




接上一篇,上期问题的bug其实就是ssh的问题,重新配置了一下免密,然后就可以了。
[ywang@hadoop103 hadoop-3.1.3]$ ./sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[ywang@hadoop103 hadoop-3.1.3]$ jps
3488 NodeManager
3347 ResourceManager
3832 Jps
3100 DataNode
[ywang@hadoop102 hadoop-3.1.3]$ jps
3799 NodeManager
3256 NameNode
4329 Jps
3403 DataNode
[ywang@hadoop104 hadoop-3.1.3]$ jps
3953 Jps
3171 SecondaryNameNode
3064 DataNode
3357 NodeManager复制
同HDFS一样,在web中 http://hadoop103:8088 也会出现相应的YARN上资源信息。
至此,我们的集群启动完毕,与配置方式中的需求完全一致。
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
2.3 集群基本测试
2.3.1 上传文件到集群
首先在根目录下创建一个文件夹wcinput,然后将本地的wcinput中的b.txt上传
[ywang@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /wcinput
[ywang@hadoop102 hadoop-3.1.3]$ hadoop fs -put wcinput/b.txt /wcinput
2021-11-20 19:19:27,199 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false复制
在 http://hadoop102:9870/explorer.html#/wcinput 中可以看到上传的文件,可以进行查看和下载b.txt。
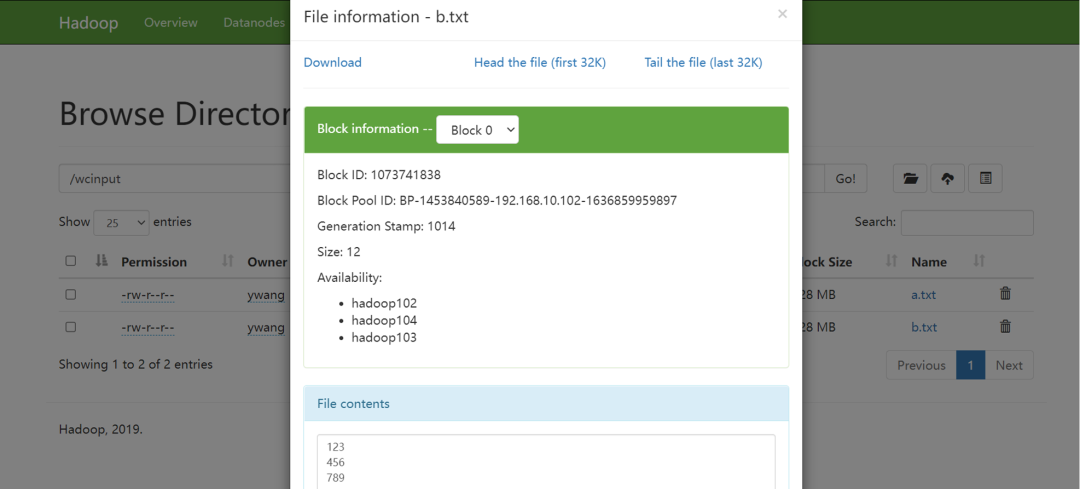
这步把数据和文件上传到hdfs中,上图为可视化展示信息,但是实际上存储文件的是DataNode节点,那么DataNode在哪里呢?
之前配置了一堆的配置文件,其中的core-site.xml中就定义好了存储的位置
<configuration>
<!-- *** -->
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-1.3.1/data</value>
</property>
<!-- *** -->
</configuration>复制
所以我们进入/opt/module/hadoop-1.3.1/data目录下面去寻找文件(具体的文件路径为代码段pwd的相关路径,data子目录中的文件分类可自行搜索)。此外,由于hadoop的高可用性,它还有两个副本在hadoop103和104中,也是在这个目录下,这里我就不做展示了。
[ywang@hadoop102 subdir0]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1453840589-192.168.10.102-1636859959897/current/finalized/subdir0/subdir0
[ywang@hadoop102 subdir0]$ ls
blk_1073741825 blk_1073741827 blk_1073741835 blk_1073741837
blk_1073741825_1001.meta blk_1073741827_1003.meta blk_1073741835_1011.meta blk_1073741837_1013.meta
blk_1073741826 blk_1073741834 blk_1073741836 blk_1073741838
blk_1073741826_1002.meta blk_1073741834_1010.meta blk_1073741836_1012.meta blk_1073741838_1014.meta
[ywang@hadoop102 subdir0]$ cat blk_1073741838
123
456
789复制
2.3.2 执行wordcount
wordcount作用是利用yarn完成文件中词数的统计。重新上传c.txt (文件内容如下) 到集群/wcinput目录下,可以看到有的词重复了多次。
[ywang@hadoop102 wcinput]$ cat c.txt
123 123 123
456 456
789
beibo beibo
beibo
abc复制
执行下面命令,其中/wcinput/c.txt是集群中的输入路径,/wcoutput2是集群中的输出路径
[ywang@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput/c.txt /wcoutput2复制
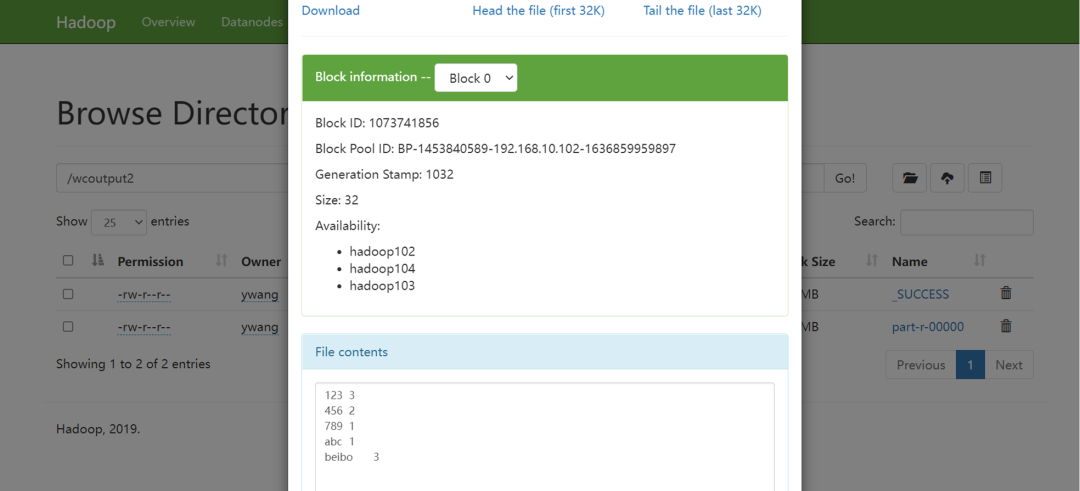
执行完毕后,观察hdfs的web页面的/wcoutput2目录,可以看到每个词出现的次数。
现在我们再次刷新yarn的web页面,可以看到有一个History的选项,点击后无法访问,说明我们没有配置历史服务器。
2.4 关闭集群(以及一些启动停止技巧)
在hadoop103上和102上执行
[ywang@hadoop103 hadoop-3.1.3]$ ./sbin/stop-yarn.sh
[ywang@hadoop102 hadoop-3.1.3]$ ./sbin/stop-dfs.sh复制
分别启动/停止hdfs组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode复制
分别启动/停止yarn组件
yarn --daemon start/stop resourcemanager/nodemanager复制
如果出现集群崩溃的情况,比如启动后NameNode不存在了,需要以下步骤
1、停掉所有进程:./sbin/stop-yarn.sh ./sbin/stop-dfs.sh
2、删除所有节点的旧数据和日志:rm -rf ./data/ ./logs/
3、初始化:hdfs namenode -format复制
3、配置历史服务器
3.1 在102上配置mapred-site.xml
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 用于hadoop集群之间的通信端口-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 用于用户访问的web端口-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
</configuration>复制
3.2 分发到103和104
[ywang@hadoop102 hadoop-3.1.3]$ xsync mapred-site.xml复制
之后,这里要重启下yarn,注意!yarn的RM配置在了103上,所以在103上stop然后start。
3.3 在102中启动历史服务器
[ywang@hadoop102 hadoop-3.1.3]$ ./bin/mapred --daemon start historyserver
[ywang@hadoop102 hadoop-3.1.3]$ jps
8569 Jps
3691 NameNode
3835 DataNode
8507 JobHistoryServer
8318 NodeManager复制
3.4 查看历史记录
这里我重新测试了wordcount,输出路径不能重复,所以改为/wcoutput3。
[ywang@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput/c.txt /wcoutput3复制
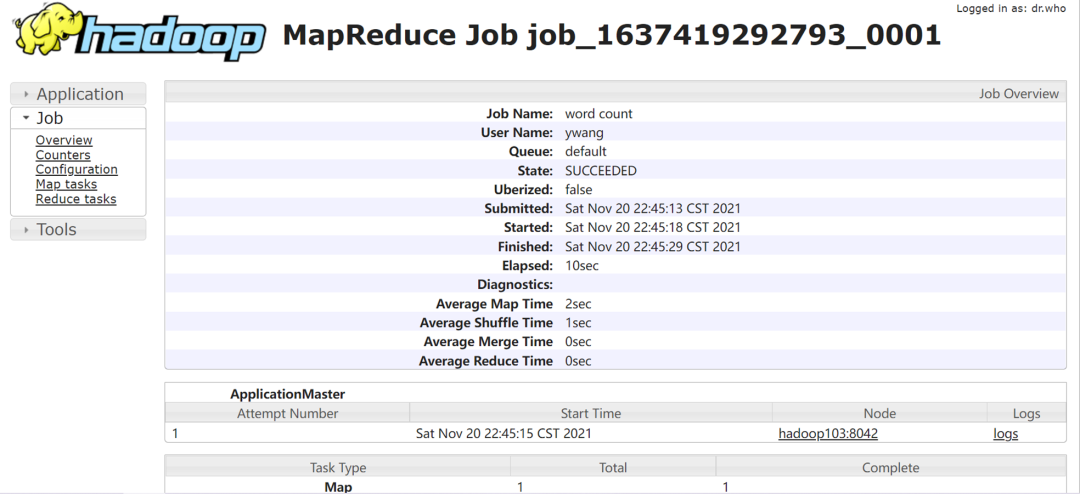
执行完毕后,刷新 http://hadoop103:8088/cluster 后点击History会进入 http://hadoop102:19888/jobhistory/job/job_1637419292793_0001 中,这里会出现mapreduce job的详细信息。注意此时点击右下角的logs无法访问,下面进行日志聚集配置:
4、配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到hdfs系统中,方便用户访问。
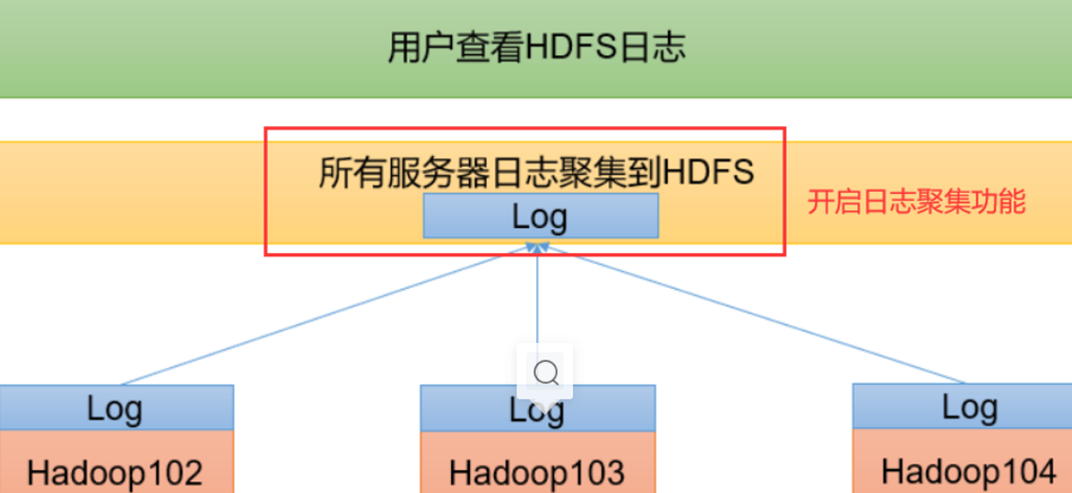
4.1 102下修改yarn-site.xml
添加下列property
<configuration>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>复制
4.2 分发到103和104
[ywang@hadoop102 hadoop-3.1.3]$ xsync yarn-site.xml复制
4.3 关闭与重启
关闭historyserver
[ywang@hadoop102 hadoop-3.1.3]$ mapred --daemon stop historyserver复制
重启yarn
[ywang@hadoop103 hadoop-3.1.3]$ ./sbin/stop-yarn.sh
Stopping nodemanagers
hadoop103: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
hadoop104: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
Stopping resourcemanager
[ywang@hadoop103 hadoop-3.1.3]$ ./sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers复制
启动historyserver
[ywang@hadoop102 hadoop-3.1.3]$ ./bin/mapred --daemon start historyserver复制
此时重新执行一次wordcount,刷新yarn的web页面,点击History、进入后点击logs就会出现所有的日志信息。
5、Hadoop集群脚本
为了方便启动停止集群和查看所有节点的jps,利用shell脚本可以方便操作,下面的脚本全部测试过没有问题。
5.1 启动停止脚本
在102的/hadoop3.1.3/bin目录下,vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac复制
然后对其chmod 777 myhadoop.sh即可使用。
启动:myhadoop.sh start
停止:myhadoop.sh stop复制
5.2 查看所有节点jps脚本
在102的/hadoop3.1.3/bin目录下,vim jpsall.sh
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done复制
然后chmod777,再讲jpsall.sh分发到103和104上,可以随时执行jpsall.sh,例如:
[ywang@hadoop104 subdir0]$ jpsall.sh
=============== hadoop102 ===============
12577 NodeManager
12082 NameNode
12754 JobHistoryServer
12261 DataNode
13926 Jps
=============== hadoop103 ===============
12784 Jps
11429 NodeManager
11290 ResourceManager
11085 DataNode
=============== hadoop104 ===============
9760 SecondaryNameNode
11063 Jps
9628 DataNode
9870 NodeManager复制
查看更多Hadoop系列文章:
[1]从头学习Hadoop
[2]Hadoop集群配置
