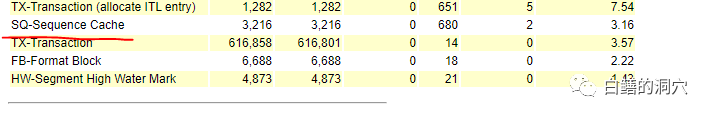排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
BBW的一些典型场景
BBW的一些典型场景
白鳝的洞穴
2020-09-30
12109
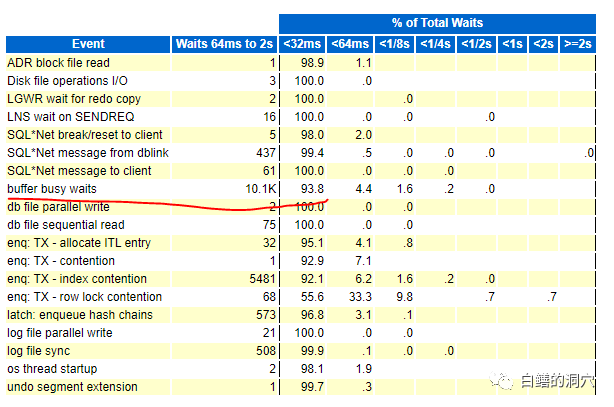
昨天介绍了一个BBW的案例,这是一个制造业DCS的案例,那种短时间的BBW问题尖峰也不过几分钟时间,在半小时的AWR报告中看到的平均BBW延时是9毫秒。一般来说9毫秒的延时不会对系统性能造成很大的影响,但是大家看到的AWR中所有的数据都是采样周期内的平均值,只有通过柱状图才可以更清晰的看到具体的BBW情况。
我们看到接近60%的BBW是8毫秒以内的,有7%是16到32毫秒的,32毫秒到1秒的有6.2%,没有1秒以上的。按总量16.24万看,这部分大于32毫秒的等待总数量也差不多有1万了。
对于大于32毫秒的,93.8%是小于64毫秒的,因此总体来说延时还不算太高。不过这种不算太高也是要分场合的。对于一个制造业的DCS系统来说,还是有点太高了。如果再恶化一点,将可能影响生产线的业务了。
除了昨天分析的那种场景,BBW还有哪些比较典型的场景呢?今天老白和大家一起来总结一下:
(1)BBW+cache buffer chains等待严重+CPU使用率较高
这种场景是小型机时代经常遇到的问题,因为那时候小型机十分昂贵,在购买的时候很多客户不能足量的购买CPU和内存,那时候的IO系统的性能也没办法和现在相比。再加上DBA最为头痛的一件事,就是开发商随着性子写SQL,导致大量的SQL性能低下。
对于这种场景,大多数都会存在buffer gets比较高的SQL,主要是SELECT和UPDATE,如果能够找几个这样的SQL优化一下,这个问题马上就能缓解,如果能找到几条索引走错或者缺少索引的SQL,那么可能很快就可以搞定这个问题。
这种场景下,有时候会出现free buffer waits和write complete等待。这种情况下,可能存在两方面的问题,一个是IO性能不足,一个是DB CACHE过小。这种情况,调整下DB cache,适当的调整下KEEP POOL,把一些热点小数据放入KEEP POOL,可能就能起到缓解的作用。
(2)BBW+enq TX conntention+单块读延时较高
这种情况一般来说都是因为某些插入量比较大的表因为索引叶节点分裂导致的行锁等待变大。对于银行核心的交易流水,传票当日、交易报文日志等通过sequence做主键的表,如果表上的索引数量较多,容易触发类似的问题。这个问题和昨天的案例有些类似,不过不完全相同。
出现此类情况
有几种
可能的原因。
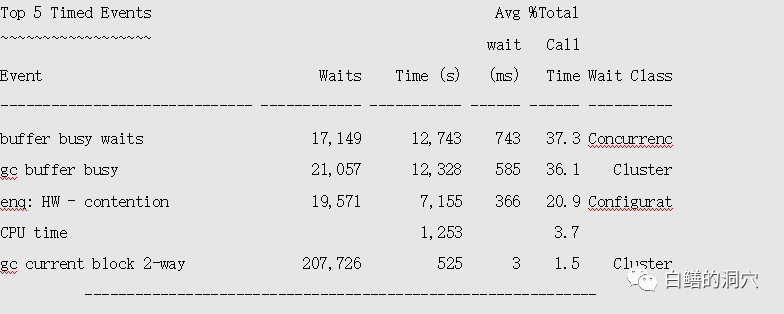
A) 单块读延时较高(或者比正常时段高50%以上),leaf node splits超过10,甚至超过20,这种情况下,可能IO负载较大导致了IO延时过大,导致在索引叶节点分裂的情况下表的索引维护成本够高,最终导致行锁问题。这个现象在TOP EVENT里能明显的看到TX锁相关的等待。这时候要比较IO总量和平时是否有变化,是什么造成的,是某条开销较大的SQL导致的,还是rman备份导致的。另外direct path read较为严重也可能导致类似问题。
B)如果IO延时没有太大变化,那么要看是不是存在较为严重的ITL等待,或者索引的LEAF NDOE SPLITS特别严重,这时候就需要调整ITL参数,或者REBUILD相关索引了。如果是应急,暂时DISABLE相关索引也能缓解这个问题。另外长远来看,通过HASH分区、反转键索引等方式来进行一些优化可能能起到除根的效果。
C)从AWR中的锁等待章节如果看到较多的sequence CACHE锁,那么可能是某些SEQUENCE的CACHE太小了或者访问太频繁了,需要优化sequence的参数,比如使用Nooder等
D)如果是UPDATE语句导致,那么就需要查看这些UPDATE语句是不是在修改数据量较小的数据,但是执行频率十分频繁。如果是这样的话,把这些表放到KEEP池里可以缓解,如果还不能缓解,那么把这些表或者索引放入4K的表空间,如果还解决不了,那么就应该修改你们的应用,用redis来处理这样的数据了。这种情况,以前在运营商的融合计费系统中常见,后来这些数据都放到内存数据库里去了。
(3)RAC GES/GCS相关问题
这种问题往往伴随gc相关的问题。这是RAC环境下的BBW,其产生的主要原因都包含在上面的情况里了,只是应用跑在RAC的多个节点上,把BBW扩大到了RAC范围了。其主要的成因除了集群网络方面的问题(比如吞吐量过大,网络延时过高、网络丢包等)外,其他的成因和上述几种场景类似。
BBW的问题还是比较复杂的,老白这些年也处理过一些案例。不过还无法覆盖所有的可能场景,也许这些场景对大家有些启发吧,这样这一千多个字,老白码的也就有价值了。
数据库
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨