





对于 MySQL 事务,可能我们大家都不陌生,事务是对数据库中数据操作保证数据逻辑一致的最小操作单位,一个事务中可能包含多条语句,但这些语句作为一个整体,由事务来保证这个整体的操作要么都成功,要么都失败,不存在部分成功部分失败的情况。
同时事务还具备 ACID 的特性,分别是原子性(Atomicity),一致性(Consistency),隔离性(Isolation),持久性(Durability)。
原子性: 事务作为一个最小操作单位,事务中的所有 SQL 要么都执行,要么都不执行
一致性: 每个事务都满足数据库的完整性约束,也就是说如果从 A 账户向 B 账户转账,只要 A 账户里面减少了 100 元,那 B 账户里面就一定会增加 100 元。
隔离性: 并发进行的多个事务,各个事务之间的操作对其他事务是相互隔离的。
持久性: 事务在提交之后,对数据的修改是永久的,即时数据库发生故障也不会丢失。
其中隔离性由于多个并发执行的事务同时操作同一条数据时,会带来数据的不一致性,包括脏读,不可重复读,幻读,因此有了不同的隔离级别来针对性的解决这些问题,分别是读未提交,读提交,可重复读,串行化。
读未提交: 一个事物产生的修改,还没提交就已经被其他事物读取到,存在的问题是脏读,不可重复读,幻读。
读提交: 一个事务产生的修改,还没提交时对其他事务不可见,只有提交之后对其他事务才可见,存在的问题是不可重复读,幻读。
可重复读: 事务开启之后,其他事务产生的修改对该事务都不可见,包括未提交和已提交的事务,当然事务本身的修改在当前事务内还是可见的,存在的问题是幻读,不过对于 MySQL InnoDB 引擎引进的行锁和间隙锁,已经可以解决幻读的问题了。
串行化: 数据库中基本上所有事务都是按顺序执行的,只有读和读之间不影响,读和写,写和写都是互斥的,这时后面的事务需要等前面的事务提交之后才能执行。
以上四种隔离级别从低到高,隔离级别越高,意味着性能越低,但数据越安全,所以在日常使用中需要综合各方面需求来选择其中一种,对于 MySQL 默认的隔离级别是可重复读,查看当前隔离级别设置的方式如下:
1show variables like 'transaction_isolation';复制
接下来我们看在特定场景,不同的隔离级别设置下,同一个事务看到的结果是怎样的,这里主要还是看前三种隔离级别,最后一种都串行化了也就不存在并行的事务了。还是以之前写 MySQL 文章最开始的那张表为例,我再贴下表结构和初始化数据:
1create table users
2(
3 id bigint auto_increment primary key,
4 name varchar(32) not null comment '用户名',
5 identity varchar(18) not null comment '身份证号',
6 age int default 0 null comment '年龄',
7 sex tinyint(1) default 0 not null comment '性别 0:男,1:女',
8 birthday date null comment '生日',
9 address varchar(128) default '' not null comment '地址'
10)
11comment '用户表';
12
13INSERT INTO activity.users (id, name, identity, age, sex, birthday, address) VALUES (1, '张三', '362422199401014501', 27, 0, '1994-01-01', '');
14INSERT INTO activity.users (id, name, identity, age, sex, birthday, address) VALUES (2, '李四', '362422199402024502', 27, 0, '1994-02-02', '');
15INSERT INTO activity.users (id, name, identity, age, sex, birthday, address) VALUES (3, '王五', '362422199403034503', 27, 1, '1994-03-03', '');
16INSERT INTO activity.users (id, name, identity, age, sex, birthday, address) VALUES (4, '赵六', '362422199404044504', 27, 1, '1994-04-04', '');
17INSERT INTO activity.users (id, name, identity, age, sex, birthday, address) VALUES (5, '小明', '362422199405054505', 27, 1, '1994-05-05', '');复制
假如说目前有下面两个事务在操作修改数据,然后事务之间的执行顺序如下:
| 事务一 | 事务二 |
|---|---|
| ① begin; select * from users where id = 1; | ① begin; select * from users where id = 1; |
| ② update users set age = 28 where id = 1; | |
| ② select * from users where id = 1;# T1 | |
| ③ commit; | |
| ③ select * from users where id = 1;# T2 | |
| ④ commit; | |
| ⑤ select * from users where id = 1;# T3 |
从表格中可以看到,事务一和事务二开启之后都分别查询了 id = 1 的数据,这时查询出来的是张三的那条数据,并且年龄都是 27,接下来事务一将张三的年龄改成 28,这时还没提交,然后事务二再次查询了这条数据,此时记为 T1,紧接着事务一提交,事务二又查询了 id = 1 的数据,此时记为 T2,最后事务二自己提交事务,提交后又查询了一次 id = 1 的数据,此时记为 T3,那么在不同的隔离级别下,事务二在 T1,T2,T3 这三个时刻查询出来张三的年龄分别是多少呢,我们一个一个来分析:
读未提交(Read Uncommitted):
读未提交,顾名思义,一个事务可以读到其他事务未提交的数据。上面事务二的 T1,T2,T3 时刻都是在事务一更新数据之后查询的,因此 T1,T2,T3 时刻查出来张三的年龄都是 28,不管事务一的更新所在事务是否已经提交。
读提交(Read Committed)
读提交,意思也很明白了,一个事务只能读到其他事务已经提交的数据。上面事务二 T1 时刻事务一还没提交,它对张三年龄的更新对因此 T1 是不可见的,T1 时刻查出来张三的年龄还是 27,T2 和 T3 时刻事务一已经提交,因此 T2 和 T3 时刻事务二查询出来张三的年龄是 28。
可重复读(Repeatable Read)
事务开启之后,在整个事务内读到的数据都是一样的,其他事物的修改对当前事务不影响,T1 时刻事务一还没提交,肯定不可见,这时查出来张三的年龄还是 27, T2 时刻事务一已经提交,但其他事物的修改对当前事务不影响,这里查出来张三的年龄也是 27,T3时刻事务一已经提交,同时事务二本身也已经提交了,相当于再启动另一个事务继续查询,这时是可以看到事务一的修改,因此 T3 时刻查出来张三的年龄是 28。
也许你对上面这些东西已经比较熟悉了,无非就是事务的 ACID 特性以及隔离性中的不同隔离级别,上面我们也用一个实际的例子来说明了三种隔离级别的不同情况,这时如果我问你事务中的隔离性是如何实现的呢?怎么做到在不同隔离级别下事务之间数据的可见性也不同?
其实是在事务开启时,会为整个事务创建一个一致性读视图,这个视图持续到事务的结束,在整个事务的执行期间所看到的数据都依赖于事务开启时创建的一致性读视图(consisitent read view)。当然一致性读视图并不是实际存在的物理结构,它只是用来定义事务执行期间能看到哪些数据。如何定义呢?
这里需要先介绍一个日志 undo log,我们之前说在更新的时候会写入 redo log 和 binlog,而 undo log 你可以认为是在写入 redo log 的同时记录的一个日志。redo log 是重做日志,记录的是数据页的物理修改,也就是只能将数据恢复到最后一次提交的状态,并且是循环写的;undo log 则是回滚日志,一般是逻辑日志,根据每行记录进行记录日志,主要用来回滚行记录到之前的版本。
比如说在三个不同事务里依次将张三的年龄依次更新成 28,29,30,SQL 如下:
1update users set age = 28 where name = '张三'; #① 事务一
2
3update users set age = 29 where name = '张三'; #② 事务二
4
5update users set age = 30 where name = '张三'; #③ 事务三复制
上面这三个更新事务分别对应着数据库中三个数据版本,下面通过一个图来详细说明三个事务更新后记录的 undo log。
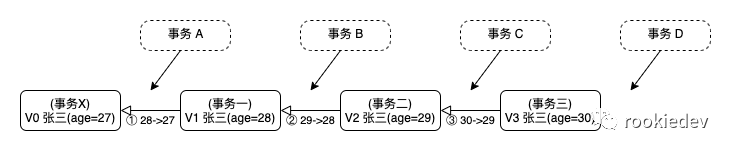
从上面图中可以看到,三个事务更新后会记录相应的 undo log 用来回滚到上一个版本,也就是对应几个箭头的部分,那么在查询张三的年龄的时候,不同时刻启动的事务查询得到的年龄是不一样的,但数据库中数据肯定已经是最新值了,只不过根据事务的隔离级别不同,需要通过 undo log 回滚到对应的可见版本,这里举几个例子:
从图中可以看刚开始张三的那条数据年龄是 27,对应的更新事务是 X,目前最新的数据年龄值是 30,对应的更新事务是事务三:
1.如果是在事务一启动之前开启事务 A 来查询,在事务 A 启动的时刻创建了一个一致性读视图,后面的更改对我都不可见,我只认我创建的视图中能看到的数据,后面在事务中查询看到的数据都依赖于视图中能看到的数据,虽然读到最新的值是 age=30,但是不可见,通过 undo log 回滚到上一个版本 age=29,同样不可见,直到回滚到 age = 27,可见。
2.如果是在事务一启动之后事务二启动之前开启事务 B 来查询,同样启动时创建一致性读视图,接下来在事务中查询读到数据库中最新的值是 age=30,不可见,通过 undo log 回滚到上一个版本 age=29,同样不可见,再往前回滚到上一个版本 age = 28,可见。
3.对于在事务二和事务三之间启动事务 C 查询,流程也是一样的,而在事务三之后启动事务 D,那么一致性读视图里面的最新值就是数据库中的最新值,不用回滚,直接可见。
从上面例子可以看出,一条记录在数据库中就像存在多个版本一样,也就是我们经常听到的多版本并发控制(MVCC),不同时刻启动的事务看到的是不同版本的数据,但要注意,并不是说这多个版本的数据是物理结构上存在的,它们都是需要拿到当前的最新值再通过 undo log 进行回滚到相应的版本。
那么就会引出一个问题了,对于那种长事务,往往数据已经更新了很多个版本了,但在这个事务里面依然需要通过 undo log 一步一步回滚到可见的那个版本,也就是说在事务提交前这些 undo log 就没办法进行删除,需要一直保留,直到没有对应的事务再需要这些日志的时候才能够删除,如果存在很多的长事务,就可能导致这些 undo log 越来越大,因此在我们日常的开发中,我们需要尽量的去避免使用长事务,长事务不仅会造成回滚日志会越来越大,还会导致锁资源的占用问题,这个后面在分析锁的时候再说。
上面也说了事务的很多东西了,事务的基本定义,ACID 特性,以及隔离性是如何实现的,然后引出了 undo log 这个新的日志,但 undo log 只是我们实现隔离性的一个辅助工具,能够让我们回滚到之前的数据版本,那在一个事务里面是怎么去判定具体要回滚到哪个版本,换句话说到底哪个版本的数据才是我可见的?这个我们下一篇文章将会详细说明。
推荐阅读
