_reclaim_mode=0 vm.numa_balancing=0 numactl-interleave=all
其他系统优化
- 打开SWAP
- 禁用Selinux
- 禁用RemoveIPC
- 禁用IPV6
- 关闭不必要的服务
表空间优化
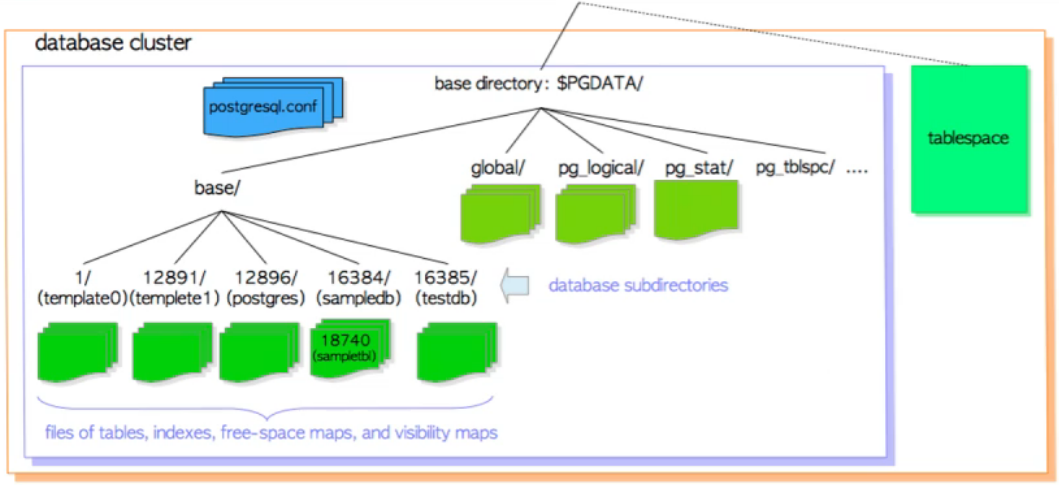
postgres=# \db
List of tablespaces
Name | Owner | Location
------------+----------+----------
pg_default | postgres |
pg_global | postgres |
(2 rows)
postgres=# create tablespace mytb1 location '/home/postgres/tbls_a';
CREATE TABLESPACE
postgres=# \db mytb1
List of tablespaces
Name | Owner | Location
-------+----------+-----------------------
mytb1 | postgres | /home/postgres/tbls_a
(1 row)
postgres=# create table t(i int) tablespace mytb1;
CREATE TABLE
postgres=#
使用表空间的优点
- 分散IO
- 存储扩容
- 限制单个table或db的size
- 对不同的磁盘进行参数调优
- 单独设置临时文件的路径
总结
-
硬件优化
CPU、内存、磁盘的选配及相应的设置
-
操作系统参数调优
VM参数、LIMITS限制、Huge Pages、NUMA设置
-
表空间优化
使用表空间的优点
