




TiDB数据库高可用概述
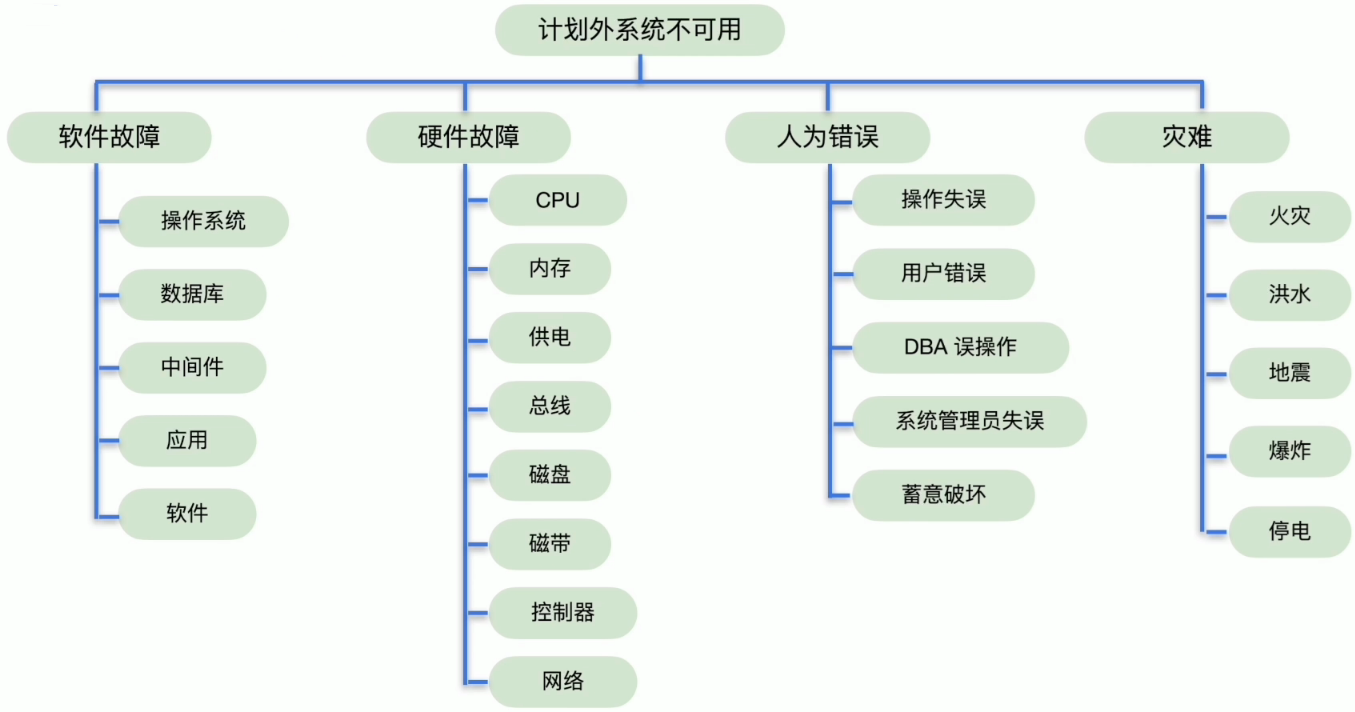
计划外系统不可用原因
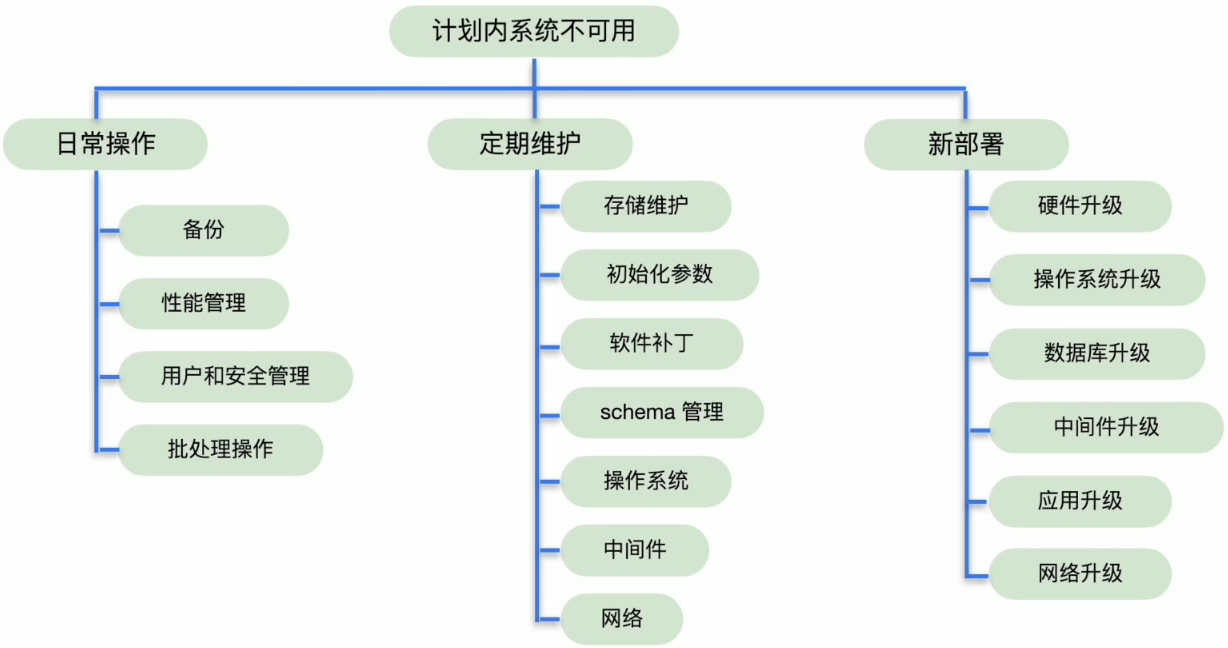
计划内系统不可用原因
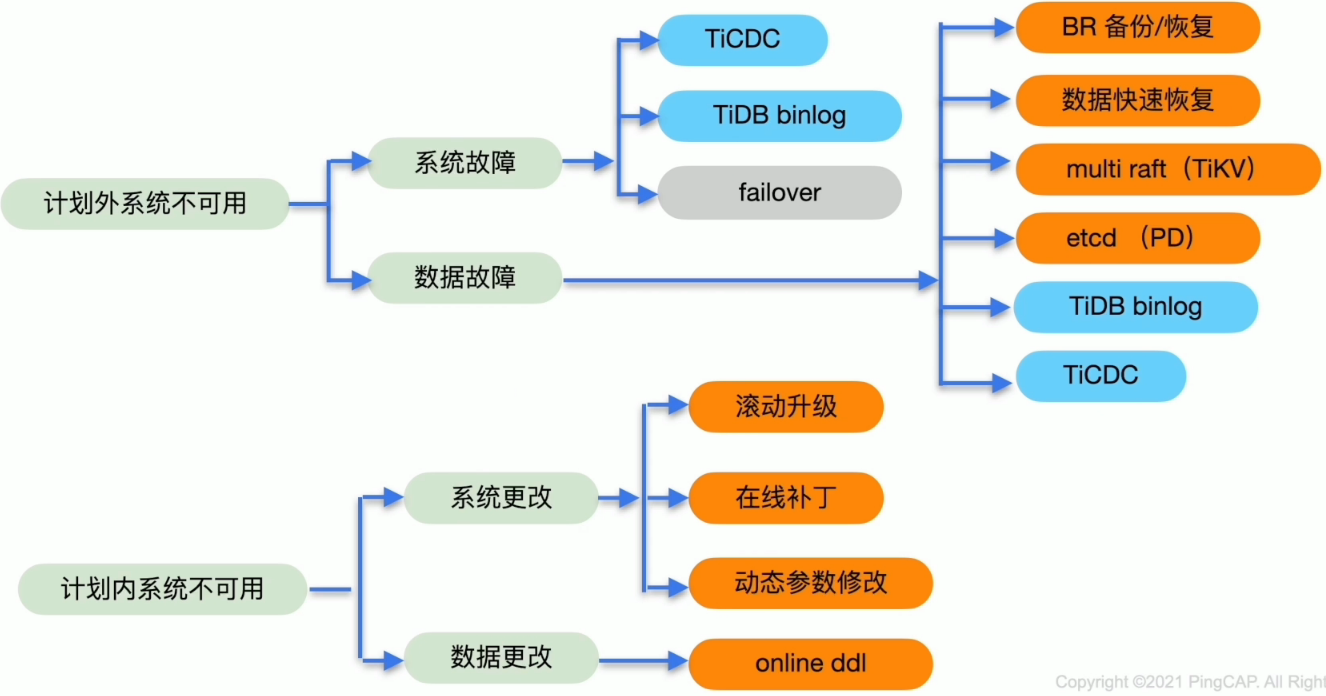
TiDB 系统不可用解决方案
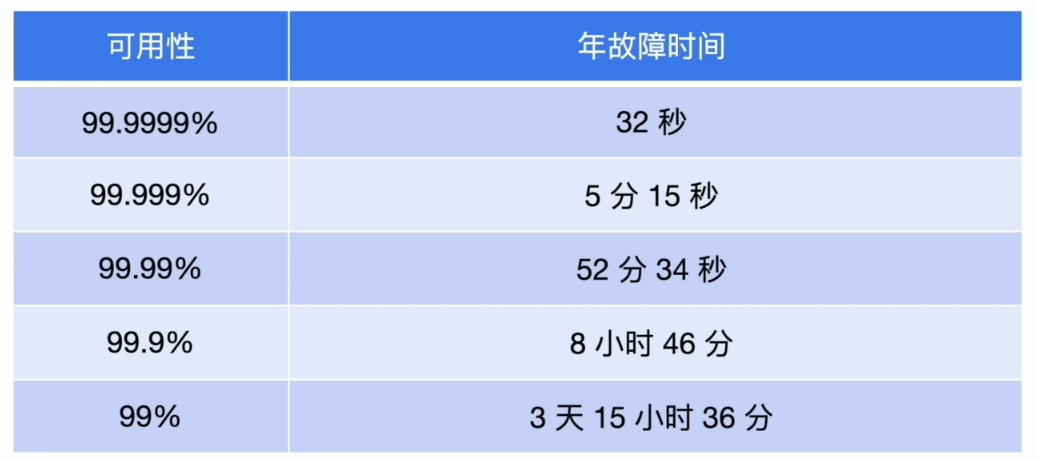
高可用的评判指标
用可提供服务的时间来评判
不可用时间=从故障发生到故障恢复所用时间
定义恢复时间目标(Recovery Time Objective, RTO)
指所能容忍的业务系统停止服务的最长时间,也就是灾难发生到业务系统恢复服务功能所需要的最短时间

定义恢复点目标(Recovery Point Objective, RPO)
指业务系统所能容忍的数据丢失量,用时间表示,是指灾难发生到数据上一次备份的时间。

Raft 与 Multi Raft

- Leader选举:
- 通过投票产生一个节点成为 Leader
- 检查宕机/网络隔离,选举新 Leader
- Log 复制︰
- Leader 负责接收客户端请求,在本地追加日志
- Leader 将日志复制给其他节点(并覆盖不一致的日志)
- 约束∶
- Leader 由超过一半节点投票选出
- Log 需复制给一半以上节点
- 持有最新日志的节点才能被选为 Leader
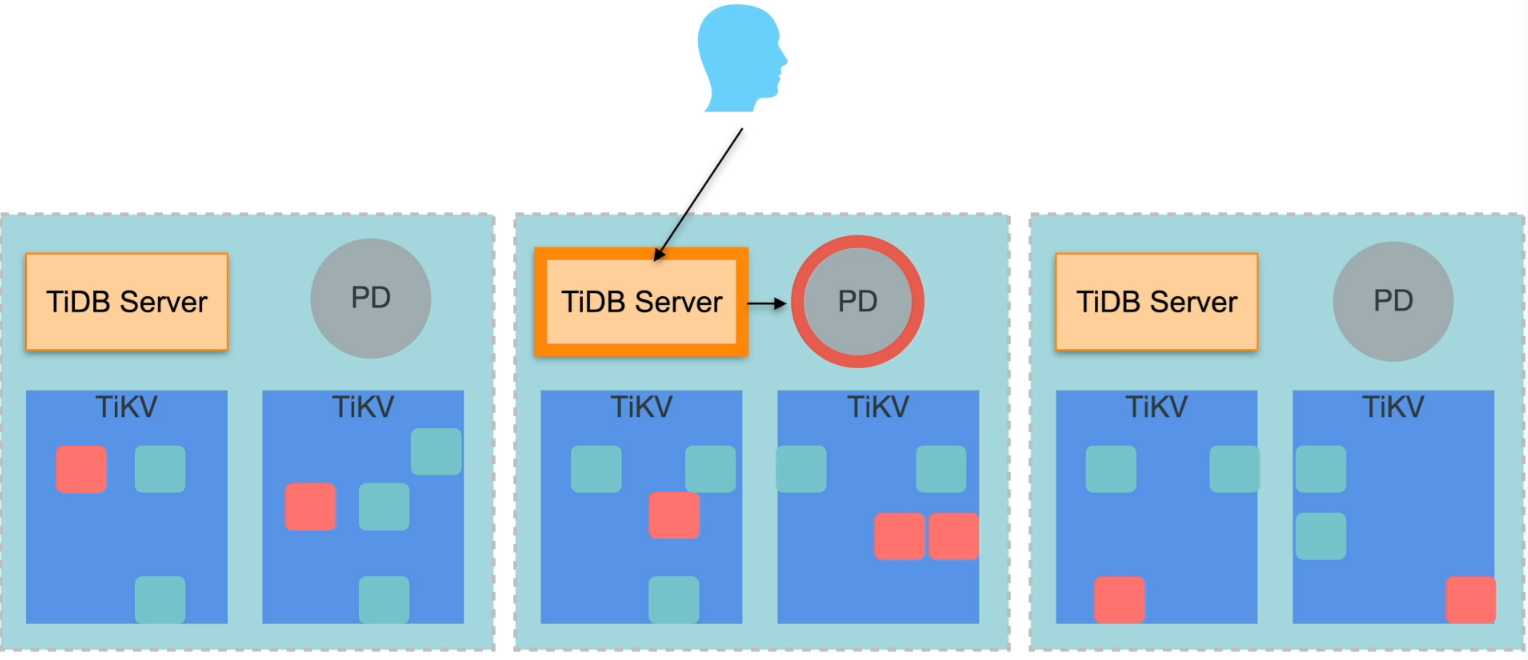
TiDB Server 的高可用特性

- 无状态∶
- 数据由 TiKV 存储
- TiDB 之间不通信(通过 TiKV 和 PD )
- 随时增加或删除
- 本身不支持 Failover,需要业务配合
TiKV 的高可用特性
- 故障恢复
- 少数 Follower 故障或隔离不影响 Leader 服务
- Leader 故障或者隔离后,Follower 心跳超时会自动开始选举流程
- 只要有一半以上节点存活,一定能选出新的 Leader,从而恢复服务
- 数据一致性
- 写入数据时,Leader 会保证日志被复制到大多数节点
- 当一部分节点故障或隔离后,只要有一半以上节点存活,其中至少有一个节点包含最新的日志
- Raft 协议总是选择包含最新日志的节点当作 Leader
- 综上所述,符合约束,则不会发生数据丢失
PD 的高可用特性
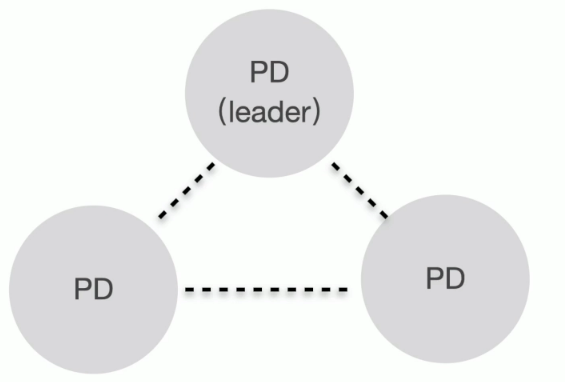
- Leader 节点提供所有服务,Follower 为 standby
- 依赖于内嵌 etcd 实现 leader 选举
- 一致性的要求
- 分配严格单调递增的 timestamp
- 同一时刻只能有一个 leader
CAP 与 TiDB
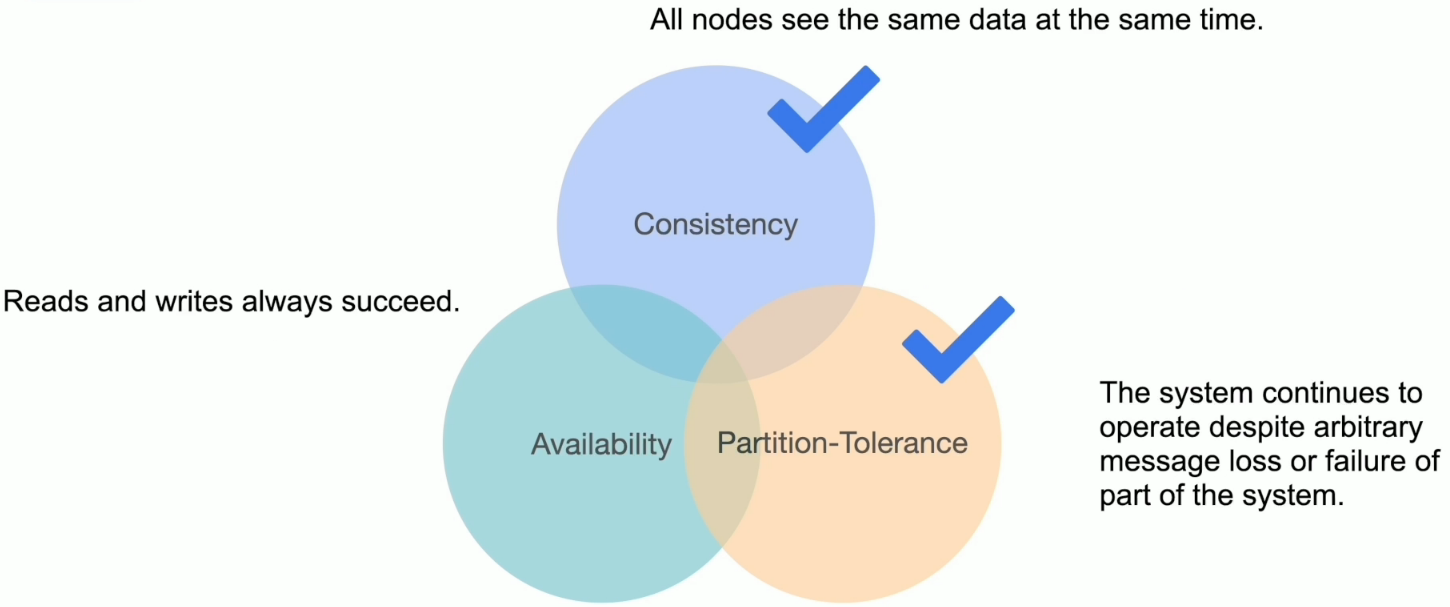
TiDB 数据库的高可用特性
- TiDB 数据库提供强—致性。
- 如不能保证强一致性,则拒绝服务。
- 在 PD 和 TiKV 至少存活半数以上副本情况下,容忍一定限度内的节点宕机或隔离。
- PD 和 TiKV 可以自动故障转移至存活的大多数副本处。
- TiDB Server 不保证所有节点同时提供服务。
- 故障解决会伴随有服务的降级。
TiDB 数据库常用高可用架构
高可用架构设计中考虑的问题
- 网络延迟
- Raft 协议要求写入复制到最少2个节点。(三副本)
- Leader 有可能与发起读取的 TiDB Server 不在一个区域。
- 读取要访问 PD 获取一次TSO,事务要获取2次。
- Raft 协议本身
- Raft 协议要求写入复制到最少2个节点。(三副本)
- 副本数最好为奇数。
- 副本的分布最好与 TiKV 节点的分布相结合。
- 其他
- 多活要求。
同城三中心架构

- 特点∶
- 数据副本分布在 3 个数据中心或可用区
- 同城网络延迟较小
- 多活特性
- RTO 较小,RPO 为 0
- 问题:
- 写入与读取延迟高
- 写入与读取延迟高
同城两中心架构
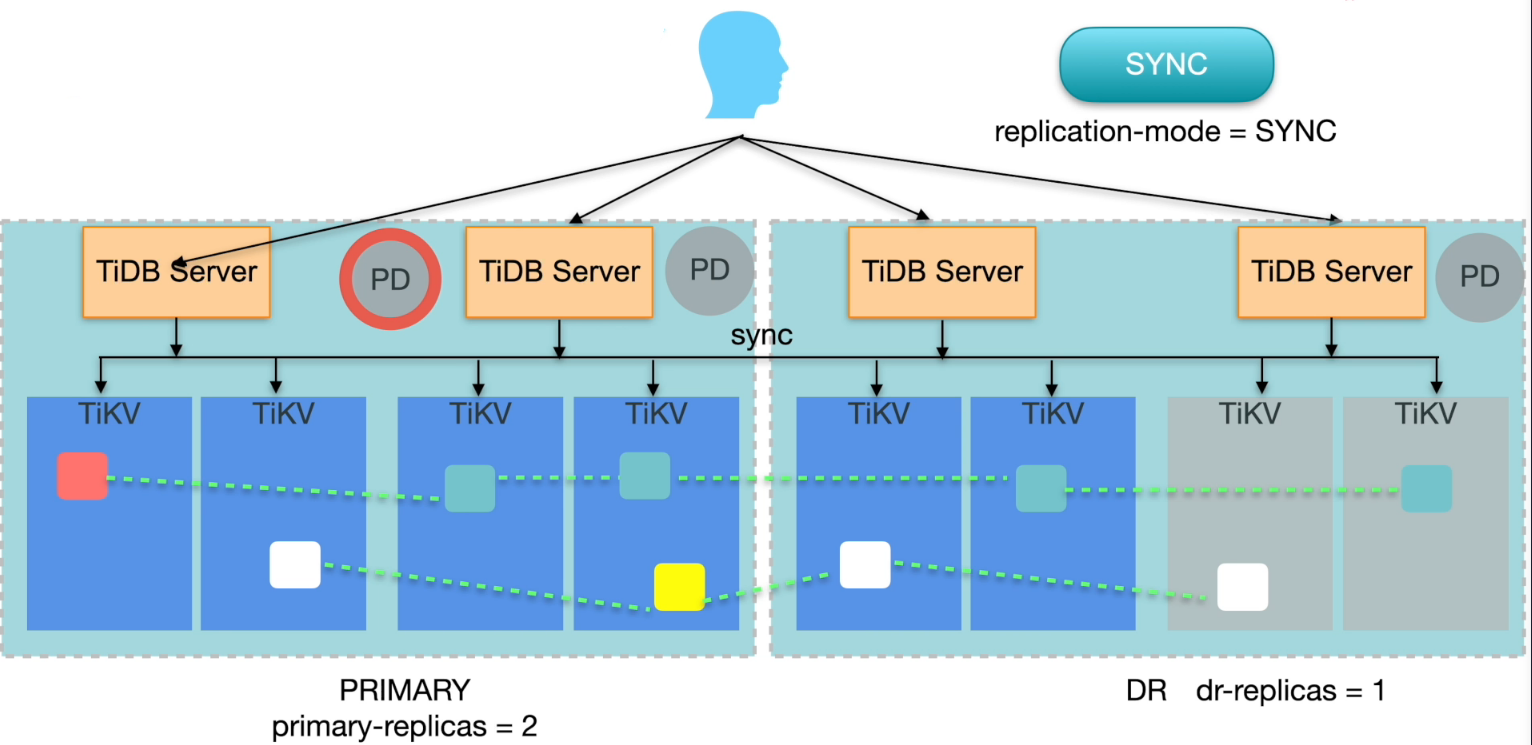

两地三中心架构

- 特点∶
- 可以保证任一数据中心失效后,服务可用不发生数据丢失
- 问题:
- 当两中心失效后,异地灾备不存在大多数副本,服务不可用
- 异地灾备为异步复制,无法保证一致性恢复
- 网络专线成本高
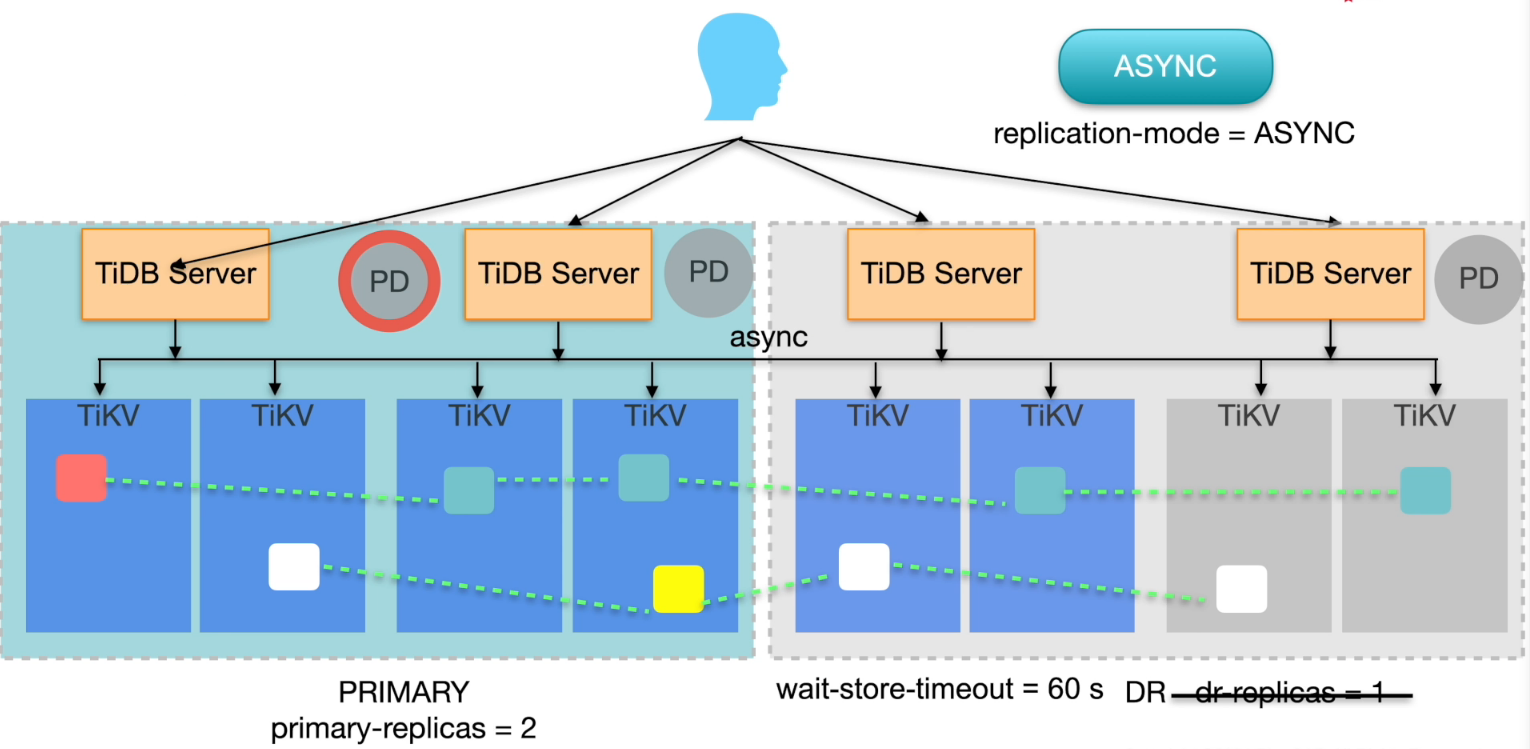
异步复制
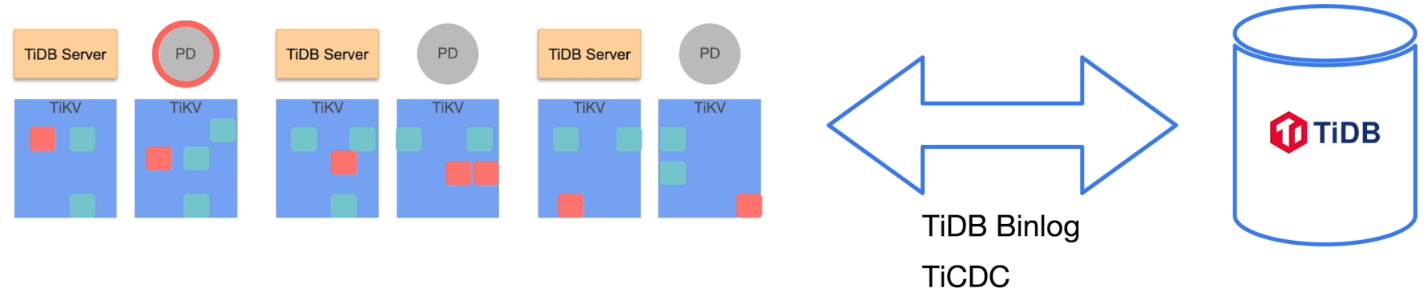
- 使用 TiDB binlog 或者 TiCDC 组件进行异步复制
- 会丢失数据(RPO不为0)
- 有损恢复后,保证一致性
- 主集群或者从集群内部具有高可用功能
集群升级方案
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
