




6 SQL语句优化
MPP数据库对SQL语句的内部优化机制
第一,分布表与复制表进行连接查询,MPP数据库会进行本地化运算。如下图所示:
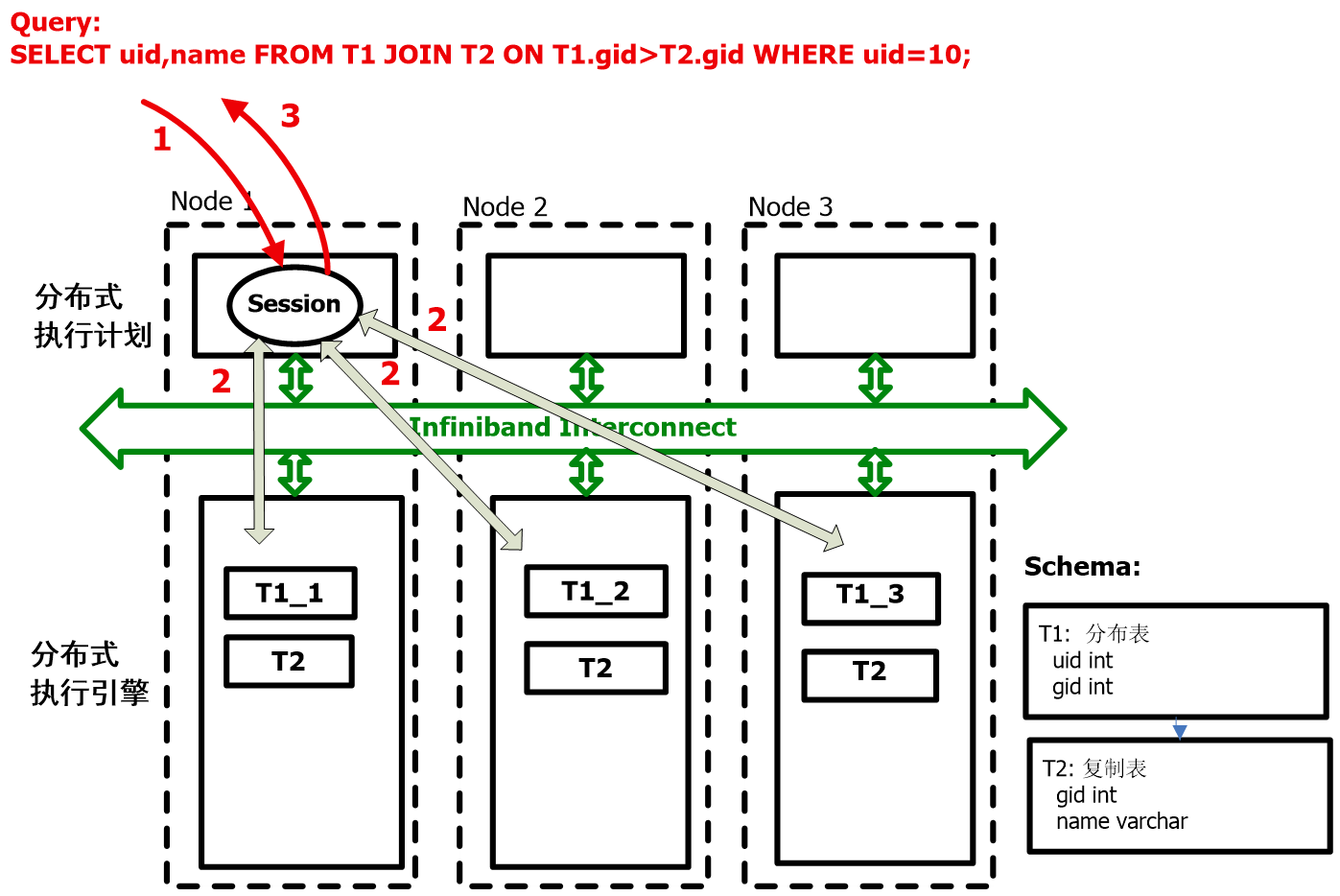
图:内部优化机制之分布表与复制表JOIN
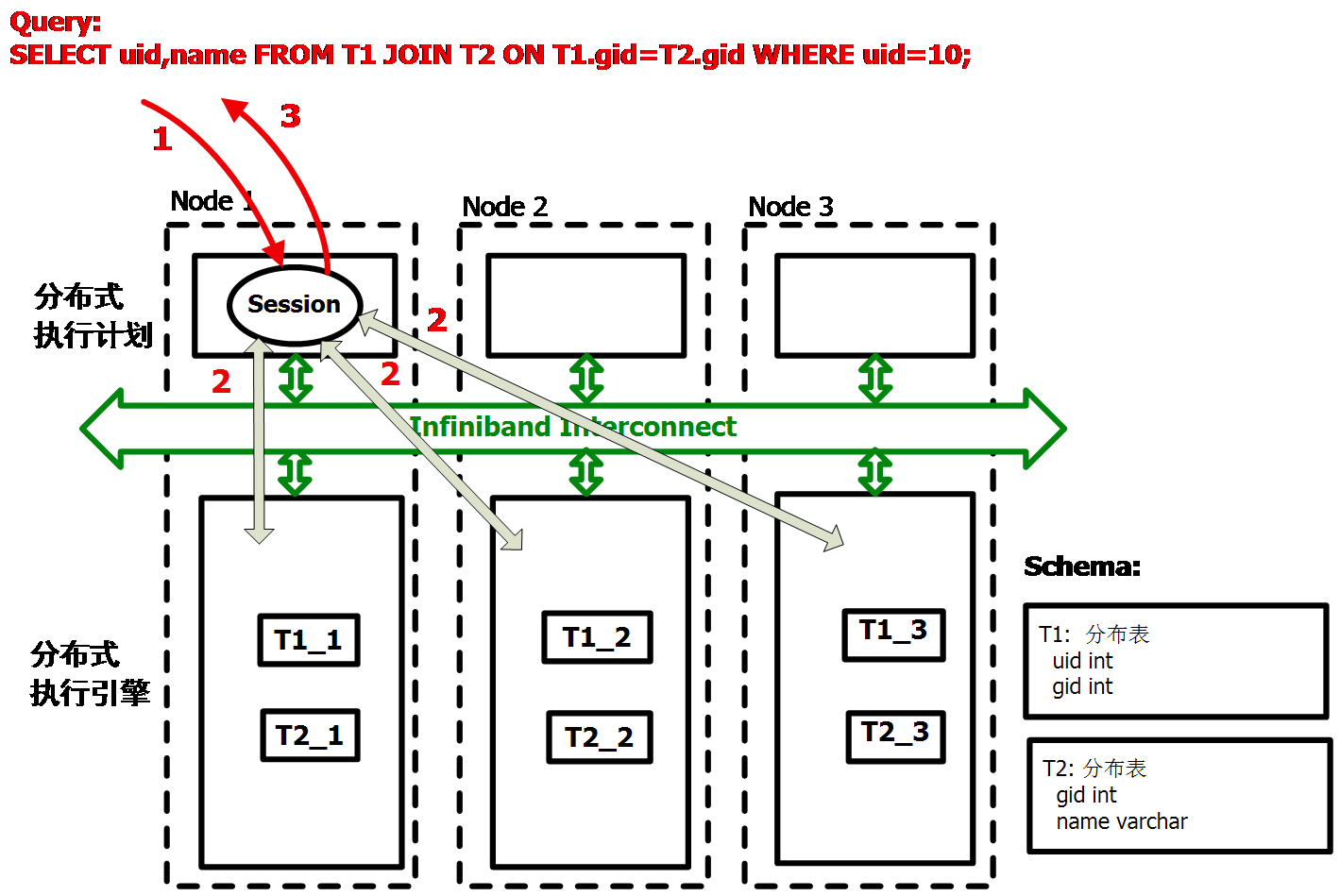
第二,静态Hash Join会进行本地化运算。如下图所示:
第三,当分布表与分布表进行连接查询时,会将当中较小的表转换成复制表,这时会进行跨节点数据访问。如下图所示:
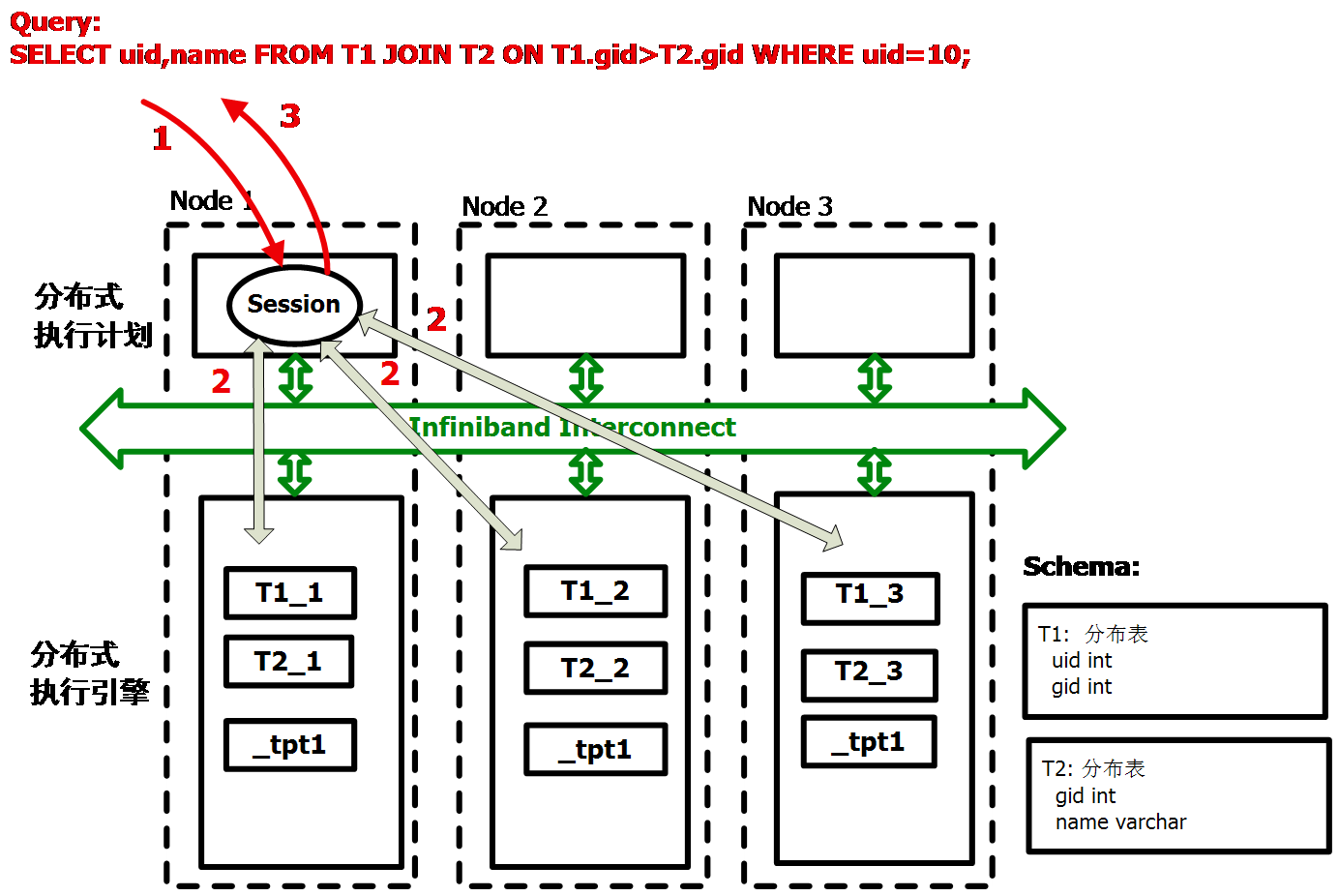
第四,当分布表与分布表进行连接查询时,如果两个分布表都很大,就会发生Hash Join,这时会进行跨节点数据访问。如下图所示:
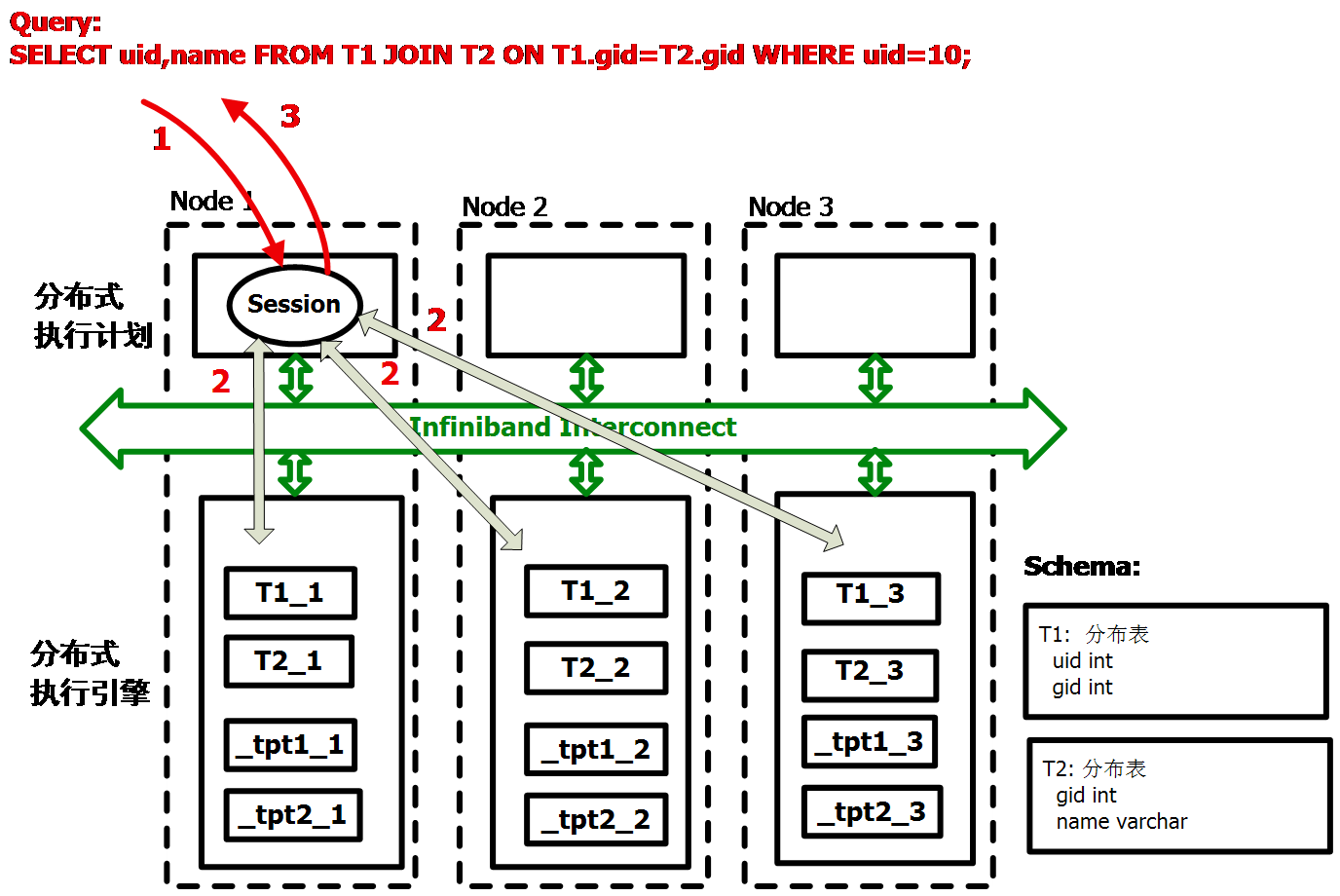
SQL语句优化实例总结
DML语句优化
u 关联优化
第一,JOIN关联优化策略。
逐个排查右表,对于右表是分布表且破坏hash分布的,如果数据量小,直接修改为复制表,避免将大表进行拉表操作;如果数据量大(1亿以上的),通过调整gcluster_hash_redistribute_join_optimize参数进行验证,参数说明如下:
set
gcluster_hash_redistribute_join_optimize=0|1|2
0 -- 拉复制表
1 -- 重分布
2 -- 自动评估。根据数据量,左右表行数接近使用重分布,如果差距大,则小表拉复制表。
当遇到 left join 语句时,评估右表是否建为复制的原则如下:
(1)如果右表的字段不大于10个,且记录数不大于5000万行,则右表创建为复制表;
(2)如果右表字段数大于10个,且记录数不大于1000万,则右表创建为复制表;
(3)其它情况,右表创建为分布表,且必须指定Hash列。条件(1)和(2)满足一个,则须把右表创建为复制表。
第二,关联顺序优化。由于GCluster的优化器不会调整LEFT JOIN语句的顺序,而用户语句的JOIN顺序可能不是最优,导致查询性能较低。这种类型的SQL语句一般有如下特征:
(1)语句包含多个LEFT JOIN。
(2)多个LEFT JOIN的ON条件均为t1.colX
= tn.colX。
如:select x1.* from x1
left join x2 on
x1.many_duplicate_value = x2.many_duplicate_value
left join x3 on
x1.no_duplicate_value = x3.no_duplicate_value
left join x4 on x1.hash_col =
x4.hash_col;
对于满足上述特征的SQL语句,即LEFT JOIN的右表,一些表可以直接与左表形成Hash JOIN关系,一些表可能会导致左表发生膨胀。这时,可以考虑如下的优化方法:
(1)让形成Hash JOIN关系的LEFT JOIN先执行,避免拉表。例如SQL特征中描述的语句,因为left join x4 on x1.hash_col =
x4.hash_col是Hash分布式JOIN,因此可以提到最前面,直接分布式执行。
(2)让膨胀率小的LEFT JOIN先执行,减小拉表数据量。
(3)如果参与JOIN条件的列的值的重复度较高,则很可能会造成LEFT JOIN结果发生膨胀。一般来说,使用主键列参与的JOIN条件,膨胀率是最小的;而重复值越多的列,膨胀率就越可能高。通过这种调整,避免对膨胀后的数据拉表,减小了拉表数据量。
下面看一个具体的例子:
select x1.* from x1
left join x2 on
x1.many_duplicate_value = x2.many_duplicate_value
left join x3 on
x1.no_duplicate_value = x3.no_duplicate_value
left join x4 on x1.hash_col =
x4.hash_col;
改写后语句
select x1.* from x1
left join x4 on x1.hash_col =
x4.hash_col;
left join x3 on
x1.no_duplicate_value = x3.no_duplicate_value
left join x2 on x1.many_duplicate_value
= x2.many_duplicate_value
说明:因x1.hash_col =
x4.hash_col使用Hash分布列,因此left
join x4调整到第1个位置;因x1.no_duplicate_value
= x3.no_duplicate_value的膨胀率比x1.many_duplicate_value =
x2.many_duplicate_value的膨胀率低,因此把left join x3调整到left join x2之前。
第三,关联条件优化。当前版本的GNode中,LEFT JOIN的ON条件中的右表单表条件会在JOIN之后执行,尤其当LEFT JOIN的右表是大表时,会导致参与JOIN的数据量过大,增加JOIN耗时。
可以通过改写,把右表单表过滤放在一个独立的子查询中,保证右表的过滤在JOIN前执行,达到优化查询性能的目的。
示例语句如下:
select x1.id2, x2.id2, x2.id3
from x1 left join x2 on x1.id2 = x2.id2 and x2.id3 = 301;
改写后语句
select x1.id2, x.id2, x.id3
from x1 left join (select x2.id2, x2.id3 from x2 where x2.id3 = 301) x;
u 查询条件优化
第一,查询条件不要使用函数。
提倡where条件中的列能不加函数运算就不加函数,因加函数会造成智能索引失效,sql性能降低。
例如:某现场原始sql为:where substr(product_no, 2, 1) in ('3', '4', '5', '8'),智能索引失效,性能非常低。
改写为:where (product_no
like '13%' or product_no like '14%' or product_no like '15%' or product_no like
'18%')',智能索引还能用的上。
第二,避免操作字段表达式后进行比较。
(1)保证使用智能索引且最有效的方法是字段与常量表达式直接操作的形式(rownumtag>=100*10)。改成(rownumtag+1>=100*10+1)就无法使用智能索引。
(2)保证一边是字段,另一边是常量表达式(常量当然也可以),常量表达式无论多么复杂都没有问题,因为它只需要计算一遍。
(3)表达式与常量进行比较的条件不能用智能索引。例如:
select ... from ... where
ceil(rownumtag / ceil(to_number('100'))) ='10' ;
改为:select ... from ...
where rownumtag>100*9 and
rownumtag<=100*10;
u union all问题
针对union all的场景,总体思想是建立临时表将各个sql结果放入临时表中,最后查询临时表统一输出。
减少集群层临时表,变成节点即可运行,2个union的条件加在一起,就是不要条件即可。然后再将不必要的外部嵌套去掉,性能可以显著提升。
u 减少嵌套
第一,将group部分移到内部,性能会提升在2-4倍。
第二,将嵌套查询改成一个查询。
第三,将外部条件移到内部,将只会向1个节点发送SQL。
第四,将嵌套sql改为一个join连接。
u update更新操作
修改多条update为关联update时,注意将非更新表放在update的前面。
例如:
update t1, t2 set t2.col = 1
where t1.id = t2.id;
如上语句,t1是关联表,t2是更新表,update后的JOIN列表中,要将关联表t1写在更新表t2的前面,有助于GCluster层减少拉表动作。即不要写成下面的形式:
update t2, t1 set t2.col = 10
where t1.id = t2.id;
u 循环insert values改成一个insert
select
将循环执行insert values的场景改为一个insert select语句,这样避免多次提交,性能提升很高。
u 使用行存列,减少节点IO
涉及到的统计列,超过15-20%时,用行存列性能更好,包括聚合列和分组列等。
说明:
1、建立行存列会冗余一倍空间。
2、加载性能也会下降。
u MAX OVER函数的改写
例1:
select
min(kpi_value) over (partition
by a.kpi_id,a.brand_id,a.city_id order by floor( days(a.kpi_date) ) range
between 1 preceding and 1 preceding ) as last_value
from a;
改写为:
select
(select min(kpi_value) from
kpi_values aa where aa.kpi_id = a.kpi_id and aa.brand_id = a.brand_id and
aa.city_id = a.city_id and aa.kpi_date = date_sub(a.kpi_date, INTERVAL 1 DAY))
as last_value from a order by a.kpi_id,a.brand_id,a.city_id,a.kpi_date
例2
select max(rn) over
(PARTITION by product_no,imei order by first_time) rn from a;
改写为:
select
(select max(rn) from a aa where
aa.product_no = a.product_no and aa.imei=a.imei and aa.first_time <=
a.first_time)
from a order by a.product_no,a.imei,a.first_time;
DDL语句优化
对于集群层主要指合理设定表的分布属性,以及合理选择Hash分布列。对于GNode层主要指压缩参数。
u 建表注意事项
当我们用create table as
select 建立一些表时,需要注意如下:
例如:create table t2 as
select * from t1 where 1=2;
这个语句无法创建出Hash列,即使表t1中有Hash列,表t2也不会有Hash列,修改为 create table t2 like t1 则会在t2中创建出与t1相同的Hash列。
但是,Like关键字创建的表不能另行指定Hash列,也不能指定为复制表或者NoCopy表,这时还需要使用上面的 create table ... as select ... 语句,另外where
1=2还需要进行运算,全部修改为limit 0具体如下:
create table t2 distributed by
('fx') as select * from t1 limit 0;
create table t2 replicated as
select * from t1 limit 0;
create table t2 distributed by
('fx') nocopies as select * from t1 limit 0;
u 复制表优化方案
当遇到多表关联的时候,尤其是主表外连接多个右表,其中关联字段为右表的hash键的时候,这时候为防止破坏hash分布计算,可根据右表数据量的大小将其创建为复制表。
举例:
Select ………….
from rep.statcmain a
-- 80989472 hash列policyno
inner join
rep.statdcompanylevel d --25887 replicate
on a.comcode = d.comcode
left join rep.statdagent l
--86485 replicate
on a.agentcode = l.agentcode
left join
rep.temp_prpcengagenew pr --164205
hash列policyno
on a.policyno = prpcengagenew.policyno
left join
rep.statdcarmodel b --178758 replicate
on a.modelcode = b.modelcode
left join
rep_dev.odsbi_prpmotorcade i --288949
replicate
on a.contractno = i.contractno
left join ……….
其中,主表rep.statcmain数据量80989472,hash列policyno,但外连接表rep.statdcompanylevel,rep.statdagent,rep.statdcarmodel,rep_dev.odsbi_prpmotorcade的关联字段为非hash键,将这些表创建为复制表,可以防止拉表做到一步下发。
u 创建nocopies表
对于数据加工处理,应该尽量在小表内进行,对于局部的数据加工处理为了不影响基础大表,应建立临时表作为工作空间,并使用no copies表保存临时表。
案例:北京阳光保险项目中涉及到一张mid.dim_statlastcar_basic,数据量为43424510,数据量大,后续存储过程中很多依赖于这张表,所以将该表创建为nocopies表,这样能在节点上不保存备份数据,能适当的减小资源利用压力。但需要注意的是,后续以mid.dim_statlastcar_basic为源表创建的新表都要创建为nocopies才不会出现拉表的情况。
u 建立物理表
关联查询中涉及隐式表且隐式表是一个Union
All语句的情况,优化方法是把隐式表创建成一个物理表,之后把Union All部分换成多个Insert Into ... Select语句。
需要注意两点:
(1)新建的物理表须设置为NoCopy和nolock表,且在不能确切评估数据量的情况下必须指定Hash列,Hash列的选择可以参考原始语句的Join条件;
(2)Insert into...select语句中Select部分不能是Union All语句,而要把insert into ... select ...
union all select ...改为多个insert into ... select语句。
