




Nacos: 注册中心,解决服务注册与发现
Ribbon: 客户端的负载均衡器,解决服务集群的负载均衡
OpenFeign:声明式的HTTP客户端,服务远程调用
Nacos:配置中心,中心化管理配置文件
Sentinel:微服务流量卫兵,以流量为入口,保护微服务,防止出现服务雪崩
Gateway: 微服务网关,服务集群的入口,路由转发以及负载均衡(结合Sentinel)
Sleuth: 链路追踪,链路快速梳理、故障定位等
Seata: 分布式事务解决方案
目录
一、概述
1.1、为什么使用链路追踪

随着业务发展,微服务的数量也会越来越多,某个服务出现问题,问题很难排查
【问题】
1、链路梳理难:无法清晰地看到整个调用链路
2、故障难定位:无法快速定位到故障点、无法快速定位哪个环节比较费时
因此,我们需要链路追踪来梳理链路调用,方便快速定位问题。
1.2、常见链路追踪解决方案
常见的有如下几种解决方案,本文讲解跟SpringCloud相关的Sleuth + Zipkin
【Zipkin】
Twitter开源的调用链分析工具,目前基于springcloud sleuth得到了广泛的使用,特点是轻量,使用部署简单
【Pinpoint】
韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,U功能强大,接入端无代码侵入。
【SkyWalking】
本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
【CAT】
是大众点评开源的基于编码和配置的调用链分析,应用监控分析,日志采集,监控报警等一系列的监控平台工具。
1.3、Sleuth概述
1.3.1、概述
sleuth是一个链路追踪工具,通过它在日志中打印的信息可以分析出一个服务的调用链条,也可以得出链条中每个服务的耗时,这为我们在实际生产中,分析超时服务,分析服务调用关系,做服务治理提供帮助。
sleuth目前并不是对所有调用访问都可以做链路追踪,它目前支持的有:rxjava、feign、quartz、RestTemplate、zuul、hystrix、grpc、kafka、Opentracing、redis、Reator、circuitbreaker、spring的Scheduled。国内用的比较多的dubbo,sleuth无法对其提供支持。
1.3.2、Sleuth术语
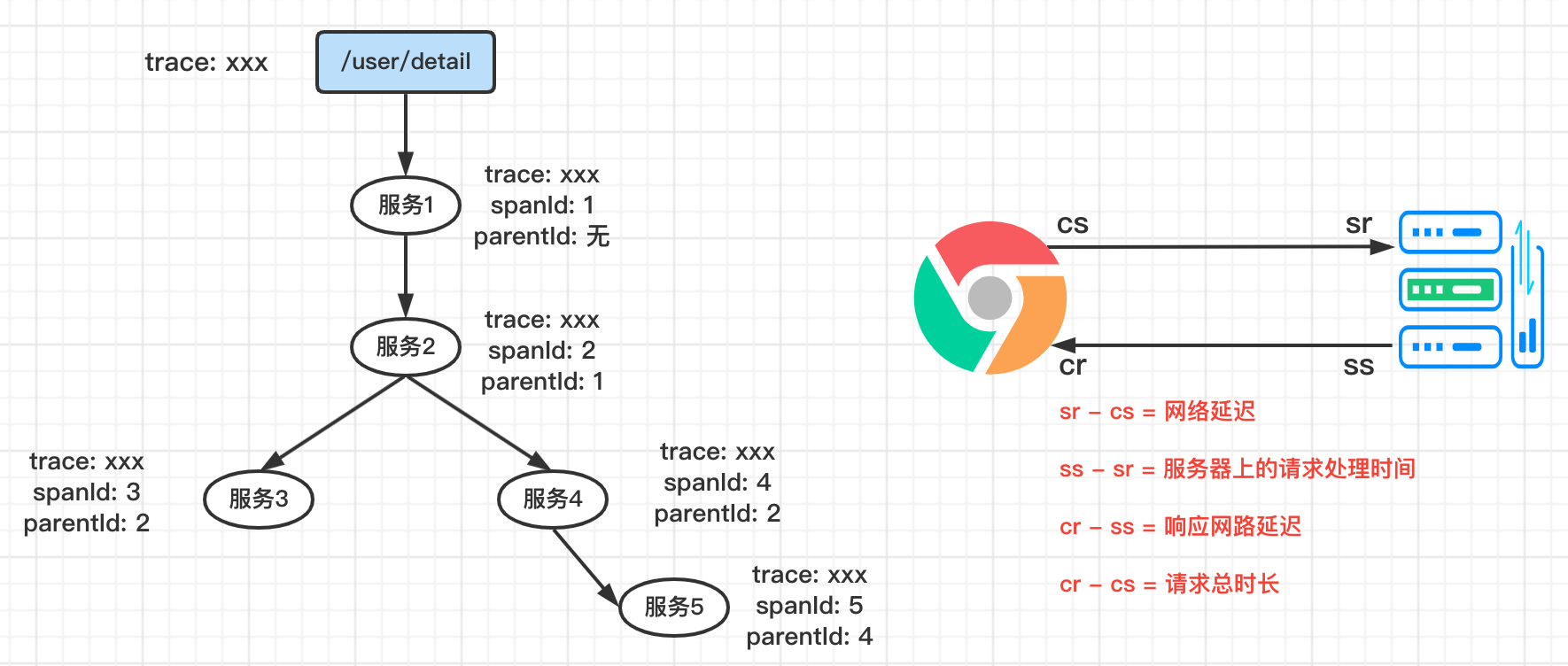
请求一个微服务系统的API接口,这个API接口需要调用多个微服务单元,调用每个微服务单元都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。整个过程使用Annotation(cs、sr、ss、cr)统计各个阶段消耗的时长
-
Span
Span是基本工作单位。Span还包含了其他的信息,例如摘要、时间戳事件、Span的ID以及进程ID。SpanId用于唯一标识请求链路到达的各个服务组件。
-
Trace
由一组具有相同TraceId的span组成的树状结构,即一个完整的请求链路
-
Annotation
记录一个请求的4个事件,用于计算各个环节消耗的时长
-
cs (Client Sent ):客户端发送一个请求,开始一个请求的生命。
-
sr (Server Received ):服务端收到请求开始处理,sr - cs = 网络延迟(服务调用的时间)
-
ss(Server Sent ):服务端处理完毕准备发送到客户端,ss - sr = 服务器处理请求所用时间
-
cr (Client Received ):客户端接收到服务端的响应,请求结束,cr - cs = 请求的总时间
-
二、Sleuth + Zipkin 原理
2.1、Sleuth原理简述
【AOP拦截器的思想】
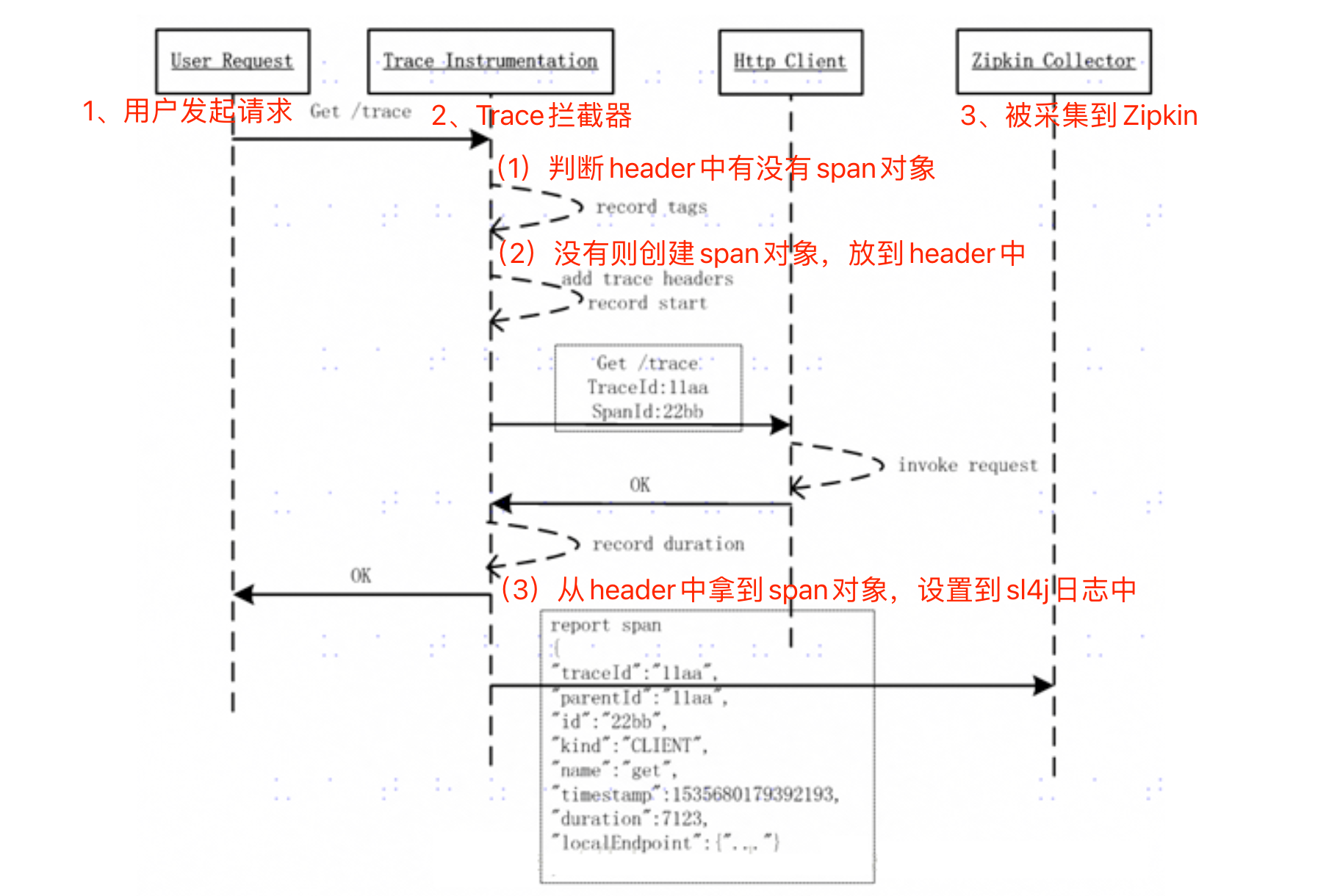
Sleuth创建TraceFilter,对所有的网络请求进行拦截,如果请求的header中没有span信息,则创建Span对象,生成span id、trace id等当前调用链的Trace信息记录到Http Headers中,如果header中有,则直接使用header中的数据创建Span对象,之后将span id、trace id设置到sl4j的MDC中。这样,我们在日志中就能看到span信息。
我们通过日志看到的信息其实只是sleuth收集信息的一小部分,在运行过程中,sleuth还会收集服务调用时间、接收到请求的时间、发起http请求的方法、http请求的路径,包括请求的IP端口等信息,这些信息都会存入Span对象,然后发送到zipkin中。
2.2、Zipkin 原理简述
【装备库】
针对不同语言,不同RPC框架,有不同的装备库实现,Brave是zipkin官方提供的Java的装备库。
【Brave】
Brave是trancer库,功能是对drace的跟踪记录
Sleuth在2.0之后使用了Brave
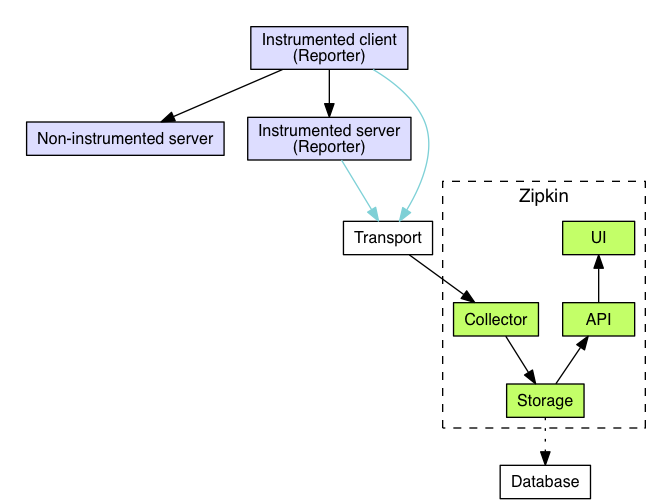
【Zipkin组成】
【Collector(收集器组件)】:主要负责收集外部系统跟踪信息,转化为Zipkin内部的Span格式。
【Storage(存储组件)】:主要负责收到的跟踪信息的存储,默认为存储在内存中,同时支持存储到Mysql、Cassandra以及ElasticSearch。
【API(Query)】: 负责查询Storage中存储的数据,提供简单的JSON API获取数据,主要提供给web UI使用。
【Web UI(展示组件)】:提供简单的web界面,方便进行跟踪信息的查看以及查询,同时进行相关的分析。
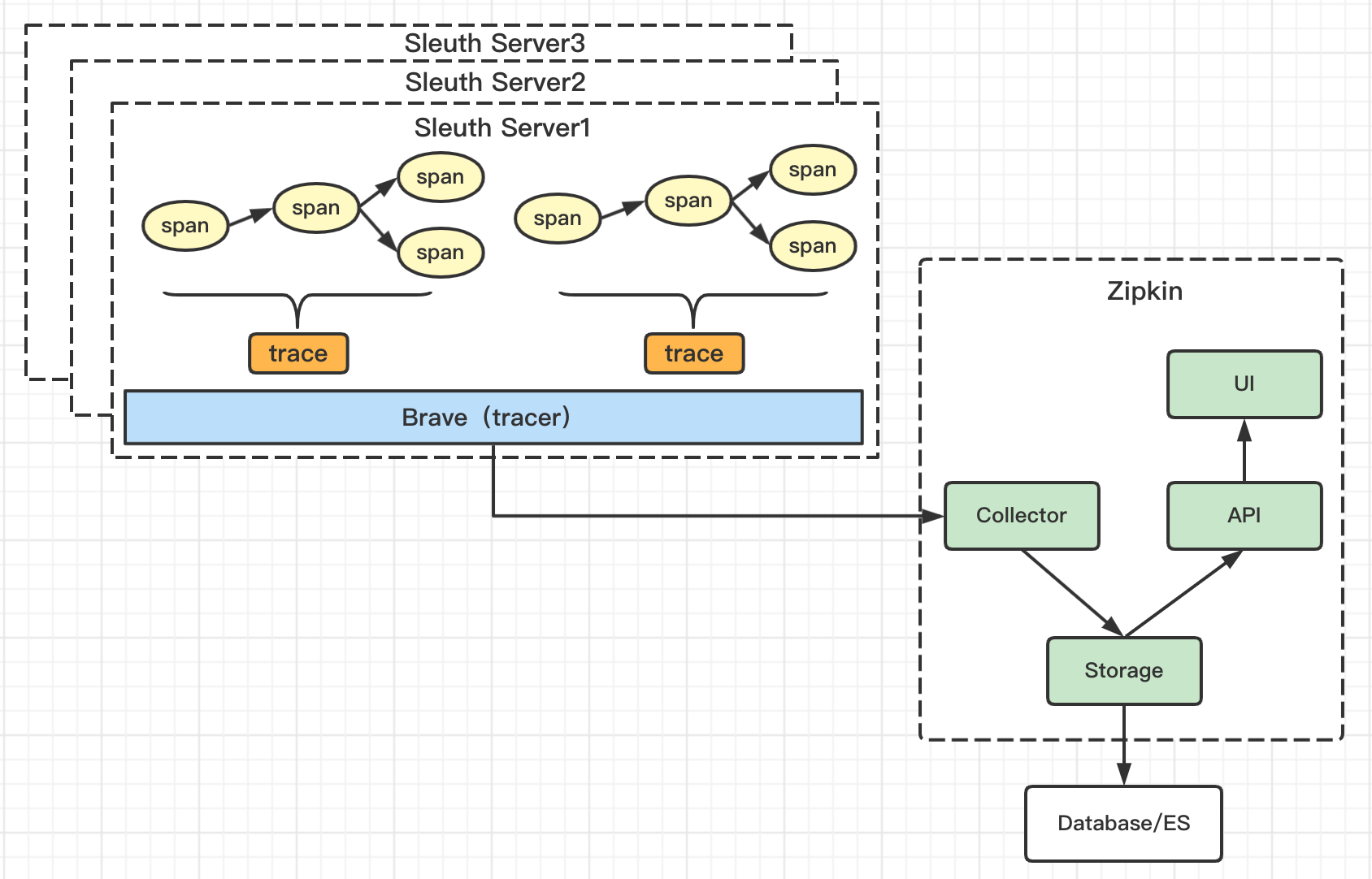
【原理】
1、Sleuth采用Brave(trancer库)追踪采集trace(由一组包含span信息的调用链组成)
2、将信息通过Zipkin的Collector发送给Zipkin
3、zipkin拿到信息后,将数据通过Storage持久化到数据库/es中
3、Zipkin通过API提供数据给UI进行可视化展示
三、Sleuth快速上手
-
引入依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>复制 -
编写配置
spring: sleuth: sampler: rate: 100 # 指定采样比例,默认10%复制 -
测试
// 在接口中加入日志 log.info("测试日志");复制当调用该接口时,输出日志如下
2022-03-14 18:28:35.494 INFO [cloud-goods,2341a5de56a506d8,2341a5de56a506d8,false] 19812 --- [nio-9001-exec-1] com.decade.controller.GoodsController : 测试日志复制可以看到,日志里出现了 [cloud-goods,2341a5de56a506d8,2341a5de56a506d8,false] 信息,这个就是由Spring Cloud Sleuth生成,用于跟踪微服务请求链路。
这些信息包含了4个部分的值,它们的含义如下:
1、cloud-goods微服务的名称,与
spring.application.name对应;
2、2341a5de56a506d8称为Trace ID,在一条完整的请求链路中,这个值是固定的。观察上面的日志即可证实这一点;
3、2341a5de56a506d8称为Span ID,它表示一个基本的工作单元;
4、false表示是否要将该信息输出到Zipkin等服务中来收集和展示,这里我们还没有集成Zipkin,所以为false。
四、集成Zipkin
虽然我们已经可以通过Trace ID来跟踪整体请求链路了,但是我们还是得去各个系统中捞取日志。在并发较高得时候,日志是海量的,这个时候我们可以借助Zipkin来代替我们完成日志获取与分析。Zipkin是Twitter的一个开源项目。
4.1、集成Zipkin
-
引入依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>复制 -
配置文件
spring: zipkin: base-url: http://localhost:9999 # zipkin的地址 discovery-client-enabled: false # 禁用往nacos里注册复制 -
安装Zipkin
只需要下载Zipkin的jar包,并启动即可
-
启动
java -jar zipkin-server-2.12.9-exec.jar --server.port=9999复制 -
访问:localhost:9999
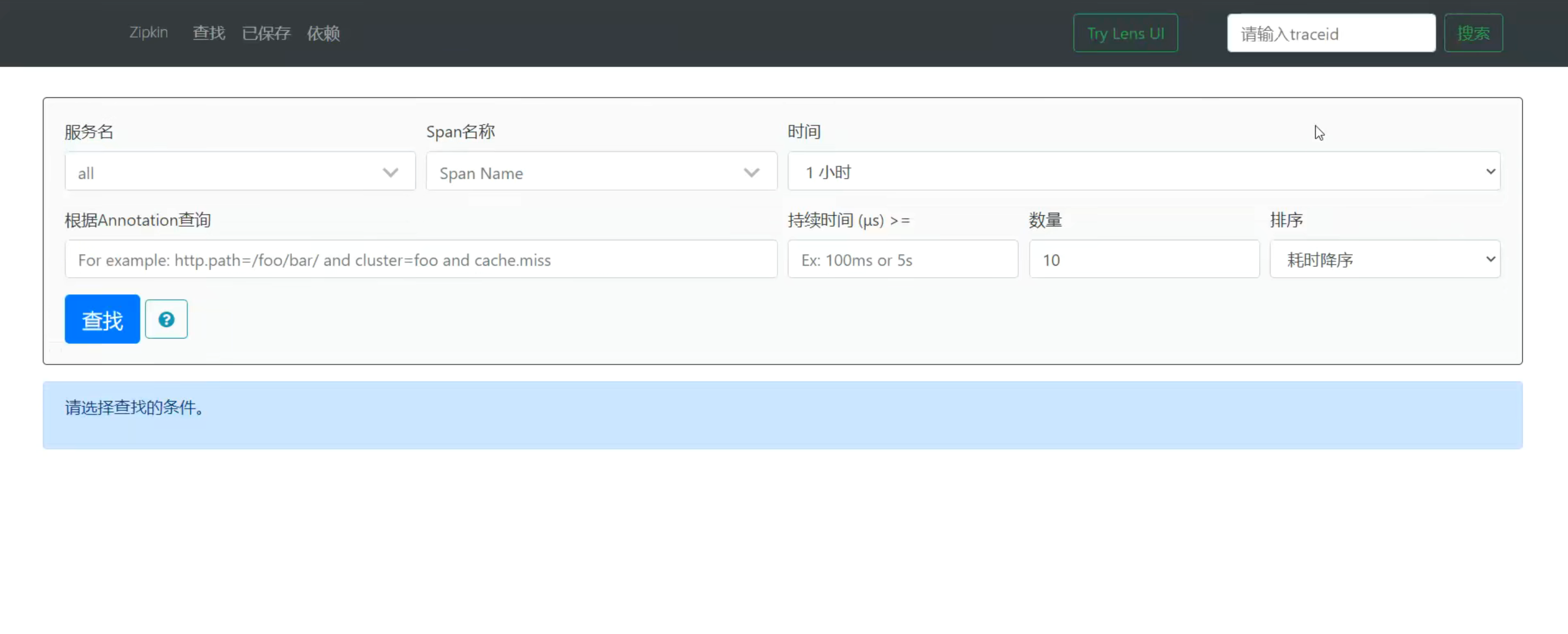
4.2、持久化存储
这些跟踪信息在Zipkin-Server服务重启后便会丢失,我们可以将这些信息存储到MySQL或者elasticsearch中。
如下演示基于Mysql的持久化存储
1、在Zipkin-Server中添加MySQL数据库驱动和JDBC依赖
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-mysql</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
复制2、在application.yml中添加数据库连接信息:
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/zipkin?useUnicode=true&characterEncoding=utf-8
driver-class-name: com.mysql.jdbc.Driver
username: root
password: 123456
zipkin:
storage:
type: mysql
复制3、创建数据库与表
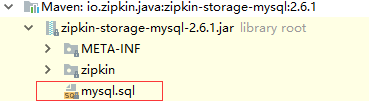
新建一个名为zipkin的数据库
导入库表,库表SQL文件在io.zipkin.java:zipkin-storage-mysql:2.6.1依赖里可以找到:
4、重启Zipkin-Server
评论

 0 点赞
0 点赞


