




我们继续对BDAS进行相关的了解和介绍,继续看这张图:
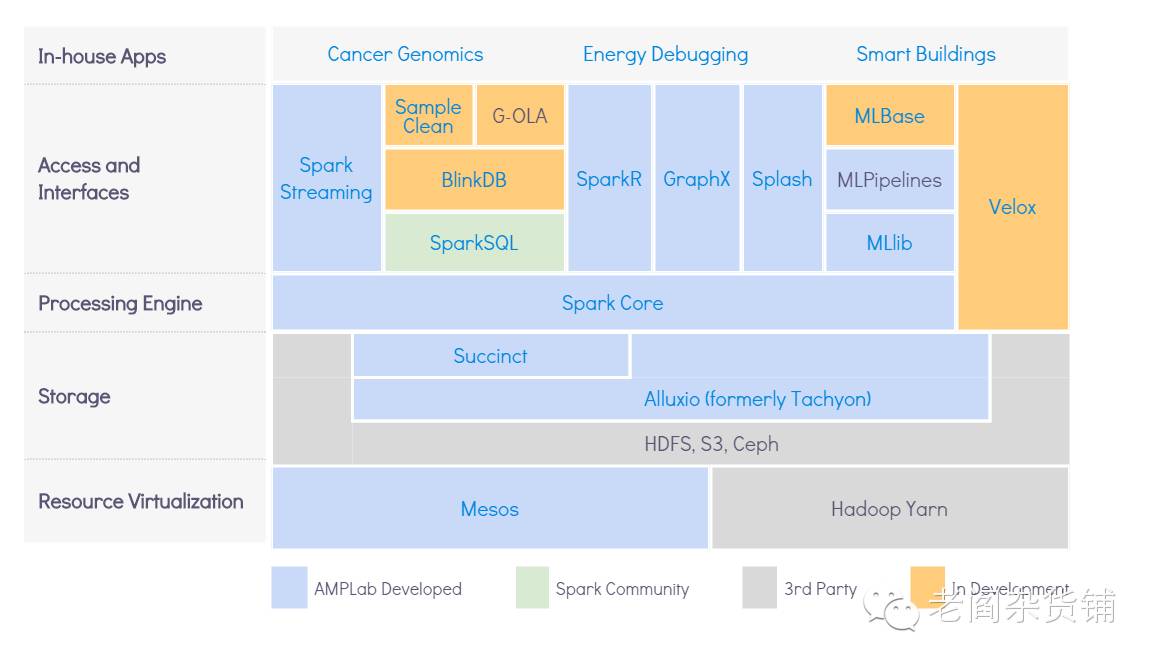
讲完了资源管理,也讲过了存储。到了计算层,也就是大数据的处理层,无疑就是最火热的明星Spark了,在这里将BDAS将Spark Core放在了处理层,SparkSQL,Spark Streaming都放在了访问和接口层。关于Spark,由于现在Spark太火热了,相关的资料网上有一大堆,我这里也就不过多的赘述了,只是稍微的提一下Spark 2.0。
当前的Spark最新版本是1.6.1,不过下一个要发布的版本却不是Spark 1.7,而是Spark 2.0,为什么是Spark 2.0呢? 从Matei的2月份Spark Summit上的演讲中可以看到,这是下一个重要的Spark发布版本,包含了过去两年学到的所有的东西,因此是一个大的版本的升级,会有API的变化。只有大的版本的升级才会有API的变化,小版本的升级之后有API的增加或者一些新的特性。 那Spark 2.0会主要包含哪些新的特性呢?
钨丝项目2.0
基于Spark SQL/Data Frame的结构化流式处理Structured Streaming
统一DataSet和DataFrame
详细的细节大家可以看Matei的片子,总的来讲就是:
优化性能。从钨丝项目开始,Spark开始自己管理内存,到钨丝2.0,在本地内存管理和代码生成方面则取得了更大的进步。这无疑也是大数据处理发展到现在的一个方向。Spark引入SparkSQL和DataFrame API无疑使得钨丝项目可以更好的进行。对于大部分程序员来讲,不合理的用Spark Core来写程序勿容置疑不如将优化交给Spark的优化器。
实时流式处理的大升级。大数据初期阶段,MapReduce让人们可以实现在大数据上实现分析。不过离线处理毕竟不能够充分发挥数据驱动决策的价值,尤其是很多场景需要非常高的实时性,比如广告、征信、乃至反恐等等。于是就有了流式的计算框架,比如Storm,再比如Samza等等。Spark在起步阶段就希望能够将流式处理和批式处理用一个框架来表达,但是在基于Spark RDD这个模型来进行处理时,流式处理总是有些别扭,只能是微批次的概念,并且用DStream这个方式来进行表达。Spark很成功,不过Spark Streaming却并不好用。尤其是在这个方面有了越来越多的竞争对手,比如Flink。终于Spark 2.0决定将Spark Streaming做大升级,引入新的Structured Streaming,基于SparkSQL和DataFrame来进行实现。这也终于让Spark的流式处理和批式处理的表达达到一致。细节大家可以去找Reynold Xin的片子和JIRA来看。
开发更容易。Spark刚出来的时候,大家不得不去了解RDD,开发也是面向RDD的各种操作,虽然容易理解,不过不是那么容易开发。随着Spark SQL和DataFrame API的引入,开发变得越来越简单。不过DataFrame本身在类型安全上会给开发者带来困难,而DataSet则帮助解决了这个问题。DataSet可以理解为类型化的DataFrame,对于开发人员,尤其是java 开发人员更容易理解和使用。
在访问接口层,Spark Streaming, Spark SQL, MLLib, SparkR, GraphX这里都不需要过多的赘述,很多Spark使用者或多或少的都会用到这些东西来完成日常的数据处理工作。下边我们来介绍其他的几个项目。
BDAS之BlinkDB
在做大数据分析时,尤其是统计类型的分析,很多情况下并不需要做精确的统计分析,那有没有办法可以在牺牲一定的精确度的情况下显著降低计算的开销,从而更快的得到结果呢? 答案就是利用采样来完成。BlinkDB就是一个在大数据上利用采样降低精确度来提高效率的一个并行计算查询引擎。

非常不错的想法,benchmark测试也有不错的性能,可惜的是,BlinkDB的发展实在是慢,到现在还是alpha 0.2.0版本。从github上看,代码已经有两年没有更新了,希望后边这个项目能够继续更新并且变得更活跃。
BDAS之SampleClean

做数据科学相关的工作最花时间的是什么?我想很多人都会说是数据清洗和准备数据。SampleClean就是BDAS中关于数据清洗的一个项目。数据清洗的工作离不开机器、算法和人。一般的数据清洗的过程是数据分析师先采样一些小样本数据,手工修复错误的数据并且评估影响,在对数据充分了解后,进一步优化数据清洗过程使得数据更精确和满足需求。数据清洗过程无疑是一个迭代过程,SampleClean定义了一些可以互换和编制的物理和逻辑计算算子,比如采样、相似度关联、过滤、抽取等等,从而使得使用者可以非常方便的构造数据清洗的处理流程。另外,SampeClean还使用机器学习的算法,采用一种叫做主动学习的技术,可以学习人对数据清洗和处理的过程,从而自动的去做缺失数据的填充、脏数据的修正和清理等等。在TalkingData数据部门,很多数据的处理也是类似的方式,人、机器、算法结合起来来进行数据的清洗和规范化。
BDAS之Splash
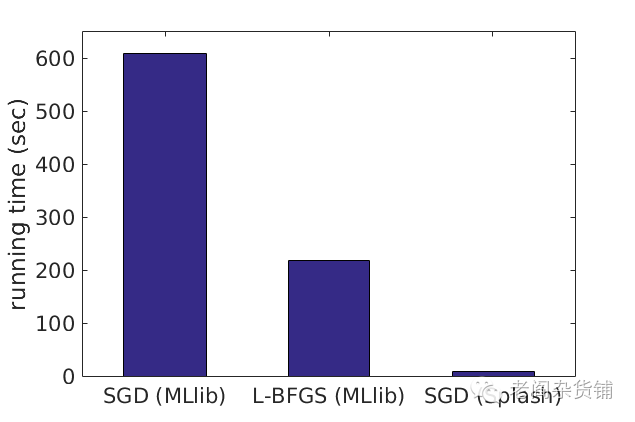
在Spark中大家都知道机器学习库MLLib,可是对于一些随机学习算法,如何高效的在集群环境中并发执行则是一个挑战。Splash是AMPLab开发的一套并行的随机学习算法的通用框架。利用Splash,你可以方便的开发随机学习算法,而不用担心并行化的问题。下图给出了利用Splash和不用Splah的一些对比:
BDAS之KeyStoneML
机器学习过程很多情况下也是由pipeline组成。KeyStoneML是AMPLab用Scala语言开发的一套机器学习pipeline构建框架。通过它,可以非常方便的在Spark上构建机器学习的pipeline。类似的pipeline构建程序例子如下:
val trainData = NewsGroupsDataLoader(sc, trainingDir)val predictor = Trim andThen LowerCase() andThen Tokenizer() andThen NGramsFeaturizer(1 to conf.nGrams) andThen TermFrequency(x => 1) andThen (CommonSparseFeatures(conf.commonFeatures), trainData.data) andThen (NaiveBayesEstimator(numClasses), trainData.data, trainData.labels) andThen MaxClassifier
可以看到,KeystoneML实现了一些流程运转的关键字,从而可以方便的编织机器学习的pipeline。
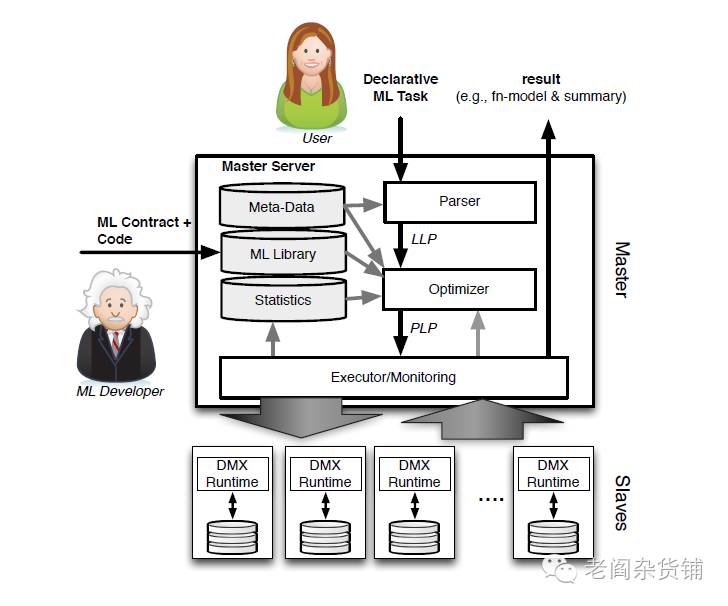
BDAS之MLBase
MLBase是一套分布式机器学习系统,其目的是使得机器学习能够被不同的用户使用,显著的降低分布式机器学习的使用门槛。它包括:
一个简单的声明式的调用机器学习任务的语言
一个创新的可以动态适应的算法优化选择器
一系列的高层算子,使得算法科学家可以方便的实现机器学习算法而不用了解底层的系统知识
一个运行时优化器,可以对高层算子在数据上的执行进行优化。
其架构为:
从论文的描述看,整个系统还是很值得期待,无论是数据科学家,还是数据分析师,甚至是数据工程师都可以利用MLBase提供的能力进行机器学习,详细的内容可以去查看对应的论文,遗憾的是网站上相关的内容还比较少。
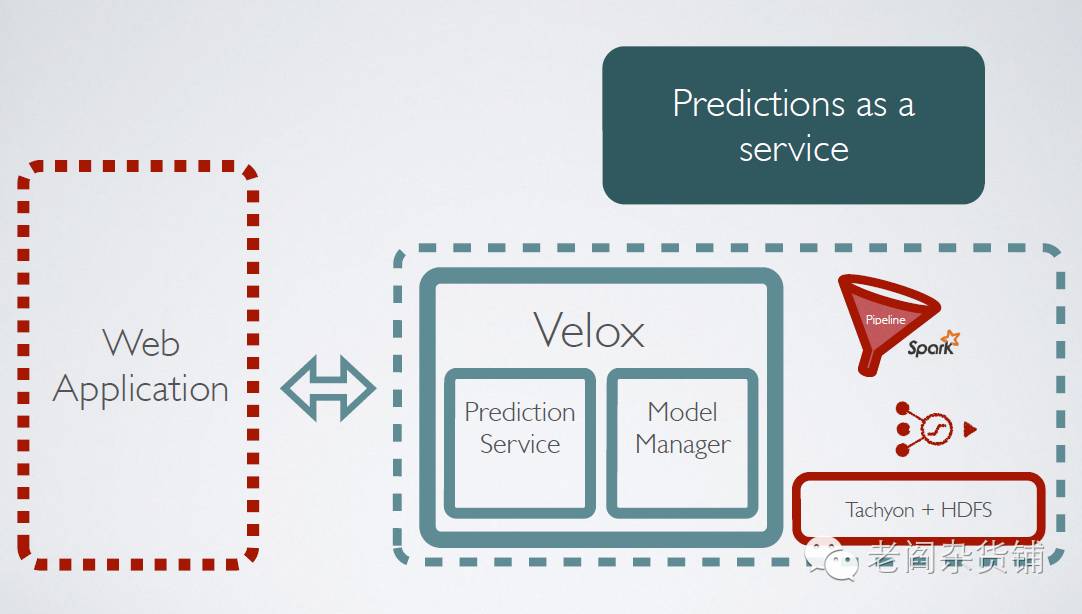
BDAS之Velox
最后一个需要介绍的是Velox。Velox是AMPLab最新的一个机器学习相关的项目,其目的是构建一个能够进行机器学习预测服务的系统。包括:
支持实时个性化推荐
集成Spark和KeystoneML
可以自动进行批量和实时的模型训练
其简单架构为:
整个项目现在处于快速开发中,github的地址是:https://github.com/amplab/velox-modelserver
关于BDAS相关的项目,先介绍到这里,基本上每个项目相关的细节,都可以从论文中找到。这些项目有的由于某些原因不是特别的活跃,而相当一部分项目则是非常的活跃,并且在大数据领域有着非常重要的影响。AMPLab作为一个将算法(Algorithms)、机器(Machine)、人(Person)非常好的融合的实验室,在大数据分析领域从2012年成立开始,逐渐的引领大数据分析的潮流。作为大数据从业者,我们无疑需要密切关注他们,去了解他们的思想,站在巨人的肩膀上,我们无疑也能够看得更远。
