




前言
前几天总结了Prometheus+Alertmanager告警与钉钉的对接,近日经过摸索,查找网上资料,得出此文章。
Prometheus Alertmanager告警发送到企业微信和微信主要需要这么几个步骤:
- 获取企业微信后台相关消息,企业ID,部门ID,AgentId,Secret;
- Alertmanager服务配置和微信告警模板配置;
- Prometheus服务配置以及Alertmanager告警规则配置;
要是企业微信能收到告警消息了,再通过微信插件就能同步给微信了。
获取企业微信消息
访问企业微信官网:https://work.weixin.qq.com/ 企业微信可以供我们注册企业,目前限制不多,人人都可以注册,也不需要企业认证。
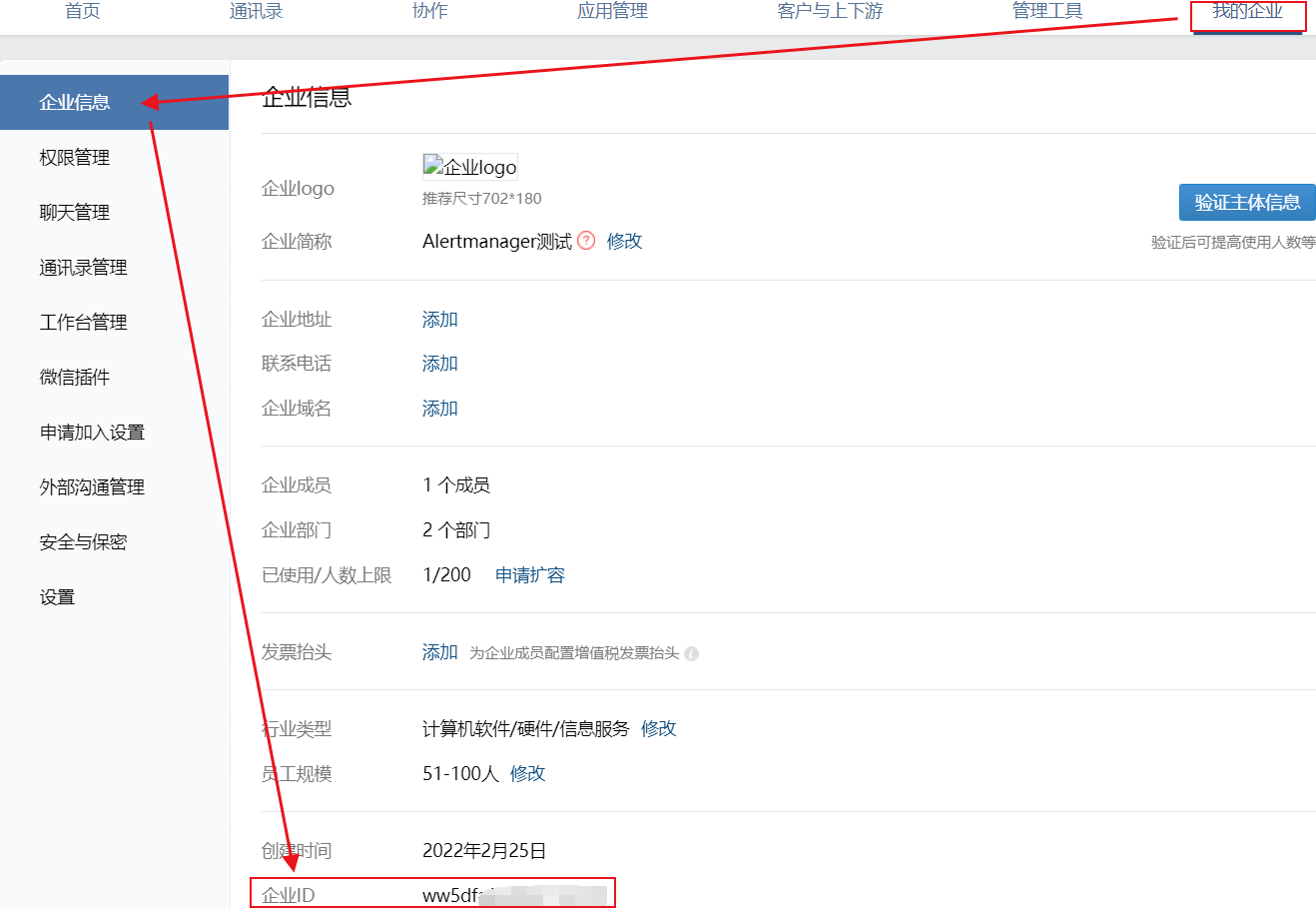
企业ID
注册完成之后,通过企业微信官网登录后台管理,在【我的企业】的企业信息里面,获取到Alertmanager服务配置需用到的第一个配置:企业ID
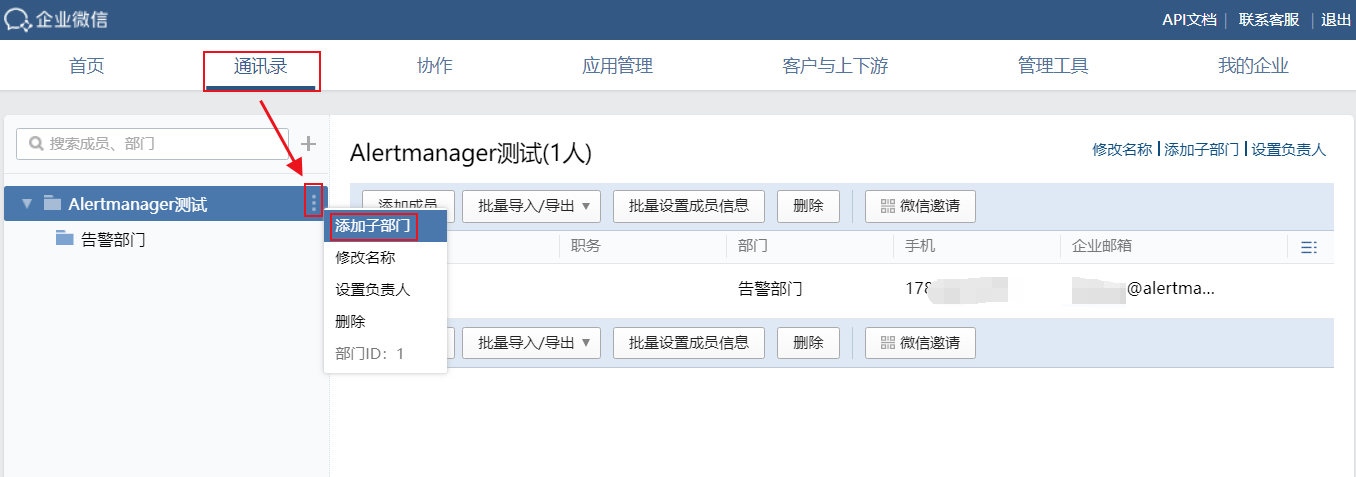
部门ID
在【通讯录】中,添加一个子部门,用于接收告警信息,后面把人加到该部门,部门内的人就能接收到告警信息了。
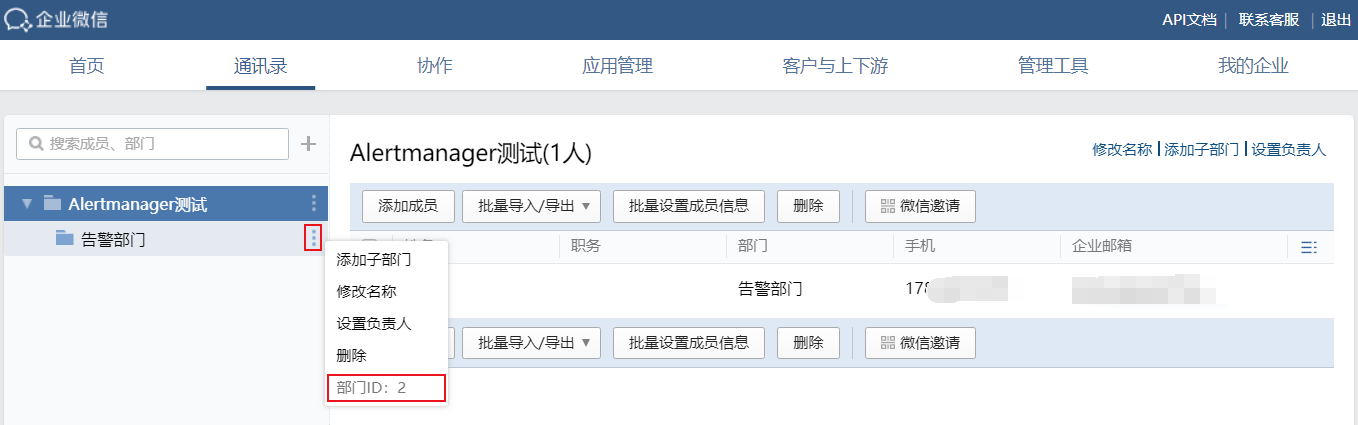
子部门添加完成之后就能看到该部门ID了
告警AgentId和Secret
告警AgentId和Secret的获取是需要在企业微信后台,在【应用管理】中,创建应用后才能够获得的。
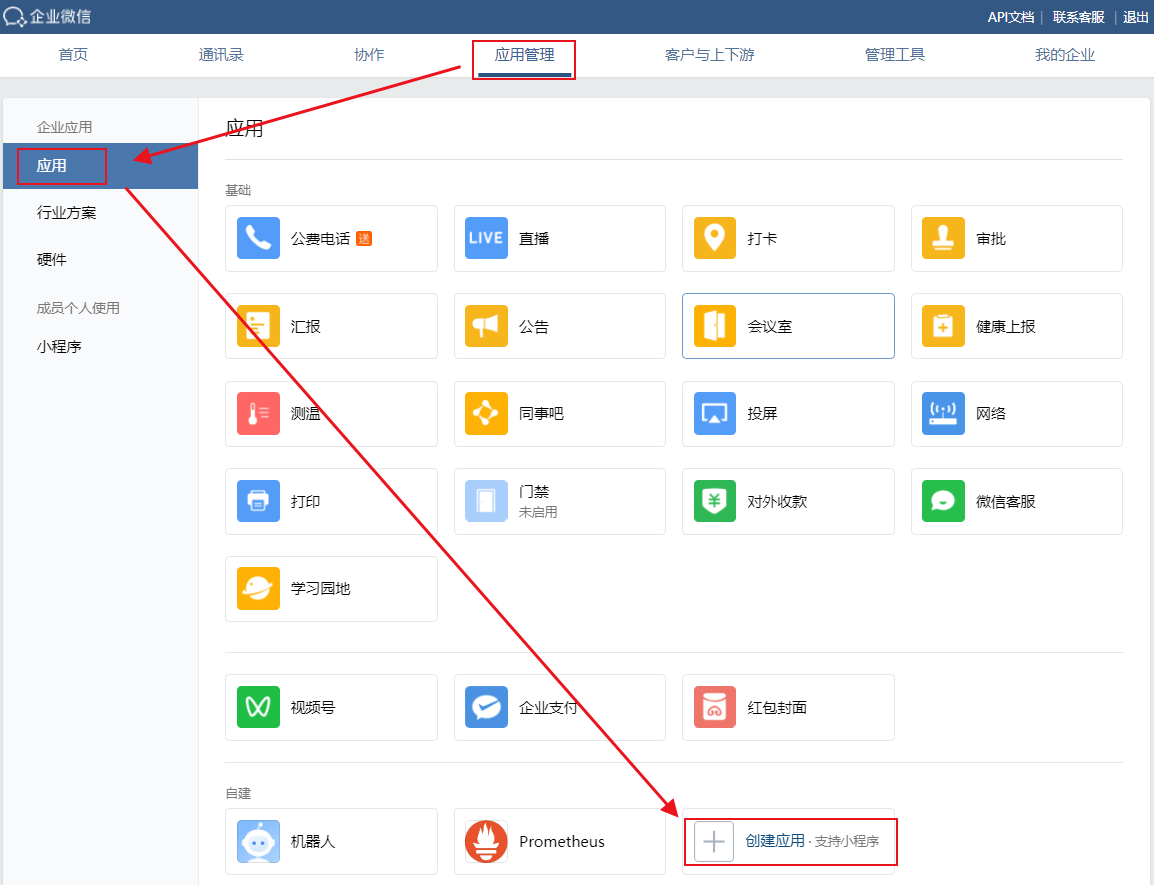
填写相关消息,最后点击创建应用。
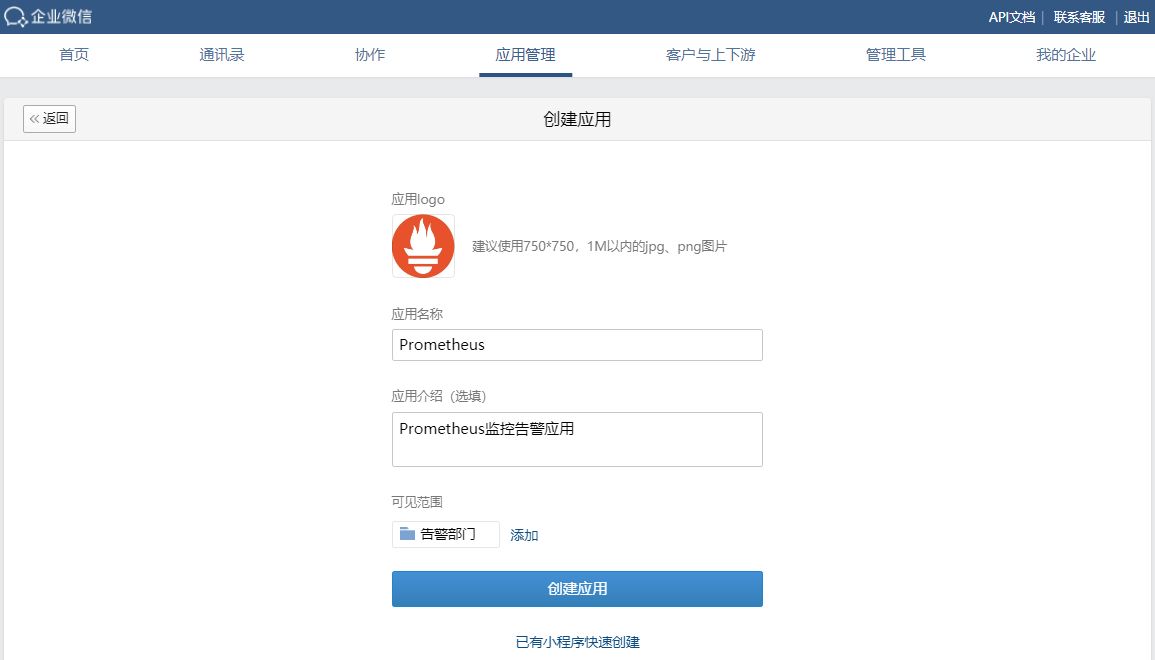
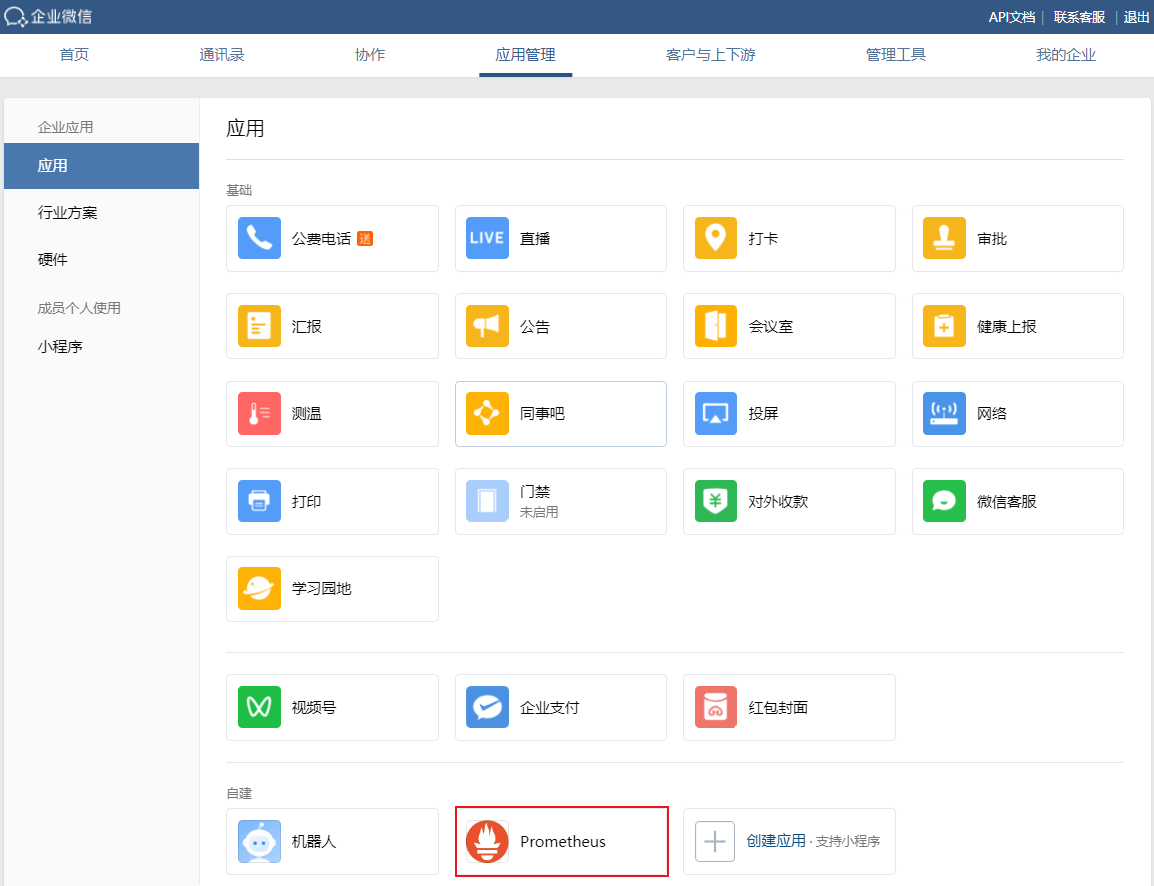
点击刚才创建好的应用Prometheus,就可以看到AgentId和Secret
Secret点击查看即可获取
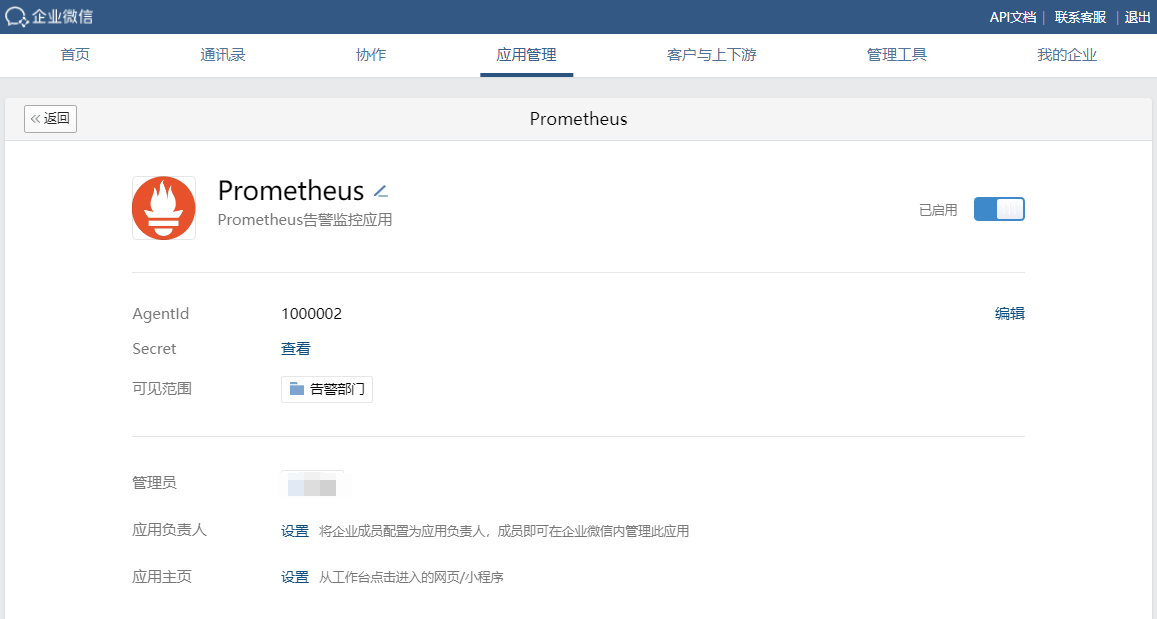
通过以上步骤,我们就获取到配置Alertmanager的全部信息,包括:企业ID,接收告警的部门ID,AgentId和Secret,共四条消息。
Alertmanager配置
alertmanager.yml
alertmanager.yml叫做Alertmanager的配置文件,其模板都大同小异,此处为企业微信的模板。
global:
resolve_timeout: 1m # 每1分钟检测一次是否恢复
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' # 企业微信的api_url,无需修改
wechat_api_corp_id: 'xxxxxxxxxx' # 企业微信中企业ID
wechat_api_secret: 'xxxxxxxxxxxxx' # 企业微信中,Prometheus应用的Secret
templates:
- '/software/alertmanager-0.23.0.linux-amd64/*.tmpl' # Alertmanager微信告警模板
route:
receiver: 'wechat'
group_by: ['env','instance','type','group','job','alertname']
group_wait: 10s # 初次发送告警延时
group_interval: 10s # 距离第一次发送告警,等待多久再次发送告警
repeat_interval: 5m # 告警重发时间
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
message: '{{ template "wechat.default.message" . }}'
to_party: '2' # 企业微信中创建的接收告警的告警部门ID
agent_id: '1000002' # 企业微信中创建应用的AgentId
api_secret: 'xxxxxxxxxxxxx' # 企业微信中,Prometheus应用的Secret
复制wechat.tmpl
alertmanager.yml中templates项以配置的就是此文件,复制内容即可使用
{{ define "wechat.default.message" }} {{- if gt (len .Alerts.Firing) 0 -}} {{- range $index, $alert := .Alerts -}} {{- if eq $index 0 }} ========= 监控报警 ========= 告警状态:{{ .Status }} 告警级别:{{ .Labels.severity }} 告警类型:{{ $alert.Labels.alertname }} 故障主机: {{ $alert.Labels.instance }} 告警主题: {{ $alert.Annotations.summary }} 告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}; 触发阀值:{{ .Annotations.value }} 故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} ========= = end = ========= {{- end }} {{- end }} {{- end }} {{- if gt (len .Alerts.Resolved) 0 -}} {{- range $index, $alert := .Alerts -}} {{- if eq $index 0 }} ========= 异常恢复 ========= 告警类型:{{ .Labels.alertname }} 告警状态:{{ .Status }} 告警主题: {{ $alert.Annotations.summary }} 告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}; 故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} 恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} {{- if gt (len $alert.Labels.instance) 0 }} 实例信息: {{ $alert.Labels.instance }} {{- end }} ========= = end = ========= {{- end }} {{- end }} {{- end }} {{- end }}复制
Prometheus配置
Prometheus的配置主要由prometheus.yml主文件和rule.yml告警规则文件组成:
prometheus.yml
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/rule.yml"
复制rule.yml
告警规则文件罗列了CPU,服务状态,内存,磁盘的告警规则
groups:
# 报警组组名称
- name: node_rule
#报警组规则
rules:
#告警名称,需唯一
- alert: Server Status
#promQL表达式
expr: up == 0
#满足此表达式持续时间超过for规定的时间才会触发此报警
for: 10s
labels:
#严重级别
severity: critical
annotations:
#发出的告警标题
summary: "实例 {{ $labels.instance }} 关闭"
#发出的告警内容
description: "系统 {{ $labels.instance }}: 实例关闭"
ip: "{{ $labels.ip }}"
- alert: Memory Usage
expr: 100 - round(node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100) > 80
for: 1m
labels:
severity: error
annotations:
summary: "实例 {{ $labels.instance }} 内存使用率过高"
description: "实例内存使用率超过 80% (当前值为: {{ $value }}%)"
ip: "{{ $labels.ip }}"
- alert: CPU Usage
expr: 100 - round(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 80
for: 1m
labels:
severity: error
annotations:
summary: "实例 {{ $labels.instance }} CPU使用率过高"
description: "实例CPU使用率超过 80% (当前值为: {{ $value }}%)"
ip: "{{ $labels.ip }}"
- alert: Disk Usage
expr: 100 - round(node_filesystem_free_bytes{fstype=~"ext3|ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}
*100) > 80
for: 1m
labels:
severity: error
annotations:
summary: "实例 {{ $labels.instance }} 磁盘使用率过高"
description: "实例磁盘使用率超过 80% (当前值为: {{ $value }}%)"
ip: "{{ $labels.ip }}"
复制启动Prometheus和Alertmanager服务
nohup ./prometheus --config.file=/software/prometheus-2.33.3.linux-amd64/etc/prometheus.yml --storage.tsdb.retention.time=90d --log.level=debug > /software/prometheus-2.33.3.linux-amd64/prometheus.log 2>&1 & #启动prometheus软件,指定配置文件设置数据保留时间为90天设置日志级别 ss -alntup | grep -i 9090 #确认9090端口是否启动,此时命令应该有输出。 nohup ./alertmanager --config.file=/software/alertmanager/alertmanager.yml --cluster.advertise-address=0.0.0.0:9093 --log.level=debug > /software/alertmanager/alertmanager.log 2>&1 & #启动alertmanager软件指定配置文件设置监听为0.0.0.0:9093设置日志级别 ss -alntup | grep -i 9093 #确认9093端口是否启动,此时命令应该有输出。复制
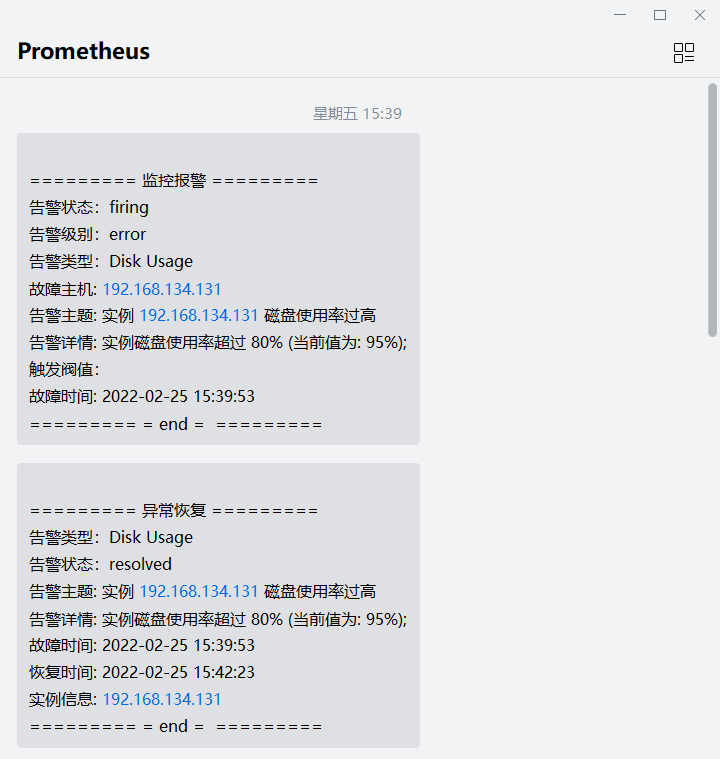
接收的告警消息及恢复消息
此图为企业微信接收告警图片
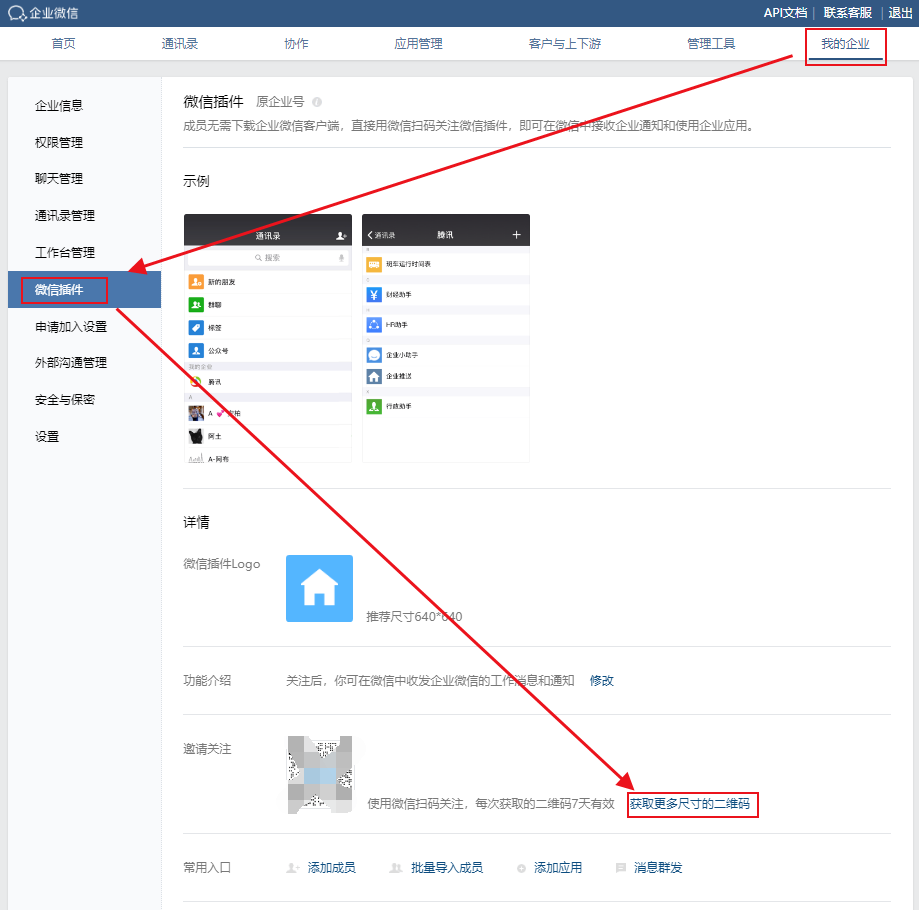
微信目前能通过和企业微信关联接收企业微信消息,微信扫描二维码关注方式关联即可。
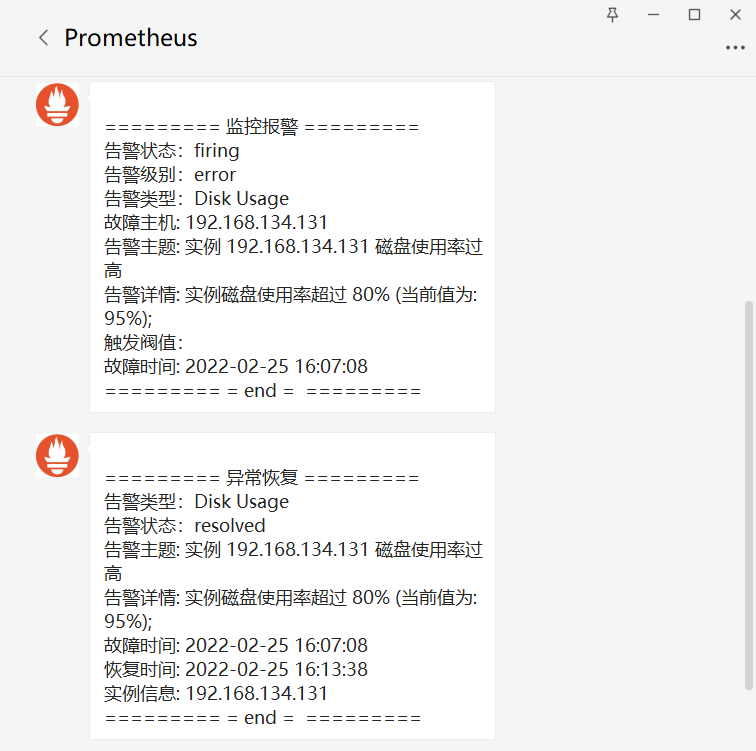
此图为微信接收告警图片
小结
Alertmanager的告警推送给企业微信是通过企业ID,部门ID,AgentId,Secret这四个消息来辨别接收者。消息是通过企业注册,企业微信部门和自定义应用来得到的,告警推送和告警模板都由Alertmanager这边控制。获取服务器消息和告警规则是Prometheus来操控。企业微信和微信能互相接收发送消息通过微信插件来完成。
评论

 0 点赞 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞
0 点赞


