




问题
Alice 和 Bob 在一家公司担任客户支持,每次他们处理客户的询问时,他们采取的任何行动都会记录在某种数据集中。
他们的经理查理必须制定人力规划计划,以找出他们每个月需要多少人来回答客户的询问。因此,他需要找出 Alice 和 Bob 处理客户询问的 实际时间 。但是查理的眼睛在数据上发现了一些奇怪的东西,由于公司拥有的技术,Alice 和 Bob 可以 同时处理 3 个查询 ,导致捕获的数据很奇怪:
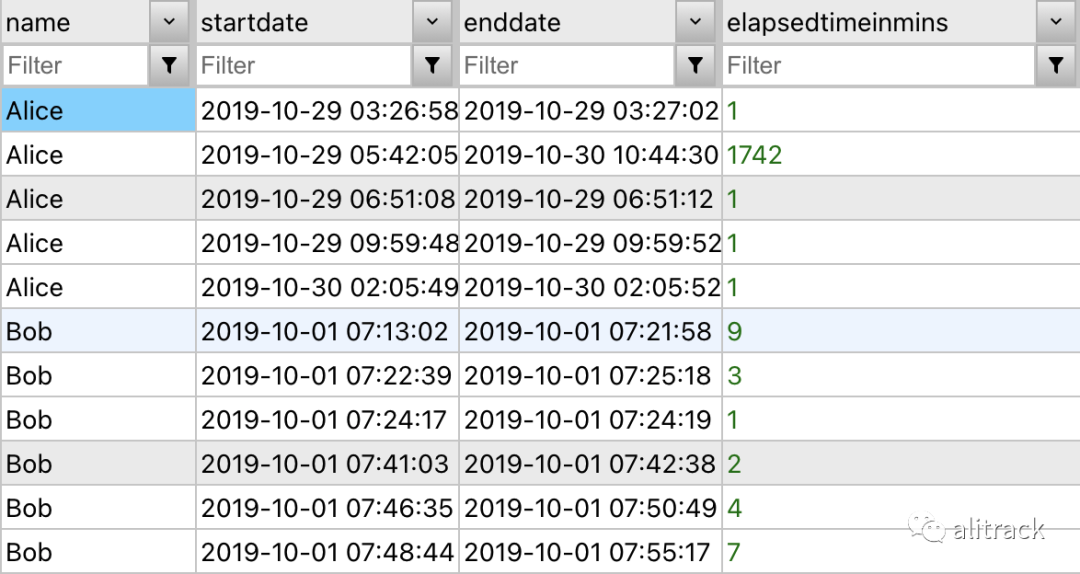
SUM()ElapsedTimeInMins 列来找出 Alice 和 Bob 用于解决客户查询的时间,结果将无法反映他们实际花费的时间,因为他们每个人一次可以处理 3 个查询。因此,为了了解他们实际花费了多少时间在处理客户上,Charlie 必须将此问题视为间隙和孤岛问题,以对数据进行相应的分组。
间隙和孤岛是 SQL 中的一个经典问题,涉及识别序列中缺失值的范围和现有值的范围。目标是识别连续数据序列组(孤岛)和序列缺失的数据组(间隙)。
间隙和孤岛问题的真实示例包括可用性报告、非活动期和活动报告等。
我最近在我的数据集中遇到了这组特殊的问题,但有一个有趣的转折,因为数据中每一行的日期范围可能是完全离散的、完全封闭的,或者它们可能在两端相互重叠,所以:
Charlie 有什么方法可以确定具有这些重叠日期范围的数据差距和孤岛?
重叠的日期范围
首先我们从之前的样本数据开始,全面掌握查理目前面临的情况。如前所述,问题的特点是每一行的日期范围可能是完全离散的、完全封闭的,或者它们可能在任一端相互重叠:
DROP TABLE IF EXISTS OverlappingDateRanges;
CREATE TABLE OverlappingDateRanges
(Name varchar(50),
StartDate DATETIME,
EndDate DATETIME,
ElapsedTimeInMins INT);
INSERT INTO OverlappingDateRanges
VALUE ('Alice', '2019-10-29 03:26:58', '2019-10-29 03:27:02', 1) ,
('Alice', '2019-10-29 05:42:05', '2019-10-30 10:44:30', 1742) ,
('Alice', '2019-10-29 06:51:08', '2019-10-29 06:51:12', 1) ,
('Alice', '2019-10-29 09:59:48', '2019-10-29 09:59:52', 1) ,
('Alice', '2019-10-30 02:05:49', '2019-10-30 02:05:52', 1) ,
('Bob', '2019-10-01 07:13:02', '2019-10-01 07:21:58', 9) ,
('Bob', '2019-10-01 07:22:39', '2019-10-01 07:25:18', 3) ,
('Bob', '2019-10-01 07:24:17', '2019-10-01 07:24:19', 1) ,
('Bob', '2019-10-01 07:41:03', '2019-10-01 07:42:38', 2) ,
('Bob', '2019-10-01 07:46:35', '2019-10-01 07:50:49', 4) ,
('Bob', '2019-10-01 07:48:44', '2019-10-01 07:55:17', 7) ;
有趣的是,虽然某些行的结束日期与其他行的开始日期匹配(例如第 1 行和第 2 行),但某些行的日期范围其他行要么完全包含在其他行中(例如第 3 行包含在第 2 行中) ) 而其他行仅与一个边界重叠(例如,第 11 行的 EndDate 不与任何其他行重叠,但其 StartDate 在第 10 行的 EndDate 之前)。
解决方案
虽然有几种方法可以解决间隙和孤岛问题,但这里是使用窗口函数的解决方案,可以满足 Charlie 的需求。
首先,我们需要根据开始和结束日期的顺序创建一个行号列,并将上一行的 EndDate 带到当前行:
SELECT
ROW_NUMBER () OVER (ORDER BY Name , StartDate , EndDate ) AS RN ,
Name ,
StartDate ,
EndDate ,
MAX(EndDate) OVER (PARTITION BY Name ORDER BY StartDate , EndDate
ROWS BETWEEN UNBounded PRECEDING 和 1 PRECEDING) AS PreviousEndDate
FROM
OverlappingDateRanges
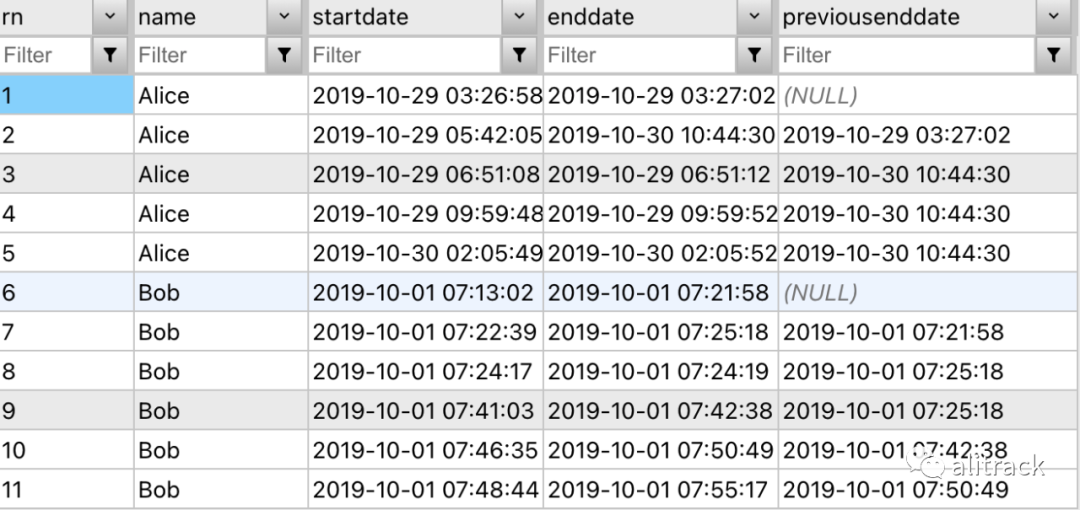
接下来我们再添加两个字段:
IslandStartInd :通过查看当前行的 StartDate 是否出现在前一行的 EndDate 之后来指示孤岛何时开始。对于示例,我们实际上并不需要此列,但我发现查看下一列中发生的情况会很有帮助。 IslandId :表示当前行属于哪个 孤岛号。
SELECT
*,
CASE WHEN PreviousEndDate >= StartDate THEN 0 ELSE 1 END AS IslandStartInd,
SUM (CASE WHEN PreviousEndDate >= StartDate THEN 0 ELSE 1 END)
OVER (ORDER BY RN) AS IslandId
FROM
(SELECT
ROW_NUMBER () OVER (ORDER BY Name, StartDate, EndDate) AS RN,
Name,
StartDate,
EndDate,
MAX(EndDate) OVER (PARTITION BY Name ORDER BY StartDate, EndDate
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS PreviousEndDate
FROM
OverlappingDateRanges
) Grouping

接下来按 汇总返回每组最小开始日期和最大结束日期,
SELECT
Name,
IslandId,
MIN (StartDate) AS IslandStartDate,
MAX (EndDate) AS IslandEndDate
FROM
(SELECT
*,
CASE WHEN Grouping.PreviousEndDate >= StartDate THEN 0 ELSE 1 END AS IslandStartInd,
SUM (CASE WHEN Grouping.PreviousEndDate >= StartDate THEN 0 ELSE 1 END) OVER (ORDER BY Grouping.RN) AS IslandId
FROM
(SELECT
ROW_NUMBER () OVER (ORDER BY Name, StartDate, EndDate) AS RN,
Name,
StartDate,
EndDate,
MAX(EndDate) OVER (PARTITION BY Name ORDER BY StartDate, EndDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS PreviousEndDate
FROM
OverlappingDateRanges
) Grouping
) Islands
GROUP BY
Name,
IslandId
ORDER BY
Name,
IslandStartDate
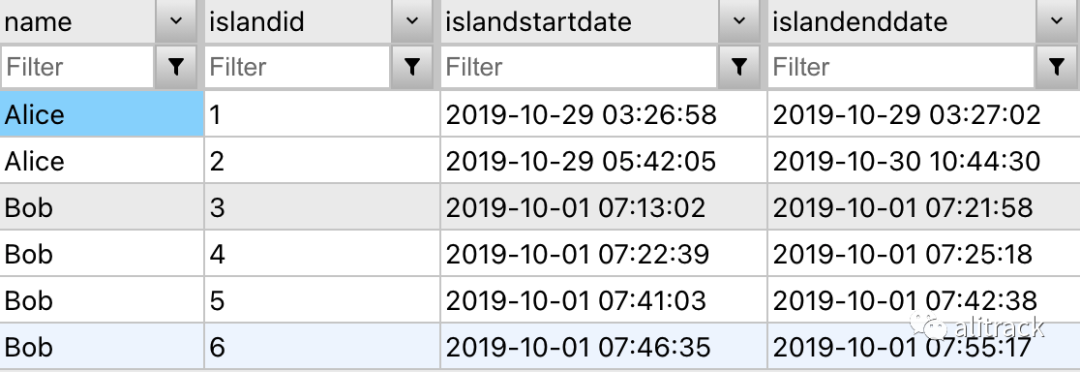
瞧!Alice 和 Bob 的数据已经被相应地分组,现在 Charlie 可以简单地使用来找出他们实际 SUM()
花费了多少时间来回答客户的询问。
SELECT
Name,
sum(timestampdiff(second,IslandStartDate, IslandEndDate))/60 AS ActualTimeSpent
FROM
(SELECT
Name,
IslandId,
MIN (StartDate) AS IslandStartDate,
MAX (EndDate) AS IslandEndDate
FROM
(SELECT
*,
CASE WHEN Grouping.PreviousEndDate >= StartDate THEN 0 ELSE 1 END AS IslandStartInd,
SUM (CASE WHEN Grouping.PreviousEndDate >= StartDate THEN 0 ELSE 1 END) OVER (ORDER BY Grouping.RN) AS IslandId
FROM
(SELECT
ROW_NUMBER () OVER (ORDER BY Name, StartDate, EndDate) AS RN,
Name,
StartDate,
EndDate,
MAX(EndDate) OVER (PARTITION BY Name ORDER BY StartDate, EndDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS PreviousEndDate
FROM
OverlappingDateRanges
) Grouping
) Islands
GROUP BY
Name,
IslandId
ORDER BY
Name,
IslandStartDate
) aa
GROUP BY
Name
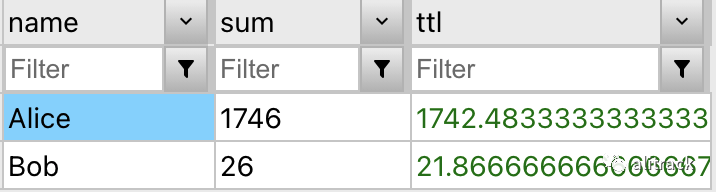
普通的 SUM() 和 间隙和孤岛 方案 总共产生了 8 分钟的差异。这可能看起来很小,但 请记住 ,此数据集仅捕获两个人和他们几天的活动。将其扩展到数千人和数月的活动,差异可能会爆炸并影响许多其他计算(例如客户服务中的人力计划计算),导致每天损失数千美元。
结论
无论岛屿内的日期范围有多么混乱,这种技术都能巧妙地识别数据中的空白并返回每个岛屿日期范围的开始和结束。这种技术可以用于我们需要聚合一些基于日期的交易数据的场景,否则这些数据很难单独使用聚合函数进行汇总。
该解决方案适用于 MySQL(需要 支持开窗函数的 8.0 及以上版本,或者 MariaDB 10.2.0 及以上版本)
下面附上 Postgres 的实现,差异仅在日期的计算上,
Postgres 版本
SELECT
Name,
sum(timestampdiff(second,IslandStartDate, IslandEndDate))/60 AS ActualTimeSpent
FROM
(SELECT
Name,
IslandId,
MIN (StartDate) AS IslandStartDate,
MAX (EndDate) AS IslandEndDate
FROM
(SELECT
*,
CASE WHEN Grouping.PreviousEndDate >= StartDate THEN 0 ELSE 1 END AS IslandStartInd,
SUM (CASE WHEN Grouping.PreviousEndDate >= StartDate THEN 0 ELSE 1 END) OVER (ORDER BY Grouping.RN) AS IslandId
FROM
(SELECT
ROW_NUMBER () OVER (ORDER BY Name, StartDate, EndDate) AS RN,
Name,
StartDate,
EndDate,
MAX(EndDate) OVER (PARTITION BY Name ORDER BY StartDate, EndDate
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS PreviousEndDate
FROM
OverlappingDateRanges
) Grouping
) Islands
GROUP BY
Name,
IslandId
ORDER BY
Name,
IslandStartDate
) aa
GROUP BY
Name
如果你的数据库不支持开窗函数,可以参考下我的另外 一篇文章,实现曲线救国,
如果想对开窗函数有更多了解,可以看看我的另外几篇文章,
开窗函数之累积最大、最小,PySpark,Pandas 和 SQL 版实现 开窗函数之累积和,PySpark,Pandas 和 SQL 版实现 开窗函数之累积乘,PySpark,Pandas 和 SQL 版实现 PySpark 之窗口函数实战
翻译整理自,SQL Classic Problem: Identifying Gaps and Islands Across Overlapping Date Ranges[1]
参考资料
SQL Classic Problem: Identifying Gaps and Islands Across Overlapping Date Ranges: https://medium.com/analytics-vidhya/sql-classic-problem-identifying-gaps-and-islands-across-overlapping-date-ranges-5681b5fcdb8
