





01 Hadoop是什么
Hadoop是一个Apache基金会所开发的分布式系统基础架构。主要解决海量数据的存储和海量数据的分析计算问题,Hadoop生态圈包括HBase、HIVE、Zookeeper等技术。
02 Hadoop的优势
高可靠性
Hadoop底层维护了多个数据副本,即使某一台服务器出现问题,也不会损失数据。
高扩展性
在集群中具有动态的扩展性。比如双11前由于购物量暴增,原来的集群可能无法处理大数据,可以增加服务器在Hadoop集群中动态分配任务数据,不需要宕机和重启,双11过后还可撤走,不影响其他服务器工作。
高效性
受到MapReduce的思想,Hadoop集群可以并行工作,提高效率。
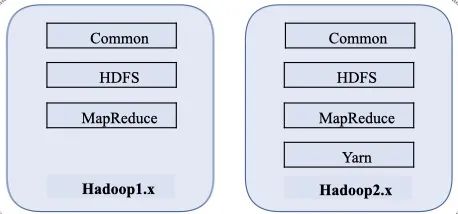
03 Hadoop的组成
Hadoop1.x:Common(辅助工具)、HDFS(数据存储)、MapReduce(计算+资源调度)
Hadoop2.x:Common(辅助工具)、HDFS(数据存储)、MapReduce(计算)、Yarn(资源调度)

HDFS
Hadoop Distributed File System,HDFS,是一个分布式文件系统,由三部分构成:NameNode、DataNode和Secondary NameNode。
NameNode(nn):存储数据的元数据,如文件名、文件目录结构、文件属性等,还有每个文件的块列表和块所在的DataNode等。就像是书的目录,起到存放位置的作用。
DataNode(dn):它实际在本地文件系统存储文件块数据,还有块数据的校验和。可以理解为书目录对应的各个内容,是真正存储文件的地方。
Secondary NameNode(2nn):它是nn的一个协作者,负责每隔一段时间对NameNode的元数据备份。
YARN
Yet Another Resource Negotiator,Yarn,是Hadoop的资源管理器,主要管理CPU和内存,主要由Resource Manager和Node Manager组成。
Resource Manager(RM):整个集群资源(内存、CPU)的所有者。可以给NM分配资源。
Node Manager(NM):单个节点服务器的所有者。
另外NM内部还有两个概念,ApplicationMaster(AM)和Container,AM是在NM中运行一个任务的所有者,并且是在Container中运行的,Container就像是docker中的容器,像一个独立的服务器。
Yarn的工作流程大致是:客户端(可以是多个)对RM进行作业提交,RM给NM分配资源,NM又在内部给Container分配内存和CPU,使任务在AM上完成。集群中可以运行多个AM,每个NM上还可以有多个Container,这也是并行计算的思想。
MapReduce
两个阶段,Map和Rudece。Map负责并行处理输入数据,Reduce负责对Map的结果进行汇总。
三者的工作关系
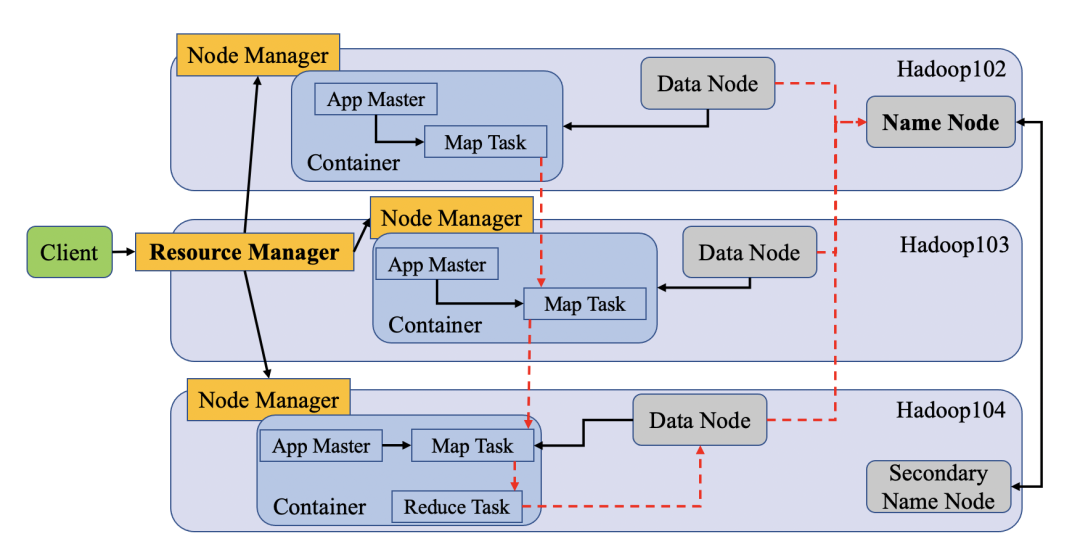
客服端发起请求到ResourceManager(Yarn),RM给NodeManager中的Container分配资源开启Application Master任务,如果资源分配到位则开启任务,在Container中运行MapTask,这一阶段是并行的操作,也就是Map。并行处理完毕后所有的MapTask都要返回一个结果,把MapTask的结果汇总为ReduceTask中,这是Reduce,并写到实际HDFS中存储数据的DataNode中,此时NameNode也会更新,SecondaryNameNode会进行备份。
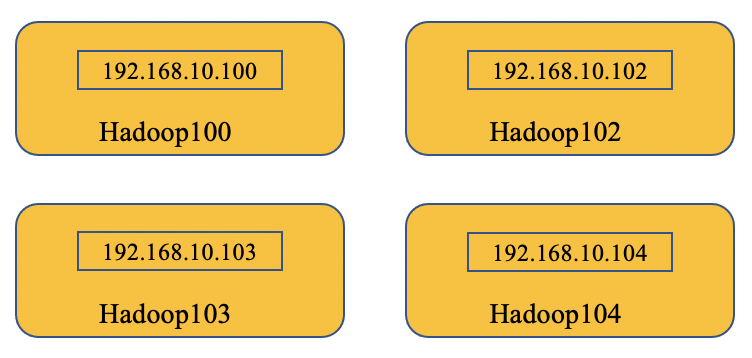
04 Hadoop的集群搭建
[1] https://blog.csdn.net/m0_46413065/article/details/114847016

