经常遇到索引比列还要多的表。为什么?因为开发结合业务需求一个场景一个索引。比如说一个表有id,name,status,time几个字段吧。然后看看这表的索引可能会出现如下的索引:
1、name
2、time
3、name+time
4、time+name
5、status
6、name+status
7、name+status+time
8、status+time
。。。。。。没完,我就不一一写了。因为结合业务场景。每个场景来一下,然后发现还是不快,那在已有的上再加一列,或者反过来试试,再或者孙行者这样不行,者行孙试试?于是乎就出现了类似上面的,各种排列组合。我这还写少了。实际中怎么可能就这几个字段。
真正结合业务一般怎么来?比如我有个订单表,站在用户维度一定是要看自己的,传入进来的一定带userid。然后用户一定看自己最新的然后往下翻。。。。。。那么检索条件应该是userid+time+其他的什么我们先不管。但是前两个要素userid和time定了。这是场景1
还是这个订单,运营人员想看看最近一周哪些用户买的东西最多。一定是time+userdi++其他的什么我们先不管。但是前两个要素time和userid定了。这是场景2
当然必须包括订单号了。比如说id。那么以上三个场景按照出现频次来说占这个表的select总数多少?我估计99.99%以上。如果这个公司业务量大,日活用户100w。那么每天100w次场景1,场景2可能几百次吧。场景3至少100万次。这个体量的公司也算可以了。
假设这就是那个表了。以MySQL为例,Oracle PG也一样。
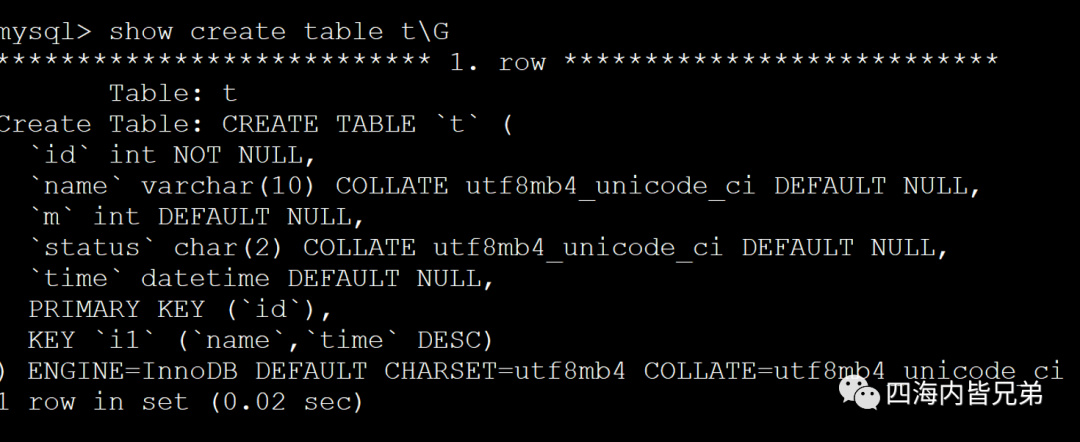
针对场景1来说我只要建立i1索引。
实验数据如下:
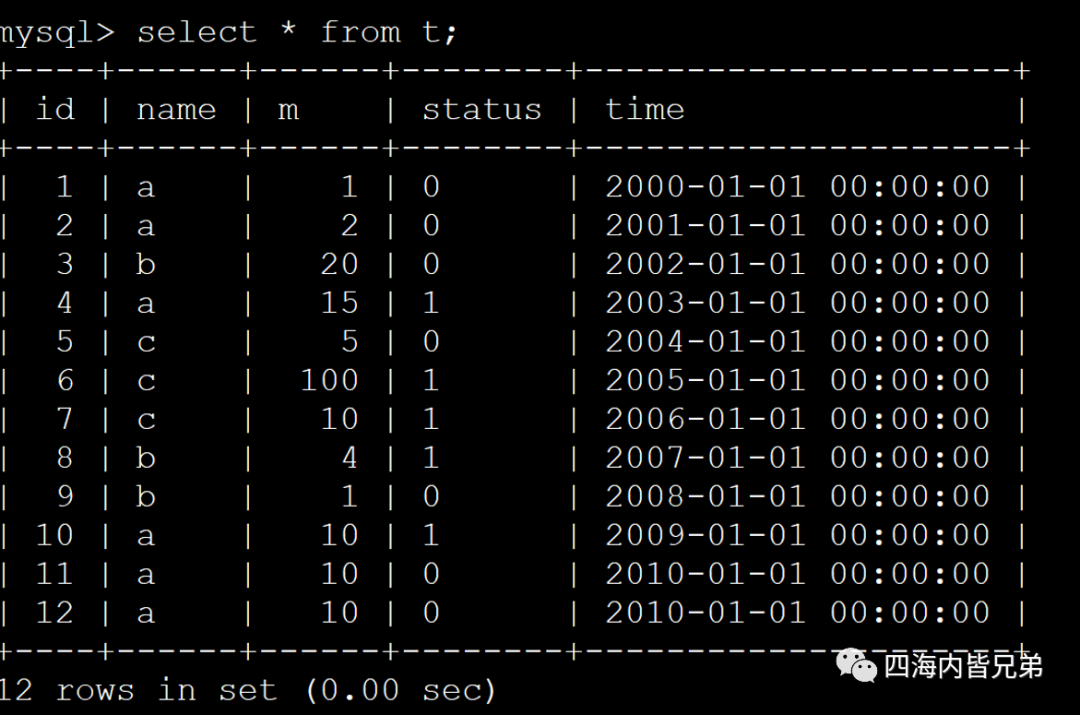
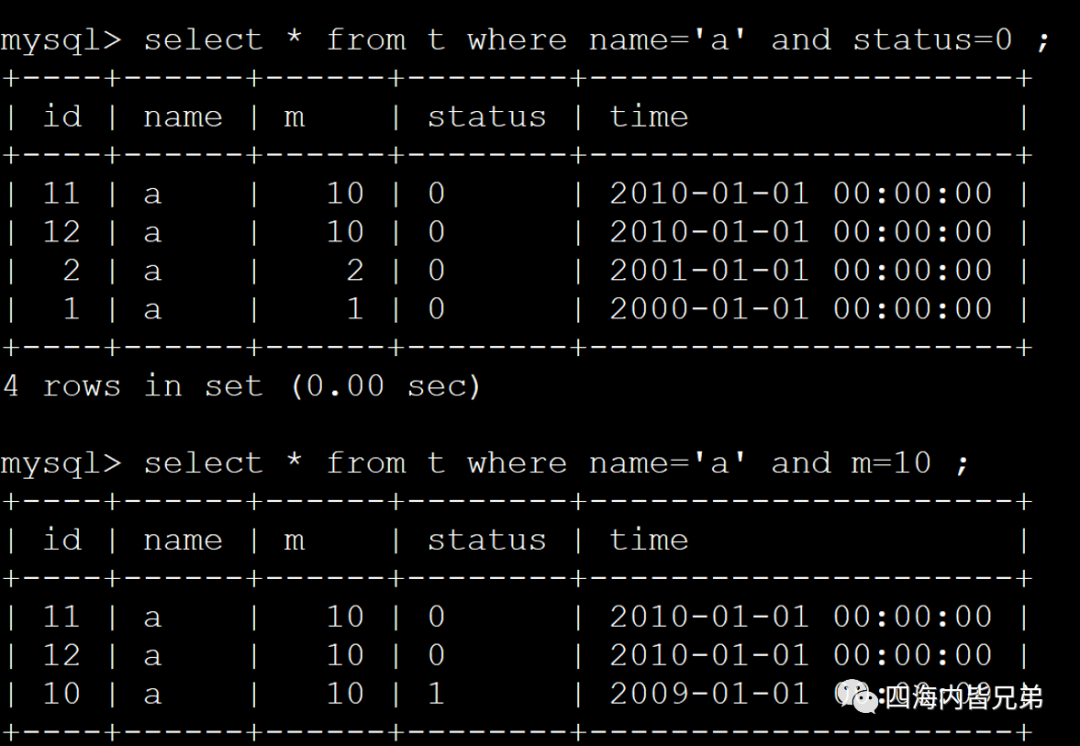
我先查一下c用户。注意我没排时间,时间倒序了。因为我索引指定desc了。
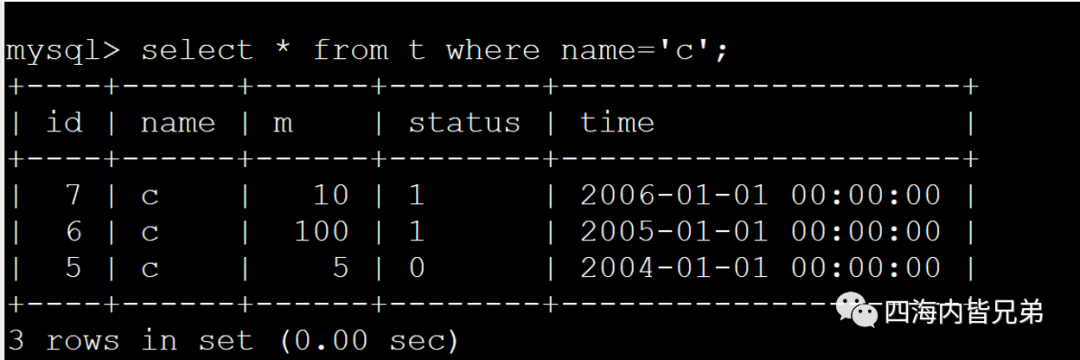
再看一次
那么这个是的我带上其他条件。看到了吗?不影响。
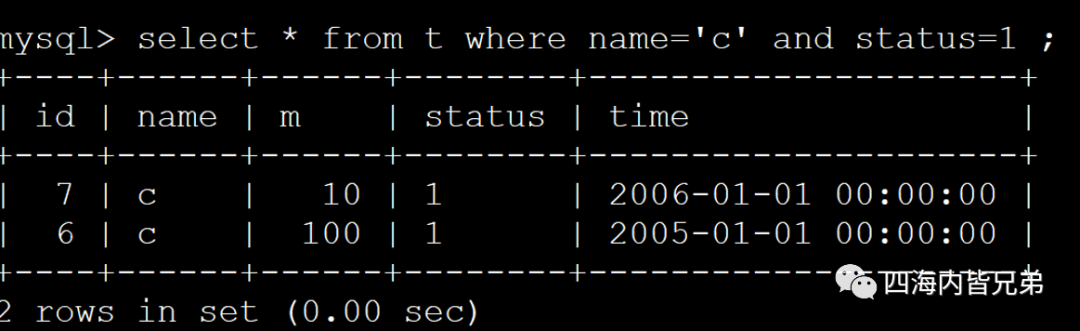
这意味着我们索引就2列,其他不见得都要带进来。(单表场景下可以)基于这个单表简单场景,注意一定是单表简单场景。就可以limit分页一页一页往下了。
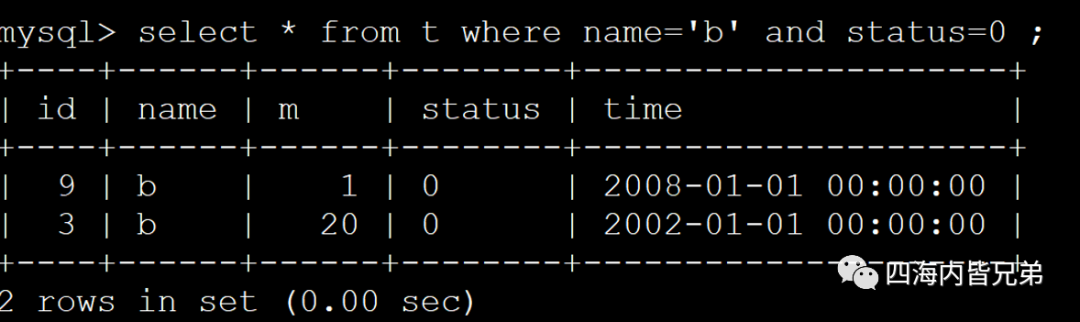
其他几个也看一下吧。