




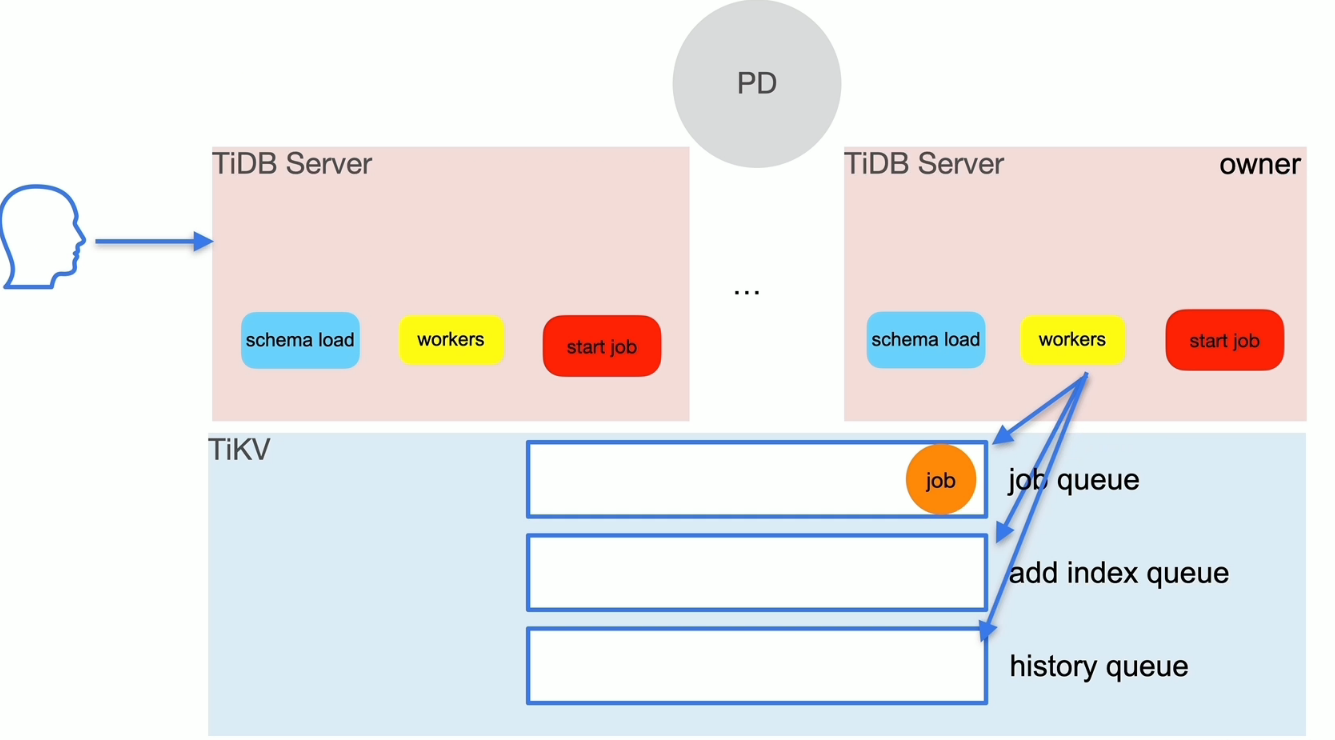
TiDB 数据库 SQL 执行流程
DML 语句读流程
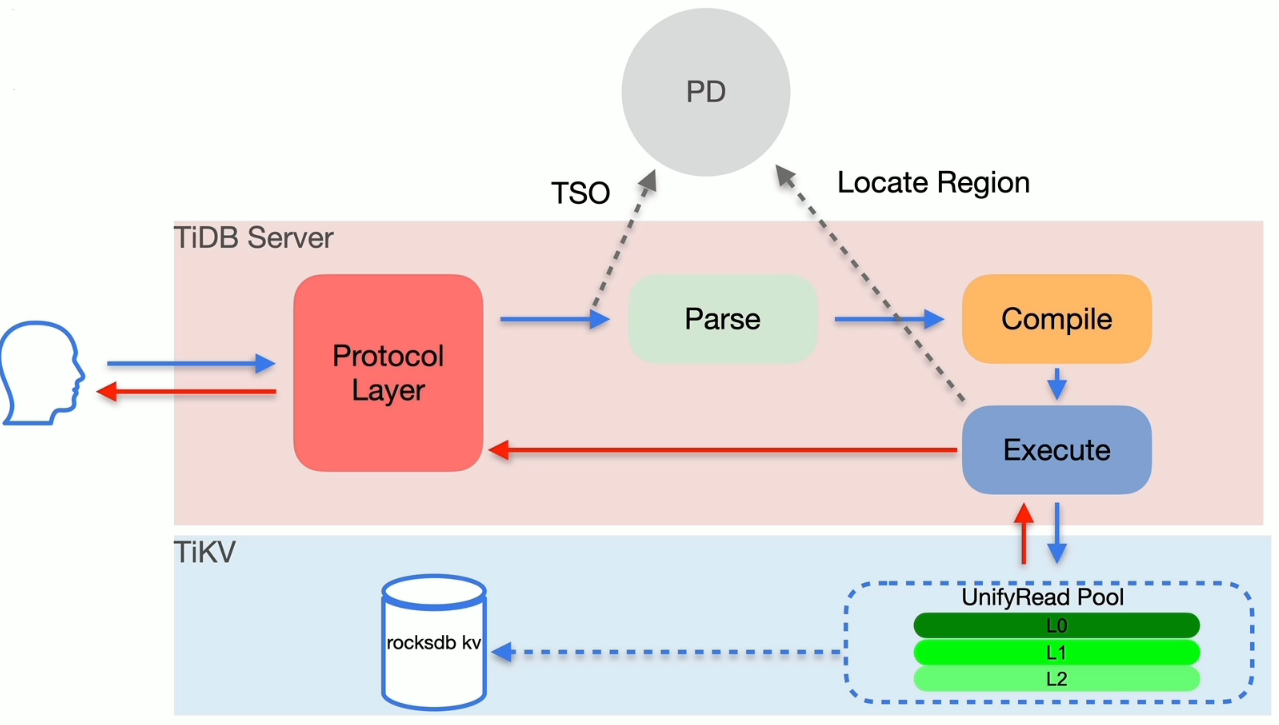
DML 语句写流程
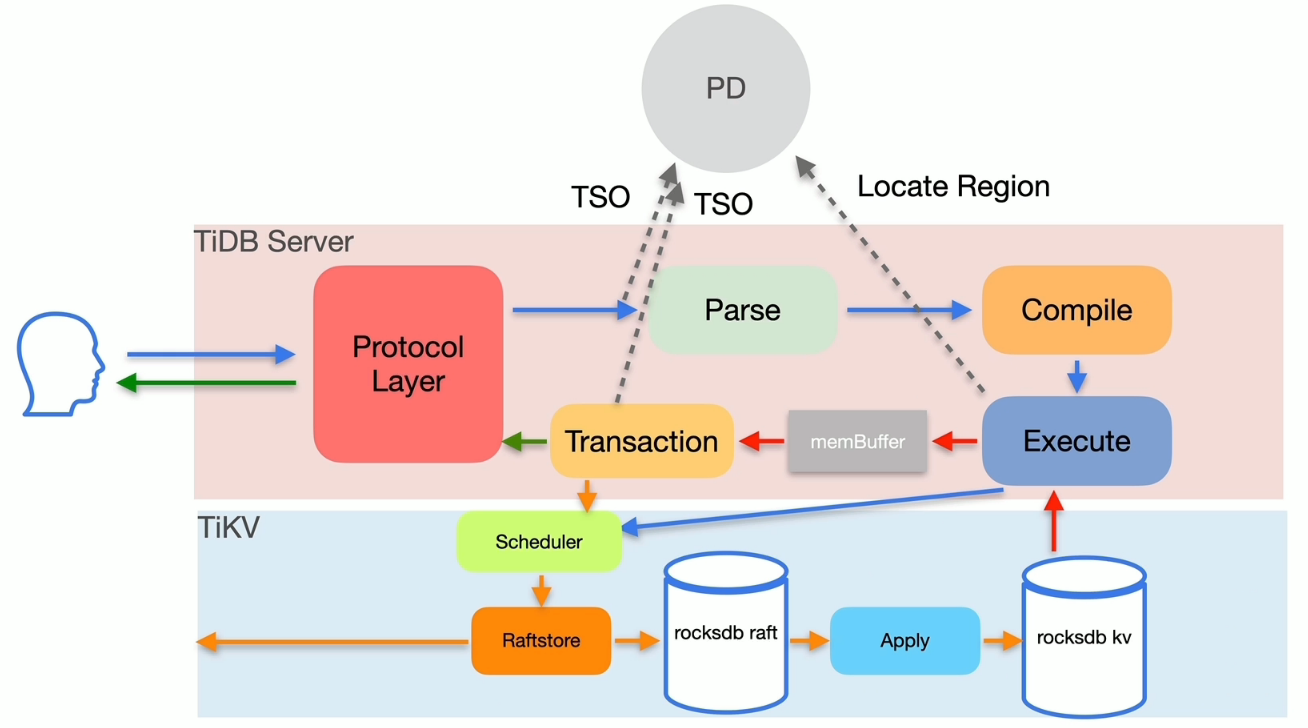
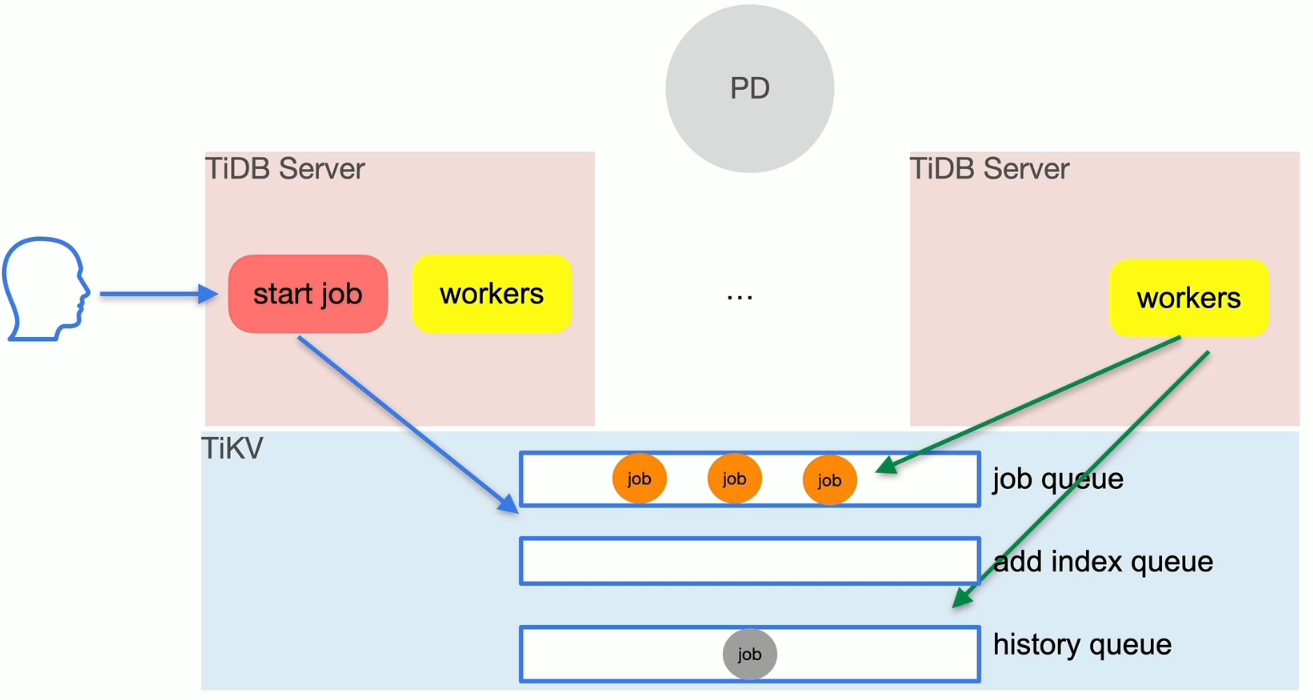
DDL 流程
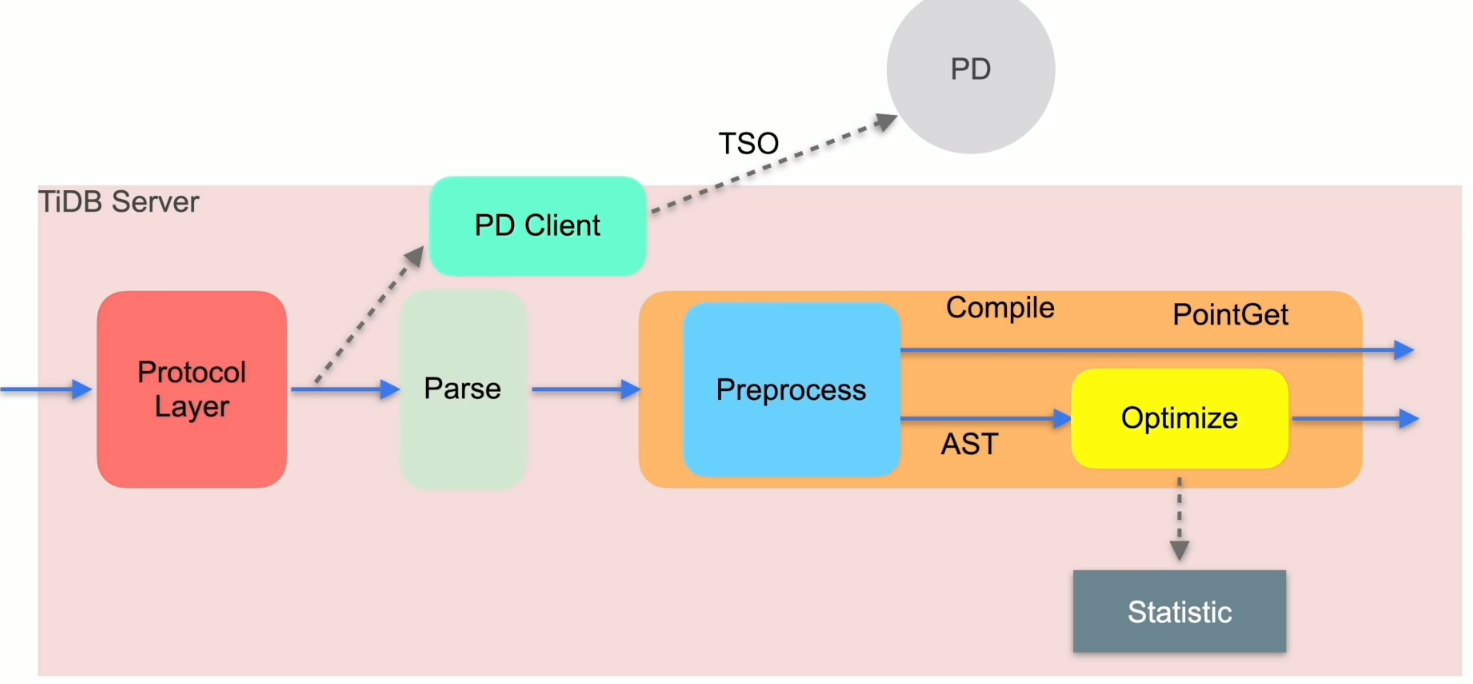
SQL 的 Parse 与 Compile
读取的执行
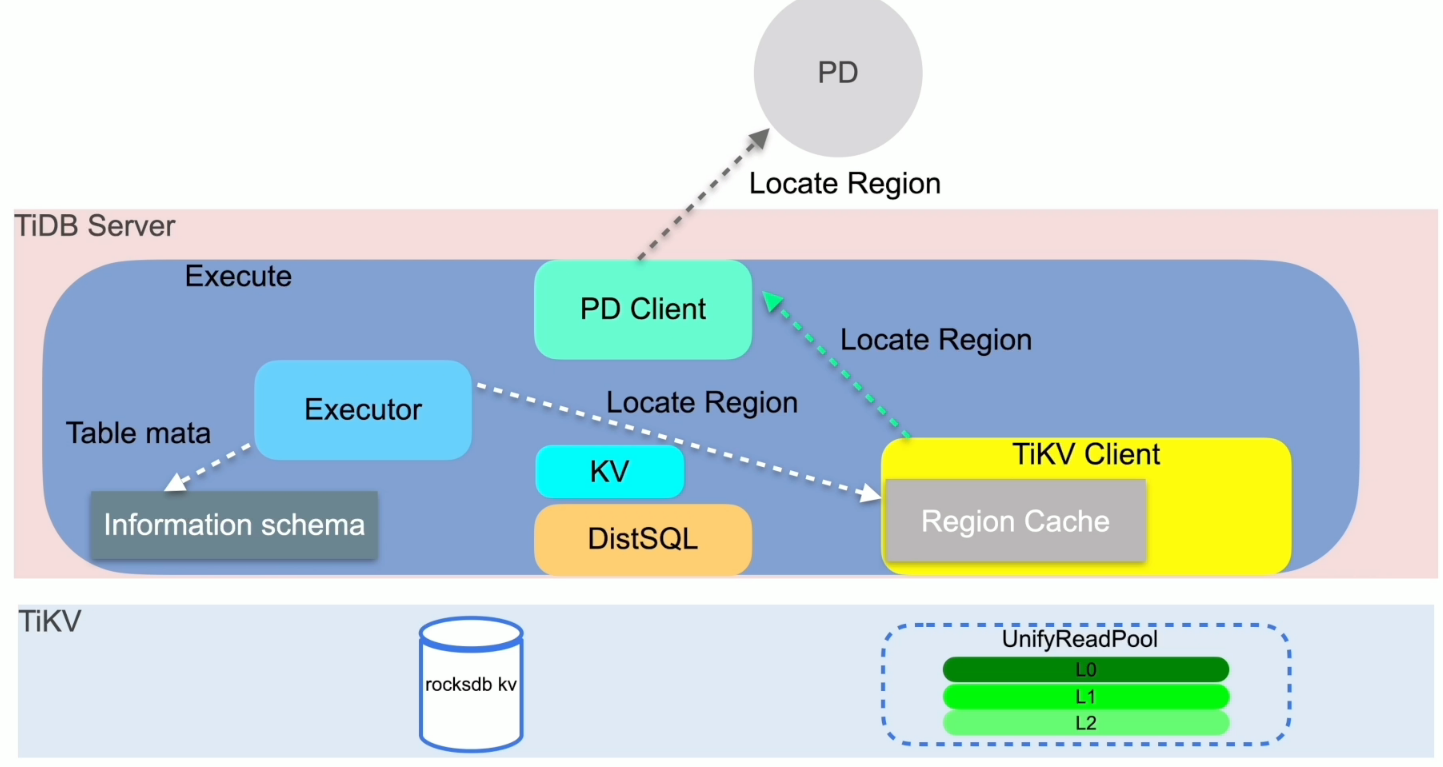
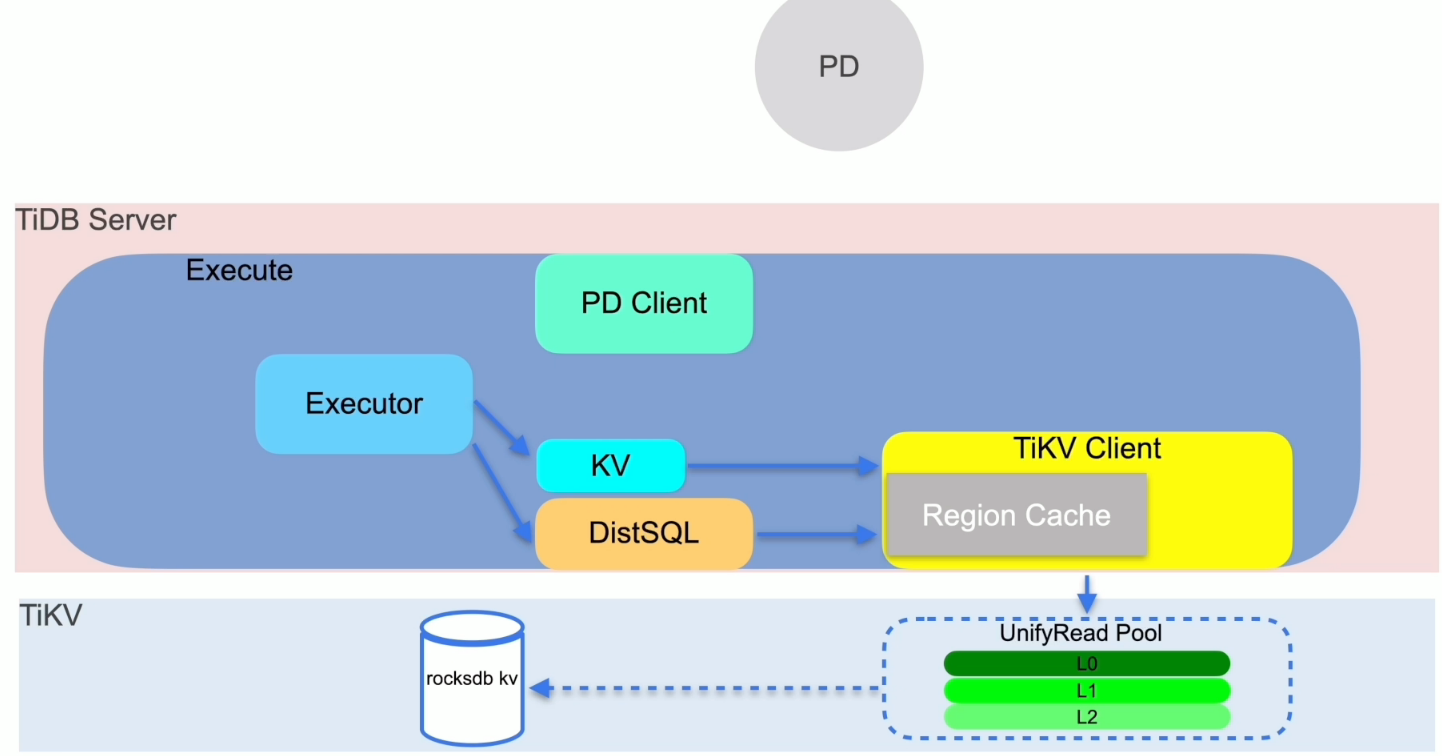
写入的执行
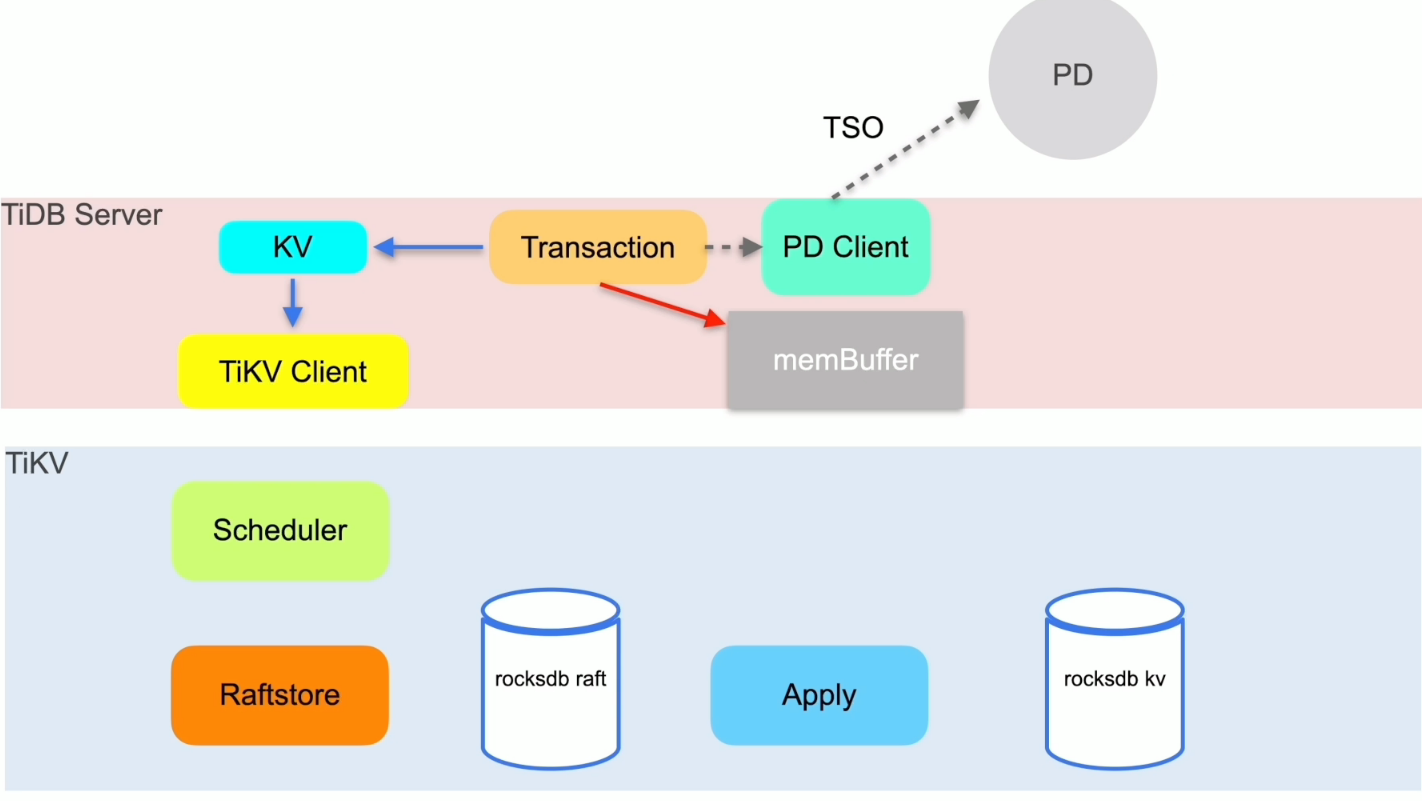
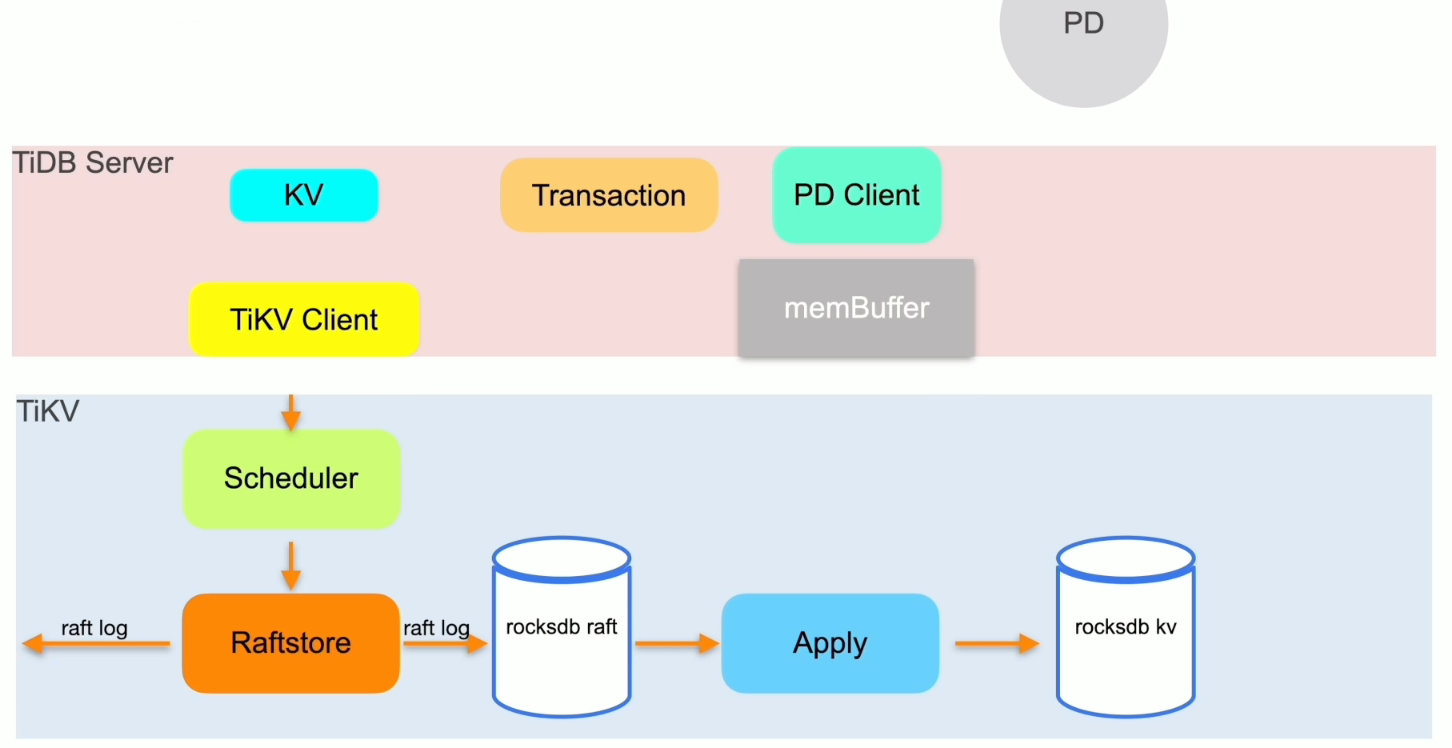
DDL的执行

数据对象

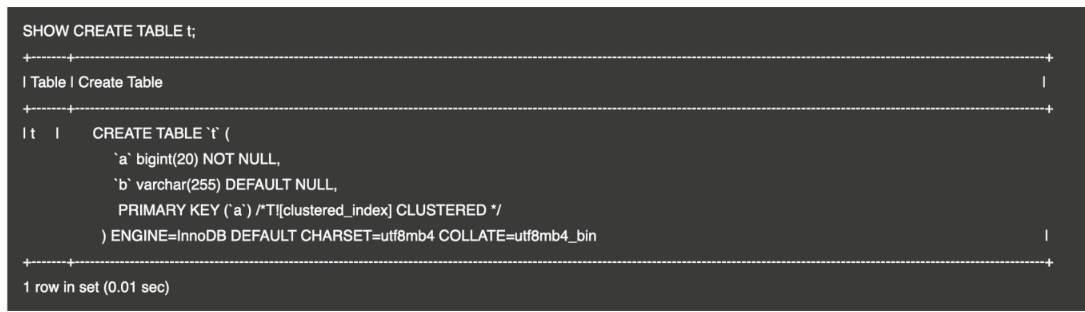
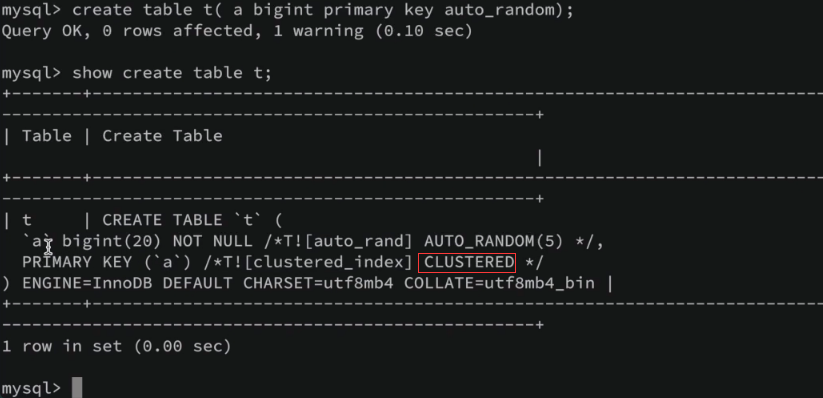
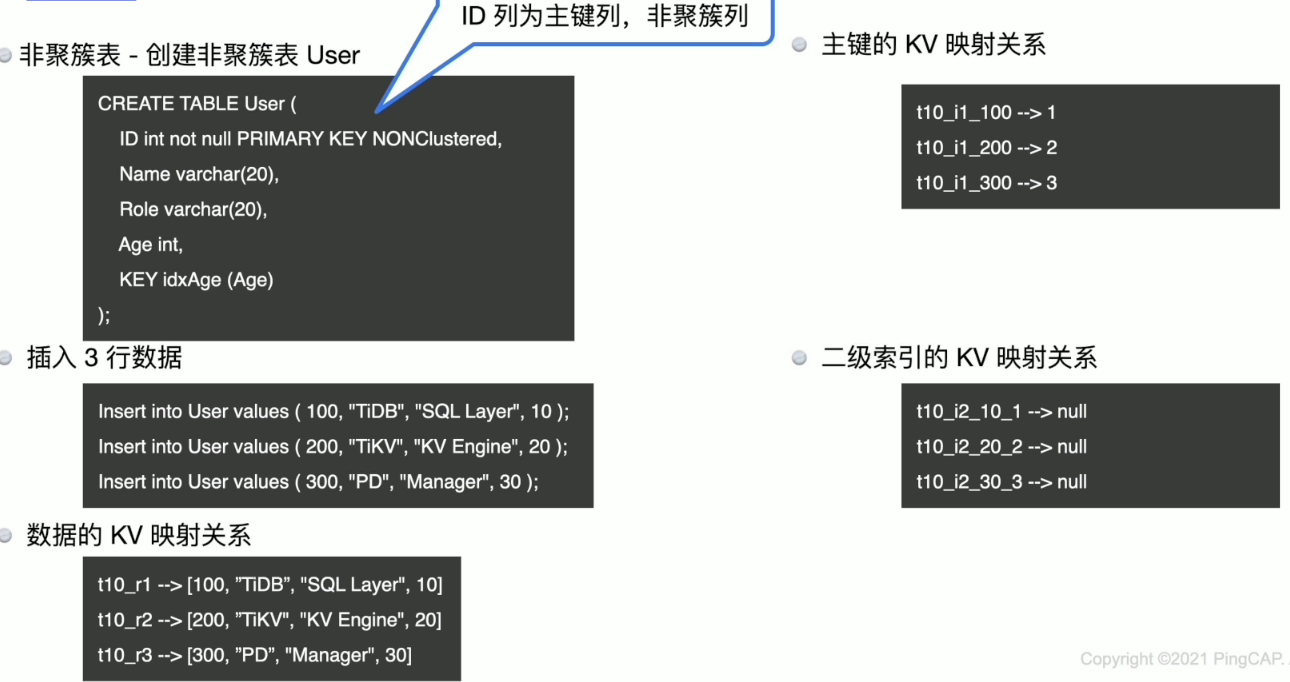
聚簇表与非聚簇表
聚簇表与非聚簇表详情 参考:TiDB PCTP 备战–TiDB Server 的 <关系型数据与 KV 的转化> 章节。
查询主键是否为聚簇索引
- 执行语句 SHOW CREATE TABLE
- 执行语句 SHOW INDEX FROM
- 查询系统表 information_schema.tables 中的 TIDB_PK_TYPE 列
添加、删除非聚簇索引
- TiDB 支持在建表之后添加或删除非聚簇索引。此时可以选择显式指定 NONCLUSTERED 关键字或省略关键字
ALTER TABLE t ADD PRIMARY KEY(b, a) NONCLUSTERED;
ALTER TABLE t ADD PRIMARY KEY(b, a); --不指定关键字,则为非聚簇索引
ALTER TABLE t DROP PRIMARY KEY;
ALTER TABLE t DROP INDEX `PRIMARY`;
添加、删除聚簇索引
- 目前 TiDB 不支持在建表之后添加或删除聚簇索引,也不支持聚簇索引和非聚簇索引的互相转换。
SHARD_ROW_ID_BITS
- 非聚簇表 NONCLUSTERED, TiDB 会使用一个隐式的自增 rowid,造成写入热点。
- SHARD_ROW_ID_BITS 通过调整隐式生成的 _tidb_rowid 的高位,从而更容易拆分不同的 region 来打散热点。
- SHARD_ROW_ID_BITS = 4 表示 16 个分片
- SHARD_ROW_ID_BITS = 5 表示 32 个分片
- 一般使用 SHARD_ROW_ID_BITS 的同时,会配合使用 PRE_SPLIT_REGIONS。在建表后即会将 Table 拆分成 2^(PRE_SPLIT_REGIONS) 个 Region。
-- 创建个非聚簇表, 并添加 SHARD_ROW_ID_BITS 来打散数据,并在建表后将表预切分为 4 个 Region
CREATE TABLE t (c int PRIMARY KEY NONCLUSTERED) SHARD_ROW_ID_BITS = 4 pre_split_regions = 2;
-- 修改表的打散随机位到 5
ALTER TABLE t SHARD_ROW_ID_BITS = 5;
分区表
- 当前支持的分区类型包括 Range 分区、List 分区、List COLUMNS 分区和 Hash 分区
- Range 分区,List 分区和 List COLUMNS 分区可以用于解决业务中大量删除带来的性能问题
- Hash 分区则可以用于大量写入场景下的数据打散
- 分区表的每个唯一键或主键,必须包含分区表达式中用到的所有列

TiDB 支持的数据类型
TiDB 支持除空间类型 (SPATIAL) 之外的所有 MySQL 数据类型,包括
- 数值型类型
- 字符串类型
- 时间和日期类型
- JSON类型
TiDB 表列的默认值
- 数值型类型、绝大部分字符串类型列的默认值必须是常量
- 时间和日期类型列的默认值可以使用函数作为默认值
- BLOB、TEXT 以及 JSON 不可以设置默认值
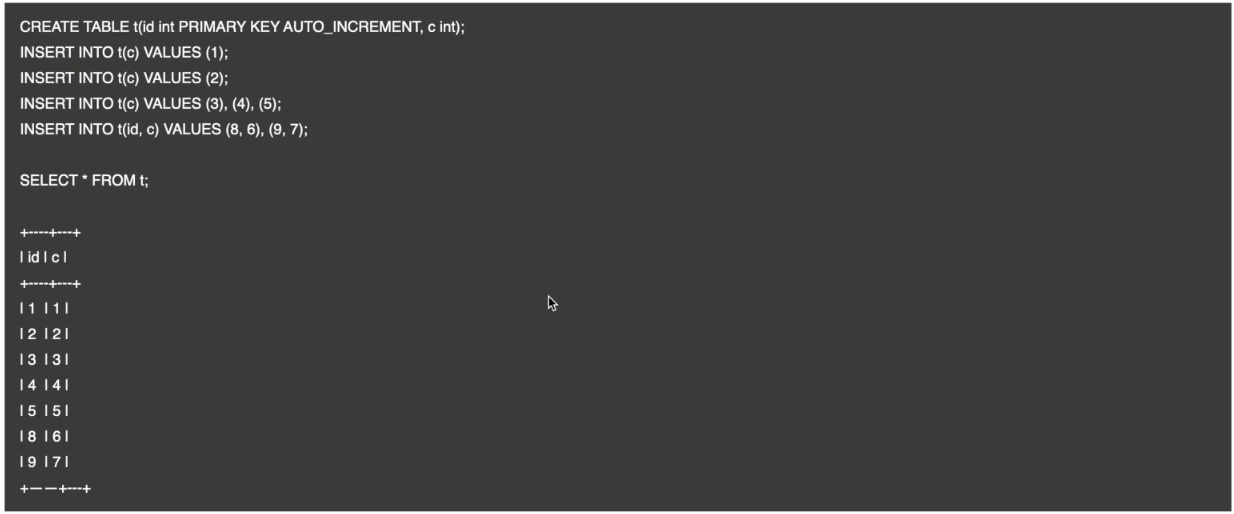
TiDB 自增 ID – AUTO_INCREMENT
AUTO_INCREMENT 的基本使用
AUTO_INCREMENT 的实现原理
- 每一个自增列使用一个全局可见的键值对用于记录当前已分配的最大ID
- 为了降低分布式系统分配自增 ID 的网络开销,每个 TiDB 节点会缓存一个不重复的 ID 段
- 当前预分配的 ID 段使用完毕或 TiDB 重启,都会重新再次申请新的 ID 段
AUTO_INCREMENT 的使用限制
- 必须定义在主键或者唯一索引的列上
- 只能定义在类型为整数、FLOAT 或 DOUBLE 的列上
- 不支持与列的默认值 DEFAULT 同时指定在同一列上
- 不支持使用 ALTER TABLE 来添加 AUTO_ INCREMENT 属性
- 需要通过 session 变量 @@tidb_allow_remove_auto_inc 控制是否允许通过 ALTER TABLE 来移除 AUTO_INCREMENT 属性; 默认是不允许移除此属性
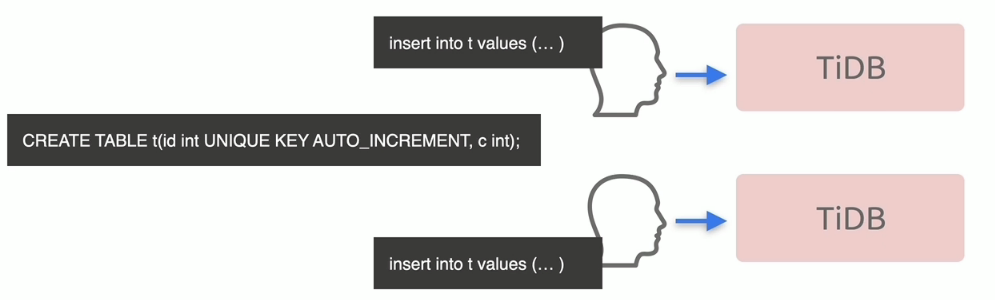
AUTO_RANDOM
AUTO_RANDOM 用于解决大批量写数据入 TiDB 时因含有整型自增主键列的表而产生的热点问题



AUTO_RANDOM 的实现原理
- AUTO_RANDOM 是一个8字节的 bigint 整数
- 其最高位为符号位
- 默认其 63 ~ 59 位为随机位(shard bits),每次插入行记录时随机生成一个 1~32 的随机数
- 若要使用不同长度的随机位可以调整 AUTO_RANDOM 后面括号中的数量
CREATE TABLE t (a bigint PRIMARY KEY AUTO_ RANDOM(3), b varchar(255));
AUTO_RANDOM 的使用限制
- AUTO_RANDOM 列类型只能为 BIGINT 类型
- 主键属性为 NONCLUSTERED 时,即使是整型主键列,也不支持使用 AUTO_RANDOM
- 不支持使用 ALTER TABLE 来修改 AUTO_RANDOM 属性,包括添加或移除该属性
- 不支持修改含有 AUTO_RANDOM 属性的主键列的列类型
- 不支持与 AUTO_INCREMENT 同时指定在同一列上
- 不支持与列的默认值 DEFAULT 同时指定在同一列上
- 插入数据时,不建议自行显式的指定含有 AUTO_RANDOM 列的值。这可能会导致该表提前耗尽用于自动分配的数值
SCHEMA 的限制
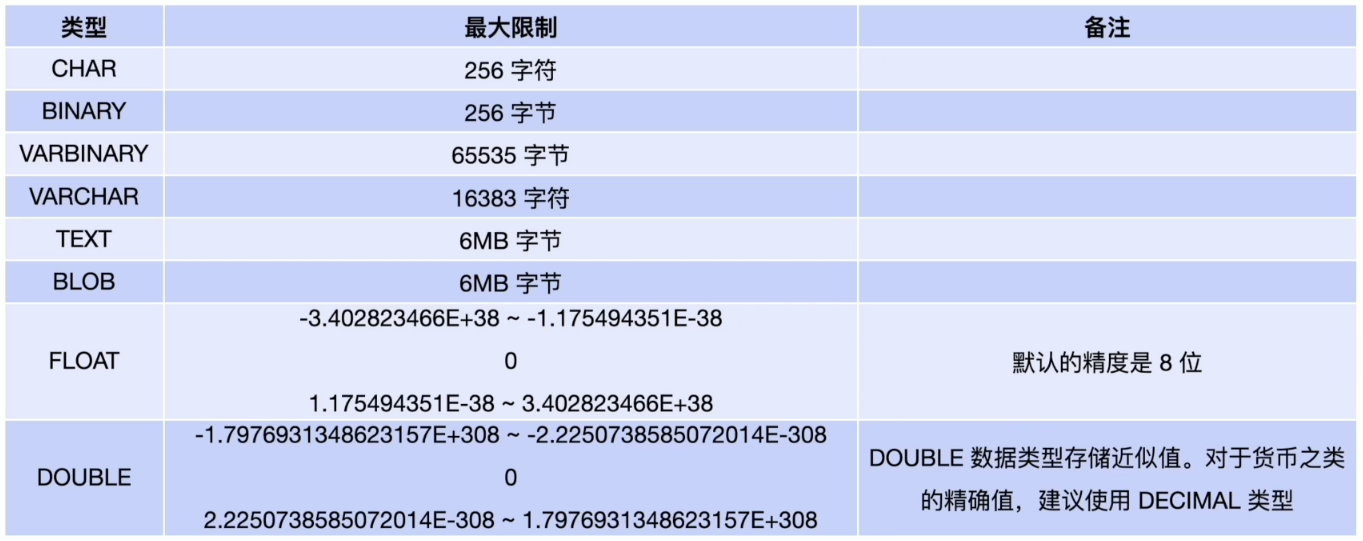
数据类型的限制
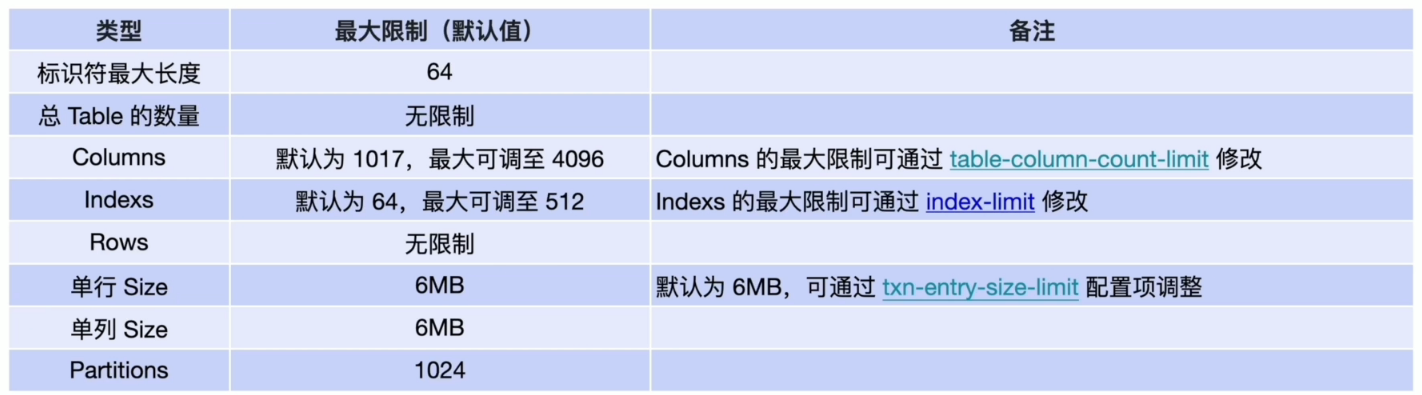
对象限制
SCHEMA设计建议
高兼容性 SCHEMA
- 适用从原来 MySQL 业务迁移到 TiDB 数据库上的表
- 建表时创建非聚簇表
- 为表添加 SHARD_ROW_ID_BITS 和 PRE_SPLIT_REGIONS 表提示
- 其他列保持原有设计

高性能 SCHEMA
- 适用在 TiDB 数据库上新添加的表,或迁移的表兼容以下改造; 特别需要注意原业务使用是否要求主键 ID 单调连续性
- 建表时创建聚簇表
- 主键使用具有较强随机性的列,或在使用自生成ID,使用 AUTO_RANDOM 属性代替 AUTO_INCREMENT 来创建主键
- 准确选择列的数据类型。能用整数型或日期类型的列,避免使用字符串类型
- 避免创建无效的索引

TiDB 数据库索引设计
索引的 KV 映射原理
- SCHEMA 的 KV 映射原理

- 唯一索引 & 非聚簇表的主键

- 二级索引

- 索引实例
索引的设计
在 Percolate 模型中一个事务的写入可能会有一个 Primary Key 和多个 Secondary Key
索引的创建
- TiDB 的索引创建语法与 MySQL 的索引创建语法保持兼容
- 索引可以在随建表时一并创建

- TiDB 在创建索引时不会阻塞表的数据读写
- 索引创建支持 ALTER TABLE… ADD INDEX 语句在已有表中添加一个索引
-- 创建普通索引
ALTER TABLE t1 ADD INDEX idx_t1_c2(c2);
-- 创建唯一索引
ALTER TABLE t1 ADD UNIQUE INDEX uidx_t1_id(`id`);
- TiDB 索引创建目前尚不支持在一个 ALTER TABLE… ADD INDEX 语句中同时创建或修改多个索引
联合索引
- 联合索引的在搜索使用时遵循最左匹配原则

- 减小开销: 建一个联合索引(col1 ,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引
-- 可以有效使用索引的场景
select * from t2 where c1 between 1 and 20;
select * from t2 where c1 = 3 and c2 > 5 and c2 < 10;
select * from t2 where c1 = 1 and c2 = 10 and c3 between 1 and 200;
-- 部分使用索引的场景
select * from t2 where c1 between 1 and 20 and c2 = 100; --(col1)
select * from t2 where c1 = 3 and c2 > 5 and c2 < 10 and c3 = 100; --(col1,col2)
-- 不能使用索引的场景
select * from t2 where c2 = 20 and c3 = 100;
select * from t2 where c3 = 100;
- 覆盖索引: 当通过索引可以完整获取数据,那么 TiDB 可以直接通过遍历索引取得数据,而无需回表,减少io操作。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一
select c1 from t2 where c1 = 1 and c2 = 10 and c3 between 1 and 200;
select c1, c2, c3 from t2 where c1 = 1 and c2 between 1 and 200;
表达式索引
- 表达式索引是一种特殊的索引,能将索引建立于表达式上
-- 表达式索引中的表达式需要用(和)包围起来,否则会报语法错误
CREATE INDEX idx1 ON t1 ((lower(col1)));
- 可以通过查询变量 tidb_allow_function_for_expression_index 得知哪些函数可以用于表达式索引

- 当查询语句中的表达式与表达式索引中的表达式一致时,优化器可以为该查询选择使用表达式索引

不可见索引
- 不可见索引 (Invisible Indexes) 不会被查询优化器使用
- “不可见”是仅仅对优化器而言的,不可见索弓|仍然可以被修改或删除
- 即使用 SQL Hint USE INDEX 强制使用索引,优化器也无法使用不可见索引
- 不允许将主键索引设为不可见
- ALTER INDEX 语句用于修改索引的可见性,可以将索引设置为 Visible 或者 Invisible

索引使用的注意事项
- 不支持 FULLTEXT,HASH 和 SPATIAL 索引
- 不支持降序索引 (类似于 MySQL 5.7)
- 无法向表中添加 CLUSTERED 类型的 PRIMARY KEY
- 不支持删除 CLUSTERED 类型的 PRIMARY KEY
- 不支持类似 MySQL 中提供的优化器开关 use_invisible_indexes=on 可将所有的不可见索引重新设为可见
索引的运维技巧
- 查看索引的 Region 分布
SHOW TABLE [table_name] INDEX [index_name] REGIONS [WhereClauseOptional];

TiDB 数据库系统表使用
TiDB系统表存储位置
- mysql 存储 TiDB 系统表
- mysql.user 等
- INFORMATION_SCHEMA 提供了一种查看系统元数据的 ANSI 标准方法
- 与 MySQL 兼容的表如: TABLES、PROCESSLIST、 COLUMNS 等等
- 自定义的表如: CLUSTER_CONFIG、CLUSTER_HARDWARE、TIFLASH_REPLICA 等等
- METRICS_SCHEMA 是基于 Prometheus 中 TiDB 监控指标的一组视图
- PERFORMANCE_SCHEMA 目前为与 MySQL 兼容保留了部分视图(大部分内部使用)
TiDB 常用集群信息系统表
mysql 数据库
mysql.user\ mysql.db\ mysql.tables_priv\ mysql.columns_priv: 用户账户以及相应的授权信息
- mysql.user 用户账户,全局权限,以及其它一些非权限的列
- mysql.db 数据库级别的权限
- mysql.tables_priv 表级的权限
- mysql.columns_priv 列级的权限( 目前不支持 )
mysql.GLOBAL_VARIABLES
- 通过系统表方式查看 TiDB 全局变量
- 支持对系统表中 VARIABLE_VALUE 的修改
mysql.tidb
- 以 Key\Value 形式存储集群状态的表
- 通过修改 mysql.tidb 中相关 VARIABLE_VALUE 可以调整相关系统行为
INFORMATION_SCHEMA 数据库
INFORMATION_SCHEMA.CLUSTER_INFO
- 提供集群当前的拓扑信息,各个节点的版本信息、版本对应的 Git Hash、各节点的启动时间、各实例的运行时间
- 当集群进行升级或者打了 patch 版本,确定各各组件版本是否打好,可以查询此表
- VERSION: 对应节点的语义版本号
- START_TIME: 对应节点的启动时间
- UPTIME: 对应节点已经运行的时间
INFORMATION_SCHEMA.CLUSTER_CONFIG
- 表用于获取集群当前所有组件实例的配置
- 当 TiDB v4.0 后引入此系统表提高了易用性
- TYPE: 节点的类型,可取值为 tidb,pd 和 tikv
- INSTANCE: 节点的服务地址
- KEY: 配置项名
- VALUE: 配置项值
INFORMATION_SCHEMA.DDL_JOBS
- DDL_JOBS 表为 ADMIN SHOW DDL JOBS 命令提供了一个 INFORMATION_SCHEMA 接口
- 方便我们通过 SQL 查询和过滤相关表近期的 DDL 变更情况
运维常用系统表查询
系统慢日志查询
- 搜索某个用户的 Top N 慢查询:

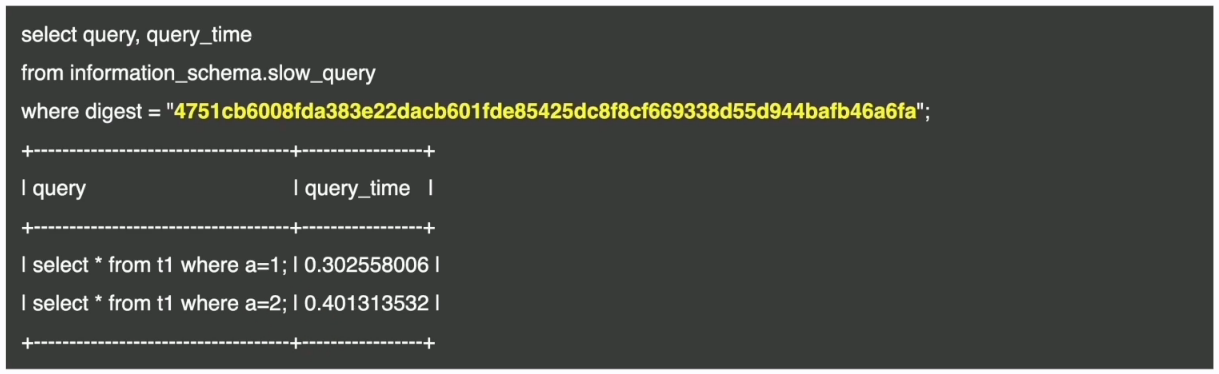
- 根据SQL指纹搜索同类慢查询:
- 先根据最近慢语句 List 查找特定慢语句:

- 再根据 digest 确定同类慢查询:
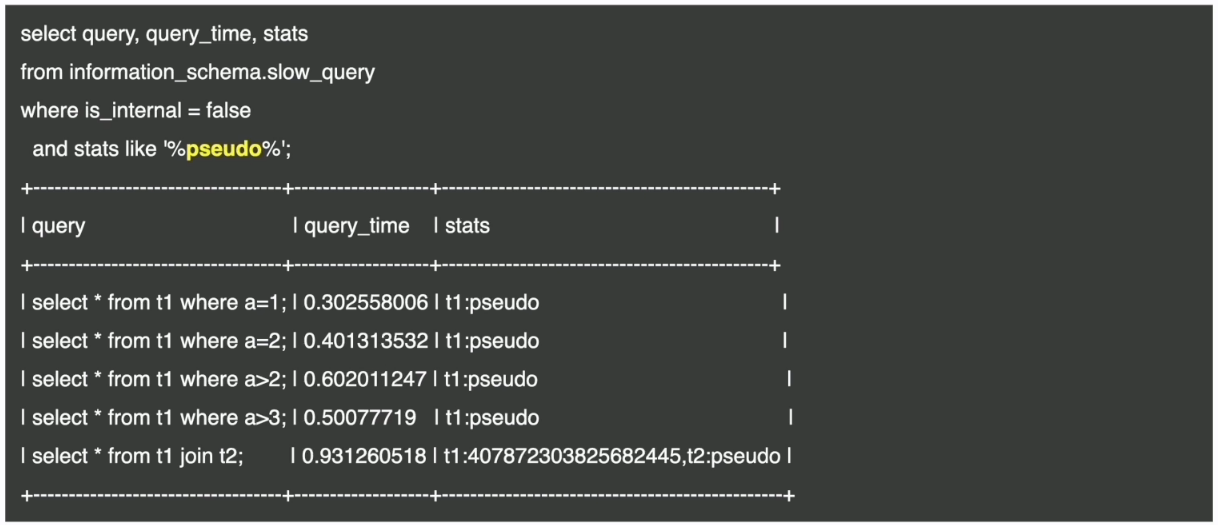
- 搜索统计信息为 pseudo 的慢查询 SQL 语句:
系统读写热点查询
- 统计当前读写热点表:

- 统计当前读写热点 STORE:

SQL堵塞查询
- DATA_LOCK_WAITS
- 集群中所有 TiKV 节点上当前正在发生的悲观锁等锁
- 仅拥有 PROCESS 权限的用户可以查询
- 从所有 TiKV 节点实时获取
- 如果集群规模很大、负载很高,查询该表有造成性能抖动的潜在风险
- DEADLOCKS
- 提供当前 TiDB 节点上最近发生的若干次死锁错误的信息
- 默认容纳最近10次死锁错误的信息
- TIDB_TRX
- 返回了所有 TiDB 上正在执行的事务信息
- 仅拥有 PROCESS 权限的用户可以查询
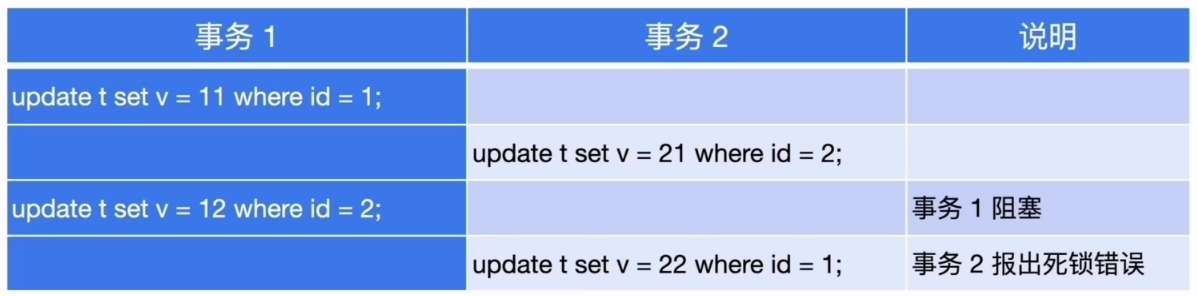
死锁问题排查
- 使两个事务按如下顺序执行:
- 查询 DEADLOCKS 表,来确定死锁情况:

「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
