





作者:王成
(github: chengwang15)
引言:
在日常的业务数据分析场景中,解析复杂的 JSON 文件并提取出有用的信息进行分析是非常高频的需求。但是解析复杂的 JSON 数据并不是一件易事,需要在理解数据结构的基础上,再配合一些 JSON 处理包,像剥洋葱一样一层一层地往里剥,费时又费力。
而在本文中,我们将结合具体的示例为大家介绍:如何利用 Byzer-lang 的内置 ET 插件简单快速地进行 JSON 数据的处理和分析,以及在遇到复杂处理逻辑时的最佳实践是什么。
那就接着往下看吧~
当我们从数据源中按照不同的业务需求获取数据时,数据会以不同层级嵌套的 JSON 结构的形式呈现。在 Byzer-lang 中,直接使用内置的 JsonExpandExt ET,就能方便地处理结果集,将一个 JSON 字段展开为多个字段方便后续的分析处理。
JSON 结构大体上可以分为两种类型:JSON Object 和 JSON Array 。
第一种类型:JSON Object
JSON Object 形如 '{ "data": [1,2,3,4] }'
以如下数据为例:
-- 首先我们创建了一个 mock_data 表,并将 stu 设置为一个层级嵌套的 JSON 结构列select '''{ "id": "1", "name": "student_1", "detail": { "age": "8" } }''' as stuas mock_data;--然后我们使用 JsonExpandExt 去推断数据结构run mock_data as JsonExpandExt.`` where inputCol="stu" and structColumn="true" as mock_data_1;复制
JsonExpandExt:为Byzer-lang 内置的 Json 处理插件
``:Byzer-lang 使用 ET 时的语法规则,为空即可
inputCol="stu":表示 JSON 字段叫 stu
structColumn="true":表示解析 inputCol 字段的数据类型
提示:在 Byzer-lang 里,如果想看到对应的 ET 插件包含哪些参数,可以用宏命令查看,例如:!show "et/params/JsonExpandExt"; 可以查看 JsonExpandExt 的相关参数。
该 Column 的结构和层级可以通过 JsonExpandExt 的推断获取到:
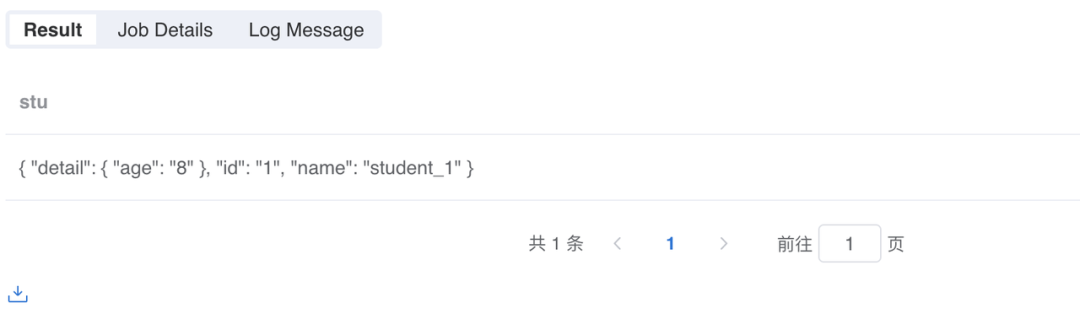
此时,再想要解析这条数据就十分简单了,可以直接通过层级获取相应字段:
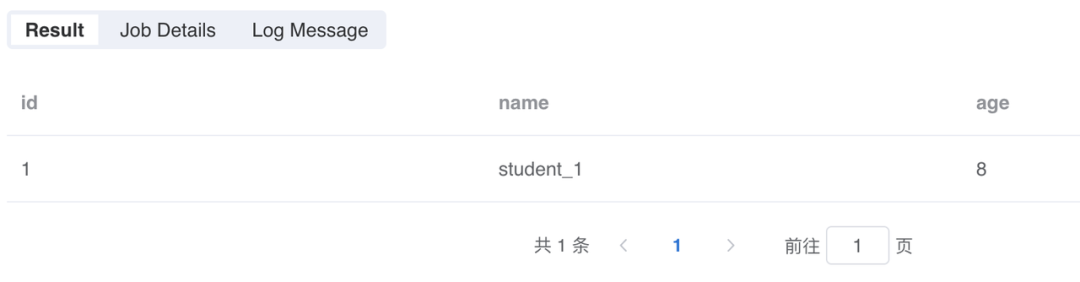
selectstu.id as id,stu.name as name,stu.detail.age as agefrom mock_data_1 as output;复制
我们可以看到,此时我们想要的列已经从复杂的 JSON 格式中被提取并展开成一张二维表:
第二种类型:JSON Array
JSON Array 形如 '[1,2,3,4]'
select '''[1,2,3,4]''' as json_arras output;复制
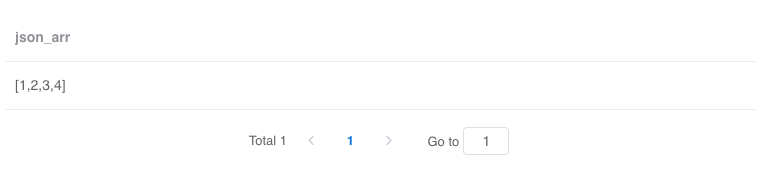
这种格式其实不怎么方便处理,但是我们可以借助一点技巧,先将 JSON Array 转化成 JSON Object:
select '''[1,2,3,4]''' as json_arras demo_1;select-- 利用字符串拼接将 json array 转化成 json objectconcat("{\"data\":", json_arr, "}") as json_arr_concatfrom demo_1as demo_2;复制

concat(col1, col2, ..., colN): Spark SQL 的函数,会将 col1, col2, ..., colN 拼接后返回,转化完成后我们就能用处理 json object 的方法处理了
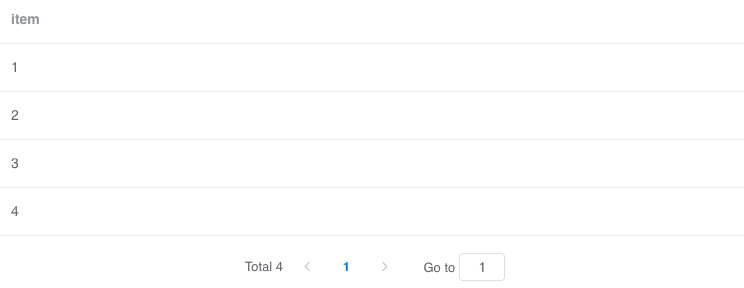
如果一个字段的值是一个数组,我们可以使用 Spark SQL 的 explode 方法将数组展开。
explode(expr): 将数组 expr 的元素分隔为多行,或将 map expr 的元素分隔为多行和多列。除非另有说明,否则对数组的元素使用默认的列名 col,或对映射的元素使用键和值。
-- 以 json array 转化成的 json object 为例select '''[1,2,3,4]''' as json_arras demo_1;select-- 利用字符串拼接将 json array 转化成 json objectconcat("{\"data\":", json_arr, "}") as json_arr_concatfrom demo_1as demo_2;--然后我们使用 JsonExpandExt 去推断数据结构run demo_2 as JsonExpandExt.`` where inputCol="json_arr_concat" and structColumn="true" as demo_3;select-- 通过 Spark SQL 的 explode 方法将数组展开explode(json_arr_concat.data) as itemfrom demo_3as output;复制
实践中我们发现,在某些特定情况下,若结果集中所有数据的 detail 字段都为 null,此时使用相同的逻辑,就会出现问题了。
select '''{ "id": "2", "name": "student_2", "detail": null }''' as stuas mock_data;run mock_data as JsonExpandExt.`` where inputCol="stu" andstructColumn="true" as mock_data_1;selectstu.id as id,stu.name as name,stu.detail.age as agefrom mock_data_1 as output;复制
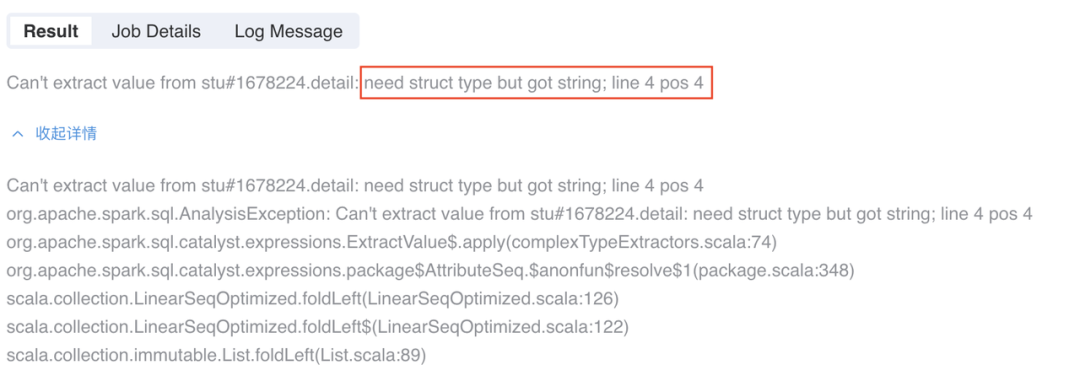
报错提示需要一个 struct 但是实际却是一个 string,这是什么情况?
第一反应猜测可能是因为 detail 为 null,先用 case when 判断试试。
select '''{ "id": "2", "name": "student_2", "detail": null }''' as stuas mock_data;run mock_data as JsonExpandExt.`` where inputCol="stu" and structColumn="true" as mock_data_1;selectstu.id as id,stu.name as name,casewhen isnotnull(stu.detail) then stu.detail.ageelse ""end as agefrom mock_data_1 as output;复制
还是一样的报错,这是为什么呢?
其实在 SQL 中第 12 行 stu.detail.age 这个解析是在很早的阶段就进行校验的,而 case when 的逻辑则是在执行时。所以 case when 不会生效,在 SQL 做解析的时候就已经报错了。
本质上是因为结果集中所有 JSON 数据的 detail 字段都为 NULL,导致 JsonExpandExt 推断该字段没有嵌套子级,而在后续处理逻辑中,我们却将 stu.detail 当做一个 struct 去获取 stu.detail.age,这就与推断的数据结构出现冲突,因此会报错。
方案一:利用 Byzer 分支语句处理结果集
我们首先很容易就会想到一条路:有这个字段,就处理,如果全都没有这个字段,不处理,这不就行了?这是一个很明显的条件判断。
SQL 是不支持分支语句的,但是在 Byzer-lang 中配合宏命令做到了分支语句的支持,允许我们正常使用 if/else,强化拓展了语言自身的能力,具体使用可以参考 Byzer 手册。这样就得到了我们的方案一:利用分支语句处理结果集。
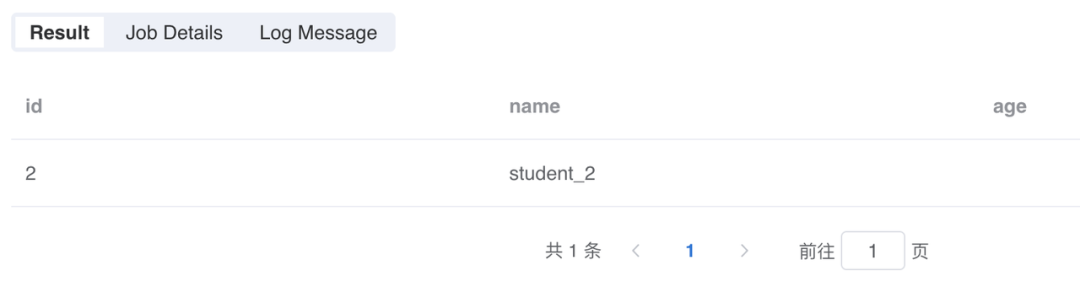
select '''{ "id": "2", "name": "student_2", "detail": null }''' as stuas mock_data;run mock_data as JsonExpandExt.`` where inputCol="stu" and structColumn="true" as mock_data_1;-- 计算 detail 字段不为 NULL 的数据的条数set count = `select count(*) from mock_data_1 where stu.detail is not null` where type="sql";-- 如果所有数据的 detail 字段都为 NULL!if ''' :count == 0 ''';!then;selectstu.id as id,stu.name as name,-- 指定 age 为空字符串"" as agefrom mock_data_1 as mock_data_2;!else;-- 如果有 detail 字段不为空的数据,那么正常处理selectstu.id as id,stu.name as name,stu.detail.age as agefrom mock_data_1 as mock_data_2;!fi;select * from mock_data_2 as output;复制
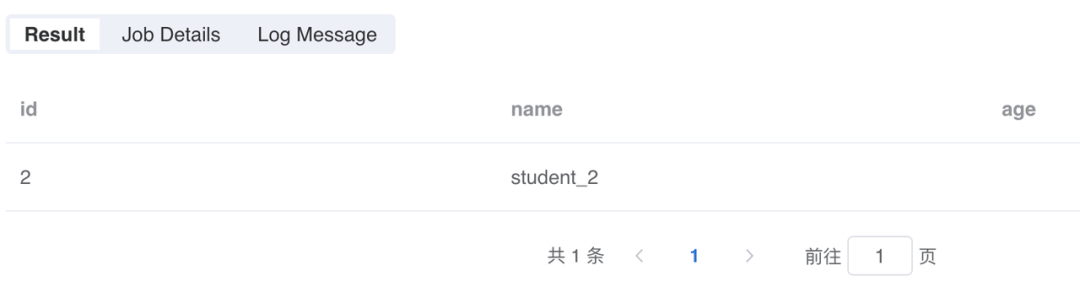
此时,所有字段都可以被正确获取到了:
方案二:分支语句结合 SQL 补全字段
在方案一的基础上扩展一下思维,我们是不是也可以自己补全一下缺失的字段?
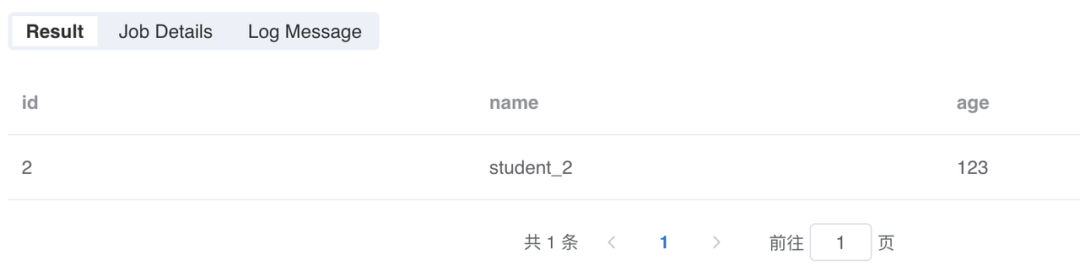
select '''{ "id": "2", "name": "student_2", "detail": null }''' as stuas mock_data;run mock_data as JsonExpandExt.`` where inputCol="stu" and structColumn="true" as mock_data_1;-- 计算 detail 字段不为 NULL 的数据的条数set count = `select count(*) from mock_data_1 where stu.detail is not null` where type="sql";-- 如果所有数据的 detail 字段都为 NULL!if ''' :count == 0 ''';!then;selectstu.id as id,stu.name as name,-- 通过 Spark SQL 的 map 函数手动给 detail 加上子级map("age","123") as detailfrom mock_data_1 as mock_data_2;!fi;select id, name, detail.age from mock_data_2 as output;复制
手动补全数据,但不是补全在 stu 字段里,而是把 detail 单独出来了:
方案三:自主开发 ET 满足需求
方案一和方案二在字段比较少的时候还是可以使用的,比较简单,但是如果数据嵌套的层级过深,就无法解决了。
现在就轮到第三个方案出场了:开发一个自定义的 ET,给定一个 schema,强制修改原来的 schema 为正确值,这样解析 SQL 时就可以用 If 函数不会报错了。
Byzer-lang 在此基础上才能具备足够灵活的扩展性,开发 ET 的方法请戳 这里。
例如下面的一段伪代码解释了自主开发一个叫 ReplaceColumnExt 的 ET 的参考方式:
select '''{ "id": "2", "name": "student_2", "detail": null }''' as stuas mock_data;run mock_data as JsonExpandExt.`` where inputCol="stu" and structColumn="true" as mock_data_1;-- 这是一段伪代码run mock_data_1 as ReplaceColumnExt.`` where col="stu.detail" andcolType="st(field(age,string))" and if=''' fieldType(stu.detail)=="string" ''' as mock_data_2;select if(stu.detail is null, "", stu.detail.age) as agefrom mock_data_2 as output;select * from table2 as output;复制
方案四:使用 python 脚本补全字段
Byzer-lang 对 Python 也提供了支持:Byzer-python,有了 Byzer-python 我们就可以在 Byzer 中拥抱 Python 的生态了。
所以即使不去自定义 ET,我们也能使用 python 脚本来修改 schema。
1)首先获取数据:
select '''{ "id": "2", "name": "student_2", "detail": null }''' as stuas mock_data;复制
2)然后用 python 脚本补全数据
以 Byzer Notebook 为例,新建一个类型为 Python 的 cell,增加如下配置:
配置项 | 功能 |
#%python | 指定当前 cell 为 Python 脚本 |
#%input | 指定输入的表名 |
#%output | 指定输出的表名 |
#%schema | 指定 Python 脚本返回的数据格式:如果返回的是表,可以通过设置 |
#%runIn | 指定代码是在 driver 还是在 executor 端执行,推荐 driver |
#%dataMode | 如果代码中使用了 |
#%cache | 指定是否需要缓存 Python 脚本运行的结果,一般配置为 true。
|
#%env | 指定需要使用的 Python 虚拟环境 |
#%python#%input=mock_data_1#%output=mock_data_2#%schema=st(field(stu,string))#%runIn=driver#%dataMode=data#%cache=true#%env=source activate devfrom pyjava.api.mlsql import PythonContext,RayContextimport json# type hintcontext:PythonContext = contextray_context = RayContext.connect(globals(),None)def completion(row):result = rowresult['stu']['detail'] = result['stu'].get('detail') if result['stu']['detail'] else {'age': ""}result['stu'] = json.dumps(result['stu'])return resultray_context.foreach(completion)
3)补全之后的数据结果显示如下:
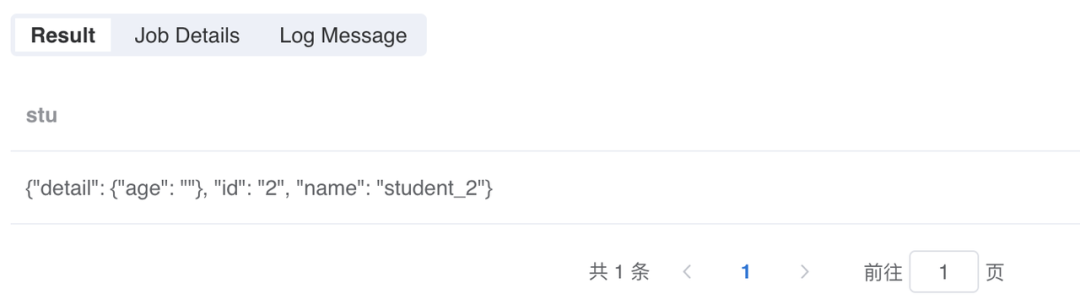
这样就能很轻易的处理 detail 的 age 字段了:
run mock_data_2 as JsonExpandExt.`` where inputCol="stu" and structColumn="true" as mock_data_3;selectstu.id as id,stu.name as name,stu.detail.age as agefrom mock_data_3 as output;复制
总结
以上四种方法只是抛砖引玉,期待小伙伴们来 Byzer 社区一起分享更多有趣的解法。

了解更多信息,欢迎大家关注我们的微信公众号
👇 👇 👇
也欢迎大家扫码添加 Byzer 小助手,
加入 Byzer 用户微信群讨论、交流问题哦~


点击阅读原文,访问 Byzer 官网
