




一个全表扫描从表中读取所有的行,然后过滤掉不符合选择标准的那些行。
8.2.2.1当优化器考虑全表扫描时
通常,当优化器无法使用其他访问路径,或者另一个可用的访问路径成本较高时,它会选择全表扫描。
下表显示了选择全表扫描的典型原因。
表8-2全表扫描的典型原因
| 原因 | 说明 | 了解更多 |
|---|---|---|
不存在索引。 | 如果不存在索引,那么优化器将使用全表扫描。 | |
查询谓词将函数应用于索引列。 | 除非索引是基于函数的索引,否则数据库将为列的值建立索引,而不是对应用了该功能的列的值进行索引。一个典型的应用程序级错误是索引一个字符列,例如 | |
一个 | 由于索引不能包含空条目,因此优化器无法使用索引来计数表行数。 | “ B树索引和空值 ” |
查询谓词不使用B树索引的前沿。 | 例如,上可能存在一个索引 | “ 索引跳过扫描 ” |
该查询是非选择的。 | 如果优化器确定查询需要表中的大多数块,则即使索引可用,它也会使用全表扫描。全表扫描可以使用较大的I / O调用。进行较少的大型I / O调用要比进行许多较小的调用便宜。 | “ 选择性 ” |
表统计信息已过时。 | 例如,一张桌子很小,但是现在已经很大了。如果表统计信息是过时的,并且不能反映表的当前大小,则优化器将不知道索引现在比全表扫描效率最高。 | “ 优化器统计简介 ” |
表很小。 | 如果一个表在高水位线以下包含少于n个块,其中n等于 | |
该表具较高的并行度。 | 表的高度并行性使优化器偏向于在范围扫描上进行全表扫描。查询 | |
该查询使用全表扫描 hint。 | 该提示指示优化器使用全表扫描。 |
8.2.2.2全表扫描如何工作
在全表扫描中,数据库按顺序读取高水位标记下的每个格式化块。数据库仅读取每个块一次。
下图描述了对表段的扫描,显示了该扫描如何跳过高水位线以下的未格式化块。
图8-2高水位线
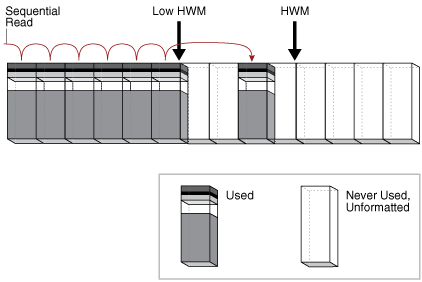
由于这些块相邻,因此数据库可以通过使I / O调用大于单个块(称为多块读取)来加快扫描速度。
读取调用的大小范围从一个块到DB_FILE_MULTIBLOCK_READ_COUNT初始化参数指定的块数。例如,设置此参数以4指示数据库在单个调用中最多读取4个块。
在全表扫描期间缓存块的算法很复杂。例如,数据库缓存表的大小取决于表的大小。
也可以看看:
- “ 表19-2 ”
- Oracle Database Concepts概述默认缓存模式
- Oracle数据库参考,了解
DB_FILE_MULTIBLOCK_READ_COUNT初始化参数
8.2.2.3全表扫描:示例
本示例扫描hr.employees表。
以下语句查询超过4000美元的月薪:
SELECT salary FROM hr.employees WHERE salary > 4000;复制
示例8-1全表扫描
使用该DBMS_XPLAN.DISPLAY_CURSOR函数检索了以下计划。因为salary列上没有索引,所以优化器无法使用索引范围扫描,因此使用全表扫描。
SQL_ID 54c20f3udfnws, child number 0 ------------------------------------- select salary from hr.employees where salary > 4000 Plan hash value: 3476115102 ------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 3 (100)| | |* 1 | TABLE ACCESS FULL| EMPLOYEES | 98 | 6762 | 3 (0)| 00:00:01 | ------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("SALARY">4000)复制
父主题: 全表扫描
