




MySQL高可用方案很多,最常见的原生复制方案,即async、semi-sync那套,所以本文从原生复制方案为中心,讨论数据一致性。
基于复制的高可用方案
两节点:双主、主从
三节点或更多:一主两从等
明确一点,这几种结构无论怎么变,无论是用MHA还是Orchestrator,还是什么第三方工具,核心点都是通过binlog event
来传递数据给其他节点。
这种结构常见的问题:
1、延迟、复制过滤、报错等造成数据不一致:
这个问题,一般能够通过优秀的DBA和业务开发大哥们,通过权限管理、schema设计、配置优化、SQL调优等手段处理掉,但……还有2
2、master crash,备库没有收到binlog event:
这个问题,有人就会说了,有个叫semi-sync
的东西,何况5.7还优化了semi-sync
,支持无损半同步(lossless semi-synchronous
),但其实极端情况下,也有问题。

异步复制
大家都懂。听名字和实际上都不靠谱:不管一个或多个从库是否收到了binlog events
,主库只管产生binlog
,极端场景下的,发生数据不一致的几率非常大。
半同步复制
先简单说一下after_commit
和after_sync(lossless)
的差异。
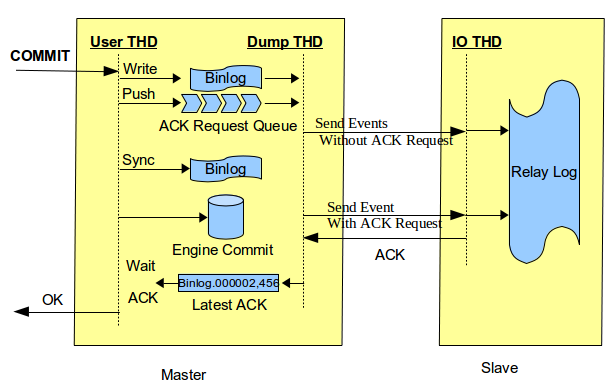
after_commit:
在engine commit之后等待ACK
after_sync:
在engine commit之前等待ACK复制
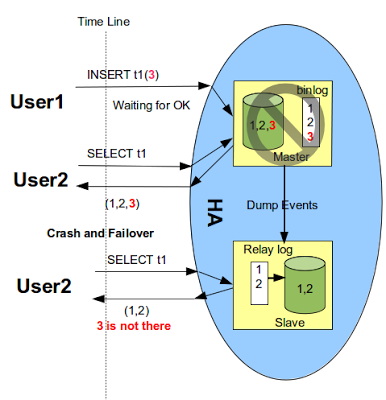
after_commit
模式下,先做引擎层提交,这时候其他客户端是可以会读到这个事务的。如果这时发生容灾,事务又没有传给Slave
,容灾后客户端就读不到这个事务了,就出现了数据不一致情况。
(出处见参考文档)
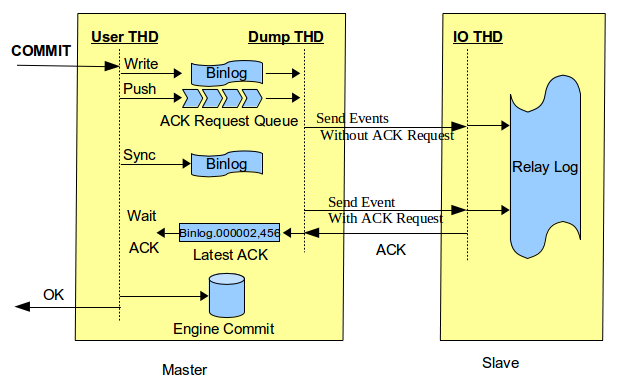
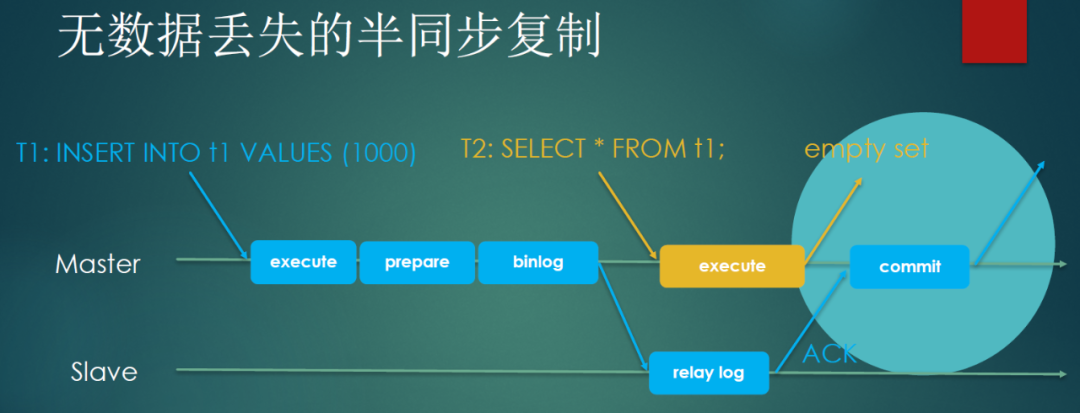
而after_sync(lossless)
优化了这点,即,等待ACK
返回成功,再做引擎层提交,这样客户端1读不到,其他客户端也读不到。
(出处见参考文档)
(图源宋利兵老师,来自知数堂的公开课-《MySQL-5.7 Replication新特性》)
基于半同步复制的容灾讨论
讨论这个话题其实是非常大的,因为复制的场景很多。比如GTID、auto-position、MTS等。
此处假设大家的MySQL实例都是经过专业DBA之手,配置好了支持slave crash safe
的参数。
此处讨论5.7+的after_sync(lossless)
Master Crash,未容灾:
没所谓,拉起后继续做crash recovery,最终主从是一致的。
Master Crash,容灾:
1)Crash时至少有一台Slave收到binlog event并成功返回了ACK给Master:
没问题,因为这种情况主从数据一致的,拉起后也不需要做额外操作。
2)Crash时binlog event发送失败:
假设产生在实例A的事务t1是:INSERT:pk_id=11, name='张三'
。
发生容灾,实例B成为新主,可能会产生新事务t2:INSERT:pk_id=11, name='李四'
实例A恢复后,做crash recovery
,将t1直接提交,然后作为新的Slave,接收到了实例B(新主)的这条事务t2,出现了duplicated key
,经典的ERROR 1062
来了,设置合理的参数也没用。
其实,事务t1是要被遗弃的小可怜(鹅厂PhxSQL团队称这种事务为“Pending Binlog”)
因为也没有返回给客户端它成功提交的信息,这种情况是要回滚的,而且这种情况在after_sync(lossless)
的设置下,也没办法的。
3)Crash时binlog event发送成功,但在等ACK,没有执行engine commit
:
因为事务t1已经发送成功了,接管成新Master的Slave是有事务t1的,所以原Master拉起后,做crash recovery
,也是没问题的,拉起后不需要做额外操作。
场景2)还有什么风险?
试想一下,如果没有pk,是不是就不会报错?
也没办法发现拉起来的老Master实际上和新Master数据不一致了?
场景2)的解决:
首先,场景2)MySQL原生复制结构是没法处理的。
但问题总要解决,为了保证整个复制节点的数据一致,考虑如下:
方案1、重建节点
方案2、回滚错误事务,断点续传新增binlog复制
方案1也就是最憨的办法,直接重建容灾后的从库,没有技术含量,有个叫做xtrabackup
的家伙,拿它一把梭,不说了。
方案2需要一定的开发量,参(bai)考(piao)了一下别人的做法:
微信PhxSQL:
额外多一个BinlogSvr的中间服务。“使得Master(重启时检查本地Binlog是否和BinlogSvr集群的数据一致)和Slave(从BinlogSvr集群中获取Binlog)的数据保持一致,从而保证了整个集群中的MySQL主备间数据的一致性。”

如果这个时候有人问,“你把pk_id=11, name='张三'
给回滚了,这个事务不是丢掉了吗?”
我认为回滚是没问题的。
理由如下:
事务的ACID特性,其中的D持久性是指“提交成功的事务肯定不丢”。而我上面所说的场景是——没有返回“提交成功”,所以我认为回滚是没问题的。
结论
原生复制存在对“一致性”和“可用性”的权衡挑战。
即使是安全的配置了各种参数,使用原生复制体系和lossless semi-sync
,也不是100%省心的(尤其是对于数据一致性要求拉满的业务)。
即使是将@@rpl_semi_sync_master_timeout
设置为无穷大,也只是保证semi-sync
不退化。
其他一致性方案或思路:
1、Paxos\Raft
2、共享存储复制
参考
《PhxSQL设计与实现》,google一搜就有
《Loss-less Semi-Synchronous Replication on MySQL 5.7.2》,http://my-replication-life.blogspot.com/2013/09/loss-less-semi-synchronous-replication.html
淘宝内核月报 - 《MySQL 半同步复制数据一致性分析》,http://mysql.taobao.org/monthly/2017/04/01/

-- the end --

戳阅读原文查看历史推送。
